第十二章 计算着色器
GPU已经过优化,可以处理来自单个位置或顺序位置的大量内存(所谓的“流式操作”); 这与设计用于随机存储器访问的CPU相反[Boyd10]。 而且,由于顶点和像素是独立处理的,所以GPU被设计为大规模并行; 例如,NVIDIA“Fermi”架构支持多达16个流式多处理器,32个CUDA内核,总共512个CUDA内核[NVIDIA09]。
显然图形从这种GPU架构中受益,因为架构是为图形设计的。但是,一些非图形应用程序可以从GPU的并行架构提供的大量计算能力中受益。将GPU用于非图形应用程序称为通用GPU(GPGPU)编程。并非所有算法都适用于GPU实现; GPU需要数据并行算法来利用GPU的并行架构。也就是说,我们需要大量的数据元素,对它们进行类似的操作,以便元素可以并行处理。像素着色这样的图形操作就是一个很好的例子,因为每个正在绘制的像素片段都由像素着色器。另外一个例子,如果您从前面的章节中查看我们的波浪模拟代码,您会看到在更新步骤中,我们对每个网格元素执行一次计算。所以这也是GPU实现的好选择,因为每个网格元素可以由GPU并行地更新。粒子系统提供了另一个例子,其中每个粒子的物理可以独立计算,只要我们简化粒子之间不会相互作用。
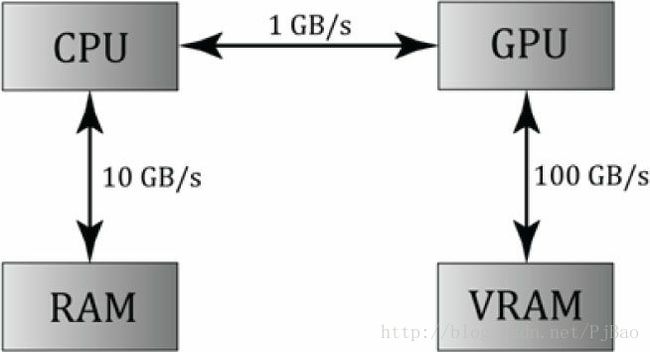
图12.1 图像已从[Boyd10]重新绘制。CPU和RAM,CPU和GPU以及GPU和VRAM之间的相对内存带宽速度。这些数字只是说明性的数字来显示带宽之间的数量级差异。注意到在CPU和GPU之间传输内存是瓶颈。
对于GPGPU编程,用户一般需要访问CPU上的计算结果。 这需要将视频内存中的结果复制到系统内存(这很慢)(参见图12.1),但与在GPU上执行计算的速度相比,这可能是微不足道的问题。对于图形,我们通常使用计算结果作为渲染管道的输入,因此不需要从GPU传输到CPU。例如,我们可以使用计算着色器模糊纹理,然后将着色器资源视图绑定到该着色器作为输入的模糊纹理。
计算着色器是Direct3D开放的一个不是只属于渲染管道的可编程着色器。而是并行的,可读取和写入GPU资源(图12.2)。本质上计算着色器允许我们访问GPU来实现数据并行算法,而不需要绘制任何东西。如前所述,这对于GPGPU编程很有用,但是在计算着色器上仍然有许多图形效果,所以它对于图形编程人员来说仍然非常有用。如前所述,因为计算着色器是Direct3D的一部分,所以它读写Direct3D资源,这使我们能够将计算着色器的输出直接绑定到渲染管道。
学习目标:
1.学习如何编程计算着色器。
2.获得对硬件进程线程组以及其中的线程的基本高级理解。
3.发现哪些Direct3D资源可以设置为计算着色器的输入,哪些Direct3D资源可以设置为计算着色器的输出。
4.了解各种线程ID及其用途。
5.了解共享内存及其如何用于性能优化。
6.找出更多关于GPGPU编程的详细信息。
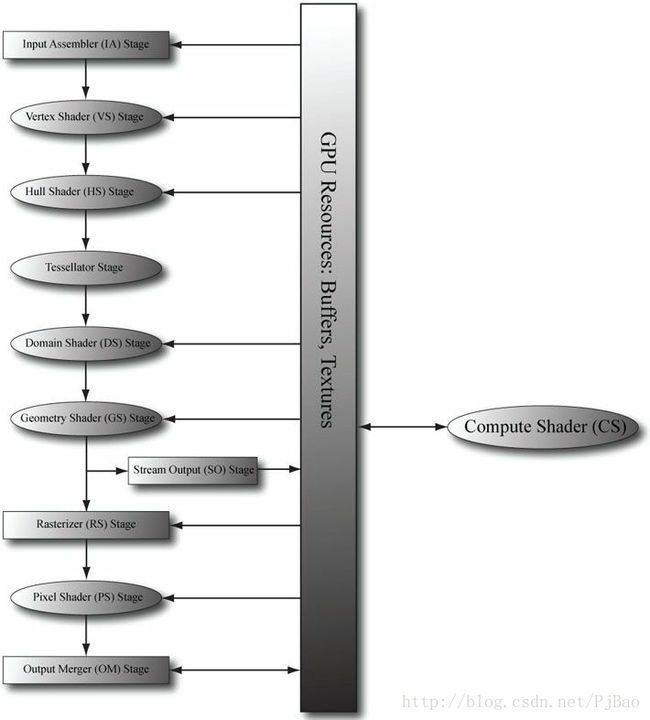
图12.2 计算着色器不是渲染管道的一部分,而是坐落在一边。计算着色器可以读取和写入GPU资源。计算着色器可以与图形渲染混合使用,也可以单独用于GPGPU编程。
12.1线程和线程组
在GPU编程中,需要执行的线程数被划分成一个线程组网格。线程组在单个多线程处理器上执行。因此,如果您有一个具有16个多线程处理器的GPU,那么您最好将您的问题分解成至少16个线程组,以便每个多线程处理器都可以工作。为了获得更好的性能,您将需要每个多线程处理器至少两个线程组,因为多处理器可以在暂停时切换到不同线程组中进行处理[Fung10](例如,如果着色器需要等待纹理运算结果才能继续下一条指令,则可能会发生失速)。
每个线程组获取的共享内存该组中所有线程都可以访问; 线程无法访问其他线程组中的共享内存。线程同步操作可以在线程组中的线程之间进行,但不同的线程组不能同步。实际上,我们无法控制处理不同线程组的顺序。这样是有原因的,因为线程组可以在不同的多处理器上执行。
线程组由n个线程组成。硬件实际上将这些线程分成线程粒(每个线程粒32个线程),并且SIMD32中的多处理器处理线程粒(即同时为32个线程执行相同的指令)。每个CUDA核心处理一个线程,并回调一个“费米”多处理器有32个CUDA内核(所以一个CUDA核心就像一个SIMD“通道”)。在Direct3D中,您可以指定一个线程组大小,其尺寸不必是32的倍数,但是出于性能原因,线程组维度应始终为warp大小的倍数[Fung10]。
线程组大小256似乎是一个应该适用于各种硬件的很好选择。然后用其他尺寸进行实验。更改每组的线程数将更改分派的组数。
NOTE:NVIDIA硬件中warp大小为32个线程。ATI使用的“wavefront”大小为64线程,并建议线程组大小应始终为波前大小的倍数[Bilodeau10]。此外,warp尺寸或wavefront尺寸可能会在后代的硬件中发生变化。
在Direct3D中,线程组通过以下方法调用启动:
void ID3D11DeviceContext::Dispatch(
UINT ThreadGroupCountX,
UINT ThreadGroupCountY,
UINT ThreadGroupCountZ);
图12.3 调度3×2线程组的网格。 每个线程组有8×8线程。
