/**
* Submit the job to the cluster and wait for it to finish.
* @param verbose print the progress to the user
* @return true if the job succeeded
* @throws IOException thrown if the communication with the
* JobTracker is lost
*/
public boolean waitForCompletion(boolean verbose ) throws IOException, InterruptedException, ClassNotFoundException {
if (state == JobState.DEFINE) {//状态是否是已定义 JobState.DEFINE 相当于还没有被占用,没有相同的 job 可以继续运行。在后面它提交 job 的时候,它会将这个状态置为JobState.RUNNING(正在运行)
submit();//提交 进入
}//提交完成之后要打印一些完成的信息
if (verbose) {
monitorAndPrintJob();
} else {
// get the completion poll interval from the client.
int completionPollIntervalMillis =
Job.getCompletionPollInterval(cluster.getConf());
while (!isComplete()) {
try {
Thread.sleep(completionPollIntervalMillis);
} catch (InterruptedException ie) {
}
}
}
return isSuccessful();
}
/**
* Internal method for submitting jobs to the system.
*
*
The job submission process involves:
*
*
* Checking the input and output specifications of the job.
*
*
* Computing the {@link InputSplit}s for the job.
*
*
* Setup the requisite accounting information for the
* {@link DistributedCache} of the job, if necessary.
*
*
* Copying the job's jar and configuration to the map-reduce system
* directory on the distributed file-system.
*
*
* Submitting the job to the JobTracker and optionally
* monitoring it's status.
*
*
* @param job the configuration to submit
* @param cluster the handle to the Cluster
* @throws ClassNotFoundException
* @throws InterruptedException
* @throws IOException
*/
JobStatus submitJobInternal(Job job, Cluster cluster)
throws ClassNotFoundException, InterruptedException, IOException {
//validate the jobs output specs //校验输出的路径 校验的很早,还没做什么事情之前都开始校验了
checkSpecs(job);//进入
Configuration conf = job.getConfiguration(); //配置信息 八个文件 (.xml)
addMRFrameworkToDistributedCache(conf);//缓存的处理
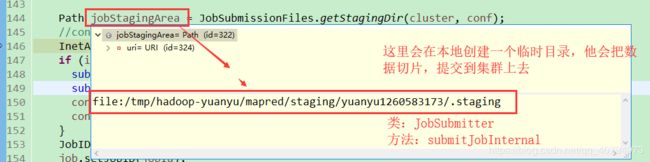
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);//每次提交会创建一个临时路径,一旦提交完就会删除参数的数据 电脑上直接 收拾 tmp 即可找到
//configure the command line options correctly on the submitting dfs
InetAddress ip = InetAddress.getLocalHost();
if (ip != null) {
submitHostAddress = ip.getHostAddress();//网络 ip
submitHostName = ip.getHostName();
conf.set(MRJobConfig.JOB_SUBMITHOST,submitHostName);
conf.set(MRJobConfig.JOB_SUBMITHOSTADDR,submitHostAddress);
}
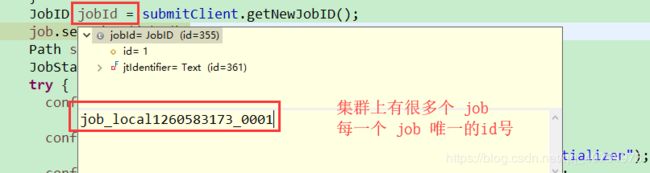
JobID jobId = submitClient.getNewJobID();//提交任务时的jobId,每个 job 提交任务的时候都会给你分配一个id
job.setJobID(jobId);
Path submitJobDir = new Path(jobStagingArea, jobId.toString());//提交的路径
JobStatus status = null;
try {
conf.set(MRJobConfig.USER_NAME,
UserGroupInformation.getCurrentUser().getShortUserName());
conf.set("hadoop.http.filter.initializers",
"org.apache.hadoop.yarn.server.webproxy.amfilter.AmFilterInitializer");
conf.set(MRJobConfig.MAPREDUCE_JOB_DIR, submitJobDir.toString());
LOG.debug("Configuring job " + jobId + " with " + submitJobDir
+ " as the submit dir");
// get delegation token for the dir
TokenCache.obtainTokensForNamenodes(job.getCredentials(),
new Path[] { submitJobDir }, conf);
populateTokenCache(conf, job.getCredentials());
// generate a secret to authenticate shuffle transfers
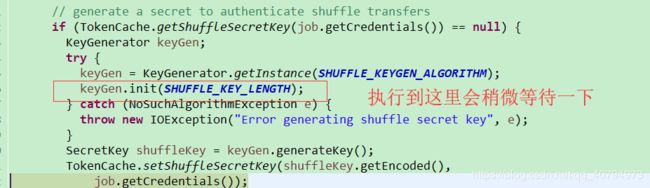
if (TokenCache.getShuffleSecretKey(job.getCredentials()) == null) {
KeyGenerator keyGen;
try {
keyGen = KeyGenerator.getInstance(SHUFFLE_KEYGEN_ALGORITHM);
keyGen.init(SHUFFLE_KEY_LENGTH);
} catch (NoSuchAlgorithmException e) {
throw new IOException("Error generating shuffle secret key", e);
}
SecretKey shuffleKey = keyGen.generateKey();
TokenCache.setShuffleSecretKey(shuffleKey.getEncoded(),
job.getCredentials());
}
if (CryptoUtils.isEncryptedSpillEnabled(conf)) {
conf.setInt(MRJobConfig.MR_AM_MAX_ATTEMPTS, 1);
LOG.warn("Max job attempts set to 1 since encrypted intermediate" +
"data spill is enabled");
}
copyAndConfigureFiles(job, submitJobDir);//提交一些文件的信息 进入 (提前打断点)
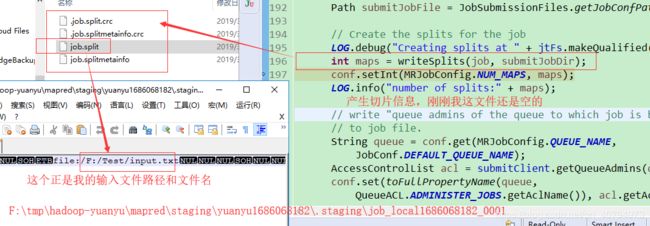
Path submitJobFile = JobSubmissionFiles.getJobConfPath(submitJobDir);
// Create the splits for the job
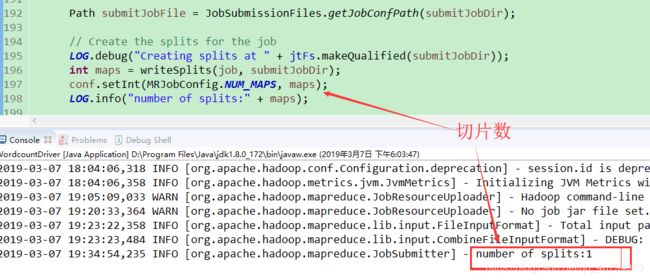
LOG.debug("Creating splits at " + jtFs.makeQualified(submitJobDir));
int maps = writeSplits(job, submitJobDir);//所有的切片信息 提交到 submitJobDir 路径上
conf.setInt(MRJobConfig.NUM_MAPS, maps);
LOG.info("number of splits:" + maps);
// write "queue admins of the queue to which job is being submitted"
// to job file.
