论文阅读笔记:CcNet: A cross-connected convolutional network for segmenting retinal vessels using 多尺度特征
论文链接:CcNet: A cross-connected convolutional network for segmenting retinal vessels using multi-scale features
CcNet: A cross-connected convolutional network for segmenting retinal vessels using multi-scale features
CcNet:交叉连接的卷积网络,使用多尺度特征分割视网膜血管
摘要
本文提出了一种用于视网膜血管树自动分割的交叉连接卷积神经网络(CcNet)。在CcNet中,卷积层提取特征并根据这些特征预测像素类。CcNet直接使用全绿色通道图像进行训练和测试。主路径和次路径的交叉连接融合了多层次的特征。DRIVE: Sn = 0.7625, Acc = 0.9528; STARE: Sn = 0.7709, Acc = 0.9633。在交叉训练阶段,CcNet的准确性波动在DRIVE和STARE分别为0.0042和0.007,与已发表的方法相比相对较小。
1.介绍
CcNet由于其交叉连接模式,能够自动有效地学习多尺度特征。在本文中,我们为RVS(retinal vessel segmentation) 做出了三大贡献:
- 通过融合多尺度特征,设计了一种适用于RVS的交叉连接网络。网络可以有效地收敛。
- 预处理步骤没有超参数,减少了人为的主观因素。这增加了方法的稳定性。
- 我们的网络性能超过大多数已发表的方法,具有先进的鲁棒性和分割速度,同时确保准确性。与那些最先进的技术相比,我们的网络的健壮性几乎是最强的。该方法具有较快的分割速度。
2.提出的方法
2.1网络结构
在CNN中,与较浅的层相比,较深的层倾向于检测更多的抽象特征。 对于RVS,较深的层更易于识别血管结构,而较浅的层则可了解更多血管细节[25-27]。 多尺度特征的融合有效地提高了深度网络的性能。CNN[26]学习所有卷积层产生的区分特征,预测输出。U-Net[32]使用跳跃连接来合并深和浅的特性。u型结构有助于同时使用全局位置和上下文。受到参考文献中作者的启发。[24,26,32],我们使用交叉连接的结构来融合不同层的特征。我们的网主要有以下两点不同于U-net。首先,U-net使用向下采样来学习深层特征。然而,在下行采样步骤[24]中,血管的小细节会丢失。CcNet中的feature map大小相同,既保留了图像细节,又便于特征融合。其次,对于U-net[32],收缩路径中的每个卷积层只连接到扩展路径中的一个层。而对于CcNet来说,主路径上的每个卷积层都与辅助路径上的所有卷积层相连。这种模式可以改善整个网络中的信息流和梯度,这有助于训练更深层次的网络架构[31]。
Fig. 1. The architecture of CcNet. L’ , L and C indicate the name of layers, and X and X’ indicate the output of layers. All of the subscripts indicate the corresponding ordinal number.
如图1所示,上方的水平连接(生成X1,X2和X3)称为主要路径。 较低的(生成X ‘1,X’2和X’3)称为辅助路径。 为了学习更多的特征,主要路径比次要路径具有更多的卷积核。 为了减少网络参数,从主路径到次路径的每个交叉连接都由CRM(卷积-ReLU-maxpooling)模块处理,该模块具有较少的卷积内核。辅助路径的每个输出都由主要路径的输出通过CRM模块连接起来,主要路径的输出如下:
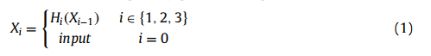
次要路径的输出如下:
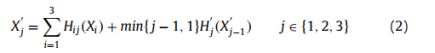
