prometheus-operator监控k8s集群及二进制k8s组件
环境
kubernetes: v1.17.3
kube-prometheus
部署
获取源码
需要安装git
yum -y install git
下载官方prometheus-operator
git clone https://github.com/coreos/kube-prometheus.git
## 或使用我自己的github文件省去下面所有配置直接kubectl apply -f 相应目录下的文件即可
https://github.com/kubernetes-devops/prometheus-operator.git
#使用此配置以下操作仅为了解
修改配置文件
在alertmanager-service.yaml增加---------type: NodePort及nodePort: 30093
在grafana-service.yaml增加---------type: NodePort及nodePort: 32000
在prometheus-service.yaml增加---------type: NodePort及nodePort: 30090
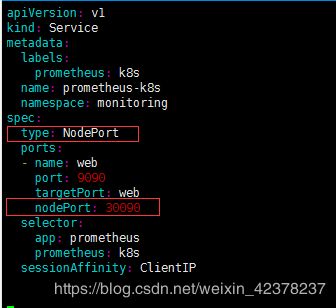
创建monitoring 名称空间并安装prometheus-operator
cd kube-prometheus
kubectl create -f manifests/setup
kubectl create -f manifests/
http://localhost:30090/targets
我们发现有两个targets下面没有内容,分别是kube-controller-manager和kube-scheduler。
解决办法
这里创建两个管理组件的svc,将svc的label设置为k8s-app: {kube-controller-manager、kube-scheduler},这样就可以被servicemonitor选中
如果需要监控controllers、scheduler需要修改其配置文件,--bind-address地址为:0.0.0.0
创建一个svc用来绑定
#创建一个单独的目录存放
mkdir /root/kube-promethues/manifests/scheduler-controller-manager
cd /root/kube-promethues/manifests/scheduler-controller-manager
vim prometheus-kubeMasterService.yaml
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-controller-manager
labels:
k8s-app: kube-controller-manager
spec:
selector:
component: kube-controller-manager
type: ClusterIP
clusterIP: None
ports:
- name: http-metrics
port: 10252
targetPort: 10252
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-scheduler
labels:
k8s-app: kube-scheduler
spec:
selector:
component: kube-scheduler
type: ClusterIP
clusterIP: None
ports:
- name: http-metrics
port: 10251
targetPort: 10251
protocol: TCP
手动填写svc对应的ep的属性,ep的名称要和svc名称和属性对应上
vim prometheus-kubeMasterEndPoints.yaml
apiVersion: v1
kind: Endpoints
metadata:
labels:
k8s-app: kube-controller-manager
name: kube-controller-manager
namespace: kube-system
subsets:
- addresses:
- ip: 192.168.0.10
- ip: 192.168.0.11
- ip: 192.168.0.12
ports:
- name: http-metrics
port: 10252
protocol: TCP
---
apiVersion: v1
kind: Endpoints
metadata:
labels:
k8s-app: kube-scheduler
name: kube-scheduler
namespace: kube-system
subsets:
- addresses:
- ip: 192.168.0.10
- ip: 192.168.0.11
- ip: 192.168.0.12
ports:
- name: http-metrics
port: 10251
protocol: TCP
kubectl apply -f prometheus-kubeMasterService.yaml
kubectl apply -f prometheus-kubeMasterEndPoints.yaml
#或者执行两次
kubectl apply -f .

