CVPR目标检测与实例分割算法解析:FCOS(2019),Mask R-CNN(2019),PolarMask(2020)
CVPR目标检测与实例分割算法解析:FCOS(2019),Mask R-CNN(2019),PolarMask(2020)
- 目标检测:FCOS(CVPR 2019)
目标检测算法FCOS(FCOS: Fully Convolutional One-Stage Object Detection),该算法是一种基于FCN的逐像素目标检测算法,实现了无锚点(anchor-free)、无提议(proposal free)的解决方案,并且提出了中心度(Center—ness)的思想,同时在召回率等方面表现接近甚至超过目前很多先进主流的基于Anchor
box目标检测算法。
基于像素级预测一阶全卷积目标检测(FCOS)来解决目标检测问题,类似于语音分割。目前大多数先进的目标检测模型,例如RetinaNet、SSD、YOLOv3、Faster
R-CNN都依赖于预先定义的Anchor box。相比之下,本文提出的FCOS是anchor box free,而且也是proposal free,就是不依赖预先定义的Anchor box或者提议区域。通过去除预先定义的Anchor box,FCOS完全的避免了关于Anchor box的复杂运算,例如训练过程中计算重叠度,而且节省了训练过程中的内存占用。更重要的是,本文避免了和Anchor box有关且对最终检测结果非常敏感的所有超参数。由于后处理只采用非极大值抑制(NMS),所以本文提出的FCOS比以往基于Anchor box的一阶检测器具有更加简单的优点。
Anchor box缺点
l 检测表现效果对于Anchor
box的尺寸、长宽比、数目非常敏感,因此Anchor box相关的超参数需要仔细的调节。
l Anchor
box的尺寸和长宽比是固定的,因此,检测器在处理形变较大的候选对象时比较困难,尤其是对于小目标。预先定义的Anchor box还限制了检测器的泛化能力,因为,它们需要针对不同对象大小或长宽比进行设计。
l 为了提高召回率,需要在图像上放置密集的Anchor
box。而这些Anchor box大多数属于负样本,这样造成了正负样本之间的不均衡。
l 大量的Anchor
box增加了在计算交并比时计算量和内存占用。
FCOS详细介绍
FCOS优势
l FCOS与许多基于FCN的思想是统一的,因此可以更轻松的重复使用这些任务的思路。
l 检测器实现了proposal free和anchor free,显著的减少了设计参数的数目。设计参数通常需要启发式调整,并且设计许多技巧。另外,通过消除Anchor box,新探测器完全避免了复杂的IOU计算以及训练期间Anchor box和真实边框之间的匹配,并将总训练内存占用空间减少了2倍左右。
l FCOS可以作为二阶检测器的区域建议网络(RPN),其性能明显优于基于锚点的RPN算法。
l FCOS可以经过最小的修改便可扩展到其他的视觉任务,包括实例分割、关键点检测。
算法详细介绍

1.1全卷积一阶检测器
FCOS首先使用Backone CNN(用于提取特征的主干架构CNN),另s为feature map之前的总步伐。
与anchor-based检测器的区别
第一点
·
anchor-based算法将输入图像上的位置作为Anchor box的中心店,并且对这些Anchor box进行回归。
·
FCOS直接对feature map中每个位置对应原图的边框都进行回归,换句话说FCOS直接把每个位置都作为训练样本,这一点和FCN用于语义分割相同。
FCOS算法feature
map中位置与原图对应的关系,如果feature map中位置为 ,映射到输入图像的位置是
。
第二点
·
在训练过程中,anchor-based算法对样本的标记方法是,如果anchor对应的边框与真实边框(ground truth)交并比大于一定阈值,就设为正样本,并且把交并比最大的类别作为这个位置的类别。
·
在FCOS中,如果位置
落入任何真实边框,就认为它是一个正样本,它的类别标记为这个真实边框的类别。
这样会带来一个问题,如果标注的真实边框重叠,位置
映射到原图中落到多个真实边框,这个位置被认为是模糊样本,后面会讲到用多级预测的方式解决的方式解决模糊样本的问题。
第三点
·
以往算法都是训练一个多元分类器
·
FCOS训练C个二元分类器(C是类别的数目)
与anchor-based检测器相似之处
与anchor-based算法的相似之处是FCOS算法训练的目标同样包括两个部分:位置和类别。
FCOS算法的损失函数为:

