RetinaFace论文解读 --- RetinaFace: Single-stage Dense Face Localisation in the Wild
论文:https://arxiv.org/pdf/1905.00641.pdf
代码:https://github.com/deepinsight/insightface/tree/master/RetinaFace
Pytorch复现:https://github.com/biubug6/Pytorch_Retinaface
RetinaFace于19年5月份出现,当时取得了state-of-the-art,可以说是目前开源的最强人脸检测算法,它主要在以下五个方面作出贡献:
-
在single-stage设计的基础上,提出了一种新的基于像素级的人脸定位方法RetinaFace,该方法采用多任务学习策略,同时预测人脸评分、人脸框、五个人脸关键点以及每个人脸像素的三维位置和对应关系。
-
在WILDER FACE hard子集上,RetinaFace的性能比目前the state of the art的two-stage方法(ISRN)的AP高出1.1% (AP等于91.4%)。
-
在IJB-C数据集上,RetinaFace有助于提高ArcFace的验证精度(FAR=1e-6时TAR等于89:59%)。这表明更好的人脸定位可以显著提高人脸识别。
-
通过使用轻量级backbone网络,RetinaFace可以在VGA分辨率的图片上实时运行
-
已经发布了额外的注释和代码,以方便将来的研究
RetinaFace
与一般的目标检测不同,人脸检测具有较小的比例变化(从1:1到1:1.5),但更大的尺度变化(从几个像素到数千像素)。目前most state-of-the-art 的方法集中于single-stage设计,该设计密集采样人脸在特征金字塔上的位置和尺度,与two-stage方法相比,表现出良好的性能和更快的速度。在此基础上,我们改进了single-stage人脸检测框架,并利用强监督和自监督信号的多任务损失,提出了一种most state-of-the-art的密集人脸定位方法。RetinaFace的想法如图1所示。
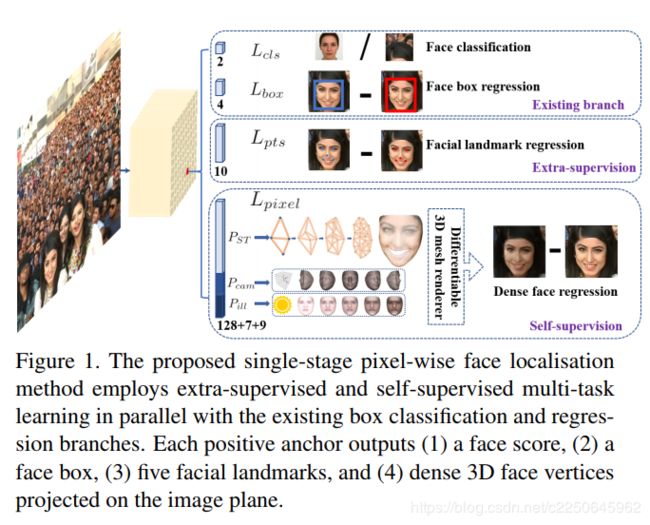
由上图可以看到,RetinaFace的detect head有四个并行的分支:人脸分类,框回归,关键点检测和人脸像素的三维位置和对应关系。
RetinaFace的大致结构如下图:

一共有四个模块,分别是Backbone,FPN,Context Module和Multi-task Loss。其中Multi-task Loss对应图1的四个并行分支Loss。
Implementation details
FPN
RetinaFace采用从P2到P6的特征金字塔层,其中P2到P5通过使用自顶向下和横向连接(如[28,29])计算相应的ResNet残差阶段(C2到C5)的输出。P6是在C5处通过一个步长2的3x3卷积计算得到到。C1-C5是在ImageNet-11k数据集上预先训练好的ResNet-152[21]分类网络,P6是用“Xavier”方法[17]随机初始化的。
Context Module
RetinaFace在五个特征金字塔层应用单独的上下文模块来提高 感受野并增加刚性上下文建模的能力。从2018年 WIDER Face 冠军方案中受到的启发, 我们也在横向连接和使用可变形卷积网络(DCN)的上下文模块中替换所有 3x3的卷积,进一步加强非刚性的上下文建模能力。
Multi-task Loss
对于任何训练的anchor i,RetinaFace的目标是最小化下面的多任务的 loss:
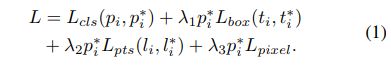
包含四个部分:
- 人脸分类loss Lcls(pi,pi*)。这里的pi是anchor i为人脸的预测概率,对于pi * 是1是positive anchor,0代表为negative anchor。分类loss Lcls采用softmax loss,即softmax loss在二分类的情况(人脸/非人脸)的应用。
- 人脸框回归loss,Lbox(ti,ti*),这里的ti={tx,ty,tw,th},ti * ={tx *,ty *,tw * ,th *}分别代表positive anchor相关的预测框和真实框(ground-truth box)的坐标。我们按照 Fast r-cnn的方法对回归框目标(中心坐标,宽和高)进行归一化,使用Lbox(ti,ti *)=R(ti-ti *),这里R 是 smooth-L1 Loss
