【数据分析day03】pandas“层次化索引对象”的多层索引,切片,stack
pandas“层次化索引对象”的多层索引,切片,stack
- Series创建多层索引
- DataFrame创建多层索引
- Series(多层索引对象)的索引和切片
- DataFrame(多层索引对象)的索引和切片
- 元素的索引 (显式,隐式)
- 小结:
- 坑点
- 索引的堆(stack)
导入 (常规操作)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from pandas import DataFrame, Series
Series创建多层索引
index = [['一班', '一班', '一班', '二班', '二班','二班'], ['张三', '李四', '王五', '赵六', '田七', '孙八']]
data = np.random.randint(0, 150, size=6)
s = Series(index=index, data=data)
s

DataFrame创建多层索引
两种方式:隐式和显示
-
隐式构造
最常见的方法是给DataFrame构造函数的index参数传递两个或更多的数组index = [['一班', '一班', '一班', '二班', '二班','二班'], ['张三', '李四', '王五', '赵六', '田七', '孙八']] columns = [['期中', '期中', '期中', '期末', '期末', '期末'], ['语文', '数学', '英语', '语文', '数学', '英语']] data = np.random.randint(0, 150, size=(6,6)) df = DataFrame(data=data, index=index, columns=columns) df

2. 显示构造 (三种方式):
- 使用数组
- 使用tuple
- 使用乘积(product)
2.1) 使用数组
index = pd.MultiIndex.from_arrays([['一班', '一班', '一班', '二班', '二班','二班'], ['张三', '李四', '王五', '赵六', '田七', '孙八']])
columns = pd.MultiIndex.from_arrays([['期中', '期中', '期中', '期末', '期末', '期末'], ['语文', '数学', '英语', '语文', '数学', '英语']])
data = np.random.randint(0, 150, size=(6,6))
df = DataFrame(data=data, index=index, columns=columns)
df
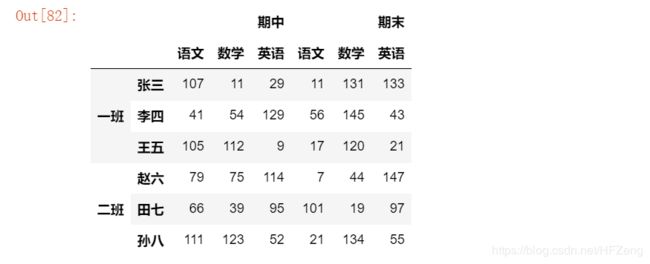
2.2) 使用 元组
index = pd.MultiIndex.from_tuples((('一班', '张三'), ('一班', '王五'), ('一班', '李四'), ('二班', '赵六'), ('二班', '田七'), ('二班', '孙八')))
columns = [['期中', '期中', '期中', '期末', '期末', '期末'], ['语文', '数学', '英语', '语文', '数学', '英语']]
data = np.random.randint(0, 150, size=(6,6))
df = DataFrame(data=data, index=index, columns=columns)
df
2.3) 使用乘积(product)
index = pd.MultiIndex.from_product([['一班', '二班'], ['张三', '李四', '王五']], sortorder=1)
columns = pd.MultiIndex.from_product([['期中','期末'], ['语文', '数学', '英语']], sortorder=0)
data = np.random.randint(0, 150, size=(6,6))
df = DataFrame(data=data, index=index, columns=columns)
df
注意:这里使用乘积有个局限性,行/列 的level 1的值要相同
Series(多层索引对象)的索引和切片
索引:分显示和隐式
【重要】对于Series来说,直接中括号[]与使用.loc()完全一样,推荐使用中括号索引和切片。

-
显示索引
多层索引的基本原则就是: 必须从最外层索引开始索引, 不能直接索引最内侧层索引.s.loc[['一班'], ['张三']]