其中![]() 是类别损失,
是类别损失, ![]() 是交并比的损失。
是交并比的损失。
-
- 用FPN对FCOS进行多级预测
首先明确两个问题:
l 基于Anchor box的检测器由于大的步伐导致低召回率,需要通过降低正的Anchor
box所需的交并比分数来进行补偿:在FCOS算法中表明,及时是大的步伐(stride),也可以获取较好的召回率,甚至效果可以优于基于Anchor box的检测器。
l 真实边框中的重叠可能会在训练过程中造成难以处理的歧义,这种模糊性导致基于fcn的检测器性能下降:在FCOSzhong ,采用多级预测方法可以有效地解决模糊问题,与基于Anchor box的模糊检测器相比,基于模糊控制器的模糊检测器具有更好的性能。
前面提到,为了解决真实边框重叠带来的模糊性和低召回率,FCOS采用类似FPN中的多级检测,就是在不同级别的特征层检测不同尺寸的目标。
与基于Anchor box不同的地方
·
基于Anchor
box的检测器将不同尺寸的Anchor box分配到不同级别的特征层
·
FCOS通过直接限定不同特征级别的边界框的回归范围来进行分配
此外,FCOS在不同的特征层之间共享信息,不仅使检测器的参数效率更高,而且提高了检测性能。
3.Center-ness

通过多级预测之后发现FCOS和基于Anchor box的检测器之间仍然存在着一定的距离,主要原因是距离目标中心较远的位置产生很多低质量的预测边框。
在FCOS中提出了一种简单而有效的策略来抑制这些低质量的预测边界框,而且不引入任何超参数。具体来说,FCOS添加单层分支,与分类分支并行,以预测"Center-ness"位置。
center-ness(可以理解为一种具有度量作用的概念,在这里称之为"中心度"),中心度取值为0,1之间,使用交叉熵损失进行训练。并把损失加入前面提到的损失函数中。测试时,将预测的中心度与相应的分类分数相乘,计算最终得分(用于对检测到的边界框进行排序)。因此,中心度可以降低远离对象中心的边界框的权重。因此,这些低质量边界框很可能被最终的非最大抑制(NMS)过程滤除,从而显着提高了检测性能。
实验结果
1)召回率

在召回率方便表现接近目前最先进的基于Anchor box的检测器。
2)有无Center-ness的结果对比
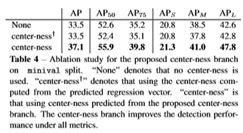
“None”表示没有使用中心。“中心度”表示使用预测回归向量计算得到的中心度。“中心度”是指利用提出的中心度分支预测的中心度。中心度分支提高了所有指标下的检测性能。
3)与先进的一阶、二阶检测器效果对比

