想学习Spark?先带你了解一些基础的知识

???? Index
Spark的核心概念
Spark的基本特性
Spark 生态系统 —— BDAS
Spark-Shell的简单使用
Pyspark的简单使用
Spark 服务的启动流程
之前也学习过一阵子的Spark了,是时候先输出一些知识内容了,一来加深印象,二来也可以分享知识,一举多得,今天这篇主要是在学习实验楼的一门课程中自己记下来的笔记,简单梳理了一下,当做是需要了解得基础知识,让不熟悉Spark的同学也有一些简单的认识,里面若有写错的地方也希望大伙们指出哈。
???? Spark的核心概念
Spark 是 UC Berkeley AMP lab 开发的一个集群计算的框架,类似于 Hadoop,但有很多的区别。最大的优化是让计算任务的中间结果可以存储在内存中,不需要每次都写入 HDFS,更适用于需要迭代的 MapReduce 算法场景中,可以获得更好的性能提升。例如一次排序测试中,对 100TB 数据进行排序,Spark 比 Hadoop 快三倍,并且只需要十分之一的机器。Spark 集群目前最大的可以达到 8000 节点,处理的数据达到 PB 级别,在互联网企业中应用非常广泛。
???? Spark 的特性
Hadoop 的核心是分布式文件系统 HDFS 和计算框架 MapReduces。Spark 可以替代 MapReduce,并且兼容 HDFS、Hive 等分布式存储层,良好的融入 Hadoop 的生态系统。
Spark 执行的特点
中间结果输出:Spark 将执行工作流抽象为通用的有向无环图执行计划(DAG),可以将多 Stage 的任务串联或者并行执行。
数据格式和内存布局:Spark 抽象出分布式内存存储结构弹性分布式数据集 RDD,能够控制数据在不同节点的分区,用户可以自定义分区策略。
任务调度的开销:Spark 采用了事件驱动的类库 AKKA 来启动任务,通过线程池的复用线程来避免系统启动和切换开销。
Spark 的优势
速度快,运行工作负载快 100 倍。Apache Spark 使用最先进的 DAG 调度器、查询优化器和物理执行引擎,实现了批处理和流数据的高性能。
易于使用,支持用 Java、Scala、Python、R 和 SQL 快速编写应用程序。Spark 提供了超过 80 个算子,可以轻松构建并行应用程序。您可以从 Scala、Python、R 和 SQL shell 中交互式地使用它。
普遍性,结合 SQL、流处理和复杂分析。Spark 提供了大量的库,包括 SQL 和 DataFrames、用于机器学习的 MLlib、GraphX 和 Spark 流。您可以在同一个应用程序中无缝地组合这些库。
各种环境都可以运行,Spark 在 Hadoop、Apache Mesos、Kubernetes、单机或云主机中运行。它可以访问不同的数据源。您可以使用它的独立集群模式在 EC2、Hadoop YARN、Mesos 或 Kubernetes 上运行 Spark。访问 HDFS、Apache Cassandra、Apache HBase、Apache Hive 和数百个其他数据源中的数据。
???? Spark 生态系统 —— BDAS
目前,Spark 已经发展成为包含众多子项目的大数据计算平台。BDAS 是伯克利大学提出的基于 Spark 的数据分析栈(BDAS)。其核心框架是 Spark,同时涵盖支持结构化数据 SQL 查询与分析的查询引擎 Spark SQL,提供机器学习功能的系统 MLBase 及底层的分布式机器学习库 MLlib,并行图计算框架 GraphX,流计算框架 Spark Streaming,近似查询引擎 BlinkDB,内存分布式文件系统 Tachyon,资源管理框架 Mesos 等子项目。这些子项目在 Spark 上层提供了更高层、更丰富的计算范式。

