再次复习输入输出流
写了好久的增删改查,觉得之前的基础有点忘光了,从今天开始重新来复习一下之前的内容。
输入输出流分类
输入输出流大致分为两类 字节流和 字符流,
字节流 : 传输最小单位字节。字节流可以操作任何数据,因为在计算机中任何数据都是以字节的形式存储的
字符流 : 传输最小单位为字符。字符流只能操作纯字符数据,比较方便。
字节流顶级父类 InputStream 和OutputStream
字符流顶级父类 Reader 和Writer
字节流的子类-----FileInputStream&&FileOutputStream
这俩类使用频率还是想当高的,之后的处理服务端的日志,传文件之类的基本上都用的这两个流。
public static void main(String[] args) {
File file = new File("D:test1.txt");
File file1 = new File("D:/test2.txt");
try (
FileInputStream fileInputStream = new FileInputStream(file);
FileOutputStream fileOutputStream = new FileOutputStream(file1,true);
// byte [] bytes = new byte[fileInputStream.available()];//分析输入流的大小设置对应的byte大小
){
byte [] bytes = new byte[1024*8];
int len =0;
while((len=fileInputStream.read(bytes))!=-1){
fileOutputStream.write(bytes,0,len);
System.out.println(len);
}} catch (IOException e) {
e.printStackTrace();
}
//
注意点一--------基本的使用方法也就是创建一个缓冲区,相当于一个杯子,把这盆水舀到另一个盆子里。否则频繁的读取磁盘势必会造成速度很慢的问题。。。
注意点二---------这里的创建两个流的操作写在了try的括号里,从OutputStream中可以看到他是继承了Closeable的方法,这样就可以不用写繁琐的关闭流的方法(前提是将创建写在try的括号中和jdk必须为1.7以上)。
注意点三----------new FileOutputStream(file,true);这种构造方法能追加内容
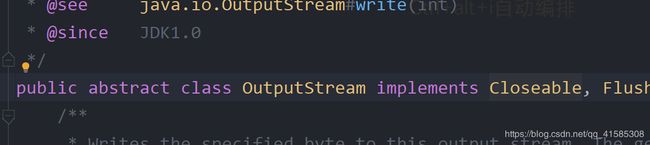
如果将其他不继承Closeable写入,将会报错
字节流的子类-----BufferedOutputStream&&BufferedInputStream
这两个类内部就有一个杯子,我们来看源码
// BufferedOutputStream源码部分
public synchronized void write(int b) throws IOException {
if (count >= buf.length) {
flushBuffer();
}
buf[count++] = (byte)b;
}
从这个写出的方法可以看出
第一点 :这个buf是每次接收一个值后不立马写出,而是存在它的杯子里,等到超过杯子的承载能力的时候再一次性写出。
第二点:可以发现这里的传入参数b是强转过来的,原先是int类型。原因就是如果传入的值为255(11111111),但是255在byte类型中是全1这并不是255而是代表-1(11111111是-1的反码)则会造成程序终止,因此只有用int(4字节)来存储数据在强转才可以了。下面是例子,具体操作也就是包装一个已有的流,其他操作就是基本操作了。这里我没有用自动关闭,来跟上边的代码做一个比较。
public static void main(String[] args) {
try {
FileOutputStream fileOutputStream = new FileOutputStream("D:/test/1234.png");
BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(fileOutputStream);
FileInputStream fileInputStream = new FileInputStream("D:/1234.png");
BufferedInputStream bufferedInputStream = new BufferedInputStream(fileInputStream);
byte[] bytes = new byte[1024*8];
int b = 0;
while ((b=bufferedInputStream.read(bytes))!=-1){
bufferedOutputStream.write(bytes,0,b);
}
bufferedInputStream.close();
bufferedOutputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
这里我用的是自定义的一个字节数组去做缓存。BufferedOutputStream内部有一个自带的字节数组。如果使用read()(空参的方法)就会调用内部的缓存了。
字符流的子类-----FileReader&&FileWriter
这个基本跟前面的字节流读取写入是类似的,,先上代码,
public static void main(String[] args) {
//字符流的拷贝dwqd
try(
FileReader reader = new FileReader("a.txt");
FileWriter writer= new FileWriter("b.txt")
) {
char[] buf = new char[1024*8];
int len = 0;
while ((len=reader.read(buf))!=-1){
writer.write(buf,0,len);
}
} catch (IOException e) {
e.printStackTrace();
}
}
注意点一:这对输入输出可以处理GBK,unicode编码的中文字符。
注意点二 :这里内部是将字符转换成字节码来处理的,如代码
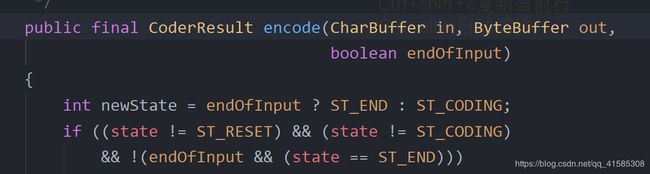
这是CharsetEncoder这个类的方法。字符输入输出流会调用此方法将char类型转换成字节类型。因此要是使用写出的话还不如直接用字节输出流。不然还多一步转化。但是在读入的时候 由于中文字符不好处理的原因。还是使用字符输入流好一些。
字符流的子类-----BufferedReader&&BufferedWriter
这个缓冲流具体和上面的字节流缓冲流是一样的
public static void main(String[] args) {
try (
BufferedReader reader = new BufferedReader(new FileReader("a.txt"));
BufferedWriter writer = new BufferedWriter(new FileWriter("b.txt",true))
){
String line =null;
while ((line=reader.readLine())!=null){
writer.write(line);
//writer.write("\r\n");
writer.newLine();
}
} catch (IOException e) {
e.printStackTrace();
}
}
注意点一 : BufferedReader有一个readLine方法可以读取一行,经测试是不读取回车和换行的。这个方法还是相当的实用的
注意点二 :BufferedWriter有newLine类似于换行的方法,但是是可以在任何系统上换行的。假如自己写一个换行则可能跨平台会有问题。
今天就先到这里吧,我分析的一定有很多不正确的地方。希望大家多多指教