String queue = conf.get(MRJobConfig.QUEUE_NAME,
JobConf.DEFAULT_QUEUE_NAME);
AccessControlList acl = submitClient.getQueueAdmins(queue);
conf.set(toFullPropertyName(queue,
QueueACL.ADMINISTER_JOBS.getAclName()), acl.getAclString());
// removing jobtoken referrals before copying the jobconf to HDFS
// as the tasks don't need this setting, actually they may break
// because of it if present as the referral will point to a
// different job.
TokenCache.cleanUpTokenReferral(conf);
if (conf.getBoolean(
MRJobConfig.JOB_TOKEN_TRACKING_IDS_ENABLED,
MRJobConfig.DEFAULT_JOB_TOKEN_TRACKING_IDS_ENABLED)) {
// Add HDFS tracking ids
ArrayList trackingIds = new ArrayList();
for (Token t :
job.getCredentials().getAllTokens()) {
trackingIds.add(t.decodeIdentifier().getTrackingId());
}
conf.setStrings(MRJobConfig.JOB_TOKEN_TRACKING_IDS,
trackingIds.toArray(new String[trackingIds.size()]));
}
// Set reservation info if it exists
ReservationId reservationId = job.getReservationId();
if (reservationId != null) {
conf.set(MRJobConfig.RESERVATION_ID, reservationId.toString());
}
// Write job file to submit dir
writeConf(conf, submitJobFile);//到你的提交目录 进入
//
// Now, actually submit the job (using the submit name)
//
printTokens(jobId, job.getCredentials());
status = submitClient.submitJob(
jobId, submitJobDir.toString(), job.getCredentials());
if (status != null) {
return status;
} else {
throw new IOException("Could not launch job");
}
} finally {
if (status == null) {
LOG.info("Cleaning up the staging area " + submitJobDir);
if (jtFs != null && submitJobDir != null)
jtFs.delete(submitJobDir, true);
}
}
}
public void checkOutputSpecs(JobContext job
) throws FileAlreadyExistsException, IOException{
// Ensure that the output directory is set and not already there //确认输出路径已经被设置好,并且不存在
Path outDir = getOutputPath(job);
if (outDir == null) {
throw new InvalidJobConfException("Output directory not set.");
}
// get delegation token for outDir's file system
TokenCache.obtainTokensForNamenodes(job.getCredentials(),
new Path[] { outDir }, job.getConfiguration());
if (outDir.getFileSystem(job.getConfiguration()).exists(outDir)) {
throw new FileAlreadyExistsException("Output directory " + outDir +
" already exists"); //路径存在会报异常
}
}
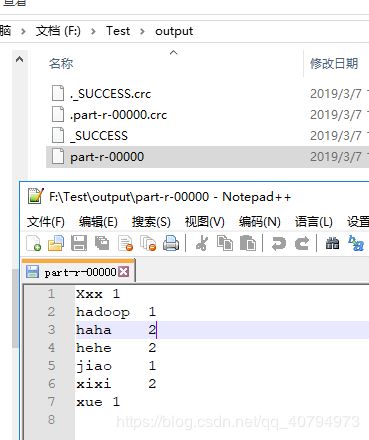
2019-03-07 16:08:39,711 INFO [org.apache.hadoop.conf.Configuration.deprecation] - session.id is deprecated. Instead, use dfs.metrics.session-id 2019-03-07 16:08:39,713 INFO [org.apache.hadoop.metrics.jvm.JvmMetrics] - Initializing JVM Metrics with processName=JobTracker, sessionId= Exception in thread "main" org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory file:/F:/Test/output already exists at org.apache.hadoop.mapreduce.lib.output.FileOutputFormat.checkOutputSpecs(FileOutputFormat.java:146) at org.apache.hadoop.mapreduce.JobSubmitter.checkSpecs(JobSubmitter.java:266) at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:139) at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1290) at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1287) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1657) at org.apache.hadoop.mapreduce.Job.submit(Job.java:1287) at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1308) at com.atguigu.mapreduce.wordcountDemo.WordcountDriver.main(WordcountDriver.java:52)
/**
* Internal method for submitting jobs to the system.
*
*
The job submission process involves:
*
*
* Checking the input and output specifications of the job.
*
*
* Computing the {@link InputSplit}s for the job.
*
*
* Setup the requisite accounting information for the
* {@link DistributedCache} of the job, if necessary.
*
*
* Copying the job's jar and configuration to the map-reduce system
* directory on the distributed file-system.
*
*
* Submitting the job to the JobTracker and optionally
* monitoring it's status.
*
*
* @param job the configuration to submit
* @param cluster the handle to the Cluster
* @throws ClassNotFoundException
* @throws InterruptedException
* @throws IOException
*/
JobStatus submitJobInternal(Job job, Cluster cluster)
throws ClassNotFoundException, InterruptedException, IOException {
//validate the jobs output specs
checkSpecs(job);
Configuration conf = job.getConfiguration();
addMRFrameworkToDistributedCache(conf);
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
//configure the command line options correctly on the submitting dfs
InetAddress ip = InetAddress.getLocalHost();
if (ip != null) {
submitHostAddress = ip.getHostAddress();
submitHostName = ip.getHostName();
conf.set(MRJobConfig.JOB_SUBMITHOST,submitHostName);
conf.set(MRJobConfig.JOB_SUBMITHOSTADDR,submitHostAddress);
}
JobID jobId = submitClient.getNewJobID();
job.setJobID(jobId);
Path submitJobDir = new Path(jobStagingArea, jobId.toString());
JobStatus status = null;
try {
conf.set(MRJobConfig.USER_NAME,
UserGroupInformation.getCurrentUser().getShortUserName());
conf.set("hadoop.http.filter.initializers",
"org.apache.hadoop.yarn.server.webproxy.amfilter.AmFilterInitializer");
conf.set(MRJobConfig.MAPREDUCE_JOB_DIR, submitJobDir.toString());
LOG.debug("Configuring job " + jobId + " with " + submitJobDir
+ " as the submit dir");
// get delegation token for the dir
TokenCache.obtainTokensForNamenodes(job.getCredentials(),
new Path[] { submitJobDir }, conf);
populateTokenCache(conf, job.getCredentials());
// generate a secret to authenticate shuffle transfers
if (TokenCache.getShuffleSecretKey(job.getCredentials()) == null) {
KeyGenerator keyGen;
try {
keyGen = KeyGenerator.getInstance(SHUFFLE_KEYGEN_ALGORITHM);
keyGen.init(SHUFFLE_KEY_LENGTH);
} catch (NoSuchAlgorithmException e) {
throw new IOException("Error generating shuffle secret key", e);
}
SecretKey shuffleKey = keyGen.generateKey();
TokenCache.setShuffleSecretKey(shuffleKey.getEncoded(),
job.getCredentials());
}
if (CryptoUtils.isEncryptedSpillEnabled(conf)) {
conf.setInt(MRJobConfig.MR_AM_MAX_ATTEMPTS, 1);
LOG.warn("Max job attempts set to 1 since encrypted intermediate" +
"data spill is enabled");
}
copyAndConfigureFiles(job, submitJobDir); //!! 提前打断点 进入方法
Path submitJobFile = JobSubmissionFiles.getJobConfPath(submitJobDir);
// Create the splits for the job
LOG.debug("Creating splits at " + jtFs.makeQualified(submitJobDir));
int maps = writeSplits(job, submitJobDir);
conf.setInt(MRJobConfig.NUM_MAPS, maps);
LOG.info("number of splits:" + maps);
// write "queue admins of the queue to which job is being submitted"
// to job file.
