今天线上的hadoop集群崩溃了,现象是namenode一直在GC,长时间无法正常服务。最后运维大神各种倒腾内存,GC稳定后,服务正常。虽说全程在打酱油,但是也跟着学习不少的东西。
第一个问题:为什么会频繁GC
有过JVM经验的开发者都应该知道,GC是在内存不够时,JVM自动进行的自我救赎(删除不用的数据,释放内存空间)。那么NameNode在什么情况下会进行GC呢?在解释这个问题之前,需要明白GC的几种级别,以及触发的条件:
- Minor GC:清理新生代,一般都是复制回收算法
- Full GC:清理所有的内存,新生代、老年代、元空间、堆外内存...(Major GC清理老年代,一般采用标记清除/标记整理)
Full GC的触发条件一般是:
- System.gc()
- jmap -histo:live pid
- minor gc时检查年老代的空间是否够年轻代用
- 使用大对象
- 长期持有引用
参考:https://blog.csdn.net/chenleixing/article/details/46706039
可以通过下面的配置输出GC日志,并记录FullGC前的线程情况:
-Xmx2g -XX:+HeapDumpBeforeFullGC
-XX:HeapDumpPath=. -Xloggc:gc.log
-XX:+PrintGC -XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-XX:+UseGCLogFileRotation
-XX:NumberOfGCLogFiles=10
-XX:GCLogFileSize=100m
-XX:HeapDumpOnOutOfMemoryError 再来说说,namenode什么情况下会触发GC:
由于namenode中需要维护namespace(目录结构)和blockmanager(block状态),因此内存消耗很严重。如果小文件很多,势必会增加两部分的内存消耗。
参考:https://blog.csdn.net/qq_25418883/article/details/79926153
第二个问题:如何查看线上进程的GC情况
JVM提供了很多JVM内存分析的工具,如jstat,使用的方法就是:
# 先执行top查找指定的进程pid
top
# 然后使用jstat分析内存情况
jstat -gc 12345 5000
# 12345是java的进程id,5000是gc的间隔时间,单位是ms我这边有一段gc的记录:
[hdfs@hnode1 ~]$ jstat -gc 1842 5000
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
127744.0 127744.0 0.0 116918.1 1022464.0 755982.7 11304960.0 1199292.3 30752.0 30014.9 3672.0 3477.0 25 3.058 2 0.302 3.360
127744.0 127744.0 0.0 127744.0 1022464.0 0.0 11304960.0 1643454.1 30752.0 30150.5 3672.0 3492.1 35 4.111 2 0.302 4.413
127744.0 127744.0 127744.0 0.0 1022464.0 613512.1 11304960.0 2042124.0 30752.0 30161.0 3672.0 3493.6 44 5.336 2 0.302 5.638
127744.0 127744.0 127744.0 122761.9 1022464.0 1022464.0 11304960.0 2517047.0 30752.0 30161.0 3672.0 3493.6 55 6.121 2 0.302 6.422
127744.0 127744.0 0.0 127744.0 1022464.0 304352.9 11304960.0 2976155.9 31008.0 30286.0 3672.0 3501.9 65 6.950 2 0.302 7.252
127744.0 127744.0 0.0 127744.0 1022464.0 211192.9 11304960.0 3267759.0 31008.0 30498.1 3672.0 3525.3 71 7.498 2 0.302 7.800
127744.0 127744.0 127744.0 0.0 1022464.0 467990.3 11304960.0 3413694.4 31008.0 30498.1 3672.0 3525.3 72 7.834 2 0.302 8.136
127744.0 127744.0 0.0 127744.0 1022464.0 693620.3 11304960.0 3598033.7 31008.0 30502.2 3672.0 3525.3 73 8.333 2 0.302 8.635
127744.0 127744.0 0.0 67244.8 1022464.0 245206.5 11304960.0 3953531.0 31264.0 30745.0 3672.0 3547.3 77 9.108 2 0.302 9.410
127744.0 127744.0 111122.2 0.0 1022464.0 736237.5 11304960.0 4239210.9 31264.0 30746.5 3672.0 3547.3 88 9.792 2 0.302 10.094
127744.0 127744.0 119642.4 0.0 1022464.0 470375.6 11304960.0 4575876.0 31264.0 30746.5 3672.0 3547.3 100 10.584 2 0.302 10.886
127744.0 127744.0 0.0 127672.5 1022464.0 878275.8 11304960.0 4887903.6 31264.0 30767.6 3672.0 3547.3 111 11.314 2 0.302 11.616在GC日志中能看到什么?
