这一篇文章主要是记录下自己阅读《Convolutional Neural Networks for Sentence Classification》这篇文章思路的一个整理。这篇文章也可以算是CNN用于文本分类的开山之作了,尽管第一个使用CNN进行文本分类的不是Yoon Kim,但是Kim在这篇文章里提出来不少的方法,并且调参的过程也很详细,这些是我们应该学习的。
1:Introduction
这部分主要还是讲了讲前人使用CNN的一些工作,这部分暂且不提,主要思考的一个问题是为什么选用CNN,在这里论文里也没有详细讲,我写写我的想法,如果不对,欢迎指教。
我们传统的分类器比如朴素贝叶斯和SVM这样的,大多数将文本表示的方法是将其转换为“词袋模型”,主要还是根据在文本中出现的词频来做的,这样也会导致词与词之间的序列信息丢失,我们分词之后,句子本身相当于切成一块一块,词和词组合之后往往会有局部语意。这里一个重要的问题就是粒度和语意的矛盾。如果粒度过大,则太稀疏就跟强行使用N-gram一样,意义不大,粒度过小那么意思就不对了。而使用CNN的话, 通过卷积层之后,把每 k 个词组合之后的语意放在一起,得到比较准确的句向量。
2:模型输入的数据格式
文章中模型的输入的格式进行了四种尝试,然后进行对比,有以下四种:
CNN-rand: 所有的 word vector 都是随机初始化的,同时当做训练过程中优化的参数;
CNN-static: 所有的 word vector 直接使用 Word2Vec 工具得到的结果,并且是固定不变的;
CNN-non-static: 所有的 word vector 直接使用 Word2Vec 工具得到的结果,这些 word vector 也当做是可优化的参数,在训练过程中被 Fine tuned;
CNN-multichannel: CNN-static 和 CNN-non-static 的混合版本,即两种类型的输入;
3:模型介绍
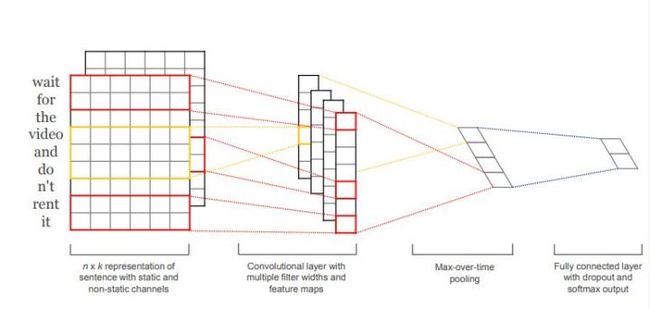
这个模型结构还是比较简单的,主要目的应该还是简单计算吧.说说他的结构:
模型的主要结构:
输入层+第一层卷积层+池化层+全连接+softmax层
输入层
从图上看,输入层就是句子中词语对应的词向量依次从上到下排列的,比如有n个词,词向量的维度是K,则这个矩阵就是n*k的矩阵。至于这个矩阵是静态和动态都可以,这个我查了一些博客,其中有个解释是说static是说词向量的大小是固定不变的,non-static的意思是指通过反向传播之后,产生的误差导致词向量发生fine tuned,对于未登录的词,这里padding一下。
第一层卷积层
输入层通过h*k的卷积核的卷积层之后得到列数为1的Feature Map,其中h表示纵向词语的个数,k表示词向量的维度。
卷积之后通过激活函数f得到feature。记为ci。它是由xi:i+h−1相邻的 h 个词语卷积得到的值,再 activation 之后的值,也是当前层的输出。
卷积之后的值:w⋅xi:i+h−1+b
输出的 feature 值 ci=f(w⋅xi:i+h−1+b),也就是sentence embedding
窗口大小:h
这样之后,一个 n 长度的sentence就有[x1:h,x2:h+1,x3:h+2,…,xn−h+1:n]这些 word windows,卷积后的结果就是 c = [c1,c2,…,cn−h+1],维度为(1,n-h+1)
然后进行池化 max pooling,选出最重要的 feature。
pooling scheme可以根据句子的长度来选择。
池化层
这里池化层说是用Max-over-time Pooling的方法,这种方法其实就是从之前的Feature Map中提取最大的值,我们在使用最大池化法的时候一般认为池化层中提取的最大,一般是最具有代表意义的或者是最重要的。最终提取出来成为一个一维向量。
全连接层+softmax层
池化之后的一维向量通过全连接的方式接入一个softmax层进行分类,并且在全连接部分使用Dropout,减少过拟合。
最后的结果

从结果看
CNN-static较与CNN-rand好,说明pre-training的word vector确实有较大的提升作用(这也难怪,因为pre-training的word vector显然利用了更大规模的文本数据信息);
CNN-non-static较于CNN-static大部分要好,说明适当的Fine tune也是有利的,是因为使得vectors更加贴近于具体的任务;
CNN-multichannel较于CNN-single在小规模的数据集上有更好的表现,实际上CNN-multichannel体现了一种折中思想,即既不希望Fine tuned的vector距离原始值太远,但同时保留其一定的变化空间。
下面总结一下Ye Zhang等人基于Kim Y的模型做了大量的调参实验之后的结论(核心)
由于模型训练过程中的随机性因素,如随机初始化的权重参数,mini-batch,随机梯度下降优化算法等,会造成模型在数据集上的结果有一定的浮动
词向量是使用word2vec还是GloVe,对实验结果有一定的影响,具体哪个更好依赖于任务本身;
Filter的大小对模型性能有较大的影响,并且Filter的参数应该是可以更新的;
Feature Map的数量也有一定影响,但是需要兼顾模型的训练效率;
1-max pooling的方式已经足够好了,相比于其他的pooling方式而言;
正则化的作用微乎其微。
调参建议
1:word2vec和Glove比单纯的one-hot效果好的多(似乎没毛病)
2:最优的Filter的大小可以通过线性搜索确定,但是过滤器的大小在1-10口味食用最佳。
3:Feature Map在100-600之间
4:激活函数tanh和Relu效果很好
5:最大池化效果就很不错了
6:适当使用正则化手段,比如调节dropout的概率
7:反复交叉验证检验模型的水平。
参考资料:
1:Kim Y. Convolutional neural networks for sentence classification[J]. arXiv preprint arXiv:1408.5882, 2014.
2:A Sensitivity Analysis of (and Practitioners' Guide to) Convolutional Neural Networks for Sentence Classification Ye Zhang, Byron Wallace
3:Convolutional Neural Networks for Sentence Classification