这使你能够启动线程组的3D网格; 然而,在本书中,我们将只关注线程组的2D网格。 以下示例调用在x方向上启动三组,在y方向上启动两组,总共3×2 = 6个线程组(参见图12.3)。
12.2计算着色器的一个例子
以下是一个将两个纹理合并的简单计算着色器,假设所有的纹理都是相同的大小。这个着色器不是很有趣,但它说明了编写计算着色器的基本语法。
cbuffer cbSettings
{
// Compute shader can access values in constant buffers.
};
// Data sources and outputs.
Texture2D gInputA;
Texture2D gInputB;
RWTexture2D gOutput;
// The number of threads in the thread group. The threads in a group can
// be arranged in a 1D, 2D, or 3D grid layout.
[numthreads(16, 16, 1)]
void CS(int3 dispatchThreadID : SV_DispatchThreadID) // Thread ID
{
// Sum the xyth texels and store the result in the xyth texel of
// gOutput.
gOutput[dispatchThreadID.xy] =
gInputA[dispatchThreadID.xy] +
gInputB[dispatchThreadID.xy];
}
technique11 AddTextures
{
pass P0
{
SetVertexShader(NULL);
SetPixelShader(NULL);
SetComputeShader(CompileShader(cs_5_0, CS()));
}
} 计算着色器由以下组件组成:
1.可被全局可变访问的常量缓冲区。
2.输入和输出资源,将在下一节讨论。
3.[numthreads(X,Y,Z)]属性,它将线程组中的线程数指定为线程的3D网格。
4.具有每个线程执行指令的着色器主体。
5.线程识别系统值参数(第12.4节讨论)。
观察我们可以定义线程组的不同拓扑;例如,线程组可以是单行的X线程[numthreads(X,1,1)]或单列的Y线程[numthreads(1,Y,1)])。可以通过将z维设置为1([numthreads(X,Y,1)]来制作X×Y线程的2D线程组。您选择的拓扑将由您正在处理的问题决定。 如上一节所述,每组的线程总数应为warp大小的倍数(NVIDIA卡为32)或wavefront大小的倍数(ATI卡为64)。wavefront大小的倍数也是warp大小的倍数,因此选择wavefront大小的倍数适用于两种类型的卡。
12.3数据输入和输出资源
可以将两种类型的资源绑定到计算着色器:缓冲区和纹理。我们已经使用了缓冲区,如顶点和索引缓冲区以及常量缓冲区。虽然我们使用效果框架设置常量缓冲区,但它们只是具有D3D11_BIND_CONSTANT_BUFFER标志的ID3D11Buffer实例。我们也熟悉第8章的纹理资源。
12.3.1纹理输入
上一节中定义的计算着色器定义了两个输入纹理资源:
Texture2D gInputA;
Texture2D gInputB;输入纹理gInputA和gInputB通过为纹理创建ID3D11ShaderResourceView(SRVs)将其绑定到着色器的输入,并通过ID3DX11EffectShaderResourceVariable变量将其设置为计算着色器变量。这与将着色器资源视图绑定到像素着色器完全一样。请注意SRVs是只读的。
12.3.2纹理输出和无序访问视图(UAV)
上一节中定义的计算着色器定义了一个输出资源:
RWTexture2D<float4> gOutput;输出被特殊处理的,并且具有它们的类型“RW”的特殊前缀,顾名思义,它代表读写,您可以在计算着色器中对资源中元素进行读取和写入。相反,纹理gInputA和gInputB是只读的。此外,有必要使用模板尖括号语法指定输出的类型和尺寸。如果我们的输出是像DXGI_FORMAT_R8G8_SINT这样的二维整数,那么我们会写:
RWTexture2D<int2> gOutput;但是,绑定输出资源不同于输入。要在计算着色器中绑定我们要写入的资源,我们需要使用一种称为无序访问视图(UAV)的新视图类型来绑定它,它在代码中由ID3D11UnorderedAccessView接口表示。这是以与着色器资源视图相似的方式创建的。这是一个例子:
// Note, compressed formats cannot be used for UAV. We get error like:
// ERROR: ID3D11Device::CreateTexture2D: The format (0x4d, BC3_UNORM)
// cannot be bound as an UnorderedAccessView, or cast to a format that
// could be bound as an UnorderedAccessView. Therefore this format
// does not support D3D11_BIND_UNORDERED_ACCESS.
