白话JUC--Queue体系--ArrayBlockingQueue
首先看一下ArrayBlockingQueue继承关系

ArrayBlockingQueue简介
ArrayBlockingQueue是java并发包下一个以数组实现的阻塞队列,它是线程安全的,特点是先进先出(FIFO)
ArrayBlockingQueue源码分析
ArrayBlockingQueue主要成员变量
/** The queued items */
存储元素的集合
final Object[] items;
/** items index for next take, poll, peek or remove */
取元素的指针
int takeIndex;
/** items index for next put, offer, or add */
放元素的指针
int putIndex;
/** Number of elements in the queue */
元素个数
int count;
/*
* Concurrency control uses the classic two-condition algorithm
* found in any textbook.
*/
/** Main lock guarding all access */
保证并发访问的锁
final ReentrantLock lock;
/** Condition for waiting takes */
非空条件
private final Condition notEmpty;
/** Condition for waiting puts */
非满条件
private final Condition notFull;
通过几个主要成员分析,我们知道ArrayBlockingQueue是利用数组存储元素的,利用指针存储数据和获取数据的,利用重入锁保证并发安全
ArrayBlockingQueue构造方法
public ArrayBlockingQueue(int capacity) {
this(capacity, false);
}
public ArrayBlockingQueue(int capacity, boolean fair) {
// 校验大小是否小于0
if (capacity <= 0)
throw new IllegalArgumentException();
// 初始化数组
this.items = new Object[capacity];
// 创建公平或者非公平重入锁
lock = new ReentrantLock(fair);
// 创建两个条件
notEmpty = lock.newCondition();
notFull = lock.newCondition();
}
public ArrayBlockingQueue(int capacity, boolean fair,
Collection<? extends E> c) {
this(capacity, fair);
final ReentrantLock lock = this.lock;
lock.lock(); // Lock only for visibility, not mutual exclusion
try {
int i = 0;
try {
for (E e : c) {
checkNotNull(e);
items[i++] = e;
}
} catch (ArrayIndexOutOfBoundsException ex) {
throw new IllegalArgumentException();
}
count = i;
putIndex = (i == capacity) ? 0 : i;
} finally {
lock.unlock();
}
}
主要有三个构造方法,实际上第一个和第三个调用的都是第二个进行的初始化
- 初始化的时候必须传入容量,也就是数组大小
- 通过构造方法控制重入锁是公平还是非公平的
ArrayBlockingQueue添加元素
ArrayBlockingQueue–add
在调用add方法的时候,会调用父类的add方法,就是AbstractQueue中的方法,通过这种方式调用父类的模板方法解决通用性问题
public boolean add(E e) {
return super.add(e);
}
AbstractQueue中的方法,调用offer方法,实际上就是子类实现类中的offer方法,如果成功返回true,如果失败则抛出异常
public boolean add(E e) {
if (offer(e))
return true;
else
throw new IllegalStateException("Queue full");
}
ArrayBlockingQueue–offer
add实际上调用子类的offer方法添加数据
public boolean offer(E e) {
// 判断元素是否为空
checkNotNull(e);
// 获取重入锁
final ReentrantLock lock = this.lock;
// 加锁
lock.lock();
try {
// 判断元素个数是否等于数组长度,如果相等代表满了,直接返回false
if (count == items.length)
return false;
else {
// 否则添加元素,返回true
enqueue(e);
return true;
}
} finally {
// 解锁
lock.unlock();
}
}
private void enqueue(E x) {
// assert lock.getHoldCount() == 1;
// assert items[putIndex] == null;
final Object[] items = this.items;
// 将x放入到数组的putIndex上
items[putIndex] = x;
// 将putIndex加一后,判断是否等于数组长度,如果相等,将putIndex设置为0
if (++putIndex == items.length)
putIndex = 0;
// 记录队列中元素的个数
count++;
// 唤醒处于notEmpty条件上的线程,也就是消费者获取到队列中的元素为空时,会阻塞消费者线程
// 当往队列中添加元素的时候,唤醒消费者,消费者可以继续消费队列中的元素
notEmpty.signal();
}
其实在这个我想了一个问题,就是如果消费者没有消费队列中的第零个元素,那么直接将putIndex设置为0会不会有问题?但是一细想不会有这种情况,因为在offer方法中已经判断了count和队列的大小了,如果第零个元素没有人消费,那么此时就不会进入到enqueue方法,通过offer方法直接返回false,所以在这里将putIndex设置为0不会有问题
putIndex为什么会在等于数组长度的时候设置为0?