这时,两个targets下面就会有内容产生了。

Prometheus监控kube-proxy集群
第一步建立一个 ServiceMonitor 对象,用于 Prometheus 添加监控项
第二步为 ServiceMonitor 对象关联 metrics 数据接口的一个 Service 对象
第三步确保 Service 对象可以正确获取到 metrics 数据
创建 ServiceMonitor
vim prometheus-serviceMonitorKube-proxy.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
k8s-app: kube-proxy
name: kube-proxy
namespace: monitoring
spec:
endpoints:
- interval: 30s
metricRelabelings:
- action: drop
regex: kubelet_(pod_worker_latency_microseconds|pod_start_latency_microseconds|cgroup_manager_latency_microseconds|pod_worker_start_latency_microseconds|pleg_relist_latency_microseconds|pleg_relist_interval_microseconds|runtime_operations|runtime_operations_latency_microseconds|runtime_operations_errors|eviction_stats_age_microseconds|device_plugin_registration_count|device_plugin_alloc_latency_microseconds|network_plugin_operations_latency_microseconds)
sourceLabels:
- __name__
- action: drop
regex: scheduler_(e2e_scheduling_latency_microseconds|scheduling_algorithm_predicate_evaluation|scheduling_algorithm_priority_evaluation|scheduling_algorithm_preemption_evaluation|scheduling_algorithm_latency_microseconds|binding_latency_microseconds|scheduling_latency_seconds)
sourceLabels:
- __name__
- action: drop
regex: apiserver_(request_count|request_latencies|request_latencies_summary|dropped_requests|storage_data_key_generation_latencies_microseconds|storage_transformation_failures_total|storage_transformation_latencies_microseconds|proxy_tunnel_sync_latency_secs)
sourceLabels:
- __name__
- action: drop
regex: kubelet_docker_(operations|operations_latency_microseconds|operations_errors|operations_timeout)
sourceLabels:
- __name__
- action: drop
regex: reflector_(items_per_list|items_per_watch|list_duration_seconds|lists_total|short_watches_total|watch_duration_seconds|watches_total)
sourceLabels:
- __name__
- action: drop
regex: etcd_(helper_cache_hit_count|helper_cache_miss_count|helper_cache_entry_count|request_cache_get_latencies_summary|request_cache_add_latencies_summary|request_latencies_summary)
sourceLabels:
- __name__
- action: drop
regex: transformation_(transformation_latencies_microseconds|failures_total)
sourceLabels:
- __name__
- action: drop
regex: (admission_quota_controller_adds|crd_autoregistration_controller_work_duration|APIServiceOpenAPIAggregationControllerQueue1_adds|AvailableConditionController_retries|crd_openapi_controller_unfinished_work_seconds|APIServiceRegistrationController_retries|admission_quota_controller_longest_running_processor_microseconds|crdEstablishing_longest_running_processor_microseconds|crdEstablishing_unfinished_work_seconds|crd_openapi_controller_adds|crd_autoregistration_controller_retries|crd_finalizer_queue_latency|AvailableConditionController_work_duration|non_structural_schema_condition_controller_depth|crd_autoregistration_controller_unfinished_work_seconds|AvailableConditionController_adds|DiscoveryController_longest_running_processor_microseconds|autoregister_queue_latency|crd_autoregistration_controller_adds|non_structural_schema_condition_controller_work_duration|APIServiceRegistrationController_adds|crd_finalizer_work_duration|crd_naming_condition_controller_unfinished_work_seconds|crd_openapi_controller_longest_running_processor_microseconds|DiscoveryController_adds|crd_autoregistration_controller_longest_running_processor_microseconds|autoregister_unfinished_work_seconds|crd_naming_condition_controller_queue_latency|crd_naming_condition_controller_retries|non_structural_schema_condition_controller_queue_latency|crd_naming_condition_controller_depth|AvailableConditionController_longest_running_processor_microseconds|crdEstablishing_depth|crd_finalizer_longest_running_processor_microseconds|crd_naming_condition_controller_adds|APIServiceOpenAPIAggregationControllerQueue1_longest_running_processor_microseconds|DiscoveryController_queue_latency|DiscoveryController_unfinished_work_seconds|crd_openapi_controller_depth|APIServiceOpenAPIAggregationControllerQueue1_queue_latency|APIServiceOpenAPIAggregationControllerQueue1_unfinished_work_seconds|DiscoveryController_work_duration|autoregister_adds|crd_autoregistration_controller_queue_latency|crd_finalizer_retries|AvailableConditionController_unfinished_work_seconds|autoregister_longest_running_processor_microseconds|non_structural_schema_condition_controller_unfinished_work