Python 轻量级爬虫
一、概念
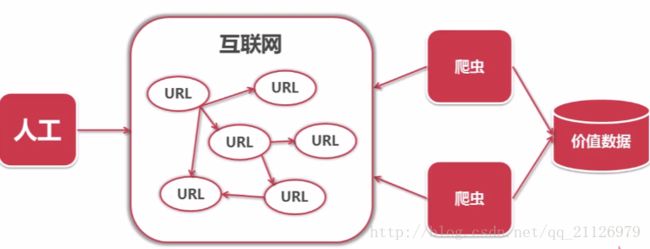
一段自动抓取互联网信息的程序。一般我们都是通过访问url进入网页,在网页中点击某个链接再进入网页,一层又一层挑战。如下图:
二、爬虫分析
1、爬虫架构
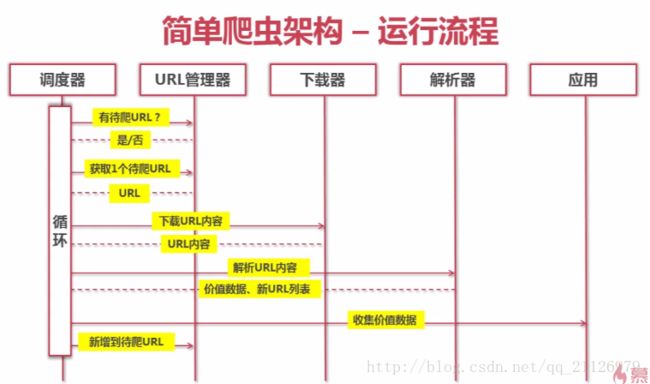
爬虫主要分为:爬虫调度端、爬虫核心模块、价值数据存储这三部分。但是爬虫核心模块包含URL管理器、网页下载器、网页解析器。

爬虫具体的运行过程:
2、爬虫核心模块
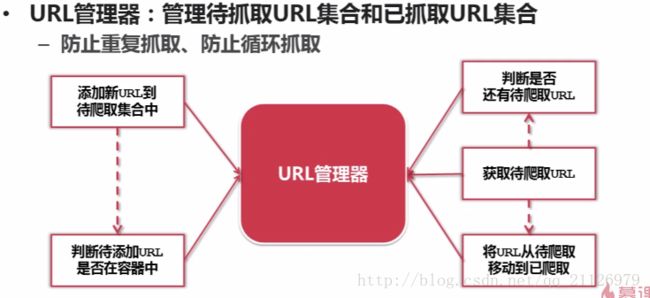
1)URL管理器
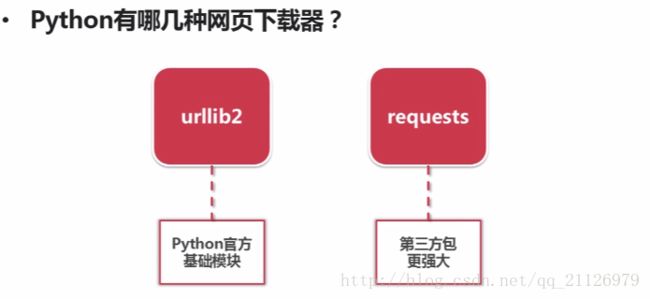
2)网页下载器
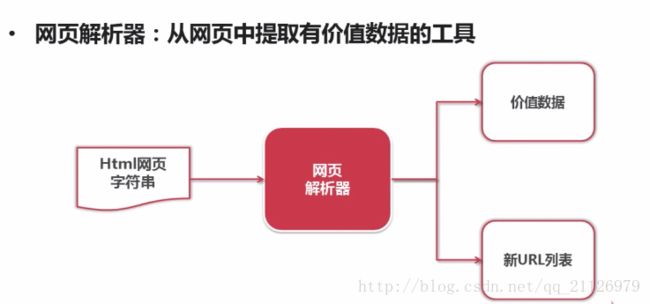
3)网页解析器
三、代码实现
1、爬虫目标分析

2、代码实现
1)函数入口
if __name__ == '__main__':
root_url = 'https://baike.baidu.com/item/Python'
obj_spider = SpiderMain()
# obj_spider.create_table()
obj_spider.craw(root_url)
# obj_spider.output_mySql()from reptile import url_manager,html_downloader,html_parser,html_outputer,html_tomysql
import datetime
class SpiderMain(object):
''' 调度器 '''
def __init__(self):
super().__init__()
self.urls = url_manager.UrlManager()
self.downloader = html_downloader.HtmlDownloader()
self.parser = html_parser.HtmlParser()
self.outputer = html_outputer.HtmlOutputer()
self.mysqlmanager = html_tomysql.MySQLUtil()
def craw(self,root_url):
now_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print('爬虫开始时间: %s' % (now_time))
'''
爬虫思想
第一:爬虫的跟地址存放在url管理器
第二:判断url管理器是否有可以解析的url
第三:如果有,记入当前url,执行下载,解析
解析完返回解析内容还有网页新的url地址
把这些地址存放在url管理器
第四:解析内容进行收集,并存放在网页或者数据库
'''
count = 1
self.urls.add_new_url(root_url)
while self.urls.has_new_url():
try:
new_url = self.urls.get_new_url()
print('爬虫序号: %d,爬虫网址:%s'%(count,new_url))
html_content = self.downloader.download(new_url)
new_urls, new_data = self.parser.parser(new_url,html_content)
self.urls.add_new_urls(new_urls)
self.outputer.collect_data(new_data)
self.outputer.insert_mySql(count)
# 爬虫一千个页面
if count == 100000:
break
count = count + 1
except:
print('craw error')
# 输出网页
now_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print('爬虫结束时间: %s' % (now_time))
self.outputer.output_html()
# 输出数据库
# self.outputer.output_mySql()2、URL管理器
class UrlManager(object):
''' url管理器 '''
def __init__(self):
super().__init__()
self.new_urls = set()
self.old_urls = set()
def add_new_url(self, url):
''' 添加单个url'''
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
def add_new_urls(self, new_urls):
''' 添加多个个url'''
if new_urls is None or len(new_urls) == 0:
return
for url in new_urls:
self.add_new_url(url)
def has_new_url(self):
return len(self.new_urls) != 0
def get_new_url(self):
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url3、网页下载器
from bs4 import BeautifulSoup
import re
import urllib.parse
class HtmlParser(object):
''' 网页解析器 '''
def parser(self, new_url, html_content):
if new_url is None or html_content is None:
return
soup = BeautifulSoup(html_content,'html.parser',from_encoding='utf-8')
new_urls = self._get_new_urls(new_url,soup)
new_data = self._get_new_data(new_url,soup)
return new_urls,new_data
def _get_new_urls(self, page_url, soup):
''' 网页解析得到新的url新地址'''
new_urls = set()
#
links = soup.find_all('a',href=re.compile(r"/item/"))
for link in links:
new_url = link['href']