D3D11_TEXTURE2D_DESC blurredTexDesc;
blurredTexDesc.Width = width;
blurredTexDesc.Height = height;
blurredTexDesc.MipLevels = 1;
blurredTexDesc.ArraySize = 1;
blurredTexDesc.Format = format;
blurredTexDesc.SampleDesc.Count = 1;
blurredTexDesc.SampleDesc.Quality = 0;
blurredTexDesc.Usage = D3D11_USAGE_DEFAULT;
blurredTexDesc.BindFlags = D3D11_BIND_SHADER_RESOURCE |
D3D11_BIND_UNORDERED_ACCESS;
blurredTexDesc.CPUAccessFlags = 0;
blurredTexDesc.MiscFlags = 0;
ID3D11Texture2D* blurredTex = 0;
HR(device->CreateTexture2D(>blurredTexDesc, 0, >blurredTex));
D3D11_SHADER_RESOURCE_VIEW_DESC srvDesc;
srvDesc.Format = format;
srvDesc.ViewDimension = D3D11_SRV_DIMENSION_TEXTURE2D;
srvDesc.Texture2D.MostDetailedMip = 0;
srvDesc.Texture2D.MipLevels = 1;
ID3D11ShaderResourceView* mBlurredOutputTexSRV;
HR(device->CreateShaderResourceView(blurredTex,
>srvDesc, >mBlurredOutputTexSRV));
D3D11_UNORDERED_ACCESS_VIEW_DESC uavDesc;
uavDesc.Format = format;
uavDesc.ViewDimension = D3D11_UAV_DIMENSION_TEXTURE2D;
uavDesc.Texture2D.MipSlice = 0;
ID3D11UnorderedAccessView* mBlurredOutputTexUAV;
HR(device->CreateUnorderedAccessView(blurredTex,
>uavDesc, >mBlurredOutputTexUAV));
// Views save a reference to the texture so we can release our reference.
ReleaseCOM(blurredTex);请注意,如果纹理要绑定为UAV,则必须使用D3D11_BIND_UNORDERED_ACCESS标志创建纹理; 在前面的例子中,纹理将被绑定为UAV和SRV(但不是同时),因此它具有组合的标志D3D11_BIND_SHADER_RESOURCE |D3D11_BIND_UNORDERED_ACCESS。这是常见的,因为我们经常使用计算着色器对纹理执行一些操作(因此纹理将作为UAV绑定到计算着色器),然后,我们要使用它来纹理几何,因此它将绑定到顶点或像素着色器作为SRV。
一旦创建了一个ID3D11UnorderedAccessView对象,我们可以使用ID3DX11EffectUnorderedAccessViewVariable接口的SetUnorderedAccessView方法将其绑定到一个“RW”计算着色器变量上:
// HLSL variables.
Texture2D gInputA;
Texture2D gInputB;
RWTexture2D<float4> gOutput;
// C++ Code.
ID3DX11EffectShaderResourceVariable* InputA;
ID3DX11EffectShaderResourceVariable* InputB;
ID3DX11EffectUnorderedAccessViewVariable* Output;
InputA = mFX->GetVariableByName(”gInputA”)->AsShaderResource();
InputB = mFX->GetVariableByName(”gInputB”)->AsShaderResource();
Output = mFX->GetVariableByName(”gOutput”)->AsUnorderedAccessView();
void SetInputA(ID3D11ShaderResourceView* tex)
{
InputA->SetResource(tex);
}
void SetInputB(ID3D11ShaderResourceView* tex)
{
InputB->SetResource(tex);
}
void SetOutput(ID3D11UnorderedAccessView* tex)
{
Output->SetUnorderedAccessView(tex);
}12.3.3 索引和采样纹理
可以使用2D索引访问纹理元素。在§12.2中定义的计算着色器中,我们根据调度线程ID为纹理编制索引(线程ID在§12.4中讨论)。每个线程都有一个唯一的调度ID。
[numthreads(16, 16, 1)]
void CS(int3 dispatchThreadID : SV_DispatchThreadID)
{
// Sum the xyth texels and store the result in the xyth texel of
// gOutput.