与目前最主流的一些一阶、二阶检测器对比,在检测效率方面FCOS优于Faster R-CNN、YOLO、SSD这些经典算法。

- Mask R-CNN(CVPR 2019)
首先回顾一下之前最经典的实例分割方法,‘先检测再分割’,在这方面做到极致的算法是Mask
RCNN。

Mask R-CNN属于基于两阶段的检测算法,在检测框的基础上进行像素级的语义分割,简化了实例分割的难度,同时取得了stoa的性能,在’先检测再分割’ 这一范式上做到了极致。
2.1. 简介
Mask R-CNN是He
Kaiming大神2017年的力作,其在进行目标检测的同时进行实例分割,取得了出色的效果,其在没有任何trick的情况下,取得了COCO 2016比赛的冠军。其网络的设计也比较简单,在Faster R-CNN基础上,在原本的两个分支上(分类+坐标回归)增加了一个分支进行语义分割,如下图所示:
2.2. Mask R-CNN详细介绍
那么为什么该网络会有如此好的效果,又有哪些网络细节呢?下面详细逐一介绍。
在介绍Mask R-CNN之前,首先了解一下什么是分割,因为Mask R-CNN是做这个的,所以这个首先要搞清楚,看下图,主要介绍了几种不同的分割,其中Mask RCNN做的是其中的instance segmentation.
语义分割(semantic segmentation):对图像中逐像素进行分类。
实例分割(instance segmentation):对图像中的object进行检测,并对检测到的object进行分割。
全景分割(panoptic segmentation):对图像中的所有物体进行描述。
下面这张图很好的表示了这几者分割的区别,如下图可见,全景分割的难度最大:
Mask R-CNN如何取得好结果
首先实例分割(instance segmentation)的难点在于:需要同时检测出目标的位置并且对目标进行分割,所以这就需要融合目标检测(框出目标的位置)以及语义分割(对像素进行分类,分割出目标)方法。在Mask R-CNN之前,Faster R-CNN在目标检测领域表现较好,同时FCN在语义分割领域表现较好。所以很自然的方法是将Faster R-CNN与FCN相结合嘛,作者也是这么干的,只是作者采用了一个如此巧妙的方法进行结合,并且取得了amazing的结果。
在以前的instance segmentation中,往往是先分割然后识别,这往往是低效的,并且准确率较低,就比如Dai【论文中提到的】,采用级联的方法,先通过bounding-boxes生成segment区域,然后进行分类。
那么Mask R-CNN是怎么做的呢?
Mask R-CNN是建立在Faster R-CNN基础上的,那么我们首先回顾一下Faster R-CNN,Faster R-CNN是典型的two stage的目标检测方法,首先生成 RPN候选区域, 然后候选区域经过Roi Pooling进行目标检测(包括目标分类以及坐标回归),分类与回归共享前面的网络。
Mask R-CNN做了哪些改进?Mask R-CNN同样是two stage的,生成RPN部分与Faster R-CNN相同,然后,Mask R-CNN在Faster R-CNN的基础上,增加了第三个支路,输出每个ROI的Mask(这里是区别于传统方法的最大的不同,传统方法一般是先利用算法生成mask然后再进行分类,这里平行进行)
自然而然,这变成一个多任务问题
网络结构如下
下图所示是两种典型的Mask R-CNN网络结构,作者借鉴FPN(不了解FPN可以点击参考此博文)的思想,分别设计了两种网络结构,左边的是采用ResNet or
ResNeXt作为网络的backbone提取特征,右边的网络采用FPN网络作为backbone进行特征提取,并且作者指明,使用FPN作为基础网络的效果其实是最好的。