String queue = conf.get(MRJobConfig.QUEUE_NAME,
JobConf.DEFAULT_QUEUE_NAME);
AccessControlList acl = submitClient.getQueueAdmins(queue);
conf.set(toFullPropertyName(queue,
QueueACL.ADMINISTER_JOBS.getAclName()), acl.getAclString());
// removing jobtoken referrals before copying the jobconf to HDFS
// as the tasks don't need this setting, actually they may break
// because of it if present as the referral will point to a
// different job.
TokenCache.cleanUpTokenReferral(conf);
if (conf.getBoolean(
MRJobConfig.JOB_TOKEN_TRACKING_IDS_ENABLED,
MRJobConfig.DEFAULT_JOB_TOKEN_TRACKING_IDS_ENABLED)) {
// Add HDFS tracking ids
ArrayList trackingIds = new ArrayList();
for (Token t :
job.getCredentials().getAllTokens()) {
trackingIds.add(t.decodeIdentifier().getTrackingId());
}
conf.setStrings(MRJobConfig.JOB_TOKEN_TRACKING_IDS,
trackingIds.toArray(new String[trackingIds.size()]));
}
// Set reservation info if it exists
ReservationId reservationId = job.getReservationId();
if (reservationId != null) {
conf.set(MRJobConfig.RESERVATION_ID, reservationId.toString());
}
// Write job file to submit dir
writeConf(conf, submitJobFile);
//
// Now, actually submit the job (using the submit name)
//
printTokens(jobId, job.getCredentials());
status = submitClient.submitJob(
jobId, submitJobDir.toString(), job.getCredentials());
if (status != null) {
return status;
} else {
throw new IOException("Could not launch job");
}
} finally {
if (status == null) {
LOG.info("Cleaning up the staging area " + submitJobDir);
if (jtFs != null && submitJobDir != null)
jtFs.delete(submitJobDir, true);
}
}
}
/**
JobSubbmitter.class
* configure the jobconf of the user with the command line options of
* -libjars, -files, -archives.
* @param job
* @throws IOException
*/
private void copyAndConfigureFiles(Job job, Path jobSubmitDir)
throws IOException {
JobResourceUploader rUploader = new JobResourceUploader(jtFs);
rUploader.uploadFiles(job, jobSubmitDir); //进入 (提前打断点)
// Get the working directory. If not set, sets it to filesystem working dir
// This code has been added so that working directory reset before running
// the job. This is necessary for backward compatibility as other systems
// might use the public API JobConf#setWorkingDirectory to reset the working
// directory.
job.getWorkingDirectory();
}
/**
JobResourceUploader
* Upload and configure files, libjars, jobjars, and archives pertaining to
* the passed job.
*
* @param job the job containing the files to be uploaded
* @param submitJobDir the submission directory of the job
* @throws IOException
*/
public void uploadFiles(Job job, Path submitJobDir) throws IOException {
Configuration conf = job.getConfiguration();
short replication =
(short) conf.getInt(Job.SUBMIT_REPLICATION,
Job.DEFAULT_SUBMIT_REPLICATION);
if (!(conf.getBoolean(Job.USED_GENERIC_PARSER, false))) {
LOG.warn("Hadoop command-line option parsing not performed. "
+ "Implement the Tool interface and execute your application "
+ "with ToolRunner to remedy this.");
}
// get all the command line arguments passed in by the user conf
String files = conf.get("tmpfiles");
String libjars = conf.get("tmpjars");
String archives = conf.get("tmparchives");
String jobJar = job.getJar();
//
// Figure out what fs the JobTracker is using. Copy the
// job to it, under a temporary name. This allows DFS to work,
// and under the local fs also provides UNIX-like object loading
// semantics. (that is, if the job file is deleted right after
// submission, we can still run the submission to completion)
//
// Create a number of filenames in the JobTracker's fs namespace
LOG.debug("default FileSystem: " + jtFs.getUri());
if (jtFs.exists(submitJobDir)) {
throw new IOException("Not submitting job. Job directory " + submitJobDir
+ " already exists!! This is unexpected.Please check what's there in"
+ " that directory");
}
submitJobDir = jtFs.makeQualified(submitJobDir);
submitJobDir = new Path(submitJobDir.toUri().getPath());
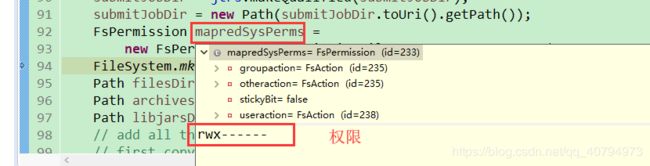
FsPermission mapredSysPerms =
new FsPermission(JobSubmissionFiles.JOB_DIR_PERMISSION);
FileSystem.mkdirs(jtFs, submitJobDir, mapredSysPerms);
Path filesDir = JobSubmissionFiles.getJobDistCacheFiles(submitJobDir);
Path archivesDir = JobSubmissionFiles.getJobDistCacheArchives(submitJobDir);
Path libjarsDir = JobSubmissionFiles.getJobDistCacheLibjars(submitJobDir);
// add all the command line files/ jars and archive
// first copy them to jobtrackers filesystem
if (files != null) {
FileSystem.mkdirs(jtFs, filesDir, mapredSysPerms);
String[] fileArr = files.split(",");
for (String tmpFile : fileArr) {
URI tmpURI = null;
try {
tmpURI = new URI(tmpFile);
} catch (URISyntaxException e) {
throw new IllegalArgumentException(e);
}
Path tmp = new Path(tmpURI);
Path newPath = copyRemoteFiles(filesDir, tmp, conf, replication);
try {
URI pathURI = getPathURI(newPath, tmpURI.getFragment());
DistributedCache.addCacheFile(pathURI, conf);
} catch (URISyntaxException ue) {
// should not throw a uri exception
throw new IOException("Failed to create uri for " + tmpFile, ue);
}
}
}
if (libjars != null) {