gOutput[dispatchThreadID.xy] =
gInputA[dispatchThreadID.xy] +
gInputB[dispatchThreadID.xy];
}假设我们派发了足够的线程组来覆盖纹理(即,为一个纹理执行一个线程),那么此代码将纹理图像求和并将结果存储在纹理gOutput中。
Note:计算着色器可以很好地定义出界指标的行为。 越界读取返回0,并且越界写入导致无操作[Boyd08]。
由于计算着色器是在GPU上执行的,因此它可以访问常用的GPU工具。特别是,我们可以使用纹理过滤来对纹理进行采样。但是有两个问题。首先,我们不能使用Sample方法,而是必须使用SampleLevel方法。 SampleLevel需要额外的第三个参数来指定纹理的mipmap级别; 0取最高级别,1取第二个mip级别等,如果启用线性mip过滤,则使用小数值在两个mip级别之间插值。另一方面,Sample会自动选择基于最佳mipmap级别纹理将覆盖屏幕上的多少像素。由于计算着色器不用于直接渲染,因此它不知道如何自动选择像这样的mipmap级别,因此我们必须在计算着色器中用SampleLevel明确指定级别。第二个问题是,当我们对纹理进行采样时,我们使用范围为[0,1] 2的归一化纹理坐标而不是整数索引。但是,可以将纹理大小(宽度,高度)设置为常量缓冲区变量,然后可以从整数索引(x,y)导出归一化纹理坐标:
以下代码显示使用整数索引的计算着色器,以及使用纹理坐标和SampleLevel的第二个等效版本,假定纹理大小为512×512,我们只需要最高级别的mip:
//
// VERSION 1: Using integer indices.
//
cbuffer cbUpdateSettings
{
float gWaveConstants[3];
};
Texture2D gPrevSolInput;
Texture2D gCurrSolInput;
RWTexture2D gNextSolOutput;
[numthreads(16, 16, 1)]
void CS(int3 dispatchThreadID : SV_DispatchThreadID)
{
int x = dispatchThreadID.x;
int y = dispatchThreadID.y;
gNextSolOutput[int2(x,y)] =
gWaveConstants[0]* gPrevSolInput[int2(x,y)].r +
gWaveConstants[1]* gCurrSolInput[int2(x,y)].r +
gWaveConstants[2]*(
gCurrSolInput[int2(x,y+1)].r +
gCurrSolInput[int2(x,y-1)].r +
gCurrSolInput[int2(x+1,y)].r +
gCurrSolInput[int2(x-1,y)].r);
}/
/
// VERSION 2: Using SampleLevel and texture coordinates.
//
cbuffer cbUpdateSettings
{
float gWaveConstants[3];
};
SamplerState samPoint
{
Filter = MIN_MAG_MIP_POINT;
AddressU = CLAMP;
AddressV = CLAMP;
};
Texture2D gPrevSolInput;
Texture2D gCurrSolInput;
RWTexture2D gNextSolOutput;
[numthreads(16, 16, 1)]
void CS(int3 dispatchThreadID : SV_DispatchThreadID)
{
// Equivalently using SampleLevel() instead of operator [].
int x = dispatchThreadID.x;
int y = dispatchThreadID.y;
float2 c = float2(x,y)/512.0f;
float2 t = float2(x,y-1)/512.0;
float2 b = float2(x,y+1)/512.0;
float2 l = float2(x-1,y)/512.0;
float2 r = float2(x+1,y)/512.0;
gNextSolOutput[int2(x,y)] =
gWaveConstants[0]*gPrevSolInput.SampleLevel(samPoint, c, 0.0f).r +
gWaveConstants[1]*gCurrSolInput.SampleLevel(samPoint, c, 0.0f).r +
gWaveConstants[2]*(
gCurrSolInput.SampleLevel(samPoint, b, 0.0f).r +
gCurrSolInput.SampleLevel(samPoint, t, 0.0f).r +
gCurrSolInput.SampleLevel(samPoint, r, 0.0f).r +
gCurrSolInput.SampleLevel(samPoint, l, 0.0f).r);
} 12.3.4结构化缓冲区资源
以下示例显示了HLSL中如何定义结构化缓冲区:
struct Data
{
float3 v1;
float2 v2;
};
StructuredBuffer<Data> gInputA;
StructuredBuffer<Data> gInputB;
RWStructuredBuffer<Data> gOutput;结构化缓冲区只是一个相同类型的元素的缓冲区,实质上是一个数组。 如您所见,该类型可以是HLSL中的用户定义结构。 除了我们指定结构化缓冲区标志并且我们必须指定要存储的元素的字节大小之外,结构化缓冲区与普通缓冲区一样创建。
struct Data
{
XMFLOAT3 v1;
XMFLOAT2 v2;
};
// Create a buffer to be bound as a shader
// input (D3D11_BIND_SHADER_RESOURCE).
