我们在前几节介绍过卷积网络的运算原理,以及通过代码实践,体验到了卷积网络对图片信息抽取的有效性。现在一个问题在于,我们知道卷积网络的运算过程,但不知道为什么卷积运算过程就能有效的识别图片,也就是说我们知其然但不知其所以然,这节我们通过视觉化的方式看看卷积网络是怎么从图片中抽取出有效信息的。
从2013年起,研究人员找到了不少有效的视觉化方法去研究卷积网络对图片信息的学习过程,通过视觉化呈现,我们人类可以有效的认识到卷积网络的学习过程。我们将通过视觉化的方式看看卷及网络的每一层是如何提取图片信息的,然后再通过视觉展现的方式看看Max Pooling层的作用。我们先看看我们自己构造的网络是怎么对图片进行学习的,卷积网络会对图片数据进行层层计算和过滤,我们把它过滤后的数据“画”出来看看,首先我们先把前两节训练好的网络加载进来:
from keras.models import load_model
#我们前几节在训练网络后,曾经以下面名字把训练后的网络存储起来,现在我们重新将它加载
model = load_model('cats_and_dogs_small_2.h5')
model.summary()
大家可以翻看我们前几节的代码,那时在训练好网络后,我们会将其存储起来,现在我们把那时存储的网络重新加载到内存中。上面代码运行后结果如下:
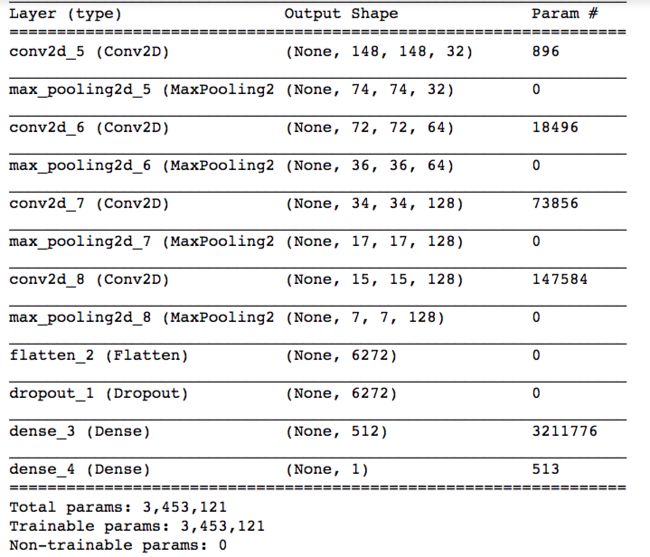
从上面结果看到,我们的网络有好几个卷积层和Max pooling层,我们用一张图片传入网络,每一层会对图片进行计算,然后抽取信息,我们把每一层抽取的信息绘制出来看看。我们加载一张图片,对其做一些数据变换,然后把图片绘制出来看看:
img_path = '/Users/chenyi/Documents/人工智能/all/cats_and_dogs_small/test/cats/cat.1700.jpg'
from keras.preprocessing import image
import numpy as np
import matplotlib.pyplot as plt
#把图片缩小为150*150像素
img = image.load_img(img_path, target_size = (150,150))
img_tensor = image.img_to_array(img)
img_tensor = np.expand_dims(img_tensor, axis = 0)
#把像素点取值变换到[0,1]之间
img_tensor /= 255.