因为ArrayBlockingQueue是一个数组,是一个FIFO的队列,队列添加元素的时候是从队列尾putIndex开始存储元素的,putIndex是不停的增加的,当putIndex等于数组的长度的时候,不能让putIndex继续增加了,否则会超出数组初始化长度的,所以需要重置putIndex的值,从头开始增加,类似于一个环状结构一样

ArrayBlockingQueue–put
put方法和add方法其实类似,只不过put方法判断队列满了会阻塞
public void put(E e) throws InterruptedException {
// 检查是否为空
checkNotNull(e);
final ReentrantLock lock = this.lock;
// 加锁,但是这个方法和lock的区别是,这个方法允许在加锁等待的时候由其他线程调用interrupt方法来中断等待状态直接返回。
// 但是lock方法是尝试获得锁成功后才能响应中断
lock.lockInterruptibly();
try {
// 如果队列满了,当前线程会被notFull条件对象挂起到等待队列中
while (count == items.length)
notFull.await();
// 添加到队列中
enqueue(e);
} finally {
lock.unlock();
}
}
通过代码发现,线程会阻塞在notFull条件上,等待唤醒
ArrayBlockingQueue–remove
在调用remove方法的时候,同样会调用父类的remove方法,就是AbstractQueue中的方法
public E remove() {
E x = poll();
if (x != null)
return x;
else
throw new NoSuchElementException();
}
ArrayBlockingQueue–poll
public E poll() {
final ReentrantLock lock = this.lock;
// 加锁
lock.lock();
try {
// 如果队列中没有元素,则返回空,否则出队
return (count == 0) ? null : dequeue();
} finally {
lock.unlock();
}
}
private E dequeue() {
// assert lock.getHoldCount() == 1;
// assert items[takeIndex] != null;
final Object[] items = this.items;
@SuppressWarnings("unchecked")
// 取数组中takeIndex位置中的元素
E x = (E) items[takeIndex];
// 将数组中takeIndex位置的元素设置为空
items[takeIndex] = null;
// takeIndex指针前移一位,如果takeIndex的位置等于数组的长度,那么设置为0,继续从头开始获取元素
if (++takeIndex == items.length)
takeIndex = 0;
// 存储的元素个数减一
count--;
if (itrs != null)
// 更新迭代器中的元素数据
itrs.elementDequeued();
// 唤醒因为队列满了以后被阻塞的线程
notFull.signal();
return x;
}
ArrayBlockingQueue 中,实现了迭代器的功能,也就是可以通过迭代器来遍历阻塞队列中的元素,所以 itrs.elementDequeued() 是用来更新迭代器中的元素数据的
ArrayBlockingQueue–take
take是一种阻塞获取队列中元素的方法,有就删除没有就阻塞,这个阻塞是可以中断的,如果队列没有数据那么就加入 notEmpty条件队列等待(有数据就直接取走,方法结束),如果有新的put线程添加了数据,那么put操作将会唤醒take线程,执行 take操作
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
// 如果队列为空,通过notEmpty条件阻塞,等待put唤醒
while (count == 0)
notEmpty.await();
return dequeue();
} finally {
lock.unlock();
}
}
如果队列中通过put添加数据,会在enqueue中调用notEmpty.signal()方法唤醒阻塞在take方法上的线程,获取到元素
ArrayBlockingQueue–remove(Object o)
public boolean remove(Object o) {
if (o == null) return false;
// 获取数组
final Object[] items = this.items;
// 获得锁
final ReentrantLock lock = this.lock;
// 加锁
lock.lock();
try {
// 如果元素数量不为空
if (count > 0) {
// 获取下一个需要添加元素的索引
final int putIndex = this.putIndex;
// 获取当前要被移除元素的索引
int i = takeIndex;
do {
// 从takeIndex下标开始,找到需要被移除的元素
if (o.equals(items[i])) {
// 移除指定元素
removeAt(i);
// 返回true
return true;
}
// 将当前删除的索引加一后判断是否等于数组长度,如果相等,说明索引已经达到了数组尽头,减i设置为0
if (++i == items.length)
i = 0;
// 继续查找,直到putIndex,因为putIndex是数组中插入的索引,当然不能超过
} while (i != putIndex);
}
return false;
} finally {
lock.unlock();
}
}
void removeAt(final int removeIndex) {
// assert lock.getHoldCount() == 1;
// assert items[removeIndex] != null;
// assert removeIndex >= 0 && removeIndex < items.length;
// 获取集合
final Object[] items = this.items;
// 判断移除的索引是否是取出索引
if (removeIndex == takeIndex) {
// removing front item; just advance
// 如果发现移除的索引和取出的索引相同,那么将取出索引位置的元素设置为null
items[takeIndex] = null;
// 将取出索引加一,因为当前的取出索引应该往前移动一位了
// 此时判断取出索引和数组长度是否相等,如果相等,说明需要重新从数组的头部开始取元素
if (++takeIndex == items.length)
// 移动取出索引为队列头部,设置为0
takeIndex = 0;
// 将数组中的元素个数减一
count--;
// 更新迭代器中的元素数据
if (itrs != null)
itrs.elementDequeued();
} else {
// an "interior" remove
// slide over all others up through putIndex.