FileSystem.mkdirs(jtFs, libjarsDir, mapredSysPerms);
String[] libjarsArr = libjars.split(",");
for (String tmpjars : libjarsArr) {
Path tmp = new Path(tmpjars);
Path newPath = copyRemoteFiles(libjarsDir, tmp, conf, replication);
DistributedCache.addFileToClassPath(
new Path(newPath.toUri().getPath()), conf, jtFs);
}
}
if (archives != null) {
FileSystem.mkdirs(jtFs, archivesDir, mapredSysPerms);
String[] archivesArr = archives.split(",");
for (String tmpArchives : archivesArr) {
URI tmpURI;
try {
tmpURI = new URI(tmpArchives);
} catch (URISyntaxException e) {
throw new IllegalArgumentException(e);
}
Path tmp = new Path(tmpURI);
Path newPath = copyRemoteFiles(archivesDir, tmp, conf, replication);
try {
URI pathURI = getPathURI(newPath, tmpURI.getFragment());
DistributedCache.addCacheArchive(pathURI, conf);
} catch (URISyntaxException ue) {
// should not throw an uri excpetion
throw new IOException("Failed to create uri for " + tmpArchives, ue);
}
}
}
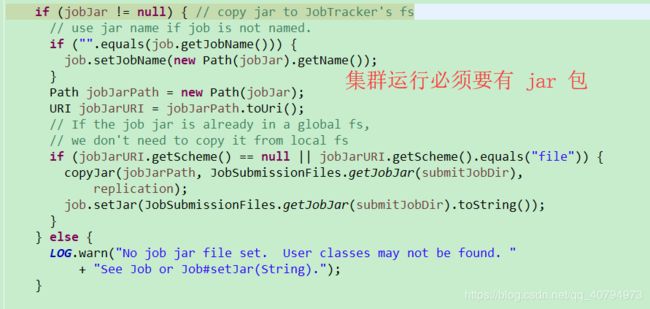
if (jobJar != null) { // copy jar to JobTracker's fs
// use jar name if job is not named.
if ("".equals(job.getJobName())) {
job.setJobName(new Path(jobJar).getName());
}
Path jobJarPath = new Path(jobJar);
URI jobJarURI = jobJarPath.toUri();
// If the job jar is already in a global fs,
// we don't need to copy it from local fs
if (jobJarURI.getScheme() == null || jobJarURI.getScheme().equals("file")) {
copyJar(jobJarPath, JobSubmissionFiles.getJobJar(submitJobDir),
replication);
job.setJar(JobSubmissionFiles.getJobJar(submitJobDir).toString());
}
} else {
LOG.warn("No job jar file set. User classes may not be found. "
+ "See Job or Job#setJar(String).");
}
addLog4jToDistributedCache(job, submitJobDir);
// set the timestamps of the archives and files
// set the public/private visibility of the archives and files
ClientDistributedCacheManager.determineTimestampsAndCacheVisibilities(conf);
// get DelegationToken for cached file
ClientDistributedCacheManager.getDelegationTokens(conf,
job.getCredentials());
}
/**
* Internal method for submitting jobs to the system.
*
*
The job submission process involves:
*
*
* Checking the input and output specifications of the job.
*
*
* Computing the {@link InputSplit}s for the job.
*
*
* Setup the requisite accounting information for the
* {@link DistributedCache} of the job, if necessary.
*
*
* Copying the job's jar and configuration to the map-reduce system
* directory on the distributed file-system.
*
*
* Submitting the job to the JobTracker and optionally
* monitoring it's status.
*
*
* @param job the configuration to submit
* @param cluster the handle to the Cluster
* @throws ClassNotFoundException
* @throws InterruptedException
* @throws IOException
*/
JobStatus submitJobInternal(Job job, Cluster cluster)
throws ClassNotFoundException, InterruptedException, IOException {
//validate the jobs output specs
checkSpecs(job);
Configuration conf = job.getConfiguration();
addMRFrameworkToDistributedCache(conf);
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
//configure the command line options correctly on the submitting dfs
InetAddress ip = InetAddress.getLocalHost();
if (ip != null) {
submitHostAddress = ip.getHostAddress();
submitHostName = ip.getHostName();
conf.set(MRJobConfig.JOB_SUBMITHOST,submitHostName);
conf.set(MRJobConfig.JOB_SUBMITHOSTADDR,submitHostAddress);
}
JobID jobId = submitClient.getNewJobID();
job.setJobID(jobId);
Path submitJobDir = new Path(jobStagingArea, jobId.toString());
JobStatus status = null;
try {
conf.set(MRJobConfig.USER_NAME,
UserGroupInformation.getCurrentUser().getShortUserName());
conf.set("hadoop.http.filter.initializers",
"org.apache.hadoop.yarn.server.webproxy.amfilter.AmFilterInitializer");
conf.set(MRJobConfig.MAPREDUCE_JOB_DIR, submitJobDir.toString());
LOG.debug("Configuring job " + jobId + " with " + submitJobDir
+ " as the submit dir");
// get delegation token for the dir
TokenCache.obtainTokensForNamenodes(job.getCredentials(),
new Path[] { submitJobDir }, conf);
populateTokenCache(conf, job.getCredentials());
// generate a secret to authenticate shuffle transfers
if (TokenCache.getShuffleSecretKey(job.getCredentials()) == null) {
KeyGenerator keyGen;
try {
keyGen = KeyGenerator.getInstance(SHUFFLE_KEYGEN_ALGORITHM);
keyGen.init(SHUFFLE_KEY_LENGTH);
} catch (NoSuchAlgorithmException e) {
throw new IOException("Error generating shuffle secret key", e);
}
SecretKey shuffleKey = keyGen.generateKey();
TokenCache.setShuffleSecretKey(shuffleKey.getEncoded(),
job.getCredentials());
}
if (CryptoUtils.isEncryptedSpillEnabled(conf)) {
conf.setInt(MRJobConfig.MR_AM_MAX_ATTEMPTS, 1);
LOG.warn("Max job attempts set to 1 since encrypted intermediate" +
"data spill is enabled");
}
copyAndConfigureFiles(job, submitJobDir);
Path submitJobFile = JobSubmissionFiles.getJobConfPath(submitJobDir);
// Create the splits for the job
LOG.debug("Creating splits at " + jtFs.makeQualified(submitJobDir));
int maps = writeSplits(job, submitJobDir);
conf.setInt(MRJobConfig.NUM_MAPS, maps);
LOG.info("number of splits:" + maps);
// write "queue admins of the queue to which job is being submitted"
// to job file.