print(img_tensor.shape)
plt.figure()
plt.imshow(img_tensor[0])
上面代码运行后结果如下:

我们把网络中的前八层,也就是含有卷积和Max pooling的网络层单独抽取出来,代码如下:
from keras import models
import matplotlib.pyplot as plt
'''
我们把网络的前8层,也就是含有卷积和max pooling的网络层抽取出来,
下面代码会把前八层网络的输出结果放置到数组layers_outputs中
'''
layer_outputs = [layer.output for layer in model.layers[:8]]
activation_model = models.Model(inputs=model.input, outputs = layer_outputs)
#执行下面代码后,我们能获得卷积层和max pooling层对图片的计算结果
activations = activation_model.predict(img_tensor)
#我们把第一层卷积网络对图片信息的识别结果绘制出来
first_layer_activation = activations[0]
print(first_layer_activation.shape)
plt.figure()
plt.matshow(first_layer_activation[0, :, : , 4], cmap = 'viridis')
上面代码专门抽取出网络中包含卷积和max pooling的前八层,然后把上面的图片传入,这八层网络层会分别从图片中抽取信息,上面代码把第一次卷积层从图片中获取的信息绘制出来,上面代码运行结果如下:

大家看的上面图片就是第一层卷积网络从原图片中抽取出来的信息。网络层获得的信息表示是148*148*32,也就是抽取出的图像大小是148*148个像素,其中每个像素对应一个含有32个元素的向量,我们只把向量中前4个元素表示的信息视觉化,如果我们把前7个元素视觉化看看,其代码如下:
plt.figure()
plt.matshow(first_layer_activation[0, :, : , 7], cmap = 'viridis')
上面代码运行结果如下,注意你自己运行结果跟我很可能不一样,因为网络对图像的学习结果与它所运行的环境相关,不是确定性的:
上面结果表明网络把绿色值高的像素点抽取出来了。接下来我们用代码把每一层卷积运算后所识别的图片信息绘制出来:
layer_names = []
for layer in model.layers[:8]:
layer_names.append(layer.name)
images_per_row = 16
for layer_name, layer_activation in zip(layer_names, activations):
#layer_activation的结构为(1, width, height, array_len)
#向量中的元素个数
n_features = layer_activation.shape[-1]
#获得切片的宽和高
size = layer_activation.shape[1]
#在做卷积运算时,我们把图片进行3*3切片,然后计算出一个含有32个元素的向量,这32个元素代表着网络从3*3切片中抽取的信息
#我们把这32个元素分成6列,绘制在一行里
n_cols = n_features // images_per_row
display_grid = np.zeros((size * n_cols, images_per_row * size))
for col in range(n_cols):
for row in range(images_per_row):
channel_image = layer_activation[0, : , :, col * images_per_row + row]
#这32个元素中,不一定每个元素对应的值都能绘制到界面上,所以我们对它做一些处理,使得它能画出来
channel_image -= channel_image.mean()
channel_image /= channel_image.std()
channel_image *= 64
channel_image += 128
channel_image = np.clip(channel_image, 0, 255).astype('uint8')
display_grid[col * size : (col + 1) * size, row * size : (row + 1) * size] = channel_image
scale = 1. / size
plt.figure(figsize = (scale * display_grid.shape[1], scale * display_grid.shape[0]))
plt.title(layer_name)
plt.grid(False)
plt.imshow(display_grid, aspect = 'auto', cmap = 'viridis')
上面代码运行后,得到的部分结果如下:
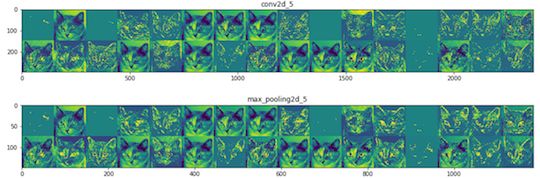
上图表示的是,第一次卷积网络从图片中抽取处理的信息,它主要抽取猫的边缘,经过第一层后,原来图片的很多信息还保留着,这些信息将交由后面的卷积网络继续抽取,我再看看最后一层网络抽取出来的信息:
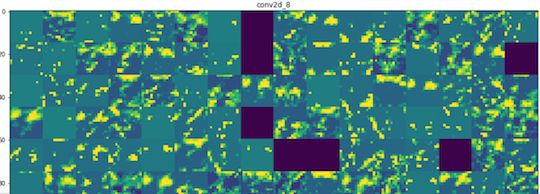
随着卷积网络的层次越高,它抽取出的信息就越抽象,就越难以被人的直觉所理解。我们把卷积层对图片的识别结果绘制出来,从中我们能观察到,网络层次越高,对图片所表示规律的抽取越深,它展现出来就越抽象,这些抽象特性可能表示所有猫所具备的共同特质,神经网络就如同信息抽取蒸馏管,每经过一处,图片中包含的噪音就去除掉一层,网络就越能得到越纯粹的该类图片所表示的共同信息。
这个过程与人的认知过程很像,我们看几张猫图片后,就能够把世界上所有的猫都识别出来,我们并没有看到黑猫图片后,给一只白猫就认不出来,因此人通过视觉把图像传送到脑中后,脑神经通过层层运算,把图像中蕴含的本质信息抽取出来,于是人看到一张黑猫的图片,就把其中蕴含的“猫”的抽象信息获取,下次看到一只白猫时,大脑也把白猫所表示的“猫”的抽象信息获取到,两者一比对,大脑就知道,黑猫白猫本质上是同一类事物。加入让你绘制一个骑自行车的人,我们大多数人都会画出如下形式:
上面图案表示着我们对“人其自行车”的概念性,抽象认知,我们看到任何骑自行车的人,我们都会抽象出上面这幅图案,我们把各种无关的信息取出掉,例如背景,人的衣服,形态等,无关紧要的信息全部去光后,就会得到上面的信息。
更详细的讲解和代码调试演示过程,请点击链接
更多技术信息,包括操作系统,编译器,面试算法,机器学习,人工智能,请关照我的公众号:
