奇异值矩阵分解(Singular Value Decomposition)的一些感想
写在前面的话:
最近的大半年一直在和矩阵分解和数值运算打交道,基本功不扎实吃了很多亏。
主要是在做算法的研究和优化。核心算法里需要用到矩阵分解的思想,目前广泛应用的分解方式有整数分解,特征值分解(eigen value),奇异值分解(SVD),非负矩阵分解(non-negative matrix fatorization)等等。我整个学习和使用的过程比较艰辛,走了很多弯路,因为之前完全把分解算法当做黑盒来处理,并没有深入进去算法的本质。而本文作为一个记录,回顾一下我学习过程的一些思考,以及一部分自己的见解。
本文主要分为五部分,在目录中有介绍,正文部分写的比较凌乱,因为记录了自己思考的整个过程,思维混乱是做研究的大忌,所以以后要改正,特别是需要静下心来慢慢梳理的部分。好在SVD的学习曲线不算非常陡峭,因而可以充分的边学边思考。目前许多大型的算法在建立之后(比如大部分的推荐算法以及计算广告等)都会划归为矩阵的操作,这里面有普通的数值运算,也有复杂的分解和变换。而奇异值分解(SVD)就是这其中效果很好并广为使用的一种,SVD的一个代数特性就是它用到了几乎所有的线性代数知识,把线性代数从入门到进阶的基础知识完美的串联了起来,推导逐层深入,理解逐渐细化。所以当你对SVD了然于心的时候,不知不觉之间,线性代数的基础知识也更加稳固了。
--------------------------------------------------------------------------------------------------------------------
content
背景
1. 什么是SVD
- concept
- geometry/physical aspect
2. SVD实现
- conventional algorithm
3. 算法优化
- modify: compute the largest singular value
4. MATLAB的实现
5. SVD的应用
- Rank
- PCA
- image denoise
- video deblocking
- recommender system
--------------------------------------------------------------------------------------------------------------------
背景
最近几个月一直在做一些有关奇异值分解(SVD,Singular Value Decomposition)的东西,并没有从理论上创新的修改奇异值的计算方法,只是在学习和了解的过程中逐渐明白了SVD的一些意义和实际的应用场景。学习的过程中间走了很多弯路,也有了很多不理解的地方,到现在也不敢说是完全明白,但是我觉得有必要总结一下这一系列的东西,顺便也梳理一下研究的思路,不要因为走得太远而忘记了为了什么而出发。同时在知乎上也有一个这类的问题[1],但是个人觉得高票的几个回答从不同的角度在解释这个问题,所以尝试自己写一个比较简单的问题。
1. 什么是SVD
1.1 概念
SVD是Singular Value Decomposition的缩写,翻译成中文一般是奇异值分解。这是一种矩阵分解形式,它将一个矩阵(可以是实矩阵也可以是复矩阵,我们只讨论实矩阵)分解为三个子矩阵,分别代表了左奇异向量,奇异值矩阵以及右奇异向量。直接说概念可能会比较抽象,后面会详细的介绍各个矩阵的左右以及物理意义。除了奇异值分解,目前常用的矩阵分解方式还有根据特征值分解以及非负矩阵分解(Non-negative Matrix Factorization, NMF)。如果需要回忆一些线性代数的基础知识的话,可以参考[2]网易公开课上MIT的线性代数课程,
Gilbert Strang将很多线性代数的基础知识讲的深入浅出,个人强推。
