文章转自【机器学习炼丹术】
线性回归解决的是回归问题,逻辑回归相当于是线性回归的基础上,来解决分类问题。
1 公式
线性回归(Linear Regression)是什么相比不用多说了。格式是这个样子的:
$f_{w,b}(x)=\sum_i{w_ix_i}+b$
而逻辑回归(Logistic Regression)的样子呢?
$f_{w,b}(x)=\sigma(\sum_i{w_ix_i}+b)$
要记住的第一句话:逻辑回归可以理解为在线性回归后加了一个sigmoid函数。将线性回归变成一个0~1输出的分类问题。
2 sigmoid
sigmoid函数就是:
$\sigma(z)=\frac{1}{1+e^{-z}}$
函数图像是:
线性回归得到大于0的输出,逻辑回归就会得到0.5~1的输出;
线性回归得到小于0的输出,逻辑回归就会得到0~0.5的输出;
这篇文章的重点,在于线性回归的参数估计使用的最小二乘法,而而逻辑回归使用的是似然估计的方法。(当然,两者都可以使用梯度下降的方法)。
3 似然估计逻辑回归参数
举个例子,现在我们有了一个训练数据集,是一个二分类问题:
上面的$x^1$是样本,下面的$C_1$是类别,总共有两个类别。
现在假设我们有一个逻辑回归的模型:
$f_{w,b}(x)=\sigma(\sum_i{w_ix_i}+b)$
那么$f_{w,b}(x^1)$的结果,就是一个0~1的数,我们可以设定好,假设这个数字就是是类别$C_1$的概率,反之,1减去这个数字,就是类别$C_2$的概率。
似然简单的理解,就是让我们上面的数据集出现的概率最大
我们来理解一下:
- $x_1$是$C_1$的概率是$f_{w,b}(x^1)$;
- $x_2$是$C_1$的概率是$f_{w,b}(x^2)$;
- $x_3$是$C_2$的概率是$1-f_{w,b}(x^3)$;
- ……
- $x_N$是$C_1$的概率是$f_{w,b}(x^N)$;
样本之间彼此独立,那么上面那个数据集的概率是什么?是每一个样本的乘积,这个就是似然Likelihood: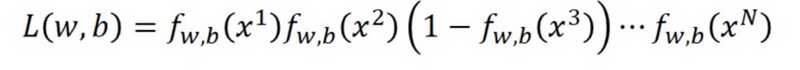
我们希望这个w,b的参数估计值,就是能获得最大化似然的那个参数。也就是: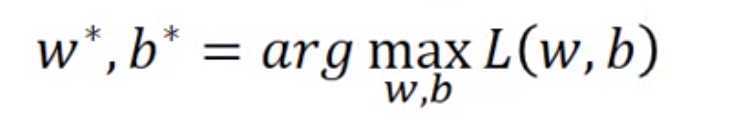
加上负号之后,就可以变成最小化的问题。当然,加上一个log并不会影响整个的w,b的估计值。因为$L(w,b)$最大的时候,$log(L(w,b))$也是最大的,log是个单调递增的函数。所以可以得到下面的:
【注意:所有的log其实是以e为底数的自然对数】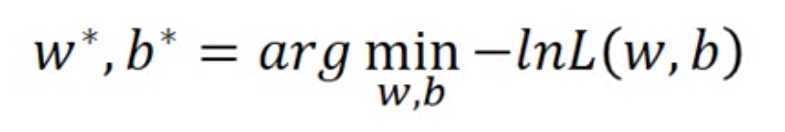
log又可以把之前的乘积和,转换成加法。
$log(L(w,b))=log(f(x^1))+log(f(x^2))+log(1-f(x^3))...$
然后,为了更加简化这个算是,我们将$C_1, C_2$数值化,变成1和0,然后每一个样本的真实标签用$y$来表示,所以就可以得到:
$log(L(w,b))=\sum_i^N{ylog(f(x^i))+(1-y)log(1-f(x^i))}$
【有点像是二值交叉熵,然而其实就是二值交叉熵。。】
- 当y=1,也就是类别是$C_1$的时候,这个是$log(f(x^i))$
- 当y=0,也就是类别是$C_2$的时候,这个是$1-log(f(x^i))$
所以其实我们得到的损失函数是:
$loss=-log(L(w,b))=-\sum_i^N{ylog(f(x^i))+(1-y)log(1-f(x^i))}$
之前说了,要找到让这个loss最小的时候的w和b,那怎么找?
【无情万能的梯度下降】
所以计算$\frac{\partial loss}{\partial w}$,然后乘上学习率就好了。这里就不继续推导了,有耐心的可以慢慢推导,反正肯定能推出来的。
这里放个结果把:
$\frac{-\partial lnL(w,b)}{\partial w_i}=\sum_n^N{-(y^n-f_{w,b}(x^n))x_i^n}$
- 其中$w_i$为第i个要估计的参数,第i个特征;
- $x^n_i$是第n个样本的第i个特征的值;
- $y^n$是第n个样本的真实类别,0或者1。