D3D11_BUFFER_DESC inputDesc;
inputDesc.Usage = D3D11_USAGE_DEFAULT;
inputDesc.ByteWidth = sizeof(Data) * mNumElements;
inputDesc.BindFlags = D3D11_BIND_SHADER_RESOURCE;
inputDesc.CPUAccessFlags = 0;
inputDesc.StructureByteStride = sizeof(Data);
inputDesc.MiscFlags = D3D11_RESOURCE_MISC_BUFFER_STRUCTURED;
D3D11_SUBRESOURCE_DATA vinitDataA;
vinitDataA.pSysMem = >dataA[0];
ID3D11Buffer* bufferA = 0;
HR(md3dDevice->CreateBuffer(>inputDesc, >vinitDataA, >bufferA));
// Create a read-write buffer the compute shader can
// write to (D3D11_BIND_UNORDERED_ACCESS).
D3D11_BUFFER_DESC outputDesc;
outputDesc.Usage = D3D11_USAGE_DEFAULT;
outputDesc.ByteWidth = sizeof(Data) * mNumElements;
outputDesc.BindFlags = D3D11_BIND_UNORDERED_ACCESS;
outputDesc.CPUAccessFlags = 0;
outputDesc.StructureByteStride = sizeof(Data);
outputDesc.MiscFlags = D3D11_RESOURCE_MISC_BUFFER_STRUCTURED;
ID3D11Buffer* mOutputBuffer;
HR(md3dDevice->CreateBuffer(>outputDesc, 0, >mOutputBuffer));要将结构化缓冲区作为输入绑定到计算着色器,我们只需创建一个SRV,并通过ID3DX11EffectShaderResourceVariable变量将其设置为计算着色器。 同样,为了将结构化缓冲区绑定为RW输出,我们只需创建一个UAV,并通过ID3DX11EffectUnorderedAccessViewVariable变量将其设置为计算着色器。 以下代码显示了如何创建SRV和UAV到结构化缓冲区:
D3D11_SHADER_RESOURCE_VIEW_DESC srvDesc;
srvDesc.Format = DXGI_FORMAT_UNKNOWN;
srvDesc.ViewDimension = D3D11_SRV_DIMENSION_BUFFEREX;
srvDesc.BufferEx.FirstElement = 0;
srvDesc.BufferEx.Flags = 0;
srvDesc.BufferEx.NumElements = mNumElements;
md3dDevice->CreateShaderResourceView(bufferA, >srvDesc, >mInputASRV);
md3dDevice->CreateShaderResourceView(bufferB, >srvDesc, >mInputBSRV);
D3D11_UNORDERED_ACCESS_VIEW_DESC uavDesc;
uavDesc.Format = DXGI_FORMAT_UNKNOWN;
uavDesc.ViewDimension = D3D11_UAV_DIMENSION_BUFFER;
uavDesc.Buffer.FirstElement = 0;
uavDesc.Buffer.Flags = 0;
uavDesc.Buffer.NumElements = mNumElements;
md3dDevice->CreateUnorderedAccessView(mOutputBuffer, >uavDesc,>mOutputUAV);下一部分代码展示了如何通过效果框架将SRV和UAV设置为计算着色器:
// HLSL variables.
struct Data
{
float3 v1;
float2 v2;
};
StructuredBuffer<Data> gInputA;
StructuredBuffer<Data> gInputB;
RWStructuredBuffer<Data> gOutput;
// C++ Code.
ID3DX11EffectShaderResourceVariable* InputA;
ID3DX11EffectShaderResourceVariable* InputB;
ID3DX11EffectUnorderedAccessViewVariable* Output;
InputA = mFX->GetVariableByName(”gInputA”)->AsShaderResource();
InputB = mFX->GetVariableByName(”gInputB”)->AsShaderResource();
Output = mFX->GetVariableByName(”gOutput”)->AsUnorderedAccessView();
void SetInputA(ID3D11ShaderResourceView* srv)
{
InputA->SetResource(srv);
}
void SetInputB(ID3D11ShaderResourceView* srv)
{
InputB->SetResource(srv);
}
void SetOutput(ID3D11UnorderedAccessView* uav)
{
Output->SetUnorderedAccessView(uav);
}观察在创建SRV或UAV到结构化缓冲区时,对于Format属性,我们指定DXGI_FORMAT_UNKNOWN。 这是因为通常情况下,结构化缓冲区使用用户定义类型,因此该结构不会直接对应于DXGI_FORMAT成员之一。 有一种类型化的缓冲区,它具有HLSL语法:
Buffer<float4> typedBuffer1;
Buffer<float> typedBuffer2;