// 但是发现移除的索引和取出的索引不相同
// 获取放入索引
final int putIndex = this.putIndex;
// while(true)循环,从removeIndex索引开始
for (int i = removeIndex;;) {
// 获取移除索引的下一个
int next = i + 1;
// 判断移除索引的下一个元素等于数组的长度,说明此时的i已经是数组的最后一个了
// 如果再获取数组的下一个元素的话会超过数组的长度,所以下一个元素应该从头再重新进行遍历
// 所以将下一个元素的索引设置为0
if (next == items.length)
next = 0;
// 判断下一个元素的索引是否等于放入索引
if (next != putIndex) {
// 发现不相等,就将下一个元素移动到i索引上,也就是将数组数据向前移动了
items[i] = items[next];
// 重新将i赋值,设置为next,也就是下一个元素的索引
i = next;
// 进行下一次循环,直到移动到放入索引
} else {
// 如果发现相等,说明已经移动到头了,已经到放入索引了
// 将放入索引上的元素设置为空,等待插入数据
// 同时重置放入索引为i,跳出循环,整体移动完毕
items[i] = null;
this.putIndex = i;
break;
}
}
// 将集合中的元素个数减一
count--;
// 更新迭代器中的元素数据
if (itrs != null)
itrs.removedAt(removeIndex);
}
// 同时唤醒等待在notFull条件上的线程,可以插入数据了
notFull.signal();
}
通过上面的remove方法,我们知道会从队列的尾部开始寻找,找到第一个能够匹配上的就会返回,然后将数组中第一个匹配上的索引的元素设置为下一个索引上的元素,从匹配上的位置开始,往后的每一个元素都往前移动一个位置
ArrayBlockingQueue–总结
- ArrayBlockingQueue是有界的阻塞队列,不接受null元素
- ArrayBlockingQueue不能进行扩容,初始化时指定容量
- ArrayBlockingQueue利用takeIndex和putIndex循环利用数组,构成一个环形FIFO队列
- 入队和出队各定义了四组方法为满足不同的用途
- 利用ReentrantLock和Condition重入锁和两个条件保证增删改并发安全,入队和出队数组下标和count共享变量都是靠这把锁维护数据安全的
- 由于通过ReentrantLock锁保证的线程安全,所以会损失一定的性能
ArrayBlockingQueue–迭代器
观察ArrayBlockingQueue源码其实挺简单的,但是看到ArrayBlockingQueue里面的迭代器的时候还是有点难的,下面就简单的介绍一下ArrayBlockingQueue里面的迭代器这个东西
如何使用迭代器
ArrayBlockingQueue<Integer> q =new ArrayBlockingQueue(5);
Iterator it = q.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
创建Itr对象
public Iterator<E> iterator() {
return new Itr();
}
Itr实现了Iterator接口
private class Itr implements Iterator<E>
首先看一下Itr的构造方法
Itr() {
// assert lock.getHoldCount() == 0;
// 这个属性可以先不用理解,知道这是Itr的一个成员变量就行
lastRet = NONE;
// 获得锁
final ReentrantLock lock = ArrayBlockingQueue.this.lock;
// 加锁
lock.lock();
try {
// 判断数组中的元素个数
if (count == 0) {
// 如果元素个数为0,说明这个迭代器就不需要进行迭代
// assert itrs == null;
// 设置cursor为NONE
cursor = NONE;
// nextIndex为NONE
nextIndex = NONE;
// prevTakeIndex为DETACHED
prevTakeIndex = DETACHED;
} else {
// 说明元素个数不为0,可以进行迭代
// 获得takeIndex索引
final int takeIndex = ArrayBlockingQueue.this.takeIndex;
// 将takeIndex设置给prevTakeIndex成员
prevTakeIndex = takeIndex;
// 将takeIndex设置给nextIndex成员
// 并获得数组中nextIndex位置上的元素
// 将nextIndex位置上的元素设置给nextItem成员属性
nextItem = itemAt(nextIndex = takeIndex);
// 增加takeIndex的值并赋值给cursor
cursor = incCursor(takeIndex);
// 判断itrs是否为空,itrs是一个类似于管理器的东西
if (itrs == null) {
// 如果为空就创建一个,并将自己设置进去
itrs = new Itrs(this);
} else {
// 如果不为空,那么就注册进去
itrs.register(this); // in this order
// 这个方法类似于管理器清理
itrs.doSomeSweeping(false);
}
// 获取数组已经循环至0的次数,并设置给prevCycles
prevCycles = itrs.cycles;
// assert takeIndex >= 0;
// assert prevTakeIndex == takeIndex;
// assert nextIndex >= 0;
// assert nextItem != null;
}
} finally {
lock.unlock();
}
}
通过上面的方法,我们知道其实就是设置Itr对象中的几个成员属性
当调用hasNext方法的时候发生了什么
public boolean hasNext() {
// assert lock.getHoldCount() == 0;
// 实际上就是判断nextItem是否为空,通过构造方法我们知道了就是takeIndex位置上的元素
// 已经通过构造方法设置好了,直接返回就可以了
if (nextItem != null)
return true;
noNext();
return false;
}
之后再调用it.next()方法
public E next() {
// assert lock.getHoldCount() == 0;
// 首先获取nextItem元素
final E x = nextItem;
// 如果为空,则抛出异常,
if (x == null)
throw new NoSuchElementException();
final ReentrantLock lock = ArrayBlockingQueue.this.lock;
// 加锁
lock.lock();
try {
// 判断是否应该废除这个迭代器,判断的依据就是prevTakeIndex是否小于0
// 如果不应该废除,则重新调整各部分索引位置,防止返回的数据错误
if (!isDetached())
incorporateDequeues();
// assert nextIndex != NONE;
// assert lastItem == null;
// 将nextIndex赋值给lastRet索引
lastRet = nextIndex;
// 获得cursor的位置
final int cursor = this.cursor;
// 如果cursor可用,也就是大于等于0
if (cursor >= 0) {
// 将cursor游标设置给nextIndex,并返回nextIndex位置上的值,设置给nextItem
nextItem = itemAt(nextIndex = cursor);
// assert nextItem != null;
// 增加cursor游标的值
this.cursor = incCursor(cursor);
} else {
// 如果cursor游标不可用,说明没有可以遍历的值了,将nextIndex设置为NONE不可用状态,设置nextItem为空
nextIndex = NONE;
nextItem = null;
}
} finally {
// 解锁
lock.unlock();
}
// 返回nextItem上的值
return x;
}
通过上面的方法,我们知道了其实next方法返回的是提前设置好的值,在调用next的时候先获得nextItem上的元素,然后更新各部分索引的位置,然后设置下一次需要的nextItem,返回当次的nextItem。感觉挺神奇的,其实这样做的主要目的就是防止在调用next方法的时候返回空元素的情况
同时,通过上面的方法我们还能发现各个索引的作用,lastRet就是用来保存上一次返回的索引,nextIndex就是用来获取返回nextItem的索引,cursor为了下一次循环获取元素的索引,以下图片可以分析移动关系。
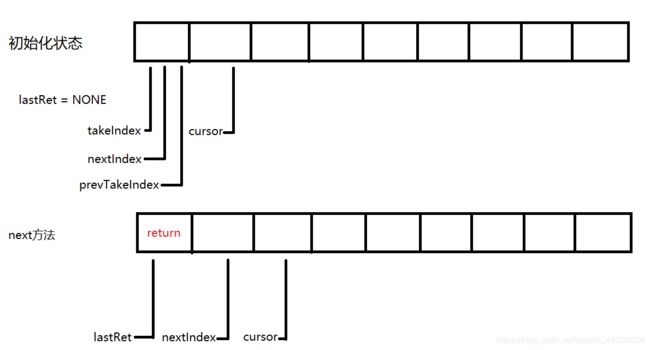
然后看一下incorporateDequeues这个方法里面都做了什么事情
private void incorporateDequeues() {
// assert lock.getHoldCount() == 1;
// assert itrs != null;
// assert !isDetached();
// assert count > 0;
// 获得ArrayBlockingQueue中循环的次数
final int cycles = itrs.cycles;
// 获得ArrayBlockingQueue中takeIndex的索引
final int takeIndex = ArrayBlockingQueue.this.takeIndex;
// 获取迭代器中之前记录的循环次数
final int prevCycles = this.prevCycles;
// 获取迭代器中之前记录的takeIndex索引
final int prevTakeIndex = this.prevTakeIndex;
// 如果发现循环的次数和takeIndex索引的位置不相同,说明需要更新迭代器中的索引为最新的
if (cycles != prevCycles || takeIndex != prevTakeIndex) {
// 获得队列大小
final int len = items.length;
// how far takeIndex has advanced since the previous
// operation of this iterator
// 获取之前迭代器中记录的takeIndex和当前takeIndex之间的距离
long dequeues = (cycles - prevCycles) * len
+ (takeIndex - prevTakeIndex);
// Check indices for invalidation
// 校验lastRet
if (invalidated(lastRet, prevTakeIndex, dequeues, len))
lastRet = REMOVED;
if (invalidated(nextIndex, prevTakeIndex, dequeues, len))
nextIndex = REMOVED;
if (invalidated(cursor, prevTakeIndex, dequeues, len))