其中Hi(.)、Hi j(.)和H’j(.)分别对应于函数Li、Lij和L’j。H(.)和H’(.)都是三个连续操作的复合函数:3×3卷积层,然后是relu和3×3最大池化层。最后一层(L4)的激活函数是relu。因此,神经元最后一层的每个输出都是一个实数,其最小值为0。对于训练集中的每个标签,0表示背景,255表示血管。
CcNet的损失函数为:
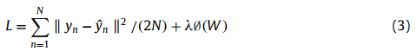
其中N为批量大小,n表示第n个输入图像,yn和y’n分别对应第N个输入的标签和输出。∅(W)是一个惩罚项即L2正则项以避免过拟合。λ是控制系数模型的复杂性的惩罚。所有的卷积和maxpooling层都是填充的,它们的步长是1。除了L1(9x9)和L4(5x5)的卷积层外,几乎所有的卷积层和maxpooling层的内核大小都是3x3 .最后,每一层feature maps的大小都等于输入图像的大小。
2.2预处理
许多方法[3,33]是在原始图像的绿色通道上进行的,因为绿色通道与视网膜图像中的其他两个颜色通道相比,包含了最大的血管背景对比度。在本文中,我们不使用高斯滤波[3]或直方图均衡化[3,19,21],直接将绿色通道馈入网络,生成图像patch[3,6,16,20–24]。由于缺乏超参数,这种预处理模式减少了人的主观影响。一般来说,与已有的方法相比,该方法的预处理步骤非常简单,容易完成。
2.3后处理
对于后处理,灰度值大于255的输出像素限制为255。因此,剪切图像中的灰度值在0到255之间。当对同一幅输出图像执行不同的阈值时,得到了不同性能的二值图像。因此,我们可以绘制一个接收机工作特性(ROC)曲线,并计算ROC曲线下的面积(AUC)。总之,我们的后处理步骤是非常一般的[6]。
2.4训练集
训练前的步骤可以加速CcNet的收敛。因此,我们建立了一个训练前的数据集。生成训练前的数据集包括镜像、旋转和剪切绿色通道图像。我们发现,最终的收敛精度很少受到预先训练的数据集图像大小的影响。这里,训练前数据集中的图像大小为80x80,接近于大多数用于RVS的基于patch的网络的大小[3,6,16,1924]。然后,通过镜像、旋转和平移将全绿通道图像直接转换为训练集。使用预包含数据集来获得预训练的模型。然后,使用预训练模型的参数作为网络的初值。因此,在训练集上对网络进行训练,得到最终的训练模型。
2.5训练网络
我们使用ADAM优化方法[34]来训练CcNet。本文的基本学习率均为0.00072。在训练前阶段,我们每3540步降低一次学习速率,并将最大迭代次数设置为8850步。训练前阶段的最终权重作为训练阶段的初始权重。在训练阶段,我们每30,795步降低一次学习速率,并将最大迭代次数设置为76,986步以获得最终的学习权值。我们每1283次迭代保存一个快照。最后,选取精度最好的模型作为试验模型。
3.实验
3.1数据
DRIVE和STARE
3.2实验设置
我们实验电脑的操作系统是Ubuntu运行在Intel Core I7-7700 CPU和GeForce GTX上1070图形处理单元(GPU)。图像的预处理和后处理由MATLAB R2016b完成。利用深度学习工具包[35]对GPU进行加速计算。
3.3评估方法
Sn,Sp,ACC,AUC
3.4血管分割
对于DRIVE,将测试集的平均结果用作最终测试结果。 但是,STARE并未分为训练集和测试集。 在这里,我们采用了一种称为V折交叉验证的技术。 STARE随机分为V部分。 在每个实验中,选择一个部分作为测试数据,而将其余的V-1部分视为训练数据。 最后,将V实验的平均结果视为测试结果。 这里V是5。

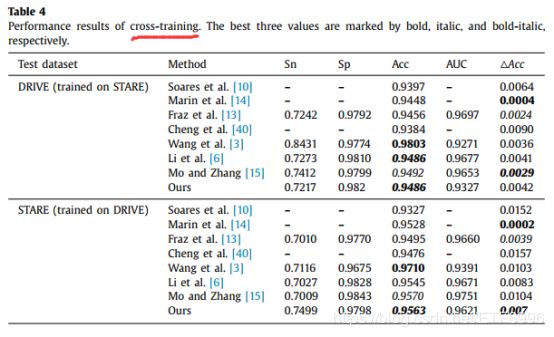
Fig. 2. Segmentation images for the DRIVE dataset. Columns 1–4 are the green channel images, ground truths, clipped output images and final segmentation results, respectively. The first row shows the best accuracy, and the second row shows the worst case.