Buffer<int2> typedBuffer3;创建这些缓冲区时,不要指定D3D11_RESOURCE_MISC_BUFFER_STRUCTURED标志,并且在创建视图时,必须为Format属性指定正确的DXGI_FORMAT。请注意,HLSL语法只定义了组件的类型和数量,但有许多DXGI_FORMAT成员可以对应于HLSL类型。 例如,typedBuffer1的可能格式是包含四个组件的任何浮点格式:
DXGI_FORMAT_R32G32B32A32_FLOAT,XGI_FORMAT_R16G16B16A16_FLOAT和DXGI_FORMAT_R8G8B8A8_UNORM。同样,typedBuffer3的可能格式为DXGI_FORMAT_R32G32_SINT,DXGI_FORMAT_R16G16_SINT和DXGI_FORMAT_R8G8_SINT。
Note:还有一种叫做原始缓冲区的东西,它基本上是一个字节的数据数组。使用字节偏移量,然后可以将数据转换为适当的类型。例如,这可能对于在同一缓冲区中存储不同的数据类型很有用。本书不使用原始缓冲区;有关详细信息,请参阅SDK文档。SDK示例“BasicCompute11”展示了如何创建原始缓冲区并使用它们。
12.3.5将CS结果复制到系统内存
通常,当我们使用计算着色器来处理纹理时,我们会在屏幕上显示处理过的纹理;因此,我们直观地看到结果来验证计算着色器的准确性。通过结构化缓冲区计算和一般GPGPU计算,我们可能根本不显示我们的结果。所以问题是我们如何从GPU内存中获取结果(记住当我们通过UAV写入结构化缓冲区时,该缓冲区存储在GPU内存中)返回到系统内存。常见模式是创建一个系统内存缓冲区,其中包含分段标志D3D11_USAGE_STAGING和CPU访问标志D3D11_CPU_ACCESS_READ。然后我们可以使用ID3D11DeviceContext :: CopyResource方法将GPU资源复制到系统内存资源。系统内存资源必须与我们想要复制的资源类型和大小相同。最后,我们可以映射系统内存缓冲区和映射API以在CPU上读取它。然后,我们可以将数据复制到系统存储器阵列中,以便在CPU端进行进一步处理,将数据保存到文件或您有什么。
我们在本章中包含了一个名为“VecAdd”的结构化缓冲区演示,它简单地将存储在两个结构化缓冲区中的相应向量组件相加:
struct Data
{
float3 v1;
float2 v2;
};
StructuredBuffer gInputA;
StructuredBuffer gInputB;
RWStructuredBuffer gOutput;
[numthreads(32, 1, 1)]
void CS(int3 dtid : SV_DispatchThreadID)
{
gOutput[dtid.x].v1 = gInputA[dtid.x].v1 + gInputB[dtid.x].v1;
gOutput[dtid.x].v2 = gInputA[dtid.x].v2 + gInputB[dtid.x].v2;
}为简单起见,结构化缓冲区只包含32个元素; 因此,我们只需分派一个线程组(因为一个线程组处理32个元素)。 在计算着色器为本演示中的所有线程完成其工作后,我们将结果复制到系统内存并将其保存到文件中。 以下代码显示了如何创建系统内存缓冲区以及如何将GPU结果复制到CPU内存:
// Create a system memory version of the buffer to read the
// results back from.
D3D11_BUFFER_DESC outputDesc;
outputDesc.Usage = D3D11_USAGE_STAGING;
outputDesc.BindFlags = 0;
outputDesc.ByteWidth = sizeof(Data) * mNumElements;
outputDesc.CPUAccessFlags = D3D11_CPU_ACCESS_READ;
outputDesc.StructureByteStride = sizeof(Data);
outputDesc.MiscFlags = D3D11_RESOURCE_MISC_BUFFER_STRUCTURED;
ID3D11Buffer* mOutputDebugBuffer;
HR(md3dDevice->CreateBuffer(>outputDesc, 0, >mOutputDebugBuffer));
// ...
//
// Compute shader finished!
struct Data
{
XMFLOAT3 v1;
XMFLOAT2 v2;
};
// Copy the output buffer to system memory.
md3dImmediateContext->CopyResource(mOutputDebugBuffer, mOutputBuffer);
// Map the data for reading.
D3D11_MAPPED_SUBRESOURCE mappedData;
md3dImmediateContext->Map(mOutputDebugBuffer, 0, D3D11_MAP_READ, 0, >mappedData);
Data* dataView = reinterpret_cast(mappedData.pData);
for(int i = 0; i < mNumElements; ++i)
{
fout << “(“ << dataView[i].v1.x << ”, “ <<
dataView[i].v1.y << “, “ <<
dataView[i].v1.z << “, ” <<
dataView[i].v2.x << “, ” <<
dataView[i].v2.y << “)” << std::endl;
}
md3dImmediateContext->Unmap(mOutputDebugBuffer, 0);
fout.close(); 在演示中,我们使用以下初始数据填充两个输入缓冲区:
std::vector dataA(mNumElements);
std::vector dataB(mNumElements);
for(int i = 0; i < mNumElements; ++i)
{
dataA[i].v1 = XMFLOAT3(i, i, i);
dataA[i].v2 = XMFLOAT2(i, 0);
