- 【自动驾驶】自动驾驶地图构建方法与工具小结
CS_Zero
自动驾驶人工智能
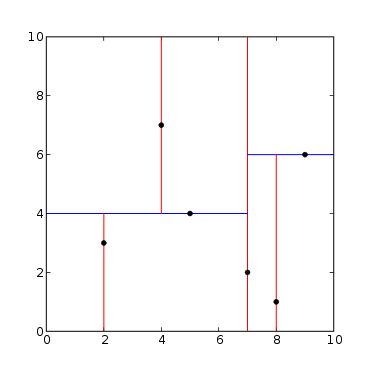
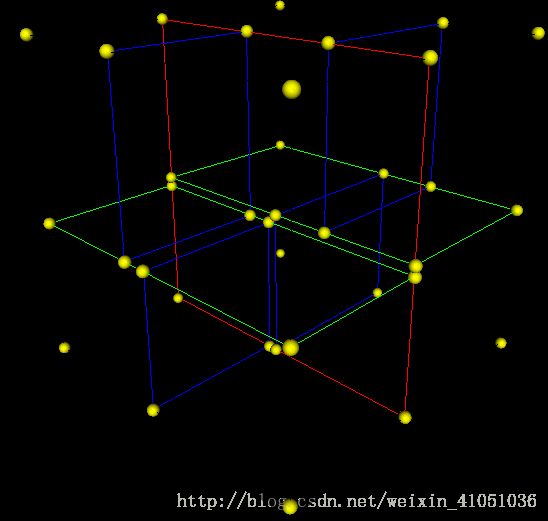
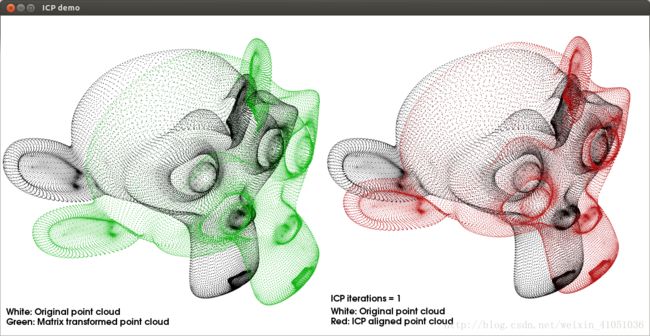
自动驾驶地图构建小结概述制作流程主要利用定位与建图算法(组合导航,视觉、激光SLAM等),融合多种传感器数据,构建高精度、高分辨率的三维语义地图,将要素矢量化,构建要素间的关联关系,通过质检确保质量可靠,形成地图引擎(服务、API)以满足自动驾驶系统的需求。底图构建底图构建存在两大类方法,点云建图与视觉建图。点云建图一般面向高精度采集设备,采用高线束激光雷达,硬件成本高。一般使用高精度组合导航进行
- Android D8 编译器 和 R8 工具,【一篇文章搞懂】
安卓开发top
Androidandroidjavaeclipse移动开发
android.enableIncrementalDesugaring=false.android.enableDesugar=false2.1Lambda表达式Java8中一个重大变更是引入Lambda表达式。publicclassLambda{publicstaticvoidmain(String[]args){logDebug(msg->System.out.println(msg),"He
- 特斯拉神器TeslaMate一键安装,终于来了
oakley0
cartesla云服务器腾讯云
之前分享了teslamate的功能和简单安装方法,很多喜欢尝鲜的车友尝试了,但安装过程对不熟悉linux服务器的非码农来说还是有点小艰辛。趁这回双十一腾讯云重磅优惠,我也重新屯了服务器重装了一遍,现在把简化后安装过程、一键安装方法包括加密登录的方式分享一下。目录1.购买服务器2.登录服务器3.安装TeslaMate3.1切换管理员用户3.2一键安装TeslaMate-【简单模式】3.3一键安装Te
- 特斯拉神器TeslaMate一键安装,来了
oakley04
腾讯云阿里云云计算
之前分享了teslamate的功能和简单安装方法,很多喜欢尝鲜的车友尝试了,但安装过程对不熟悉linux服务器的非码农来说还是有点小艰辛。趁这回双十一腾讯云重磅优惠,我也重新屯了服务器重装了一遍,现在把简化后安装过程或一键安装方法分享一下。1.购买服务器以下三款服务器都可以,其中最推荐中间的2核4G8M带宽的三年198,还没入手请点击下面的入口链接:腾讯云运营活动-腾讯云https://curl.