1 各项指标的含义
- S0C:第一个幸存区的大小
- S1C:第二个幸存区的大小
- S0U:第一个幸存区的使用大小
- S1U:第二个幸存区的使用大小
- EC:伊甸园区的大小(新生代)
- EU:伊甸园区的使用大小
- OC:老年代大小
- OU:老年代使用大小
- MC:方法区大小
- MU:方法区使用大小
- CCSC:压缩类空间大小
- CCSU:压缩类空间使用大小
- YGC:年轻代垃圾回收次数
- YGCT:年轻代垃圾回收消耗时间
- FGC:老年代垃圾回收次数
- FGCT:老年代垃圾回收消耗时间
GCT:垃圾回收消耗总时间
- 参考:https://blog.csdn.net/zlzlei/article/details/46471627
参考:https://blog.csdn.net/maosijunzi/article/details/46049117
2 新生代的垃圾回收模式
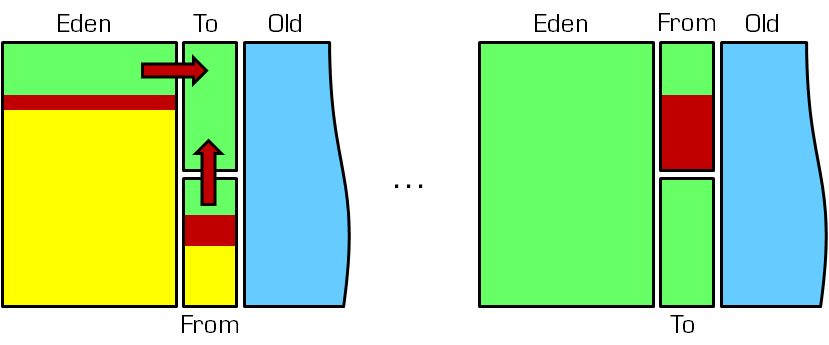
由于JVM设计者认为,大部分的对象都是新创建的,生命周期都不长。因此新建的对象会直接放在新生代中,并采用复制回收机制。即保证to区总是空的,每次触发GC的时候,就会把Eden和from survivor中的还存活的对象拷贝到to区中。然后to变成了from,from变成to。这样反复几次,还存活的对象,就会拷贝到old老年代当中。
在配置JVM的时候就有几个比较重要的参数:
- -Xms 和 -Xmx 配置了堆的最小和最大内存
- -XX:NewSize 和 -XX:MaxNewSize 配置了新生代的内存。最大是Xmx的一半,不过最好还是看业务场景
- -XX:NewRatio 设置新生代和老年代的比例,如 -XX:NewRatio=3 指定老年代/新生代为3/1
- -XX:SurvivorRatio 设置survivor与eden的比例,如 -XX:SurvivorRatio=10 表示eden是survivor的10倍,即survivor每个占1/12,eden占10/12
- -XX:InitialTenuringThreshold, -XX:MaxTenuringThreshold and -XX:TargetSurvivorRatio 控制进入老年代的条件,例如 , -XX:MaxTenuringThreshold=10 -XX:TargetSurvivorRatio=90 设定老年代阀值的上限为10,幸存区空间目标使用率为90%
- -XX:+NeverTenure and -XX:+AlwaysTenure 分别表示永远不进入老年代,和一次GC存活就进入老年代
参考:http://ifeve.com/useful-jvm-flags-part-5-young-generation-garbage-collection/
YGC和FGC
通过前面的讲述,应该了解到:
1 频繁的YGC
表示新创建的对象过多、survivor剩余空间太小;如果老年代内存利用率不高,那么可以考虑调整老年代的阈值。
2 频繁的FGC
就需要认真排查了,比如:
- 查看堆空间大小分配(年轻代、年老代、持久代分配)
- 垃圾回收监控(长时间监控回收情况)
- 线程信息监控:系统线程数量
- 线程状态监控:各个线程都处在什么样的状态下
- 线程详细信息:查看线程内部运行情况,死锁检查
- CPU热点:检查系统哪些方法占用了大量CPU时间
- 内存热点:检查哪些对象在系统中数量最大
看看是不是内存发生泄漏,内存泄漏的情况:
- 静态集合类。生命周期会跟类的生命周期一样,因此不会被GC
- 集合里面对象的属性改变。比如HashSet,改变了某个对象的属性,导致hashcode发生变化。但是引用还在。
- 控件的监听器
- 各种连接,没有close
- 外部模块的引用
- 单例模式,如果它持有外部对象的引用。
4 PC和PU去哪里了
在老版本的JVM中,类的方法数据、字节码、变量大小、常量池等等被认为是静态信息,不由程序创建而控制,存储在永久带Perm当中。
在1.8中,这部分数据放入了一个叫做元空间的地方。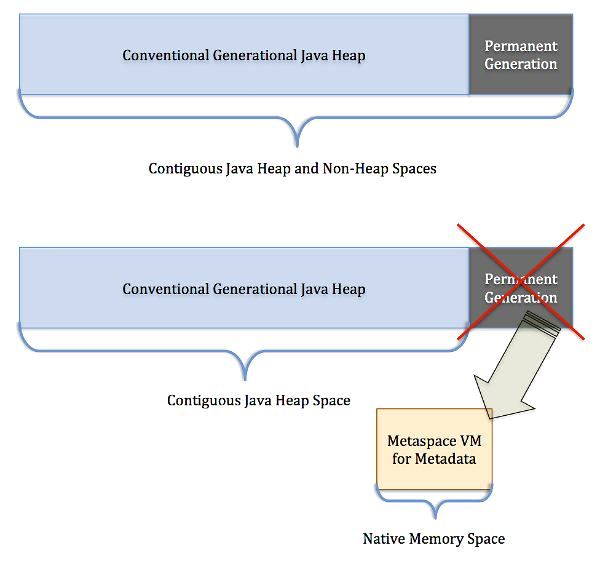
带来的好处:
- 元空间使用系统内存,不会出现内存溢出(不过内存泄漏一样会占用系统内存哦)
- 元空间不由垃圾回收器管理,之前垃圾回收效率也很低
参考:https://www.cnblogs.com/paddix/p/5309550.html
可以优化的点
1 合并小文件
2 优化目录树:https://www.cnblogs.com/yangjiandan/p/3535125.html