MySQL学习笔记索引篇:索引基本原理
目录
硬盘读写过程
数据库加载数据的过程
块与页
索引基本原理
索引的优点
索引的种类
聚簇索引
非聚簇索引
硬盘读写过程
确定磁盘地址(柱面号,磁头号,扇区号),内存地址(源/目):
当需要从磁盘读取数据时,系统会将数据逻辑地址传给磁盘,磁盘的控制电路按照寻址逻辑将逻辑地址翻译成物理地址,即确定要读的数据在哪个磁道,哪个扇区。
为了读取这个扇区的数据,需要将磁头放到这个扇区上方,为了实现这一点:
1)首先必须找到柱面,然后磁头需要对准相应磁道,这个过程叫做寻道,所耗费时间叫做寻道时间,这个过程最慢,因为选取磁头只需通过电子切换即可,而选取柱面则必须通过机械切换。
2)然后目标扇区旋转到磁头下,即磁盘旋转将目标扇区旋转到磁头下。这个过程耗费的时间叫做旋转时间。
即一次访盘请求(读/写)完成过程由三个动作组成:
1)寻道(时间):磁头移动定位到指定磁道
2)旋转延迟(时间):等待指定扇区从磁头下旋转经过
3)数据传输(时间):数据在磁盘与内存之间的实际传输
数据库加载数据的过程
块与页
块是数据库最小的数据操作单位,数据库中以块(4KB,8KB,16KB..)为最小单位对数据进行划分,但磁盘中并没有块这个概念。
数据库对数据的修改需要加载到内存中进行,所以数据库一次读取通常会读取多个块,称为连续读。但是内存空间有限,当内存中的数据块过多时需要被淘汰,这时则需要使用lru算法将数据写回磁盘。这样一来一回就会导致原本连续的数据块一部分存在于内存中,一部分在磁盘中,所以再加载这些块时就会发生许多的随机读。有些数据块的分布不容易被确定,但是一些索引的顺序是可以被确定的,因为索引本身是有序的,尤其是基于自动增长类的索引。
索引基本原理
索引可以提高查找性能,也会降低写性能。
索引也是数据,他的存储原理和数据类似。但索引不会存储整行数据,而是存储索引对应的字段内容,然后通过某种标识符与原表关联起来。这种标识符在某些数据上体现为数据的物理位置,或者是主键值。
索引通常没有存储整行数据,所以在一个索引的数据块内可以存储的行会比在数据块中存放的数据行多很多。
查找数据分为两个过程,首先通过索引查找到对应的标识符,然后通过这个标识符找到原表中对应的数据(这个动作称为回表),这使查找数据需要进行两次磁盘IO。如果索引中存在需要查找的数据,那么就不需要进行回表操作。
正常情况下,向表的数据块中修改一行数据,就会向索引块中写入一条数据,而当修改表中的数据时,如果修改到索引字段,索引通常使先删除再插入,删除的方式是在旧索引的位置打一个作废的标记,当存在很多作废的索引时,会重建索引。
当插入数据时,如果数据很少,一个块空间就足以存储,当数据量增大时,就会涉及到块的分裂。
索引的优点
- 索引减少了服务器需要扫描的数据量。
- 索引可以帮助服务器避免排序和临时表。
- 索引可以将随机IO变为顺序IO。
索引的种类
普通索引:最基本的索引,没有任何限制
唯一索引
- 唯一索引不允许两行具有相同的索引值。
- 如果现有数据中存在重复的键值,则大多数数据库都不允许将新创建的唯一索引与表一起保
- 存。当新数据将使表中的键值重复时,数据库也拒绝接受此数据。
- 例如,如果在employee 表中的职员姓氏(lname) 列上创建了唯一索引,则所有职员不能同姓。
主键索引
- 主键索引是唯一索引的特殊类型。
- 数据库表通常有一列或列组合,其值用来唯一标识表中的每一行。该列称为表的主键。
- 在数据库关系图中为表定义一个主键将自动创建主键索引,主键索引是唯一索引的特殊类型。
- 主键索引要求主键中的每个值是唯一的。
- 当在查询中使用主键索引时,它还允许快速访问数据。
组合索引:为了更多的提高mysql效率可建立组合索引,遵循”最左前缀“原则。
聚簇索引
将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据,也就是索引即数据。
聚簇索引的数据的物理存放顺序与索引顺序是一致的,即:只要索引是相邻的,那么对应的数据一定也是相邻地存放在磁盘上的。
如果主键不是自增id,那么可以想 象,它会干些什么,不断地调整数据的物理地址、分页,当然也有其他一些措施来减少这些操作,但却无法彻底避免。但,如果是自增的,那就简单了,它只需要一 页一页地写,索引结构相对紧凑,磁盘碎片少,效率也高。
在innodb中,在聚簇索引之上创建的索引称之为辅助索引(二级索引),非聚簇索引都是辅助索引,像复合索引、前缀索引、唯一索引。
辅助索引叶子节点存储的不是行的物理位置,而是主键值,辅助索引访问数据总是需要二次查找。这样做的好处就是InnoDB在移动行时无须更新二级索引中的主键值,可以避免对二级索引的维护工作,只需要维护聚簇索引树就好了。另一个好处是,因为辅助索引存放的是主键值,减少了辅助索引占用的存储空间大小。
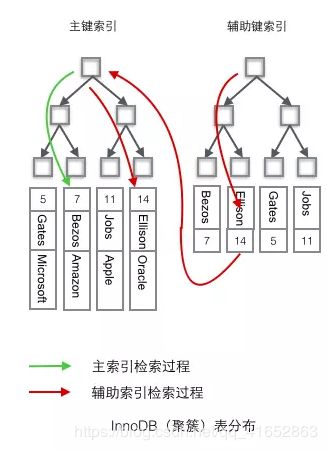
- InnoDB使用的是聚簇索引,将主键组织到一棵B+树中,而行数据就储存在叶子节点上,若使用"where id = 14"这样的条件查找主键,则按照B+树的检索算法即可查找到对应的叶节点,之后获得行数据。
- 若对Name列进行条件搜索,则需要两个步骤:第一步在辅助索引B+树中检索Name,到达其叶子节点获取对应的主键。第二步使用主键在主索引B+树种再执行一次B+树检索操作,最终到达叶子节点即可获取整行数据。(重点在于通过其他键需要建立辅助索引)
聚簇索引的优点
- 可以把相关的数据保存在一起。
- 数据访问更快。聚簇索引将索引和数据保存在同一个B+树种,因此聚簇索引中获取数据通常比在非聚簇索引中查找要快。
- 聚簇索引最大限度的提高了I/O密集型应用的性能。
聚簇索引的缺点
- 更新聚簇索引列的代价很高,因为会强制InnoDB将每个被更行的行移动到新的位置。
- 基于聚簇索引的表在插入新行,或者主键被更新导致需要移动行的时候,可能面临页分裂问题。页分裂会导致表占用更多的磁盘空间。
- 二级索引的叶子节点包含了引用行的主键列,索引占用的空间页不小。
非聚簇索引
将数据与索引分开存储,索引结构的叶子节点指向了数据对应的位置
MyISAM使用的是非聚簇索引,非聚簇索引的两棵B+树看上去没什么不同,节点的结构完全一致只是存储的内容不同而已,主键索引B+树的节点存储了主键,辅助键索引B+树存储了辅助键。
表数据存储在独立的地方,这两颗B+树的叶子节点都使用一个地址指向真正的表数据,对于表数据来说,这两个键没有任何差别。由于索引树是独立的,通过辅助键检索无需访问主键的索引树。