String queue = conf.get(MRJobConfig.QUEUE_NAME,
JobConf.DEFAULT_QUEUE_NAME);
AccessControlList acl = submitClient.getQueueAdmins(queue);
conf.set(toFullPropertyName(queue,
QueueACL.ADMINISTER_JOBS.getAclName()), acl.getAclString());
// removing jobtoken referrals before copying the jobconf to HDFS
// as the tasks don't need this setting, actually they may break
// because of it if present as the referral will point to a
// different job.
TokenCache.cleanUpTokenReferral(conf);
if (conf.getBoolean(
MRJobConfig.JOB_TOKEN_TRACKING_IDS_ENABLED,
MRJobConfig.DEFAULT_JOB_TOKEN_TRACKING_IDS_ENABLED)) {
// Add HDFS tracking ids
ArrayList trackingIds = new ArrayList();
for (Token t :
job.getCredentials().getAllTokens()) {
trackingIds.add(t.decodeIdentifier().getTrackingId());
}
conf.setStrings(MRJobConfig.JOB_TOKEN_TRACKING_IDS,
trackingIds.toArray(new String[trackingIds.size()]));
}
// Set reservation info if it exists
ReservationId reservationId = job.getReservationId();
if (reservationId != null) {
conf.set(MRJobConfig.RESERVATION_ID, reservationId.toString());
}
// Write job file to submit dir
writeConf(conf, submitJobFile);
//
// Now, actually submit the job (using the submit name)
//
printTokens(jobId, job.getCredentials());
status = submitClient.submitJob(
jobId, submitJobDir.toString(), job.getCredentials());
if (status != null) {
return status;
} else {
throw new IOException("Could not launch job");
}
} finally {
if (status == null) {
LOG.info("Cleaning up the staging area " + submitJobDir);
if (jtFs != null && submitJobDir != null)
jtFs.delete(submitJobDir, true);
}
}
}
// 6)提交Job,返回提交状态 status = submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials());
Job提交流程源码和切片源码详解
写完mr(job) 如何提交到集群上,这一段过程它执行了那些
1、数据块:Block是HDFS物理上把数据分成一块一块。
2、数据切片:数据切片只是在逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储。
3、一个 Job 的Map阶段并行度由客户端在提交Job时的切片数决定(有多少个切片就有多少个 MapTask)
// 1 获取配置信息以及封装任务
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);//获取实例对象
job.waitForCompletion(true);//提交 (打断点)
/**
* Submit the job to the cluster and wait for it to finish.
* @param verbose print the progress to the user
* @return true if the job succeeded
* @throws IOException thrown if the communication with the
* JobTracker is lost
*/
public boolean waitForCompletion(boolean verbose ) throws IOException, InterruptedException, ClassNotFoundException {
if (state == JobState.DEFINE) {//状态是否是已定义 JobState.DEFINE 相当于还没有被占用,没有相同的 job 可以继续运行。在后面它提交 job 的时候,它会将这个状态置为JobState.RUNNING(正在运行)
submit();//提交 进入
}//提交完成之后要打印一些完成的信息
if (verbose) {
monitorAndPrintJob();
} else {
// get the completion poll interval from the client.
int completionPollIntervalMillis =
Job.getCompletionPollInterval(cluster.getConf());
while (!isComplete()) {
try {
Thread.sleep(completionPollIntervalMillis);
} catch (InterruptedException ie) {
}
}
}
return isSuccessful();
}
//打印的信息
File System Counters
FILE: Number of bytes read=712
FILE: Number of bytes written=562435
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
Map-Reduce Framework
Map input records=7
Map output records=10
Map output bytes=95
Map output materialized bytes=121
Input split bytes=115
Combine input records=0
Combine output records=0
Reduce input groups=7
Reduce shuffle bytes=121
Reduce input records=10
Reduce output records=7
Spilled Records=20
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=0
Total committed heap usage (bytes)=514850816
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=66
/**
* Submit the job to the cluster and return immediately.
* @throws IOException
*/
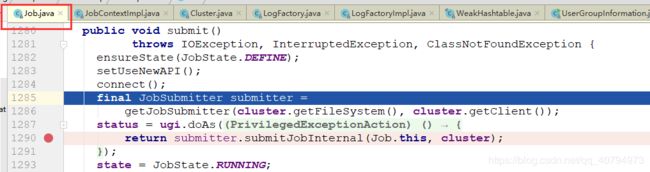
public void submit() throws IOException, InterruptedException, ClassNotFoundException {
ensureState(JobState.DEFINE);//判断状态
setUseNewAPI();//让你使用新 API
connect();//网络连接
final JobSubmitter submitter = getJobSubmitter(cluster.getFileSystem(), cluster.getClient());
status = ugi.doAs(new PrivilegedExceptionAction() {
public JobStatus run() throws IOException, InterruptedException, ClassNotFoundException {
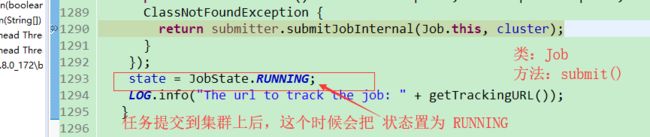
return submitter.submitJobInternal(Job.this, cluster);//提交 job 的一些详细信息 (打断点)
}
});
state = JobState.RUNNING;
LOG.info("The url to track the job: " + getTrackingURL());
}
//抛出异常
private void ensureState(JobState state) throws IllegalStateException {
if (state != this.state) {
throw new IllegalStateException("Job in state "+ this.state + " instead of " + state);//job 在什么状态
}
if (state == JobState.RUNNING && cluster == null) {
throw new IllegalStateException ("Job in state " + this.state + ", but it isn't attached to any job tracker!");//job 的状态
}
}
//处理老的 API
//把老的API"翻译"成新的 API,匹配兼容性
/**
* Default to the new APIs unless they are explicitly set or the old mapper or
* reduce attributes are used.