dataB[i].v1 = XMFLOAT3(-i, i, 0.0f);
dataB[i].v2 = XMFLOAT2(0, -i);
}生成的文本文件包含以下数据,这些数据确认计算着色器按预期工作。
(0, 0, 0, 0, 0)
(0, 2, 1, 1, -1)
(0, 4, 2, 2, -2)
(0, 6, 3, 3, -3)
(0, 8, 4, 4, -4)
(0, 10, 5, 5, -5)
(0, 12, 6, 6, -6)
(0, 14, 7, 7, -7)
(0, 16, 8, 8, -8)
(0, 18, 9, 9, -9)
(0, 20, 10, 10, -10)
(0, 22, 11, 11, -11)
(0, 24, 12, 12, -12)
(0, 26, 13, 13, -13)
(0, 28, 14, 14, -14)
(0, 30, 15, 15, -15)
(0, 32, 16, 16, -16)
(0, 34, 17, 17, -17)
(0, 36, 18, 18, -18)
(0, 38, 19, 19, -19)
(0, 40, 20, 20, -20)
(0, 42, 21, 21, -21)
(0, 44, 22, 22, -22)
(0, 46, 23, 23, -23)
(0, 48, 24, 24, -24)
(0, 50, 25, 25, -25)
(0, 52, 26, 26, -26)
(0, 54, 27, 27, -27)
(0, 56, 28, 28, -28)
(0, 58, 29, 29, -29)
(0, 60, 30, 30, -30)
(0, 62, 31, 31, -31)
Note:从图12.1中可以看出,CPU和GPU内存之间的拷贝速度最慢。 对于图形来说,我们从不想每帧都做这个拷贝,因为它会导致性能下降。 对于GPGPU编程,通常需要将结果返回到CPU; 然而,对于GPGPU编程来说,这通常不是什么大问题,因为使用GPU的收益超过了从GPU到CPU的复制成本 - 而且,对于GPGPU,副本的频率将低于“每帧”。例如,假设 应用程序使用GPGPU编程来实现昂贵的图像处理计算。 计算完成后,结果被复制到CPU。 在用户请求另一次计算之前,GPU不会再次使用。
12.4线程识别系统值
参考图12.4。
1.每个线程组由系统分配一个ID;这称为组ID,并且具有系统值语义SV_GroupID。如果Gx×Gy×Gz是分派的线程组的数量,则组ID从(0,0,0)到(Gx-1,Gy-1 ,Gz-1)。
2.在一个线程组内,每个线程都有一个相对于其组的唯一ID。如果线程组的大小为X×Y×Z,则组线程ID的范围将从(0,0,0)到(X-1,Y-1,Z-1)。组线程ID的系统值语义为SV_GroupThreadID。
3.调度调用分派线程组的网格。调度线程ID唯一标识与调度调用生成的所有线程相关的线程。换句话说,虽然组线程ID唯一地标识了一个线程相对于它的线程组,但是调度线程ID唯一地标识了一个线程相对于来自Dispatch调用调度的所有线程组的所有线程的联合。让ThreadGroupSize =(X,Y,Z)为线程组的大小,然后派生线程ID可以从组ID和组线程ID派生,如下所示:
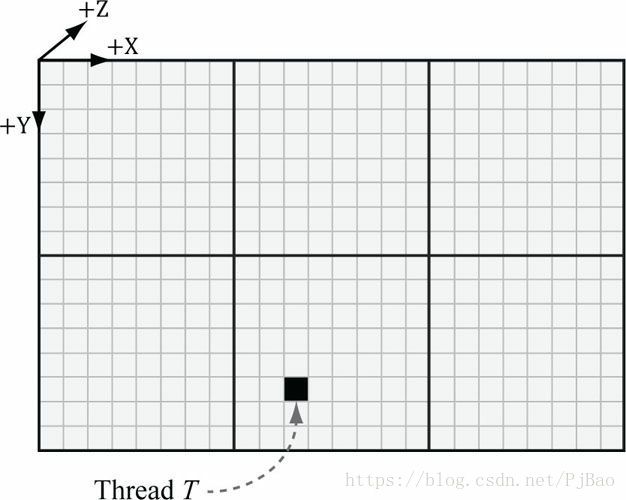
图12.4 考虑标记的线程T.线程T具有线程组ID(1,1,0)。 它具有组线程ID(2,5,0)。 它具有调度线程ID(1,1,0)⊗(8,8,0)+(2,5,0)=(10,13,0)。它具有组索引ID 5∙8 + 2 = 42。
dispatchThreadID.xyz = groupID.xyz * ThreadGroupSize.xyz + groupThreadID.xyz;
调度线程ID具有系统值语义SV_DispatchThreadID。如果调度3×2个线程组,每个线程组为10×10,则调度共60个线程,调度线程ID范围从(0,0,0)到(29,19.0)。
4.线程索引版本的组线程ID由Direct3D通过SV_GroupIndex系统值给我们; 它被计算为:
groupIndex = groupThreadID.z*ThreadGroupSize.x*ThreadGroupSize.y + groupThreadID.y*ThreadGroupSize.x + groupThreadID.x;NOTE:关于索引坐标顺序,第一个坐标给出x位置(或列),第二个坐标给出y位置(或行)。这与常见的矩阵符号相反,其中Mij表示第i行第j列中的元素。
那么为什么我们需要这些线程ID值。那么,计算着色器通常会将某些输入数据结构和输出传递给某些数据结构。我们可以使用线程标识值作为这些数据结构的索引:
Texture2D gInputA;
Texture2D gInputB;
RWTexture2D gOutput;
[numthreads(16, 16, 1)]
void CS(int3 dispatchThreadID : SV_DispatchThreadID)
{
// Use dispatch thread ID to index into output and input textures.
gOutput[dispatchThreadID.xy] =
gInputA[dispatchThreadID.xy] +
gInputB[dispatchThreadID.xy];
} SV_GroupThreadID对于索引到线程本地存储器(第12.6节)非常有用。
12.5添加和消耗缓冲
假设我们有一个由结构定义的粒子缓冲区:
struct Particle
{
float3 Position;
float3 Velocity;
float3 Acceleration;
};我们希望根据计算着色器中恒定的加速度和速度更新粒子位置。此外,假设我们不关心粒子更新的顺序,也不关心它们写入输出缓冲区的顺序。消费和追加结构化缓冲区非常适合这种情况,它们提供了我们无需担心索引的便利:
struct Particle
{
float3 Position;
float3 Velocity;
float3 Acceleration;
};
float TimeStep = 1.0f / 60.0f;
ConsumeStructuredBuffer gInput;
AppendStructuredBuffer gOutput;
[numthreads(16, 16, 1)]
void CS()
{
// Consume a data element from the input buffer.