- TeslaMate特斯拉神器本地Docker部署实现无公网远程访问
nagiY
てんさいdocker容器运维sql
文章目录1.Docker部署TeslaMate2.本地访问TeslaMate3.Linux安装Cpolar4.配置TeslaMate公网地址5.远程访问TeslaMate6.固定TeslaMate公网地址7.固定地址访问TeslaMateTeslaMate是一个开源软件,可以通过连接特斯拉账号,记录行驶历史,统计能耗、里程、充电次数等数据。用户可以通过web界面查看车辆状态、行程报告、充电记录等信
- Ubuntu环境搭建TeslaMate,特斯拉车友必备,可视化数据仪表!使用极空间Z4虚拟机
喵不是白养的
ubuntulinux
能点进来的大概率都是特斯拉车友~~本篇记录一下使用极空间Z4家庭NAS搭建TeslaMate的全过程,使用极空间最近更新的虚拟机功能,在虚拟机中安装Ubuntu部署Docker。当然大家用PC虚拟机搭建也可以啦!至于为什么不用极空间自带的Docker功能,emmm并不好用。要是想要使用自带的docker来搭建,可以参照这个https://post.smzdm.com/p/az59px95/本人自学
- 使用Docker部署TeslaMate并结合内网穿透软件实现远程访问车辆数据
比奥利奥还傲.
docker容器运维服务器linux
文章目录1.Docker部署TeslaMate2.本地访问TeslaMate3.Linux安装Cpolar4.配置TeslaMate公网地址5.远程访问TeslaMate6.固定TeslaMate公网地址7.固定地址访问TeslaMateTeslaMate是一个开源软件,可以通过连接特斯拉账号,记录行驶历史,统计能耗、里程、充电次数等数据。用户可以通过web界面查看车辆状态、行程报告、充电记录等信
- 如何在本地服务器部署TeslaMate并远程查看特斯拉汽车数据无需公网ip
日出等日落
内网穿透服务器汽车tcp/ip
文章目录1.Docker部署TeslaMate2.本地访问TeslaMate3.Linux安装Cpolar4.配置TeslaMate公网地址5.远程访问TeslaMate6.固定TeslaMate公网地址7.固定地址访问TeslaMateTeslaMate是一个开源软件,可以通过连接特斯拉账号,记录行驶历史,统计能耗、里程、充电次数等数据。用户可以通过web界面查看车辆状态、行程报告、充电记录等信
- 伊朗藏红花前五个月出口增长33%
西域竹君斋
Iran’ssaffronexportsincreased33percentduringthefirstfivemonthsofthecurrentIraniancalendaryear(March21-August22)comparedtothesameperiodoftimeinthepastyear,accordingtothelatestdatareleasedbytheIslamicRe
- 如何实现基于图像与激光雷达的 3d 场景重建?