损失函数的设计是网络的精髓所在
Mask R-CNN的损失函数为:
![]()
这里主要介绍一下 ![]() 是对每个像素进行分类,其含有K∗m∗m维度的输出,K代表类别的数量,m*m是提取的ROI图像的大小。
是对每个像素进行分类,其含有K∗m∗m维度的输出,K代表类别的数量,m*m是提取的ROI图像的大小。![]() 被定义为 average binary cross-entropy loss(平均二值交叉熵损失函数)。这里解释一下是如何计算的,首先分割层会输出channel为K的Mask,每个Mask对应一个类别,利用sigmoid函数进行二分类,判断是否是这个类别,然后在计算loss的时候,假如ROI对应的ground-truth的类别是
被定义为 average binary cross-entropy loss(平均二值交叉熵损失函数)。这里解释一下是如何计算的,首先分割层会输出channel为K的Mask,每个Mask对应一个类别,利用sigmoid函数进行二分类,判断是否是这个类别,然后在计算loss的时候,假如ROI对应的ground-truth的类别是![]() ,则计算第
,则计算第![]() 个mask对应的loss,其他的mask对这个loss没有贡献计算二值交叉熵搞的公式如下图中的函数接口。这里不同于FCN的是,FCN是对每个像素进行softmax分类,分为K个类别,然后计算softmax loss。那在inference的时候选择哪个mask作为最终的输出呢?作者根据分类分支的预测结果进行判断,是不是很神奇,并且作者解释到,利用这种方法比softmax效果要好,因为简化了loss并且利用了分类信息,应该会有提升的。
个mask对应的loss,其他的mask对这个loss没有贡献计算二值交叉熵搞的公式如下图中的函数接口。这里不同于FCN的是,FCN是对每个像素进行softmax分类,分为K个类别,然后计算softmax loss。那在inference的时候选择哪个mask作为最终的输出呢?作者根据分类分支的预测结果进行判断,是不是很神奇,并且作者解释到,利用这种方法比softmax效果要好,因为简化了loss并且利用了分类信息,应该会有提升的。
另一个创新点:ROI Align
另外由于分割需要较准确的像素位置,而Faster R-CNN方法中,在进行Roi-Pooling之前需要进行两次量化操作(第一次是原图像中的目标到conv5之前的缩放,比如缩放32倍,目标大小是600,结果不是整数,需要进行量化舍弃,第二次量化是比如特征图目标是55,ROI-pooling后是22,这里由于5不是2的倍数,需要再一次进行量化,这样对于Roi Pooling之后的结果就与原来的图像位置相差比较大了),因此作者对ROI-Pooling进行了改进,提出了RoI Align方法,在下采样的时候,对像素进行对准,使得像素更准确一些。
ROI Align是怎么做的呢?
ROI-Align取消了所有的量化操作,不再进行4舍5入,如下图所示比较清晰,图中虚线代表特征图,其中黑框代表object的位置,可见object的位置不再是整数,而可能在中间,然后进行22的align-pooling,图中的采样点的数量为4,所以可以计算出4个位置,然后对每个位置取距离最近的4个坐标的值取平均求得。采样点的数量怎么计算? 这个可以自己设置,默认是设置4个点。 22是4个bin。

ROI-Warp:在Roi-Pooling前面增加一层,将Roi区域缩放到固定大小,然后在进行roi-pooling,这样就减少了量化的操作。
网络训练
这里其实跟Faster R-CNN基本一致,IOU > 0.5的是正样本,并且LmaskLmask L_{mask}Lmask只在正样本的时候才计算,图像变换到短边 800, 正负样本比例 1:3 , RPN采用5个scale以及3个aspect ratio。
inference细节
采用ResNet作为backbone的Mask
R-CNN产生300个候选区域进行分类回归,采用FPN方法的生成1000个候选区域进行分类回归,然后进行非极大值抑制操作,** 最后检测分数前100的区域进行mask检测**,这里没有使用跟训练一样的并行操作,作者解释说是可以提高精度和效率,然后mask分支可以预测k个类别的mask,但是这里根据分类的结果,选取对应的第k个类别,得到对应的mask后,再resize到ROI的大小, 然后利用阈值0.5进行二值化即可。(这里由于resize需要插值操作,所以需要再次进行二值化,m的大小可以参考上图,mask最后并不是ROI大小,而是一个相对较小的图, 所以需要进行resize操作。)
2.3. 实验结果:
实验效果还是杠杠的,Mask R-CNN轻松打败了上界冠军FCIS(其使用了multi-scale训练,水平翻转测试,OHEM等)


溶解实验:
下面一张图基本上说明了所有的对比问题:

表(a),显示了网络越深,效果越好。并且FPN效果要好一些。
表(b),sigmoid要比softmax效果好一些。
表(c,d),roi-align效果有提升,特别是AP75提升最明显,说明对精度提升很有用。
表(e),mask banch采用FCN效果较好(因为FCN没有破坏空间关系)
另外作者实验,mask分支采用不同的方法,方法一:对每个类别预测一个mask ,方法二:所有的都预测一个mask,实验结果每个类预测一个mask别会好一些 30.3 vs 29.7
对于目标检测的结果:
对比下表,可见,在预测的时候即使不使用mask分支,结果精度也是很高的,下图中’Faster R-CNN, ROIAlign’ 是使用ROI
Align,而不使用ROI Pooling的结果,较ROI
Pooling的结果高了约0.9个点,但是比MaskR-CNN还是低了0.9个点,这个提升,作者将其归结为多任务训练的提升,由于加入了mask分支,带来的loss改变,间接影响了主干网络的效果。
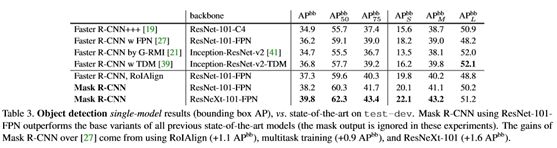