那么,奇异值的数学表达式是什么呢?对于矩阵X,总能找到一个正交矩阵U和一个正交矩阵V,以及一个对角矩阵
Σ,使得:
X = UΣV
T
式子成立。其中,U被称为的左奇异向量,V被称为右奇异向量,而对角矩阵
Σ的主对角线上的值称为矩阵X的奇异值,并按照从大到小降序排列。
1.2 几何意义
以2x2的矩阵为例,因为二阶矩阵可以使用平面在直角坐标系来表示,主要参考了[3]。SVD在2x2矩阵上的作用的几何意义主要是可以将二维空间下两个互相正交(也就是垂直)的向量,通过矩阵分解,变换为另一个二维空间下互相正交的两个向量。具体的过程如下图所示。
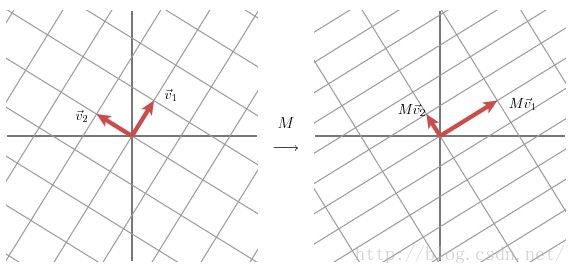
上图的含义是,我们在左图首先选定了两个单位正交基向量
V
1和
V
2
。那么此时,通过矩阵M的作用下,左图中的一个二维空间(左图正方形格子)下的正交向量
V
1和
V
2
。就变换成为了另一个二维空间(右图长方形格子)下的正交向量Mv
1和
Mv
2
。然后我们在
Mv
1和
Mv
2
的方向上分别选择两个单位向量
u1
和
u2
,同时设
Mv
1和
Mv
2的模长度为
σ
1和
σ
2,那么就有下式成立:
M
v1
= σ
1
u1
(1)
M v2 = σ 2 u2 (2)
M v2 = σ 2 u2 (2)
因此,对于上面左图中二维空间(正方形格子)的任意一个向量X来说,就有:(
“
·”表示向量内积)
x = (v1·x) v1 + (v2·x) v2
(3)
(3)式左右同时乘以矩阵M:
M
x
= (
v1·
x
)
M
v1
+ (
v2·
x
)
M
v2
(4)
(4)式结合(1)和(2):
M
x
= (
v1
·
x
) σ
1
u1
+ (
v2
·
x
) σ
2
u2
(5)
将内积操作通过用转置表示出来():
Mx = u1σ1v1Tx + u2σ2v2T
x
(6)
两边同时消去X
M = u1σ1 v1T + u2σ2v2T
(7)
通常,我们将(7)式的形式写为:
M = UΣVT
(8)
从(8)式我们可以看到,U矩阵是一个原始空间的正交矩阵,它的每一个列向量都是原始空间的规范正交基;而V矩阵则是变换之后的域的正交矩阵,它的每一个列向量都是变换空间的规范正交基。而式子中的奇异值对角矩阵Σ的值则对应了从原始空间(U)到变换空间(V)的对应关系,具体来说就是两个空间的基向量的拉伸程度。
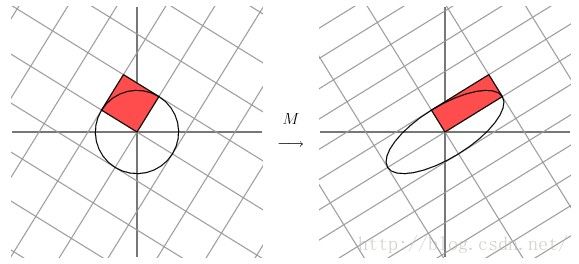
同时,在[3]当中还有另一种几何解释,也就是把SVD分解的过程看做是将单位圆的半径通过变换伸缩为椭圆的两个半轴。
如下图:
1.3 物理意义
个人理解,从信号的角度来讲,SVD过程的物理意义是将矩阵的能量集中到奇异值矩阵的左上角的过程。
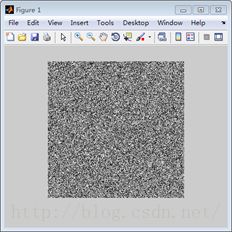
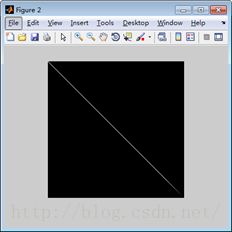
例如,上图中的左图为随机生成的一幅256x256的图像,值都是在0-255之间。右图为左图SVD分解之后的奇异值矩阵,颜色越亮,代表了值越大,也就是能量越大。因此SVD的过程就是通过变换,将原空间的能量重新聚集分配,在新的空间集中的过程,这就是SVD的物理意义。通过这个物理意义,我们可以做许多的应用,例如数据的压缩,图像的滤波,以及推荐算法等,这些会在后文说到。
2. SVD的实现
目前用的比较多的算法都是通过一次次的迭代来逼近奇异值,比如Jacob算法和QR算法。
MATLAB中也集成了SVD的算法而且无论速度还是精度都非常高。
在书 “Numerical Recipes IN C: The Art of Science Computing” ISBN:0-521-43108-5 的Chapter 2.6 SVD一部分中,给出了一种通过Household进行规约实现双对角化的迭代算法,能达到完全分解的精度,但是速度比MATLAB稍慢一些(为什么比MATLAB慢后面会解释)。有兴趣的话可以参考一下书籍和代码。