_seconds|APIServiceOpenAPIAggregationControllerQueue1_depth|AvailableConditionController_depth|DiscoveryController_retries|admission_quota_controller_depth|crdEstablishing_adds|APIServiceOpenAPIAggregationControllerQueue1_retries|crdEstablishing_queue_latency|non_structural_schema_condition_controller_longest_running_processor_microseconds|autoregister_work_duration|crd_openapi_controller_retries|APIServiceRegistrationController_work_duration|crdEstablishing_work_duration|crd_finalizer_adds|crd_finalizer_depth|crd_openapi_controller_queue_latency|APIServiceOpenAPIAggregationControllerQueue1_work_duration|APIServiceRegistrationController_queue_latency|crd_autoregistration_controller_depth|AvailableConditionController_queue_latency|admission_quota_controller_queue_latency|crd_naming_condition_controller_work_duration|crd_openapi_controller_work_duration|DiscoveryController_depth|crd_naming_condition_controller_longest_running_processor_microseconds|APIServiceRegistrationController_depth|APIServiceRegistrationController_longest_running_processor_microseconds|crd_finalizer_unfinished_work_seconds|crdEstablishing_retries|admission_quota_controller_unfinished_work_seconds|non_structural_schema_condition_controller_adds|APIServiceRegistrationController_unfinished_work_seconds|admission_quota_controller_work_duration|autoregister_depth|autoregister_retries|kubeproxy_sync_proxy_rules_latency_microseconds|rest_client_request_latency_seconds|non_structural_schema_condition_controller_retries)
sourceLabels:
- __name__
- action: drop
regex: etcd_(debugging|disk|request|server).*
sourceLabels:
- __name__
port: http-metrics
jobLabel: k8s-app
namespaceSelector:
matchNames:
- kube-system
selector:
matchLabels:
k8s-app: kube-proxy
创建 Service/Endpoints
vim prometheus-serviceKube-Proxy.yaml
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-proxy
labels:
k8s-app: kube-proxy
spec:
selector:
component: kube-proxy
type: ClusterIP
clusterIP: None
ports:
- name: http-metrics
port: 10249
targetPort: 10249
protocol: TCP
---
apiVersion: v1
kind: Endpoints
metadata:
labels:
k8s-app: kube-proxy
name: kube-proxy
namespace: kube-system
subsets:
- addresses:
- ip: 200.200.100.71
- ip: 200.200.100.72
- ip: 200.200.100.73
- ip: 200.200.100.74
ports:
- name: http-metrics
port: 10249
protocol: TCP
kubectl apply -f prometheus-serviceMonitorKube-proxy.yaml
kubectl apply -f prometheus-serviceKube-Proxy.yaml
Prometheus 的 Dashboard 中查看 targets,便会有 kube-proxy的监控项

数据采集到后,可以在 grafana 获取到 kube-proxy 的监控图表。
Prometheus监控Etcd集群
作者:baiyongjie
链接:https://www.jianshu.com/p/cc0a7cbdb41d
来源:简书
前提Prometheus是用Prometheus Operator安装的
安装方法:
Prometheus Operator: https://www.qikqiak.com/post/first-use-prometheus-operator/
监控Etcd: https://www.qikqiak.com/post/prometheus-operator-monitor-etcd/
第一步建立一个 ServiceMonitor 对象,用于 Prometheus 添加监控项
第二步为 ServiceMonitor 对象关联 metrics 数据接口的一个 Service 对象
第三步确保 Service 对象可以正确获取到 metrics 数据
创建secrets资源
首先查看etcd引用的证书文件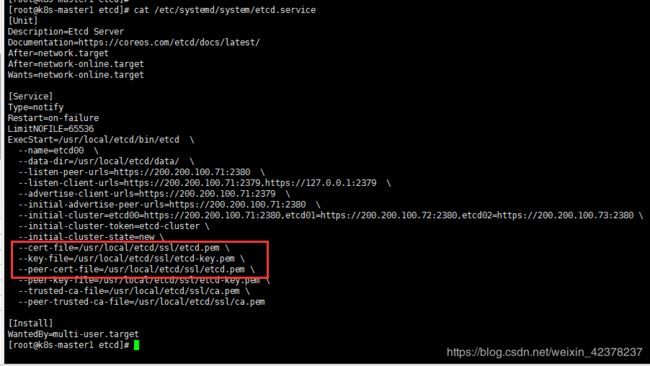
创建secret资源
kubectl -n monitoring create secret generic etcd-certs \
--from-file=/usr/local/etcd/ssl/ca.pem \
--from-file=/usr/local/etcd/ssl/etcd.pem \
--from-file=/usr/local/etcd/ssl/etcd-key.pem
apply Prometheus配置文件
修改下载的Prometheus Operator的kube-prometheus/manifests/prometheus-prometheus.yaml文件

kubectl apply -f prometheus-prometheus.yaml
#等到pod重启后,进入pod查看是否可以看到证书
# kubectl exec -it -n monitoring prometheus-k8s-0 -- /bin/sh
/prometheus $ ls -l /etc/prometheus/secrets/etcd-certs/
total 0
lrwxrwxrwx 1 root root 22 Oct 24 07:20 k8s-root-ca.pem -> ..data/k8s-root-ca.pem
lrwxrwxrwx 1 root root 25 Oct 24 07:20 kubernetes-key.pem -> ..data/kubernetes-key.pem
lrwxrwxrwx 1 root root 21 Oct 24 07:20 kubernetes.pem -> ..data/kubernetes.pem
创建 ServiceMonitor
$ vim prometheus-serviceMonitorEtcd.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: etcd-k8s
namespace: monitoring
labels:
k8s-app: etcd-k8s
spec:
jobLabel: k8s-app
endpoints:
- port: port
interval: 30s
scheme: https
tlsConfig:
caFile: /etc/prometheus/secrets/etcd-certs/k8s-root-ca.pem
certFile: /etc/prometheus/secrets/etcd-certs/kubernetes.pem
keyFile: /etc/prometheus/secrets/etcd-certs/kubernetes-key.pem
insecureSkipVerify: true
selector:
matchLabels:
k8s-app: etcd
namespaceSelector:
matchNames:
- kube-system
$ kubectl apply -f prometheus-serviceMonitorEtcd.yaml
注:此文件内的证书路径为prometheus-k8s-0 里的etcd证书路径!!!