对于时间消耗来说,Mask R-CNN FPN网络195ms,比Mask R-CNN, ResNet网络的400ms要快一些。
人体关键点检测:
与Mask R-CNN进行Mask检测有什么不同呢?
人体关键点检测,作者对最后m*m的mask进行one-hot编码,并且,mask中只有一个像素点是foreground其他的都是background。
人体关键点检测,最后的输出是m^2-way 的softmax, 不再是Sigmoid,作者解释说,这有利于单独一个点的检测。
人体关键点检测,
最后的mask分辨率是5656,不再是2828,作者解释,较高的分辨率有利于人体关键点的检测。
- 实例分割算法PolarMask(CVPR 2020)
PolarMask基于FCOS,把实例分割统一到了FCN的框架下。把更复杂的实例分割问题,转化成在网络设计和计算量复杂度上和物体检测一样复杂的任务,把对实例分割的建模变得简单和高效。PolarMask提出了一种新的instance segmentation建模方式,通过寻找物体的contour建模,提供了一种新的方法供大家选择。
两种实例分割的建模方式:
1)像素级建模 类似于图b,在检测框中对每个pixel分类
2)轮廓建模 类似于图c和图d,其中,图c是基于直角坐标系建模轮廓,图d是基于极坐标系建模轮廓

可以看到Mask R-CNN属于第一种建模方式,而我们提出的PolarMask属于图d建模方式。图c也会work,但是相比图d缺乏固定角度先验。换句话说,基于极坐标系的方式已经将固定角度设为先验,网络只需回归固定角度的长度即可,简化了问题的难度。
PolarMask 基于极坐标系建模轮廓,把实例分割问题转化为实例中心点分类(instance center
classification)问题和密集距离回归(dense distance regression)问题。同时,我们还提出了两个有效的方法,用来优化high-quality正样本采样和dense distance regression的损失函数优化,分别是Polar CenterNess和 Polar IoU Loss。没有使用任何trick(多尺度训练,延长训练时间等),PolarMask 在ResNext 101的配置下 在coco test-dev上取得了32.9的mAP。 这是首次,我们证明了更复杂的实例分割问题,可以在网络设计和计算复杂度上,和anchor
free物体检测一样简单。我们希望PolarMask可以成为一个简单且强有效的single shot instance segmentation 的baseline。
PolarMask最重要的特点是:
(1) anchor free and bbox free,不需要出检测框
(2) fully convolutional network, 相比FCOS把4根射线散发到36根射线,将instance
segmentation和object detection用同一种建模方式来表达。
我们选取FCOS嵌入我们的方法,主要是为了simple。FCOS是目前state-of-the-art的anchor-free检测器,并且十分simple。我们在FCOS的基础上,几乎不加任何计算量,就可以建模实例分割问题,并取得competitive的性能,证明了实例分割可以简化成和目标检测相同复杂的问题。
此外,FCOS可以看成PolarMask的特殊形式,而PolarMask可以看作FCOS的通用形式,因为bbox本质上是最简单的Mask,只有0,90,180,270四个角度回归长度。
我们首次将instance segmentation和object
detection用同一种建模方式来表达。
网络结构

整个网络和FCOS一样简单,首先是标准的backbone + fpn模型,其次是head部分,我们把fcos的bbox分支替换为mask分支,仅仅是把channel=4替换为channel=n, 这里n=36,相当于36根射线的长度。同时我们提出了一种新的Polar Centerness 用来替换FCOS的bbox centerness。
可以看到,在网络复杂度上,PolarMask和FCOS并无明显差别。
Polar Segmentation建模