3. 算法优化
3.1 算法修改为每次计算最大的奇异值
上面提到了SVD的计算是比较慢的,那么优化的步骤可以通过两个方面来进行。
1). 利用GPU修改算法,实现并行化,在这一点里,CUDA7.0 中提供了GPU计算的API,详情可以参阅CUDA的官方文档[5]。
2). 调整思路,如果完全分解显得很缓慢,那么就采用分治法,将矩阵部分分解。
部分分解的算法如下:
① 计算原矩阵M得到最大的奇异值(
σ
max)已经它对应的左奇异向量(
U
max)和右奇异向量(
V
max)
② 利用①中计算得到的
σ
max,
U
max和
V
max对矩阵进行重构的M
'
③ 原矩阵M减去②重构得到的矩阵M
'得到矩阵M
''
④ 如果M
''为零则结束,否则令M = M
''并执行①
这个算法的核心在于寻找一种计算矩阵的最大的奇异值的方法,好在我们已经有了KSVD(计算前k个奇异值)的思路,参考KSVD的方法可以找到这种计算最大奇异值的方法。而实验证明,计算一个奇异值所需要的迭代次数比完全分解矩阵需要的迭代次数少得多,具体的会减少多少次迭代则需要根据矩阵的稀疏性以及矩阵数据值的大小来确定。
4. MATLAB的SVD实现
在第2部分中提到了MATLAB中集成的SVD函数的运算速度很快,那么MATLAB的开发者运用了什么黑科技呢?
答案是底层优化。
我们都知道MATLAB的UI层是基于JVM用Java实现的,而底层的算法则都使用C/C++实现,并且在数值计算函数中不仅用到了底层的库比如BLAS/LAPACK,还使用了Intel推出的Math Kernel Lib(MKL),利用这些底层优化可以大大提速数值计算的过程。同时,这也解释了为什么MATLAB的速度比进行了代码级优化的纯C实现还要快。
5. 应用
5.1 矩阵的秩
显然,根据定义我们就可以知道,SVD计算结果中的奇异值矩阵是对角矩阵,因此SVD的一个直观应用就是可以知道被分解矩阵的秩,同时秩的大小也就是奇异值的个数。当然,计算秩的方法更多,不必大费周章用如此复杂的分解来计算矩阵的秩。
从本质上来说,第3部分中提到的部分分解算法其实就是一种在降秩的过程,原矩阵减去每一次重构之后的矩阵的过程其实就是降秩的过程。
5.2 PCA
在参考[1]中
从奇异值分解(SVD)和主成分分析(PCA)的关系的角度来描述奇异值(以及SVD得到的另外两个矩阵)的物理意义。
设X是一个数据矩阵(在此不把它理解成变换),每一列表示一个数据点,每一行表示一维特征。
对X做主成分分析(PCA)的时候,需要求出各维特征的协方差,这个协方差矩阵是
XX
T
。
(其实需要先把数据平移使得数据的均值为0,不过在此忽略这些细节)
PCA做的事情,是对这个协方差矩阵做对角化: XX T = P AP T
可以这样理解上式右边各项的物理意义:用一个均值为0的多维正态分布来拟合数据,则正交矩阵P的每一列是正态分布的概率密度函数的等高线(椭圆)的各个轴的方向,而对角矩阵
A
的对角线元素是数据在这些方向上的方差,它们的平方根跟椭圆各个轴的长度成正比。
现在来看数据矩阵X的奇异值分解:
X = U
S
V
T
,其中U、V各列是单位正交的,S是对角阵,对角元非零。
由此式可以得到
XX
T
= U
S
V
T
VSUT
=
US2UT
也就是说,SVD中的矩阵U相当于PCA中的矩阵P,不过仅保留了
A
的非零特征值对应的那些特征向量,而
S=A
1/2
(也只保留了非零特征值)。
那么V呢?可以把US放在一起看成一个由伸缩和旋转组成的坐标变换(不包括平移),数据矩阵X是由数据矩阵
V
T
经此变换得来的,而
V
T
的各列(V的各行)则服从标准正态分布。这也就是说,
V
T
的各维特征(
V
T
的各行,V的各列)是互不相关的且各自的方差均为1,也就是说V的各列是单位正交的。