* @throws IOException if the configuration is inconsistant
*/
private void setUseNewAPI() throws IOException {
int numReduces = conf.getNumReduceTasks();
String oldMapperClass = "mapred.mapper.class";
String oldReduceClass = "mapred.reducer.class";
conf.setBooleanIfUnset("mapred.mapper.new-api",
conf.get(oldMapperClass) == null);
if (conf.getUseNewMapper()) {
String mode = "new map API";
ensureNotSet("mapred.input.format.class", mode);
ensureNotSet(oldMapperClass, mode);
if (numReduces != 0) {
ensureNotSet("mapred.partitioner.class", mode);
} else {
ensureNotSet("mapred.output.format.class", mode);
}
} else {
String mode = "map compatability";
ensureNotSet(INPUT_FORMAT_CLASS_ATTR, mode);
ensureNotSet(MAP_CLASS_ATTR, mode);
if (numReduces != 0) {
ensureNotSet(PARTITIONER_CLASS_ATTR, mode);
} else {
ensureNotSet(OUTPUT_FORMAT_CLASS_ATTR, mode);
}
}
if (numReduces != 0) {
conf.setBooleanIfUnset("mapred.reducer.new-api",
conf.get(oldReduceClass) == null);
if (conf.getUseNewReducer()) {
String mode = "new reduce API";
ensureNotSet("mapred.output.format.class", mode);
ensureNotSet(oldReduceClass, mode);
} else {
String mode = "reduce compatability";
ensureNotSet(OUTPUT_FORMAT_CLASS_ATTR, mode);
ensureNotSet(REDUCE_CLASS_ATTR, mode);
}
}
}
//网络连接
//根据运行环境的不同创建不同的对象,本地创建LocalJobRunner 集群上创建的是yarnRunner
private synchronized void connect() throws IOException, InterruptedException, ClassNotFoundException {
if (cluster == null) {//cluster(集群) 集群为空,创建
cluster = ugi.doAs(new PrivilegedExceptionAction() {
public Cluster run() throws IOException, InterruptedException, ClassNotFoundException {
return new Cluster(getConfiguration());//
}
});
}
}
public Cluster(InetSocketAddress jobTrackAddr, Configuration conf) throws IOException { (打断点)
this.conf = conf;
this.ugi = UserGroupInformation.getCurrentUser();
initialize(jobTrackAddr, conf);//conf 就是 Hadoop etc/hadoop/ 里面的各种配置文件(如:yarn-site.xml) 进入(打断点)
}
//该方法做主要的作用就是判断你连接的是 Yarn 还是本地,根据环境的不同创建的对象也不同
private void initialize(InetSocketAddress jobTrackAddr, Configuration conf) throws IOException {
synchronized (frameworkLoader) { //加锁 (打断点)
for (ClientProtocolProvider provider : frameworkLoader) {
LOG.debug("Trying ClientProtocolProvider : "+ provider.getClass().getName());
ClientProtocol clientProtocol = null; //客户端的协议目前是空
try {
if (jobTrackAddr == null) {
clientProtocol = provider.create(conf);//创造一个客户端协议 根据运行的地方不同创建的协议也不同,如果是在本地运行创建的是LocalJobRunner 如果是Hadoop集群上运行创建的是 Yarn上的
} else {
clientProtocol = provider.create(jobTrackAddr, conf);
}
if (clientProtocol != null) {
clientProtocolProvider = provider;
client = clientProtocol;
LOG.debug("Picked " + provider.getClass().getName() + " as the ClientProtocolProvider");
break;
}
else {
LOG.debug("Cannot pick " + provider.getClass().getName() + " as the ClientProtocolProvider - returned null protocol");
}
}
catch (Exception e) {
LOG.info("Failed to use " + provider.getClass().getName() + " due to error: ", e);
}
}
}
if (null == clientProtocolProvider || null == client) {
throw new IOException( "Cannot initialize Cluster. Please check your configuration for " + MRConfig.FRAMEWORK_NAME + " and the correspond server addresses.");
}
}
/**
* Internal method for submitting jobs to the system.
*
*
The job submission process involves:
*
*
* Checking the input and output specifications of the job.
*
*
* Computing the {@link InputSplit}s for the job.
*
*
* Setup the requisite accounting information for the
* {@link DistributedCache} of the job, if necessary.
*
*
* Copying the job's jar and configuration to the map-reduce system
* directory on the distributed file-system.
*
*
* Submitting the job to the JobTracker and optionally
* monitoring it's status.
*
*
* @param job the configuration to submit
* @param cluster the handle to the Cluster
* @throws ClassNotFoundException
* @throws InterruptedException
* @throws IOException
*/
JobStatus submitJobInternal(Job job, Cluster cluster)
throws ClassNotFoundException, InterruptedException, IOException {
//validate the jobs output specs //校验输出的路径 校验的很早,还没做什么事情之前都开始校验了
checkSpecs(job);//进入
Configuration conf = job.getConfiguration(); //配置信息 八个文件 (.xml)
addMRFrameworkToDistributedCache(conf);//缓存的处理
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);//每次提交会创建一个临时路径,一旦提交完就会删除参数的数据 电脑上直接 收拾 tmp 即可找到
//configure the command line options correctly on the submitting dfs
InetAddress ip = InetAddress.getLocalHost();
if (ip != null) {
submitHostAddress = ip.getHostAddress();//网络 ip
submitHostName = ip.getHostName();
conf.set(MRJobConfig.JOB_SUBMITHOST,submitHostName);
conf.set(MRJobConfig.JOB_SUBMITHOSTADDR,submitHostAddress);
}
JobID jobId = submitClient.getNewJobID();//提交任务时的jobId,每个 job 提交任务的时候都会给你分配一个id
job.setJobID(jobId);
Path submitJobDir = new Path(jobStagingArea, jobId.toString());//提交的路径
JobStatus status = null;
try {
conf.set(MRJobConfig.USER_NAME,
UserGroupInformation.getCurrentUser().getShortUserName());
conf.set("hadoop.http.filter.initializers",
"org.apache.hadoop.yarn.server.webproxy.amfilter.AmFilterInitializer");
conf.set(MRJobConfig.MAPREDUCE_JOB_DIR, submitJobDir.toString());
LOG.debug("Configuring job " + jobId + " with " + submitJobDir
+ " as the submit dir");
// get delegation token for the dir
TokenCache.obtainTokensForNamenodes(job.getCredentials(),
new Path[] { submitJobDir }, conf);
populateTokenCache(conf, job.getCredentials());
// generate a secret to authenticate shuffle transfers
if (TokenCache.getShuffleSecretKey(job.getCredentials()) == null) {
KeyGenerator keyGen;
try {
keyGen = KeyGenerator.getInstance(SHUFFLE_KEYGEN_ALGORITHM);
keyGen.init(SHUFFLE_KEY_LENGTH);
} catch (NoSuchAlgorithmException e) {
throw new IOException("Error generating shuffle secret key", e);
}
SecretKey shuffleKey = keyGen.generateKey();
TokenCache.setShuffleSecretKey(shuffleKey.getEncoded(),
job.getCredentials());
}
if (CryptoUtils.isEncryptedSpillEnabled(conf)) {
conf.setInt(MRJobConfig.MR_AM_MAX_ATTEMPTS, 1);
LOG.warn("Max job attempts set to 1 since encrypted intermediate" +
"data spill is enabled");
}
copyAndConfigureFiles(job, submitJobDir);//提交一些文件的信息 进入 (提前打断点)
Path submitJobFile = JobSubmissionFiles.getJobConfPath(submitJobDir);
// Create the splits for the job
LOG.debug("Creating splits at " + jtFs.makeQualified(submitJobDir));
int maps = writeSplits(job, submitJobDir);//所有的切片信息 提交到 submitJobDir 路径上
conf.setInt(MRJobConfig.NUM_MAPS, maps);
LOG.info("number of splits:" + maps);
// write "queue admins of the queue to which job is being submitted"
// to job file.
String queue = conf.get(MRJobConfig.QUEUE_NAME,
JobConf.DEFAULT_QUEUE_NAME);
AccessControlList acl = submitClient.getQueueAdmins(queue);
conf.set(toFullPropertyName(queue,
QueueACL.ADMINISTER_JOBS.getAclName()), acl.getAclString());
// removing jobtoken referrals before copying the jobconf to HDFS
// as the tasks don't need this setting, actually they may break
// because of it if present as the referral will point to a
// different job.
TokenCache.cleanUpTokenReferral(conf);
if (conf.getBoolean(
MRJobConfig.JOB_TOKEN_TRACKING_IDS_ENABLED,
MRJobConfig.DEFAULT_JOB_TOKEN_TRACKING_IDS_ENABLED)) {
// Add HDFS tracking ids
ArrayList trackingIds = new ArrayList();
for (Token t :
job.getCredentials().getAllTokens()) {
trackingIds.add(t.decodeIdentifier().getTrackingId());
}
conf.setStrings(MRJobConfig.JOB_TOKEN_TRACKING_IDS,
trackingIds.toArray(new String[trackingIds.size()]));
}
// Set reservation info if it exists
ReservationId reservationId = job.getReservationId();
if (reservationId != null) {
conf.set(MRJobConfig.RESERVATION_ID, reservationId.toString());
}
// Write job file to submit dir
writeConf(conf, submitJobFile);//到你的提交目录 进入
//
// Now, actually submit the job (using the submit name)
//
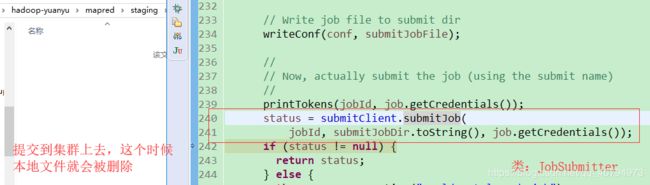
printTokens(jobId, job.getCredentials());
status = submitClient.submitJob(
jobId, submitJobDir.toString(), job.getCredentials());
if (status != null) {
return status;
} else {
throw new IOException("Could not launch job");
}
} finally {
if (status == null) {
LOG.info("Cleaning up the staging area " + submitJobDir);
if (jtFs != null && submitJobDir != null)
jtFs.delete(submitJobDir, true);
}
}
}
//校验输出路径
private void checkSpecs(Job job) throws ClassNotFoundException,InterruptedException, IOException { //进入
JobConf jConf = (JobConf)job.getConfiguration();
// Check the output specification
if (jConf.getNumReduceTasks() == 0 ?
jConf.getUseNewMapper() : jConf.getUseNewReducer()) {
org.apache.hadoop.mapreduce.OutputFormat output =
ReflectionUtils.newInstance(job.getOutputFormatClass(),job.getConfiguration());
output.checkOutputSpecs(job);//进入 确保输出路径设置好,并且不存在 不然抛出异常
} else {
jConf.getOutputFormat().checkOutputSpecs(jtFs, jConf);
}
}
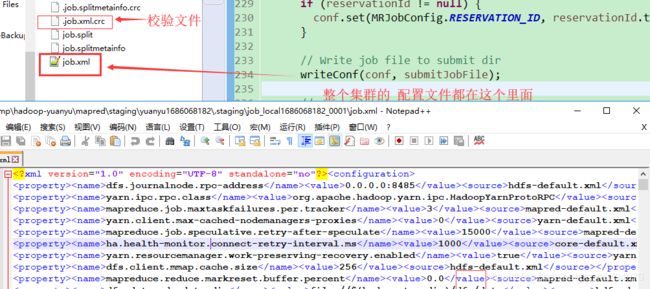
//各种属性参数 产数一个xml文件,真个hadoop集群的配置信息
private void writeConf(Configuration conf, Path jobFile)
throws IOException {
// Write job file to JobTracker's fs
FSDataOutputStream out =
FileSystem.create(jtFs, jobFile,
new FsPermission(JobSubmissionFiles.JOB_FILE_PERMISSION));
try {
conf.writeXml(out);
} finally {
out.close();
}
}
private void checkSpecs(Job job) throws ClassNotFoundException,
InterruptedException, IOException {
JobConf jConf = (JobConf)job.getConfiguration();
// Check the output specification
if (jConf.getNumReduceTasks() == 0 ?
jConf.getUseNewMapper() : jConf.getUseNewReducer()) {
org.apache.hadoop.mapreduce.OutputFormat output =
ReflectionUtils.newInstance(job.getOutputFormatClass(),
job.getConfiguration());
output.checkOutputSpecs(job); 进入(提前打断点)
} else {
jConf.getOutputFormat().checkOutputSpecs(jtFs, jConf);
}
}
public void checkOutputSpecs(JobContext job
) throws FileAlreadyExistsException, IOException{
// Ensure that the output directory is set and not already there //确认输出路径已经被设置好,并且不存在
Path outDir = getOutputPath(job);
if (outDir == null) {
throw new InvalidJobConfException("Output directory not set.");
}
// get delegation token for outDir's file system
TokenCache.obtainTokensForNamenodes(job.getCredentials(),
new Path[] { outDir }, job.getConfiguration());
if (outDir.getFileSystem(job.getConfiguration()).exists(outDir)) {
throw new FileAlreadyExistsException("Output directory " + outDir +
" already exists"); //路径存在会报异常
}
}
/**
JobSubbmitter.class
* configure the jobconf of the user with the command line options of
* -libjars, -files, -archives.
* @param job
* @throws IOException
*/
private void copyAndConfigureFiles(Job job, Path jobSubmitDir)
throws IOException {
JobResourceUploader rUploader = new JobResourceUploader(jtFs);
rUploader.uploadFiles(job, jobSubmitDir); //进入 (提前打断点)
// Get the working directory. If not set, sets it to filesystem working dir
// This code has been added so that working directory reset before running
// the job. This is necessary for backward compatibility as other systems
// might use the public API JobConf#setWorkingDirectory to reset the working
// directory.
job.getWorkingDirectory();
}
//-------------------------------------------------------------
/**
JobResourceUploader
* Upload and configure files, libjars, jobjars, and archives pertaining to
* the passed job.