首先,输入一张原图,经过网络可以得到中心点的位置和n(n=36
is best in our setting)根射线的距离,其次,根据角度和长度计算出轮廓上的这些点的坐标,从0°开始连接这些点,最后把联通区域内的区域当做实例分割的结果。
在实验中,我们以重心为基准,assign到feature
map上,会在重心周围采样,作为正样本,别的地方当做负样本,训练方式和FCOS保持一致,采用Focal Loss, 在此,我们提出Polar CenterNess,用来选择出高质量的正样本,给低质量的正样本降低权重。
Polar CenterNess
如何在Polar Coordinate下定义高质量的正样本?我们通过如下公式定义

其中 d1 d2…dn指的是36根射线的长度,最好的正样本必须具备dmin ——> dmax.
用一张图举例

以看到中间的图,会出现长度回归差别很大的问题,而右边的图中心点位置就较为合适,到所有轮廓的长度回归就较为接近,36根射线的距离会比较均衡。 Polar Centerness 可以给右边图的点较高的centerness分数,给中间图的点降低centerness分数,这样在infernece的时候右边图的点分数较高。
根据消融实验,Polar Centerness可以有效提高1.4的性能,同时不增加网络复杂度。结果如下图所展示


Polar IoU Loss
在PolarMask中,需要回归k(k=36)根射线的距离,这相比目标检测更为复杂,如何监督regression
branch是一个问题。我们提出Polar IoU Loss近似计算出predict mask和gt mask的iou,通过Iou Loss 更好的优化mask的回归。通过实验证明,Polar IoU Loss相比Smooth L1loss可以明显提高2.6个点,同时Smooth L1loss还面临和其他loss不均衡的问题,需要精心调整权重,这是十分低效的,Polar IoU loss不需要调整权重就可以使mask分支快速且稳定收敛。
那么,Polar IoU Loss如何计算呢?如下图所展示
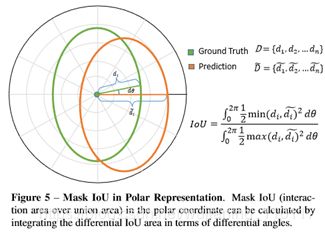
可以看到 两个mask的Iou可以简化为在dθ下的三角形面积iou问题并对无数个三角形求和,最终可以推倒到如下形式:
我们在论文中还做了如下消融实验:射线数量的选择,加不加bbox branch, backbone以及尺寸和速度的trade off. 细节在论文中都有,不一一展开。
上限分析
看到这里,很多人心里都会有一个疑问,射线这种建模方式,对于凹的物体会有性能损失,上限达不到100mAP,PolarMask怎么处理这个问题?
答案是这样,PolarMask相比Mask R-CNN这种pixel建模的方法,对于形状特别奇怪的mask的确建模会失败,但是这并不代表polarmask毫无意义。原因有两个,(1)Mask R-CNN的上限也到不了100 mAP 因为有下采样这类操作使得信息损失。(2)不管Mask R-CNN还是PolarMask,他们的实际性能距离100mAP的上限都特别远。
所以我们目前应该关注如何让实际网络性能去更好地趋近于上限。
定量分析分析射线建模的上限:
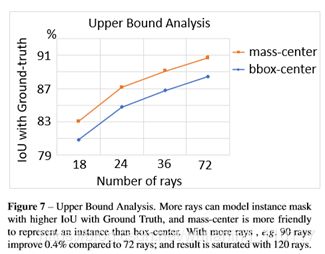
如图所示,当采用mass center做instance中心时,当射线数量不断提高,射线的gt和真实的gt的平均iou高达90%以上,这证明了对于射线建模的性能上限的忧虑还远远不需要担心。现阶段需要操心的问题是如何不断提高基于射线建模的网络性能。
实验
最终,配上一图一表展示一下相比sota的结果

可以看到, 没用采用任何trick的情况下,PolarMask在resnext101-fpn的情况下,取得了32.9的配置,虽然不是stoa,但是也比较有竞争力。我们目前并没有采用很多常用的能涨点的trick,比如 ms train和longer training epochs。相比之下,别的one stage方法都不约而同的采用了mstrain和longer training epoches。 我们会进一步改进,争取再提高性能。