cursor = takeIndex;
if (cursor < 0 && nextIndex < 0 && lastRet < 0)
// 在没有更多的索引要更新时,主动分离当前迭代器
detach();
else {
// 重新设置索引
this.prevCycles = cycles;
this.prevTakeIndex = takeIndex;
}
}
}
private boolean invalidated(int index, int prevTakeIndex,
long dequeues, int length) {
// 初始化时小于0,并不是无效
if (index < 0)
return false;
// 与上次takeIndex的距离
int distance = index - prevTakeIndex;
// 小于0说明发生了循环,index索引指向了循环后prevTakeIndex的前面某个位置,所以与数组长度求和就是首尾索引的距离
if (distance < 0)
// 这里只加了一倍的数组长度,对于循环超过一次的也会重新设置索引
distance += length;
// 如果距离小于当前实际的有效的元素之间,说明索引无效
return dequeues > distance;
}
private void detach() {
// Switch to detached mode
// assert lock.getHoldCount() == 1;
// assert cursor == NONE;
// assert nextIndex < 0;
// assert lastRet < 0 || nextItem == null;
// assert lastRet < 0 ^ lastItem != null;
if (prevTakeIndex >= 0) {
// assert itrs != null;
// 设置prevTakeIndex为分离
prevTakeIndex = DETACHED;
// try to unlink from itrs (but not too hard)
// 清理迭代器
itrs.doSomeSweeping(true);
}
}
下面看一下remove方法
public void remove() {
// assert lock.getHoldCount() == 0;
final ReentrantLock lock = ArrayBlockingQueue.this.lock;
lock.lock();
try {
if (!isDetached())
incorporateDequeues(); // might update lastRet or detach
// 获得lastRet索引的状态
final int lastRet = this.lastRet;
// 设置为NONE状态
this.lastRet = NONE;
// 如果lastRet索引可用
if (lastRet >= 0) {
// 此时迭代器没有分离
if (!isDetached())
// 直接remove
removeAt(lastRet);
else {
// 获得lastRet索引位置上的元素
final E lastItem = this.lastItem;
// assert lastItem != null;
// 设置为空
this.lastItem = null;
// 判断lastRet位置上的元素和lastItem元素是否相同
// 如果相同说明lastRet索引之前的元素没有移动,所以可以移除lastRet位置上的元素
if (itemAt(lastRet) == lastItem)
removeAt(lastRet);
}
} else if (lastRet == NONE)
// 如果不可用,直接抛出异常
throw new IllegalStateException();
// else lastRet == REMOVED and the last returned element was
// previously asynchronously removed via an operation other
// than this.remove(), so nothing to do.
// 分离
if (cursor < 0 && nextIndex < 0)
detach();
} finally {
lock.unlock();
// assert lastRet == NONE;
// assert lastItem == null;
}
}
void removeAt(final int removeIndex) {
// assert lock.getHoldCount() == 1;
// assert items[removeIndex] != null;
// assert removeIndex >= 0 && removeIndex < items.length;
final Object[] items = this.items;
// 判断takeIndex与removeIndex是否相同,说明在尾部进行的移除
if (removeIndex == takeIndex) {
// removing front item; just advance
// 将takeIndex位置上的元素设置为null
items[takeIndex] = null;
if (++takeIndex == items.length)
takeIndex = 0;
// 元素数量减一
count--;
// 通知所有迭代器更新
if (itrs != null)
itrs.elementDequeued();
} else {
// an "interior" remove
// slide over all others up through putIndex.