-
隐式索引(不区分层级索引)
s.iloc[[0]]
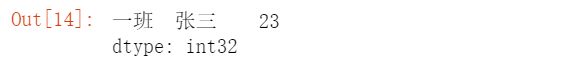
!----------------------------------------------------------------------------------
切片也分显式和隐式
显式索引切片.只能切最外层
s.loc['一班': '二班']

隐式索引的切片
s.iloc[0:2]

DataFrame(多层索引对象)的索引和切片
多层索引
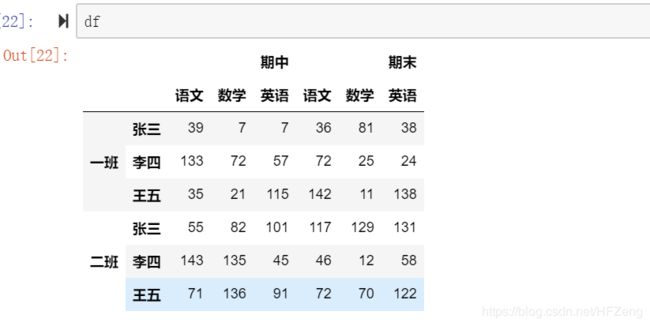
1)列索引 :可以直接使用列名称来进行列索引,没有显式索引
例子:索引“期中-语文”
df['期中', '语文']
# ()表示是一个整体. 推荐写法:
df[('期中', '语文')]
# 不推荐写法
df.期中.语文
#列索引可以有隐式索引:
df.iloc[:, 0] #索引全部行,第0列

2)行索引
显式:
# 显式索引
df.loc[[('一班', '张三')]] #外层[ ] 表示返回原数据类型(df)
隐式:
# 隐式索引
df.iloc[[0]]

!----------------------------------------------------------------------------------------------
切片
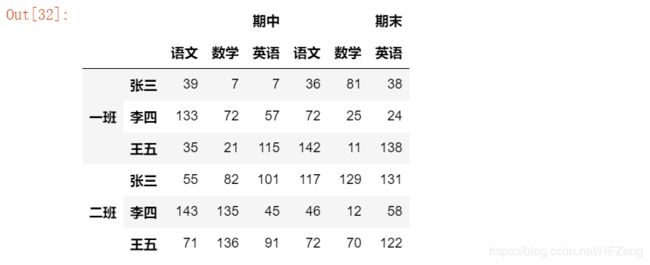
1)列切片(显式,隐式)
显式:
# 注意:切片不要在外层加括号
df.loc[:, '期中': '期末']
隐式:
# 隐式切片
df.iloc[:, 0: 4]
2)行切片 (显式,隐式)
显式:
df.loc[('一班', '张三'): ('二班', '张三')]

隐式:
# 隐式切片.
df.iloc[0:4]

元素的索引 (显式,隐式)

显式:
# 最推荐的写法, 先行后列, 行列索引用括号括起来.
df.loc[('一班', '张三'), ('期中', '语文')]
隐式:
df.iloc[0,0]
![]()
链式(不推荐):先列后行
# 错误示范,链式索引,赋值没成功. 无法预测的结果.
df['期中']['数学']['一班']['张三'] = np.nan
小结:
1, 列索引直接使用中括号, 行索引用.loc[], 隐式索引用.iloc[]
2, 多层索引,不能直接索引内层索引,需要从外层索引开始, 可以用括号括起来, 表示是同一级的索引.
坑点
为了解决unsortedindexerror的报错问题,要使用sortorder参数设定排序规则

索引的堆(stack)
stack() :就是把列索引 变成 行索引 (列 --> 行)
unstack() :行索引–> 列索引

# 默认是把最里面一层的列索引变成行索引.(即默认level=-1)
df.stack() #把语数英堆起来

# 期中,期末 是level 0,
# 语数英是level 1 (也可认为是最里层,默认 level -1)倒数第一层
df.stack(level=0) #把期中,期末堆起来

unstack是stack的反向操作.即行索引变成列索引.
df.unstack(level=0) # 把一班二班扔上去

df.unstack(fill_value=0)