*
* @param job the job containing the files to be uploaded
* @param submitJobDir the submission directory of the job
* @throws IOException
*/
public void uploadFiles(Job job, Path submitJobDir) throws IOException {
Configuration conf = job.getConfiguration();
short replication =
(short) conf.getInt(Job.SUBMIT_REPLICATION,
Job.DEFAULT_SUBMIT_REPLICATION);
if (!(conf.getBoolean(Job.USED_GENERIC_PARSER, false))) {
LOG.warn("Hadoop command-line option parsing not performed. "
+ "Implement the Tool interface and execute your application "
+ "with ToolRunner to remedy this.");
}
// get all the command line arguments passed in by the user conf
String files = conf.get("tmpfiles");
String libjars = conf.get("tmpjars");
String archives = conf.get("tmparchives");
String jobJar = job.getJar();
//
// Figure out what fs the JobTracker is using. Copy the
// job to it, under a temporary name. This allows DFS to work,
// and under the local fs also provides UNIX-like object loading
// semantics. (that is, if the job file is deleted right after
// submission, we can still run the submission to completion)
//
// Create a number of filenames in the JobTracker's fs namespace
LOG.debug("default FileSystem: " + jtFs.getUri());
if (jtFs.exists(submitJobDir)) {
throw new IOException("Not submitting job. Job directory " + submitJobDir
+ " already exists!! This is unexpected.Please check what's there in"
+ " that directory");
}
submitJobDir = jtFs.makeQualified(submitJobDir);
submitJobDir = new Path(submitJobDir.toUri().getPath());
FsPermission mapredSysPerms =
new FsPermission(JobSubmissionFiles.JOB_DIR_PERMISSION);
FileSystem.mkdirs(jtFs, submitJobDir, mapredSysPerms);
Path filesDir = JobSubmissionFiles.getJobDistCacheFiles(submitJobDir);
Path archivesDir = JobSubmissionFiles.getJobDistCacheArchives(submitJobDir);
Path libjarsDir = JobSubmissionFiles.getJobDistCacheLibjars(submitJobDir);
// add all the command line files/ jars and archive
// first copy them to jobtrackers filesystem
if (files != null) {
FileSystem.mkdirs(jtFs, filesDir, mapredSysPerms);
String[] fileArr = files.split(",");
for (String tmpFile : fileArr) {
URI tmpURI = null;
try {
tmpURI = new URI(tmpFile);
} catch (URISyntaxException e) {
throw new IllegalArgumentException(e);
}
Path tmp = new Path(tmpURI);
Path newPath = copyRemoteFiles(filesDir, tmp, conf, replication);
try {
URI pathURI = getPathURI(newPath, tmpURI.getFragment());
DistributedCache.addCacheFile(pathURI, conf);
} catch (URISyntaxException ue) {
// should not throw a uri exception
throw new IOException("Failed to create uri for " + tmpFile, ue);
}
}
}
if (libjars != null) {
FileSystem.mkdirs(jtFs, libjarsDir, mapredSysPerms);
String[] libjarsArr = libjars.split(",");
for (String tmpjars : libjarsArr) {
Path tmp = new Path(tmpjars);
Path newPath = copyRemoteFiles(libjarsDir, tmp, conf, replication);
DistributedCache.addFileToClassPath(
new Path(newPath.toUri().getPath()), conf, jtFs);
}
}
if (archives != null) {
FileSystem.mkdirs(jtFs, archivesDir, mapredSysPerms);
String[] archivesArr = archives.split(",");
for (String tmpArchives : archivesArr) {
URI tmpURI;
try {
tmpURI = new URI(tmpArchives);
} catch (URISyntaxException e) {
throw new IllegalArgumentException(e);
}
Path tmp = new Path(tmpURI);
Path newPath = copyRemoteFiles(archivesDir, tmp, conf, replication);
try {
URI pathURI = getPathURI(newPath, tmpURI.getFragment());
DistributedCache.addCacheArchive(pathURI, conf);
} catch (URISyntaxException ue) {
// should not throw an uri excpetion
throw new IOException("Failed to create uri for " + tmpArchives, ue);
}
}
}
if (jobJar != null) { // copy jar to JobTracker's fs
// use jar name if job is not named.
if ("".equals(job.getJobName())) {
job.setJobName(new Path(jobJar).getName());
}
Path jobJarPath = new Path(jobJar);
URI jobJarURI = jobJarPath.toUri();
// If the job jar is already in a global fs,
// we don't need to copy it from local fs
if (jobJarURI.getScheme() == null || jobJarURI.getScheme().equals("file")) {
copyJar(jobJarPath, JobSubmissionFiles.getJobJar(submitJobDir),
replication);
job.setJar(JobSubmissionFiles.getJobJar(submitJobDir).toString());
}
} else {
LOG.warn("No job jar file set. User classes may not be found. "
+ "See Job or Job#setJar(String).");
}
addLog4jToDistributedCache(job, submitJobDir);
// set the timestamps of the archives and files
// set the public/private visibility of the archives and files
ClientDistributedCacheManager.determineTimestampsAndCacheVisibilities(conf);
// get DelegationToken for cached file
ClientDistributedCacheManager.getDelegationTokens(conf,
job.getCredentials());
}
1、网络上现成的资料
格式: sed -i "s/查找字段/替换字段/g" `grep 查找字段 -rl 路径`
linux sed 批量替换多个文件中的字符串
sed -i "s/oldstring/newstring/g" `grep oldstring -rl yourdir`
例如:替换/home下所有文件中的www.admi
对于AJAX应用(使用XMLHttpRequests)来说,向服务器发起请求的传统方式是:获取一个XMLHttpRequest对象的引用、发起请求、读取响应、检查状态码,最后处理服务端的响应。整个过程示例如下:
var xmlhttp = new XMLHttpRequest();
xmlhttp.onreadystatechange
Hive中的排序语法 2014.06.22 ORDER BY
hive中的ORDER BY语句和关系数据库中的sql语法相似。他会对查询结果做全局排序,这意味着所有的数据会传送到一个Reduce任务上,这样会导致在大数量的情况下,花费大量时间。
与数据库中 ORDER BY 的区别在于在hive.mapred.mode = strict模式下,必须指定 limit 否则执行会报错。
post-commit hook failed (exit code 1) with output:
svn: E155004: Working copy 'D:\xx\xxx' locked
svn: E200031: sqlite: attempt to write a readonly database
svn: E200031: sqlite: attempt to write a