上面我们在 monitoring 命名空间下面创建了名为 etcd-k8s 的 ServiceMonitor 对象,基本属性和前面章节中的一致,匹配 kube-system 这个命名空间下面的具有 k8s-app=etcd 这个 label 标签的 Service,jobLabel 表示用于检索 job 任务名称的标签,和前面不太一样的地方是 endpoints 属性的写法,配置上访问 etcd 的相关证书,endpoints 属性下面可以配置很多抓取的参数,比如 relabel、proxyUrl,tlsConfig 表示用于配置抓取监控数据端点的 tls 认证,由于证书 serverName 和 etcd 中签发的可能不匹配,所以加上了 insecureSkipVerify=true
创建 Service
#vim prometheus-etcdService.yaml
apiVersion: v1
kind: Service
metadata:
name: etcd-k8s
namespace: kube-system
labels:
k8s-app: etcd
spec:
type: ClusterIP
clusterIP: None
ports:
- name: port
port: 2379
protocol: TCP
---
apiVersion: v1
kind: Endpoints
metadata:
name: etcd-k8s
namespace: kube-system
labels:
k8s-app: etcd
subsets:
- addresses:
- ip: 200.200.100.71
- ip: 200.200.100.72
- ip: 200.200.100.73
ports:
- name: port
port: 2379
protocol: TCP
#kubectl apply -f prometheus-etcdService.yaml
Prometheus 的 Dashboard 中查看 targets,便会有 etcd 的监控项
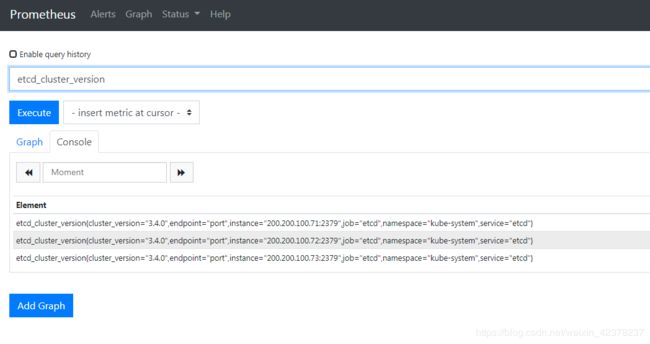

数据采集到后,可以在 grafana 中导入编号为3070的 dashboard,获取到 etcd 的监控图表。

Etcd监控指标
参考: https://github.com/coreos/etcd/blob/master/Documentation/metrics.md
领导者相关
etcd_server_has_leader etcd是否有leader
etcd_server_leader_changes_seen_total etcd的leader变换次数
etcd_debugging_mvcc_db_total_size_in_bytes 数据库的大小
process_resident_memory_bytes 进程驻留内存
网络相关
grpc_server_started_total grpc(高性能、开源的通用RPC(远程过程调用)框架)服务器启动总数
etcd_network_client_grpc_received_bytes_total 接收到grpc客户端的字节总数
etcd_network_client_grpc_sent_bytes_total 发送给grpc客户端的字节总数
etcd_network_peer_received_bytes_total etcd网络对等方接收的字节总数(对等网络,即对等计算机网络,是一种在对等者(Peer)之间分配任务和工作负载的分布式应用架构,是对等计算模型在应用层形成的一种组网或网络形式)
etcd_network_peer_sent_bytes_total etcd网络对等方发送的字节总数
提案相关
etcd_server_proposals_failed_total 目前正在处理的提案(提交会议讨论决定的建议。)数量
etcd_server_proposals_pending 失败提案总数
etcd_server_proposals_committed_total 已落实共识提案的总数。
etcd_server_proposals_applied_total 已应用的共识提案总数。
这些指标描述了磁盘操作的状态。
etcd_disk_backend_commit_duration_seconds_sum etcd磁盘后端提交持续时间秒数总和
etcd_disk_backend_commit_duration_seconds_bucket etcd磁盘后端提交持续时间
快照
etcd_debugging_snap_save_total_duration_seconds_sum etcd快照保存用时
文件
process_open_fds{service="etcd-k8s"} 打开文件描述符的数量
process_max_fds{service="etcd-k8s"} 打开文件描述符的最大数量
etcd_disk_wal_fsync_duration_seconds_sum Wal(预写日志系统)调用的fsync(将文件数据同步到硬盘)的延迟分布
etcd_disk_wal_fsync_duration_seconds_bucket 后端调用的提交的延迟分布