- 人脸的landmark回归loss Lpts(li,li *),这里li={l x1,l y1,…l x5,l y5},li *={l x1 *,l y1 *,…l x5 *,l y5 *}代表预测的五个人脸关键点和基准点(ground-truth)。五个人脸关键点的回归也采用了基于anchor中心的目标归一化。
- Dense回归loss Lpixel。
loss调节参数 λ1-λ3 设置为0.25,0.1和0.01,这意味着在监督信号中,RetinaFace增加了边界框和关键点定位的重要性。
anchors设置
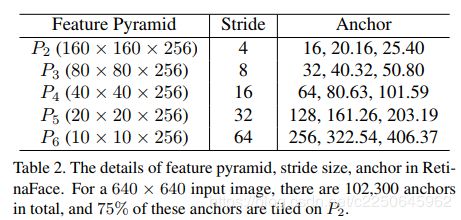
如上表所示,RetinaFace从P2到P6的特征金字塔级别上使用特定于比例的锚点,例如[56]。 在这里,P2旨在通过平铺小anchors来捕获微小的面部,但要花费更多的计算时间,并且要冒更多的误报风险。RetinaFace将scale step设置为2^(1/3),aspect ratio设置为1:1。输入图像大小为 640*640 , anchors可以 覆盖 从16x16 到 406x406的特征金字塔层。从五个下采样(4,8,16,32,64)的feature map平铺anchors,每个feature map中的点预测3个anchors,总共有(160 * 160 + 80 * 80+40 * 40+400+100) * 3 = 102300个anchors,其中75%来自P2。不过在代码中,只用了8,16,32这三个下采样层的输出feature map,且每个点只放两个anchors。
所以,对于640 * 640的输入,32,16,8的下采样输出,每个点的输出是【(1,4,20,20),(1,8,20,20),(1,20,20,20)】,【(1,4,40,40),(1,8,40,40),(1,20,40,40)】,【(1,4,80,80),(1,8,80,80),(1,20,80,80)】。
其中4,8,20分别代表一个点两个anchors的类别数(2 anchors * 2类),(2 anchors * 框的信息),(2 anchors * 5个关键点信息(一个点x,y))
数据增强
WIDER FACE训练集中大约 有 20% 的小人脸 , RetinaFace遵循 [68, 49 ) 并从原始图像随机crop方形patches并调整这些 patches到 640*640 产生更大的训练人脸。更具体地说,在原始图像的短边[0.3,1]之间随机裁剪正方形patches。对于crop边界上的人脸,如果人脸框的中心在crop patches内,则保持人脸框的重叠部分。除了随机裁剪,我们还通过0.5概率的随机水平翻转和光度颜色蒸馏来增加训练数据。
学习率调整
使用warmup learning 策略,学习速率从10e-3,在5个epoch后上升到10e-2,然后在第55和第68个epochs时除以10。训练过程在第80个epochs结束。
实验结果
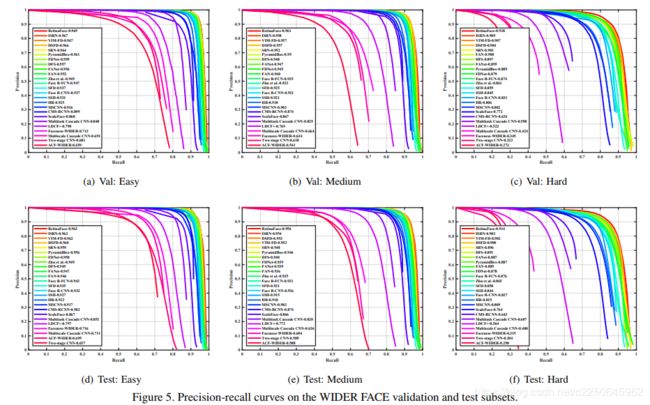
RetinaFace与其他24个stage-of-the-art的人脸检测算法对比。RetinaFace在所有的验证集和测试集都达到的最好的AP,在验证集上的AP是96.9%(easy),96.1%(Medium)和91.8%(hard)。在测试集的AP是96.3%,95.6%,91.4%.相比与当前最好的方法(Improved selective refinement network for face detection)在困难的数据集(包含大量的小人脸)的AP对比(91.4% vs 90.3%)。
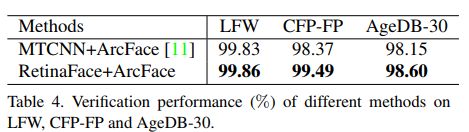
Retinaface是人脸识别得到更高的准确率。
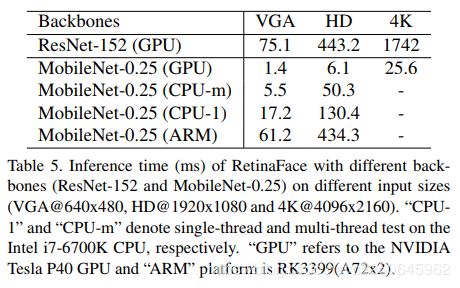
此外,使用轻量Mobilenet-0.25作为backbone,对于VGA可以在CPU上达到实时。
参考
https://mp.weixin.qq.com/s/vGAQ4OXv_jHQJECG27o2SQ
https://blog.csdn.net/TheDayIn_CSDN/article/details/95058236