// 如果不相等
final int putIndex = this.putIndex;
// 从removeIndex索引位置开始遍历
// 慢慢将removeIndex以后位置上的元素提前一个位置,直到等于putIndex,跳出循环
for (int i = removeIndex;;) {
int next = i + 1;
if (next == items.length)
next = 0;
if (next != putIndex) {
items[i] = items[next];
i = next;
} else {
items[i] = null;
this.putIndex = i;
break;
}
}
count--;
if (itrs != null)
// 同时更新迭代器管理器
itrs.removedAt(removeIndex);
}
notFull.signal();
}
以上就是关于迭代器的说明,然后说一说迭代器管理器这个东西Itrs
class Itrs {
/**
* Node in a linked list of weak iterator references.
*/
private class Node extends WeakReference<Itr> {
Node next;
Node(Itr iterator, Node next) {
super(iterator);
this.next = next;
}
}
迭代器管理器将所有的迭代器都用链表的形式进行保存,每一次有新的迭代器被注册时都将其加到该迭代器链表的头节点。
void register(Itr itr) {
// assert lock.getHoldCount() == 1;
head = new Node(itr, head);
}
这里的迭代器链表使用了迭代器的弱引用,这可以在迭代器实例被使用完时(例如将其置为null)被GC及时的回收掉
在元素进行清理或者集合中元素为空的时候,会对整个链表中的数据进行清理
void elementDequeued() {
// assert lock.getHoldCount() == 1;
if (count == 0)
queueIsEmpty();
else if (takeIndex == 0)
takeIndexWrapped();
}
void takeIndexWrapped() {
// assert lock.getHoldCount() == 1;
cycles++;
for (Node o = null, p = head; p != null;) {
final Itr it = p.get();
final Node next = p.next;
if (it == null || it.takeIndexWrapped()) {
// unlink p
// assert it == null || it.isDetached();
p.clear();
p.next = null;
if (o == null)
head = next;
else
o.next = next;
} else {
o = p;
}
p = next;
}
if (head == null) // no more iterators to track
itrs = null;
}
void doSomeSweeping(boolean tryHarder) {
// assert lock.getHoldCount() == 1;
// assert head != null;
int probes = tryHarder ? LONG_SWEEP_PROBES : SHORT_SWEEP_PROBES;
Node o, p;
final Node sweeper = this.sweeper;
boolean passedGo; // to limit search to one full sweep
if (sweeper == null) {
o = null;
p = head;
passedGo = true;
} else {
o = sweeper;
p = o.next;
passedGo = false;
}
for (; probes > 0; probes--) {
if (p == null) {
if (passedGo)
break;
o = null;
p = head;
passedGo = true;
}
final Itr it = p.get();
final Node next = p.next;
if (it == null || it.isDetached()) {
// found a discarded/exhausted iterator
probes = LONG_SWEEP_PROBES; // "try harder"
// unlink p
p.clear();
p.next = null;
if (o == null) {
head = next;
if (next == null) {
// We've run out of iterators to track; retire
itrs = null;
return;
}
}
else
o.next = next;
} else {
o = p;
}
p = next;
}
this.sweeper = (p == null) ? null : o;
}
其实,调用takeIndexWrapped和doSomeSweeping方法的时候就是遍历迭代器链表中的迭代器,对迭代器进行清理,将Node的next设置为null,如果发现迭代器被GC回收(it == null)或者迭代器已经用完(it.isDetached())了,就将其从迭代器链表中移除
每当检查迭代器链表时,如果确定GC已经回收了迭代器(it == null),或者迭代器报告它被“分离”(即不需要任何进一步的状态更新)(it.isDetached()),那么它就会被删除。
ArrayBlockingQueue–迭代器–总结
迭代器其实是创建队列的一个快照,只有在创建的时刻会持有关于数组相关信息,至于数组是否发生变化,迭代器并不关心,所以迭代器具有弱一致性,仅代表创建时数组的状态,所以在next返回的时候,nextItem可能已经被删除了,但是next依然能够返回它,所以迭代器是弱一致性的,在循环过程中允许对数组进行修改,而不会抛出ConcurrentModificationException
上面就是对迭代器的一个简单分析,其实应用到实际中的用处就是迭代器管理器这个思想,通过弱引用的方式维护迭代器,并通过不同的状态标识每个迭代器的状态,实现迭代器链表的清理
还有就是迭代器中对于元素的变量方式,和可用性校验同样值得我们学习。