也就是说,奇异值和特征值是有联系的,奇异值是特征值的算数平方根,而因为求特征值必须是方阵,奇异值则是每一个矩阵都可以求,因此求奇异值比起特征值的适用范围更广。
5.3 Image Denoise(图像去噪)
在图像去噪问题中,搜索了相似的patch之后,就可以对矩阵进行类似的SVD分解,并且通过设定阈值进行滤波,去掉噪声在变换域上的分量,从而达到了去噪的目的,详情可以参看[6]。
图像去噪算法流程图:
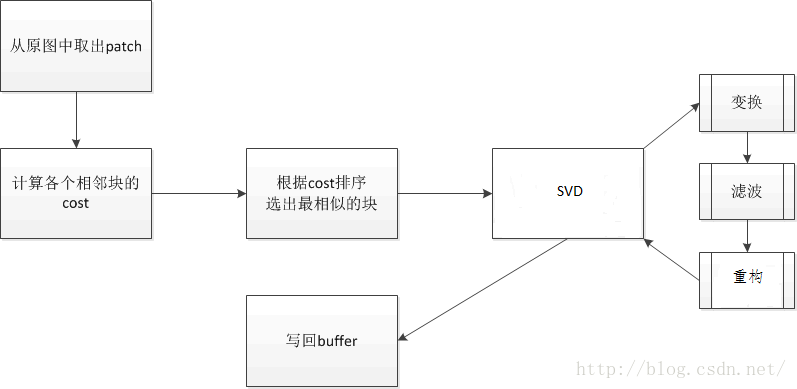
在算法流程图中,首先根据图中进行相似块的搜索,然后利用non-local的特性进行处理。将搜索的到的二维相似块进行列向量化,然后stack起来组成一个二维矩阵,那么对这个二维矩阵的SVD处理从图像的角度来理解就是讲相似的相似进行能量集中的过程,在能量集中了之后,噪声的信息在变换域内就都集中到了较小的系数部分,此时采用滤波方法,可以是固定阈值的滤波器,也可以是自适应(adaptive)的滤波器。
5.4 视频编码后处理
根据5.3的启发,可以将5.3的方法应用到Video Codec的Deblocking Filter中,同样是利用SVD进行去块效应已达到图像的增强。
5.5 推荐系统中的协同滤波
推荐系统应用数据分析技术,找出用户最可能喜欢的东西推荐给用户,现在很多电子商务网站都有这个应用。目前用的比较多、比较成熟的推荐算法是协同过滤(Collaborative Filtering,简称CF)推荐算法,CF的基本思想是根据用户之前的喜好以及其他兴趣相近的用户的选择来给用户推荐物品[7]。
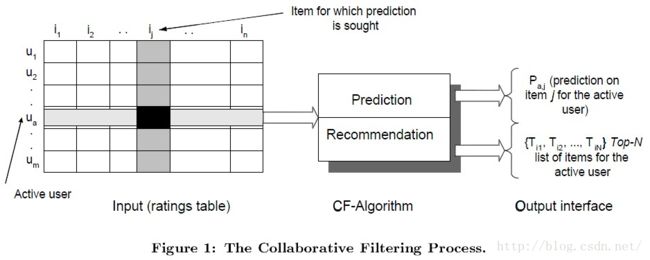
从上图中可以看到,每一行是User,而每一列是每个商品的Item,整个大矩阵是一个User-Iterm表,而由于用户和商品数量是成千上万的,所以这个矩阵很大。矩阵的每一个值则是不同用户对不同的商品进行打分的信息。SVD(Singular Value Decomposition)的想法是根据已有的评分情况,分析出评分者对各个因子的喜好程度以及电影包含各个因子的程度,最后再反过来根据分析结果预测评分。电影中的因子可以理解成这些东西:电影的搞笑程度,电影的爱情爱得死去活来的程度,电影的恐怖程度。SVD的想法抽象点来看就是将一个N行M列的评分矩阵R(R[u][i]代表第u个用户对第i个物品的评分),分解成一个N行F列的用户因子矩阵P(P[u][k]表示用户u对因子k的喜好程度)和一个M行F列的物品因子矩阵Q(Q[i][k]表示第i个物品的因子k的程度)。
----未完待续
Reference
1. http://www.zhihu.com/question/22237507
2. http://open.163.com/movie/2010/11/1/G/M6V0BQC4M_M6V2B5R1G.html MIT linear algebra
3.
We Recommend a Singular Value Decomposition( http://www.ams.org/samplings/feature-column/fcarc-svd
)
4. http://blog.csdn.net/myan/article/details/647511
5. http://docs.nvidia.com/cuda
6.
Jian Zhang, Debin Zhao, Wen Gao,“Group-based Sparse representation for image restoration,” IEEE Transactions on Image Processing, vol. 23, no. 8, pp. 3336–3351, Aug. 2014.
7. http://blog.csdn.net/wuyanyi/article/details/7964883