✅ Spark-Shell的简单使用
安装的就忽略不说了,网上一查一大把。我们通过在终端输入 spark-shell,从而进入到Spark自带的一个Scala交互Shell,启动成功后如下:
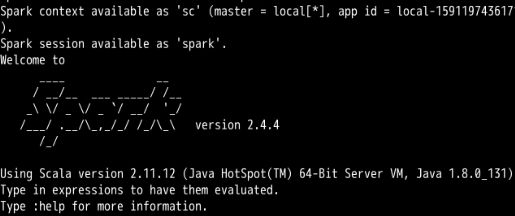
我们可以简单操作一下,比如我们读取一个文件,然后统计它的一些信息:
case1:简单展示
var file = sc.textFile("/etc/protocols")
file.count()
file.first()
上面的语句的意思就是创建一个RDD file,然后执行简单的count和first操作。
case2:统计多少行满足条件
当然我们可以执行更多复杂一丢丢的操作,比如查找有多少行含有 tcp 和udp字符串:
file.filter(line => line.contains("tcp")).count()
file.filter(line => line.contains("udp")).count()

case3:统计有多少不同单词的方法
这里稍微复杂一点,可以稍微看一看就好了。
var wordcount = file.flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey(_+_)
wordcount.count()

case4:ctrl+D退出Shell
这个简单,就是快捷键退出当前的Spark-Shell环境。
✅ Pyspark的简单使用
Pyspark和刚刚讲的类似,但是一个Python和交互Shell。通常就是执行pyspark进入到Pyspark。

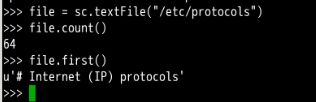
然后简单的调用一下,先读入文件:
file = sc.textFile("/etc/protocols")
file.count()
file.first()
更多的介绍要看官方文档:http://spark.apache.org/docs/latest/api/python/index.html
???? Spark 服务的启动流程
我们大概会按照以下几个步骤来进行Spark服务的启动与操作:
启动主节点
启动从节点
测试实例
停止服务
1 启动主节点
主要就是通过执行下面几条命令来执行启动主节点:
# 进入到spark目录
cd /opt/spark-2.4.4-bin-hadoop2.7/sbin
# 启动主节点
./start-master.sh
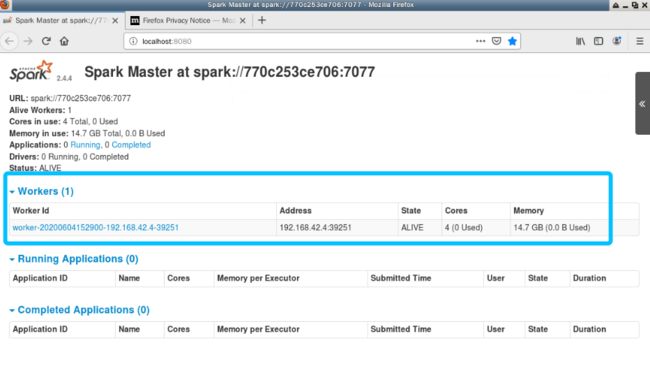
正常情况下没有报错就代表启动成功了,可以试着访问 http://localhost:8080

这里有一点需要注意的,那就是后续我们启动worker是需要master的参数的,而这个参数就是上图中的 //770c253ce706:7077(不同人会不一样的)。
2 启动从节点
那么启动完主节点后,我们就可以启动一下从节点(也就是worker),代码如下:
./start-slave.sh spark://770c253ce706:7077
没有报错,那么重新刷新一下刚刚的页面,可以看到有一个新的worker。
3 测试实例
我们可以通过输入 jps 命令来查看启动的服务。
接下来我们使用spark-shell来连接master,
MASTER=spark://770c253ce706:7077s spark-shell #执行需要等待一小会
接下来我们刷新一下刚刚的页面,就可以看到新的正在运行的应用了,如下图所示:

4 停止服务
如果我们想要停止服务,脚本为:
./stop-all.sh
jps
以上的Spark的一些基础的知识,可以简单浏览一下,算是起了个头,后续会继续更新一些实战型的知识,直接从实际的项目开始总结经验并分享知识,主要是用PySpark啦,所以也会大篇幅会讲一些PySpark的使用方法和技巧。目前我在读的一本书是 Tomasz Drabas的《PySpark实战指南》,有兴趣的同学可以一起来看看。
???? References
Spark大数据实战课程——实验楼