大势智慧
3d人工智能计算机视觉三维建模激光点云
智影S100是一款基于图像和激光点云融合建模技术的高精度轻巧手持SLAM三维激光扫描仪。设备机身小巧、手持轻便,可快速采集点云数据;支持实时解算、实时预览点云成果,大幅提高内外业工作效率;同时支持一键生成实景三维Mesh模型,实现城市建筑、堆体、室内空间等场景的高逼真3d重建。以下是智影S100在国家游泳中心“水立方”进行实地采集的点云与模型成果展示:智影S100:水立方立面点云与模型成果分享,实
- ROS目标跟随(路径规划、雷达、slam、定位)
海风-
ROS小车跟随目标跟随雷达路径规划定位
ROS目标跟随(路径规划、雷达、地图、定位)最终效果展示一、总体launch文件1、打开已有地图2、组合小车的各个部分2.1惯性矩阵设置2.2小车底盘2.3摄像头2.4雷达2.5为机器人模型添加传动装置以及控制器2.6为机器人模型添加雷达配置2.7为机器人模型添加摄像头配置2.8为机器人模型添加kinect摄像头配置3、定位系统(amcl)4、路径规划(move_base)4.1全局路径规划与本地
- ROS小车跟随
海风-
ROS小车跟随目标跟随雷达
这篇的目的是方便自己复习总体流程1、gazebo仿真世界2、机器人模型3、slam建图4、定位5、路径规划6、小车跟随7、总体launch文件第一篇博客给出了总体代码:https://blog.csdn.net/m0_71523511/article/details/135610191第二篇博客改善了跟随的效果:https://blog.csdn.net/m0_71523511/article/d
- 【激光SLAM】激光的前端配准算法
趴抖
激光SLAM激光SLAMSLAM前端
文章目录ICP匹配方法(PointtoPoint)PL-ICP匹配方法(PointtoLine)基于优化的匹配方法(Optimization-basedMethod)优化方法的求解地图双线性插值拉格朗日插值法——一维线性插值相关方法(Correlation-basedMethod)帧间匹配似然场算法流程位姿搜索分枝定界算法引用在激光SLAM中,前端配准(FrontendRegistration)是
- 【Java万花筒】跨越云平台的无服务器开发:使用Java构建弹性、高效的应用
friklogff
Java万花筒serverlessjavapython
无服务器计算平台的Java集成指南:AWSLambda、GoogleCloudFunctions、腾讯云函数和IBMCloudFunctions前言无服务器计算平台提供了一种方便、弹性和成本效益高的方式来运行代码,而无需关心底层基础设施的管理。在这篇文章中,我们将探讨如何使用Java语言与一些主要的无服务器计算平台集成,包括AWSLambda、GoogleCloudFunctions、腾讯云函数和
- 基于ORB-SLAM2与YOLOv8剔除动态特征点
笨小古
SLAM学习SLAMYOLOYOLOv8
基于ORB-SLAM2与YOLOv8剔除动态特征点以下方法以https://cvg.cit.tum.de/data/datasets/rgbd-dataset/download#freiburg3_walking_xyz数据集进行实验测试APE首先在不剔除动态特征点的情况下进行测试:方法1:segment坐标点集合逐一排查剔除利用YOLOv8的segment获取动态对象(这里指人person)所在
- 周三 2020-03-11 06:40 - 24:00 晴 05h34m
么得感情的日更机器
白天干事,晚上玩和总结,早睡早起概述 早上6:40醒,然后开始日常任务:单词+口语+听力+学习强国。7:00到7:30躺床上看哔哩哔哩,发现一些好的SLAM视频。7:40下楼吃饭,8:30上楼练字。上午8:40到9:40看论文,9:45到10:00运动时间,10:00到11:15看论文。11:15到11:50玩哔哩哔哩。下午12:00吃午饭,12:30到13:00学习摄影技能。14:13-14:
- 视觉slam十四讲学习笔记(六)视觉里程计 1
苦瓜汤补钙
视觉SLAM十四讲笔记机器学习ubuntu
本文关注基于特征点方式的视觉里程计算法。将介绍什么是特征点,如何提取和匹配特征点,以及如何根据配对的特征点估计相机运动。目录前言一、特征点法1特征点2ORB特征FAST关键点BRIEF描述子3特征匹配二、实践:特征提取和匹配三、2D-2D:对极几何1对极约束2本质矩阵3单应矩阵四、实践:对极约束求解相机运动五、三角测量总结前言1.理解图像特征点的意义,并掌握在单幅图像中提取出特征点,及多幅图像中匹
- 相机—特点及区别
Dirschs
摄像头数码相机
1.相机种类RGB,RGB-D,单目,双目,sterro相机,实例相机2.相机特点2.1单目只使用一个摄像头进行SLAM,结构简单,成本低三维空间的二维投影必须移动相机,才能估计场景中物体的远近和大小单目SLAM估计的轨迹和地图与真实的相差一个因子2.2双目由两个单目相机组成,两个相机之间的距离(基线)是已知的根据基线估计每个像素的空间位置,距离估计:比较左右眼的图像室内+室外缺点:配置与标定较为
- 视觉SLAM十四讲学习笔记——第五讲 相机与图像
晒月光12138
视觉SLAM十四讲学习笔记自动驾驶计算机视觉人工智能
这一讲主要内容就是了解摄像机的成像模型以及OpenCV的使用。1.四种坐标系坐标系基本描述世界坐标系因为摄像机和物体可以随便摆放在空间中的任何位置,所以我们必须用一个固定的坐标系来描述空间中任何物体的位置和摄像机的位置和朝向,这个基准坐标系我们称之为世界坐标系。在计算机视觉中,我们通常把世界坐标系定义为摄像机坐标系或者所观测的物体的中心。摄像机坐标系摄像机坐标系的原点是摄像机的光心,X、Y轴分别平
- 视觉slam十四讲学习笔记(四)相机与图像
苦瓜汤补钙
视觉SLAM十四讲笔记相机机器学习
理解理解针孔相机的模型、内参与径向畸变参数。理解一个空间点是如何投影到相机成像平面的。掌握OpenCV的图像存储与表达方式。学会基本的摄像头标定方法。目录前言一、相机模型1针孔相机模型2畸变单目相机的成像过程3双目相机模型4RGB-D相机模型二、图像计算机中图像的表示三、图像的存取与访问1安装OpenCV2存取与访问总结前言前面介绍了“机器人如何表示自身位姿”的问题,部分地解释了SLAM经典模型中
- 移动机器人激光SLAM导航(五):Cartographer SLAM 篇
Robot_Yue
自主探索导航学习SLAMCartographer工程化调参
参考Cartographer官方文档Cartographer从入门到精通1.Cartographer安装1.1前置条件推荐在刚装好的Ubuntu16.04或Ubuntu18.04上进行编译ROS安装:ROS学习1:ROS概述与环境搭建1.2依赖库安装资源下载完解压并执行以下指令https://pan.baidu.com/s/1LWqZ4SOKn2sZecQUDDXXEw?pwd=j6cf$sudo
- Serverless里FaaS与BaaS
久绊A
阿里云阿里云
目录什么是FaaS?什么是BaaS?什么是FaaS?FaaS即FunctionsasaService,函数即服务,是Serverless架构的一种形态,面向函数编程,基于事件驱动提供云服务之间端到端的解决方案。借助FaaS,开发人员可以快速构建任何类型的应用和服务,并且只需为任务实际消耗的资源付费。FaaS是Serverless模型中代码的托管计算服务。阿里云的函数计算、AWSLambda都是Fa
- 扩展速度提高了12倍!AWS Lambda 函数重大改进!