Particle p = gInput.Consume();
p.Velocity += p.Acceleration*TimeStep;
p.Position += p.Velocity*TimeStep;
// Append normalized vector to output buffer.
gOutput.Append(p);
} 一旦数据元素被消耗,它就不能被另一个线程再次使用; 一个线程会占用一个数据元素。我们再次强调,消费和追加的订单元素是未知的; 因此,输入缓冲区中的第i个元素被写入输出缓冲区中的第i个元素通常不是这种情况。
NOTE:附加结构化缓冲区不会动态增长。它们必须足够大以存储您将添加到它们的所有元素。
在应用方面唯一必要的步骤是在创建UVA时,我们必须指定D3D11_BUFFER_UAV_FLAG_APPEND标志:
D3D11_UNORDERED_ACCESS_VIEW_DESC uavDesc;
uavDesc.Format = DXGI_FORMAT_UNKNOWN;
uavDesc.ViewDimension = D3D11_UAV_DIMENSION_BUFFER;
uavDesc.Buffer.FirstElement = 0;
uavDesc.Buffer.Flags = D3D11_BUFFER_UAV_FLAG_APPEND;
uavDesc.Buffer.NumElements = mNumElements;12.6共享存储器和同步
线程组被赋予一部分所谓的共享内存或线程本地存储。访问这个内存很快,可以被认为和硬件缓存一样快。在计算着色器代码中,共享内存是这样声明的:
groupshared float4 gCache[256];数组大小可以是任何你想要的,但组共享内存的最大大小是32kb。 由于共享内存是线程组本地的,因此它使用SV_ThreadGroupID索引; 因此,例如,您可以让组中的每个线程访问共享内存中的一个插槽。
如以下示例所示,使用太多共享内存会导致性能问题[Fung10]。假设多处理器支持32kb的共享内存,并且计算着色器需要20kb的共享内存。这意味着只有一个线程组适合多处理器,因为没有足够的内存留给另一个线程组[Fung10],如20kb + 20kb = 40kb> 32kb。这限制了GPU的并行性,因为多处理器无法在线程组之间关闭以隐藏延迟(从§12.1中可以看出,推荐每个多处理器至少有两个线程组)。 因此,即使硬件在技术上支持32kb的共享内存,性能的提高也可以通过少用。
共享内存的一个常见应用是在其中存储纹理值。某些算法(如模糊)需要多次提取相同的纹素。采样纹理实际上是GPU运算速度较慢的一种,因为内存带宽和内存延迟并未像GPU的原始计算能力那样得到提高[Möller08]。通过将所有需要的纹理样本预加载到共享内存数组中,线程组可以避免重复的纹理拾取。然后该算法继续查找共享存储器阵列中的纹理采样,这非常快。 假设我们用下面的错误代码实现这个策略:
Texture2D gInput;
RWTexture2D gOutput;
groupshared float4 gCache[256];
[numthreads(256, 1, 1)]
void CS(int3 groupThreadID : SV_GroupThreadID,
int3 dispatchThreadID : SV_DispatchThreadID)
{
// Each thread samples the texture and stores the
// value in shared memory.
gCache[groupThreadID.x] = gInput[dispatchThreadID.xy];
// Do computation work: Access elements in shared memory
// that other threads stored:
// BAD!!! Left and right neighbor threads might not have
// finished sampling the texture and storing it in shared memory.
float4 left = gCache[groupThreadID.x - 1];
float4 right = gCache[groupThreadID.x + 1];
...
} 这种情况出现问题,因为我们不能保证线程组中的所有线程同时完成。因此,线程可以访问尚未初始化的共享内存元素,因为负责初始化这些元素的相邻线程 尚未完成。要解决此问题,在计算着色器可以继续之前,必须等到所有线程都将纹理加载到共享内存中。 这是通过同步命令完成的:
Texture2D gInput;
RWTexture2D gOutput;
groupshared float4 gCache[256];
[numthreads(256, 1, 1)]
void CS(int3 groupThreadID : SV_GroupThreadID,
int3 dispatchThreadID : SV_DispatchThreadID)
{
// Each thread samples the texture and stores the
// value in shared memory.
gCache[groupThreadID.x] = gInput[dispatchThreadID.xy];
// Wait for all threads in group to finish.
GroupMemoryBarrierWithGroupSync();
// Safe now to read any element in the shared memory
//and do computation work.
float4 left = gCache[groupThreadID.x - 1];
float4 right = gCache[groupThreadID.x + 1];
...
} 12.7 BLUR DEMO
**
**