new_full_url = urllib.parse.urljoin(page_url,new_url)
new_urls.add(new_full_url)
return new_urls
def _get_new_data(self, page_url, soup):
res_data = {}
res_data['url'] = page_url
title_node = soup.find('dd',class_="lemmaWgt-lemmaTitle-title").find('h1')
res_data['title'] = title_node.get_text()
summary_node = soup.find('div',class_="lemma-summary")
res_data['summary'] = summary_node.get_text()
return res_data4、网页输出器
from reptile import html_tomysql
class HtmlOutputer(object):
''' 网页输出器 '''
def __init__(self):
self.datas = []
self.mysqlmanager = html_tomysql.MySQLUtil()
def collect_data(self, data):
if data is None:
return
self.data = data
self.datas.append(data)
def output_html(self):
fout = open('output.html','w',encoding='utf8')
fout.write("")
fout.write("")
fout.write("")
for data in self.datas:
fout.write("")
fout.write("%s " % (data['url']))
fout.write("%s " % (data['title']))
fout.write("%s " % (data['summary']))
fout.write(" ")
fout.write("
")
fout.write("")
fout.write("")
def output_mySql(self):
try:
conn = self.mysqlmanager.get_conn()
cursor = self.mysqlmanager.get_cursor(conn)
count = 1
for data in self.datas:
sql = "INSERT INTO PYTHON_DATA(ID,URL,TITLE,CONTENT) \
VALUES ('%d', '%s', '%s', '%s' )" % (count, data['url'], data['title'], data['summary'])
cursor.execute(sql)
conn.commit()
count = count + 1
finally:
cursor.close()
conn.close()
def insert_mySql(self,count):
try:
conn = self.mysqlmanager.get_conn()
cursor = self.mysqlmanager.get_cursor(conn)
sql = "INSERT INTO PYTHON_DATA(ID,URL,TITLE,CONTENT) \
VALUES ('%d', '%s', '%s', '%s' )" % (count, self.data['url'], self.data['title'], self.data['summary'])
cursor.execute(sql)
conn.commit()
finally:
cursor.close()
conn.close()
# #创建一个数据表 writers(id,name)
# cur.execute("CREATE TABLE IF NOT EXISTS \
# Writers(Id INT PRIMARY KEY AUTO_INCREMENT, Name VARCHAR(25))")
def create_table(self):
conn = self.mysqlmanager.get_conn()
cursor = self.mysqlmanager.get_cursor(conn)
sql = """CREATE TABLE PYTHON_DATA (
ID BIGINT NOT NULL,
URL VARCHAR(200),
TITLE VARCHAR(200),
CONTENT MEDIUMTEXT)"""
cursor.execute(sql)
conn.commit()
cursor.close()
conn.close()5、数据库连接
# 存储到数据库
import pymysql
from reptile import MySQLConfig
class MySQLUtil(object):
def __init__(self):
self.config = MySQLConfig.MySQLConfig()
def get_conn(self):
try:
conn = pymysql.connect(host=self.config.get_host(),
user=self.config.get_user(),
passwd=self.config.get_passwd(),
db=self.config.get_db(),
port =self.config.get_port(),
charset='utf8')
except:
print('数据库连接失败!')
return conn
def get_cursor(self,conn):
if conn is not None and conn != '':
cursor = conn.cursor()
return cursor6、数据库配置
# 数据库配置
class MySQLConfig(object):
def __init__(self):
self.host = '127.0.0.1'
self.user = 'root'
self.passwd = 'hjy'
self.db = 'data_db'
self.port = 3306
def get_host(self):
return self.host
def get_user(self):
return self.user
def get_passwd(self):
return self.passwd
def get_db(self):
return self.db
def get_port(self):
return self.port好了,主要代码就在上面,有什么错误欢迎大家指错!