诗者才子酒中仙
物联网/互联网/人工智能/其他awsjava面试
Marcia是AmazonWebServices的首席开发倡导者,在软件行业构建和扩展应用程序方面拥有20年的工作经验。她热衷于设计能够充分利用云并拥抱DevOps文化的系统。最近她发表了一篇博文,带来了一个AWSLambda重大改进:扩展速度提升了12倍!1、Lambda函数更新,扩展速度倍增现在,AWSLambda的扩展速度提高了12倍。每个同步调用的Lambda函数现在每10秒扩展1000个
- ORB-SLAM3运行自制数据集进行定位教程
极客范儿
ORB-SLAM━═━═━◥MR◤━═━═━IMUORB-SLAM3
目前手上有一个特定的任务,做应急救援的视觉SLAM,目前公共数据集比较少,考虑自建数据集,从网络上爬虫火灾、地震的等手机录制的视屏,应用一些现有成熟ORB-SLAM3系统到这个数据集上看效果,然后根据效果得到一些模型改进思路。文章目录一、系统配置二、制作数据集1、脚本编写2、配置文件编写3、录制视频素材4、修改CMakeLists.txt5、编译运行一、系统配置系统版本ubuntu20.04Ope
- 视觉SLAM十四讲学习笔记(二)三维空间刚体
苦瓜汤补钙
视觉SLAM十四讲笔记计算机视觉算法
哔哩哔哩课程连接:视觉SLAM十四讲ch3_哔哩哔哩_bilibili目录一、旋转矩阵1点、向量、坐标系2坐标系间的欧氏变换3变换矩阵与齐次坐标二、实践:Eigen(1)运行报错记录与解决三、旋转向量和欧拉角1旋转向量2欧拉角四、四元数1四元数的定义2四元数的运算3用四元数表示旋转4四元数到旋转矩阵的转换五、实践:Eigen(2)useGeometryvisualizeGeometry总结前言问题
- 视觉slam十四讲学习笔记(三)李群与李代数
苦瓜汤补钙
视觉SLAM十四讲笔记人工智能学习
1.理解李群与李代数的概念,掌握SO(3),SE(3)与对应李代数的表示方式。2.理解BCH近似的意义。3.学会在李代数上的扰动模型。4.使用Sophus对李代数进行运算。目录前言一、李群李代数基础1群2李代数的引出3李代数的定义4李代数so(3)5李代数se(3)二、指数与对数映射1SO(3)上的指数映射2SE(3)上的指数映射三、李代数求导与扰动模型1BCH公式与近似形式2SO(3)李代数上的
- 【激光SLAM】激光雷达数学模型和运动畸变去除
趴抖
激光SLAMSLAM激光SLAM
目录概念介绍激光雷达传感器介绍测距原理三角测距飞行时间(TOF)激光雷达数学模型介绍光束模型(beammodel)似然场模型(likelihoodmodel)运动畸变介绍畸变去除纯估计方法(ICPVariants)ICP方法VICP(VelocityestimationICP)里程计辅助方法概念介绍激光雷达传感器介绍测距原理三角测距特点:中近距离精度较高,距离越近,精度越高价格便宜远距离精度较差易
- CentOS 7.9安装Tesla M4驱动、CUDA和cuDNN
Danileaf_Guo
centoslinux运维服务器
正文共:1333字21图,预估阅读时间:2分钟上次我们在Windows上尝试用TeslaM4配置深度学习环境(TensorFlow识别GPU难道就这么难吗?还是我的GPU有问题?),但是失败了。考虑到Windows本身就会调用图形显示,可能会有影响,所以我们本次换用Linux系统(CentOS7.9)来尝试一下。1、下载软件结合上次的经验教训,我们本次先确定合适的CUDA(ComputeUnifi
- 【Ubuntu18.04搭建 SLAM环境】
cc-growing
gitubuntulinux
CMake、g++、git的安装这是最基本的c++编译环境,可能已经安装了sudoapt-getinstallcmakesudoapt-getinstallg++sudoapt-getinstallgitOpencv3.4.16配置+opencv_contribOpencv有很多版本,建议采用源码安装对于Opencv3来说,最好安装3.4.5/3.4.16安装包下载注意opencv与opencv-
- 【orbslam2+nerf】
cashap27149
webpack前端node.js
1.需要安装cudacudnneigen-3.4.0opencv4.4以上(推荐opencv-4.5.5)需要gui,还要安装glfw:sudoapt-getinstalllibglfw3-devlibgl1-mesa-devlibglu1-mesa-devlibglew-dev2.run下载源码:给你了解压VocabularycdVocabularytarzxfORBvoc.txt.tar.gz
- Java常用排序算法/程序员必须掌握的8大排序算法
cugfy
java
分类:
1)插入排序(直接插入排序、希尔排序)
2)交换排序(冒泡排序、快速排序)
3)选择排序(直接选择排序、堆排序)
4)归并排序
5)分配排序(基数排序)
所需辅助空间最多:归并排序
所需辅助空间最少:堆排序
平均速度最快:快速排序
不稳定:快速排序,希尔排序,堆排序。
先来看看8种排序之间的关系:
1.直接插入排序
(1
- 【Spark102】Spark存储模块BlockManager剖析
bit1129
manager
Spark围绕着BlockManager构建了存储模块,包括RDD,Shuffle,Broadcast的存储都使用了BlockManager。而BlockManager在实现上是一个针对每个应用的Master/Executor结构,即Driver上BlockManager充当了Master角色,而各个Slave上(具体到应用范围,就是Executor)的BlockManager充当了Slave角色
- linux 查看端口被占用情况详解
daizj
linux端口占用netstatlsof
经常在启动一个程序会碰到端口被占用,这里讲一下怎么查看端口是否被占用,及哪个程序占用,怎么Kill掉已占用端口的程序
1、lsof -i:port
port为端口号
[root@slave /data/spark-1.4.0-bin-cdh4]# lsof -i:8080
COMMAND PID USER FD TY
- Hosts文件使用
周凡杨
hostslocahost
一切都要从localhost说起,经常在tomcat容器起动后,访问页面时输入http://localhost:8088/index.jsp,大家都知道localhost代表本机地址,如果本机IP是10.10.134.21,那就相当于http://10.10.134.21:8088/index.jsp,有时候也会看到http: 127.0.0.1:
- java excel工具
g21121
Java excel
直接上代码,一看就懂,利用的是jxl:
import java.io.File;
import java.io.IOException;
import jxl.Cell;
import jxl.Sheet;
import jxl.Workbook;
import jxl.read.biff.BiffException;
import jxl.write.Label;
import
- web报表工具finereport常用函数的用法总结(数组函数)
老A不折腾
finereportweb报表函数总结
ADD2ARRAY
ADDARRAY(array,insertArray, start):在数组第start个位置插入insertArray中的所有元素,再返回该数组。
示例:
ADDARRAY([3,4, 1, 5, 7], [23, 43, 22], 3)返回[3, 4, 23, 43, 22, 1, 5, 7].
ADDARRAY([3,4, 1, 5, 7], "测试&q
- 游戏服务器网络带宽负载计算
墙头上一根草
服务器
家庭所安装的4M,8M宽带。其中M是指,Mbits/S
其中要提前说明的是:
8bits = 1Byte
即8位等于1字节。我们硬盘大小50G。意思是50*1024M字节,约为 50000多字节。但是网宽是以“位”为单位的,所以,8Mbits就是1M字节。是容积体积的单位。
8Mbits/s后面的S是秒。8Mbits/s意思是 每秒8M位,即每秒1M字节。
我是在计算我们网络流量时想到的
- 我的spring学习笔记2-IoC(反向控制 依赖注入)
aijuans
Spring 3 系列
IoC(反向控制 依赖注入)这是Spring提出来了,这也是Spring一大特色。这里我不用多说,我们看Spring教程就可以了解。当然我们不用Spring也可以用IoC,下面我将介绍不用Spring的IoC。
IoC不是框架,她是java的技术,如今大多数轻量级的容器都会用到IoC技术。这里我就用一个例子来说明:
如:程序中有 Mysql.calss 、Oracle.class 、SqlSe
- 高性能mysql 之 选择存储引擎(一)
annan211
mysqlInnoDBMySQL引擎存储引擎
1 没有特殊情况,应尽可能使用InnoDB存储引擎。 原因:InnoDB 和 MYIsAM 是mysql 最常用、使用最普遍的存储引擎。其中InnoDB是最重要、最广泛的存储引擎。她 被设计用来处理大量的短期事务。短期事务大部分情况下是正常提交的,很少有回滚的情况。InnoDB的性能和自动崩溃 恢复特性使得她在非事务型存储的需求中也非常流行,除非有非常
- UDP网络编程
百合不是茶
UDP编程局域网组播
UDP是基于无连接的,不可靠的传输 与TCP/IP相反
UDP实现私聊,发送方式客户端,接受方式服务器
package netUDP_sc;
import java.net.DatagramPacket;
import java.net.DatagramSocket;
import java.net.Ine
- JQuery对象的val()方法执行结果分析
bijian1013
JavaScriptjsjquery
JavaScript中,如果id对应的标签不存在(同理JAVA中,如果对象不存在),则调用它的方法会报错或抛异常。在实际开发中,发现JQuery在id对应的标签不存在时,调其val()方法不会报错,结果是undefined。
- http请求测试实例(采用json-lib解析)
bijian1013
jsonhttp
由于fastjson只支持JDK1.5版本,因些对于JDK1.4的项目,可以采用json-lib来解析JSON数据。如下是http请求的另外一种写法,仅供参考。
package com;
import java.util.HashMap;
import java.util.Map;
import
- 【RPC框架Hessian四】Hessian与Spring集成
bit1129
hessian
在【RPC框架Hessian二】Hessian 对象序列化和反序列化一文中介绍了基于Hessian的RPC服务的实现步骤,在那里使用Hessian提供的API完成基于Hessian的RPC服务开发和客户端调用,本文使用Spring对Hessian的集成来实现Hessian的RPC调用。
定义模型、接口和服务器端代码
|---Model
&nb
- 【Mahout三】基于Mahout CBayes算法的20newsgroup流程分析
bit1129
Mahout
1.Mahout环境搭建
1.下载Mahout
http://mirror.bit.edu.cn/apache/mahout/0.10.0/mahout-distribution-0.10.0.tar.gz
2.解压Mahout
3. 配置环境变量
vim /etc/profile
export HADOOP_HOME=/home
- nginx负载tomcat遇非80时的转发问题
ronin47
nginx负载后端容器是tomcat(其它容器如WAS,JBOSS暂没发现这个问题)非80端口,遇到跳转异常问题。解决的思路是:$host:port
详细如下:
该问题是最先发现的,由于之前对nginx不是特别的熟悉所以该问题是个入门级别的:
? 1 2 3 4 5
- java-17-在一个字符串中找到第一个只出现一次的字符
bylijinnan
java
public class FirstShowOnlyOnceElement {
/**Q17.在一个字符串中找到第一个只出现一次的字符。如输入abaccdeff,则输出b
* 1.int[] count:count[i]表示i对应字符出现的次数
* 2.将26个英文字母映射:a-z <--> 0-25
* 3.假设全部字母都是小写
*/
pu
- mongoDB 复制集
开窍的石头
mongodb
mongo的复制集就像mysql的主从数据库,当你往其中的主复制集(primary)写数据的时候,副复制集(secondary)会自动同步主复制集(Primary)的数据,当主复制集挂掉以后其中的一个副复制集会自动成为主复制集。提供服务器的可用性。和防止当机问题
mo
- [宇宙与天文]宇宙时代的经济学
comsci
经济
宇宙尺度的交通工具一般都体型巨大,造价高昂。。。。。
在宇宙中进行航行,近程采用反作用力类型的发动机,需要消耗少量矿石燃料,中远程航行要采用量子或者聚变反应堆发动机,进行超空间跳跃,要消耗大量高纯度水晶体能源
以目前地球上国家的经济发展水平来讲,
- Git忽略文件
Cwind
git
有很多文件不必使用git管理。例如Eclipse或其他IDE生成的项目文件,编译生成的各种目标或临时文件等。使用git status时,会在Untracked files里面看到这些文件列表,在一次需要添加的文件比较多时(使用git add . / git add -u),会把这些所有的未跟踪文件添加进索引。
==== ==== ==== 一些牢骚
- MySQL连接数据库的必须配置
dashuaifu
mysql连接数据库配置
MySQL连接数据库的必须配置
1.driverClass:com.mysql.jdbc.Driver
2.jdbcUrl:jdbc:mysql://localhost:3306/dbname
3.user:username
4.password:password
其中1是驱动名;2是url,这里的‘dbna
- 一生要养成的60个习惯
dcj3sjt126com
习惯
一生要养成的60个习惯
第1篇 让你更受大家欢迎的习惯
1 守时,不准时赴约,让别人等,会失去很多机会。
如何做到:
①该起床时就起床,
②养成任何事情都提前15分钟的习惯。
③带本可以随时阅读的书,如果早了就拿出来读读。
④有条理,生活没条理最容易耽误时间。
⑤提前计划:将重要和不重要的事情岔开。
⑥今天就准备好明天要穿的衣服。
⑦按时睡觉,这会让按时起床更容易。
2 注重
- [介绍]Yii 是什么
dcj3sjt126com
PHPyii2
Yii 是一个高性能,基于组件的 PHP 框架,用于快速开发现代 Web 应用程序。名字 Yii (读作 易)在中文里有“极致简单与不断演变”两重含义,也可看作 Yes It Is! 的缩写。
Yii 最适合做什么?
Yii 是一个通用的 Web 编程框架,即可以用于开发各种用 PHP 构建的 Web 应用。因为基于组件的框架结构和设计精巧的缓存支持,它特别适合开发大型应
- Linux SSH常用总结
eksliang
linux sshSSHD
转载请出自出处:http://eksliang.iteye.com/blog/2186931 一、连接到远程主机
格式:
ssh name@remoteserver
例如:
ssh
[email protected]
二、连接到远程主机指定的端口
格式:
ssh name@remoteserver -p 22
例如:
ssh i
- 快速上传头像到服务端工具类FaceUtil
gundumw100
android
快速迭代用
import java.io.DataOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOExceptio
- jQuery入门之怎么使用
ini
JavaScripthtmljqueryWebcss
jQuery的强大我何问起(个人主页:hovertree.com)就不用多说了,那么怎么使用jQuery呢?
首先,下载jquery。下载地址:http://hovertree.com/hvtart/bjae/b8627323101a4994.htm,一个是压缩版本,一个是未压缩版本,如果在开发测试阶段,可以使用未压缩版本,实际应用一般使用压缩版本(min)。然后就在页面上引用。
- 带filter的hbase查询优化
kane_xie
查询优化hbaseRandomRowFilter
问题描述
hbase scan数据缓慢,server端出现LeaseException。hbase写入缓慢。
问题原因
直接原因是: hbase client端每次和regionserver交互的时候,都会在服务器端生成一个Lease,Lease的有效期由参数hbase.regionserver.lease.period确定。如果hbase scan需
- java设计模式-单例模式
men4661273
java单例枚举反射IOC
单例模式1,饿汉模式
//饿汉式单例类.在类初始化时,已经自行实例化
public class Singleton1 {
//私有的默认构造函数
private Singleton1() {}
//已经自行实例化
private static final Singleton1 singl
- mongodb 查询某一天所有信息的3种方法,根据日期查询
qiaolevip
每天进步一点点学习永无止境mongodb纵观千象
// mongodb的查询真让人难以琢磨,就查询单天信息,都需要花费一番功夫才行。
// 第一种方式:
coll.aggregate([
{$project:{sendDate: {$substr: ['$sendTime', 0, 10]}, sendTime: 1, content:1}},
{$match:{sendDate: '2015-
- 二维数组转换成JSON
tangqi609567707
java二维数组json
原文出处:http://blog.csdn.net/springsen/article/details/7833596
public class Demo {
public static void main(String[] args) { String[][] blogL
- erlang supervisor
wudixiaotie
erlang
定义supervisor时,如果是监控celuesimple_one_for_one则删除children的时候就用supervisor:terminate_child (SupModuleName, ChildPid),如果shutdown策略选择的是brutal_kill,那么supervisor会调用exit(ChildPid, kill),这样的话如果Child的behavior是gen_