二进制日志的工作模式 (二进制日志的类型)
1.statement 语句模式(mysql5.6的默认模式),记录数据库中所有操作过的的'SQL语句'(create insert alter drop)
优点:易读,相对于行级模式,占用磁盘空间小
缺点:不安全
2.row 行级模式
优点:安全
缺点:'不易读',相对于语句模式,占用磁盘大
3.mixed 混合模式
#查看mysql工作模式
5.7.6之前默认为STATEMENT模式。MySQL 5.7.7之后默认为ROW模式。这个参数主要影响主从复制(也就是说mysql5.7.7之后,主从方式会修改)
mysql> show variables like '%binlog_format%';
+---------------+-----------+
| Variable_name | Value |
+---------------+-----------+
| binlog_format | STATEMENT |
+---------------+-----------+
---------------------------------------------------------
#查看statement工作模式的binlog
[root@db03 data]# mysqlbinlog mysql-bin.000014
/*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=1*/;
/*!40019 SET @@session.max_insert_delayed_threads=0*/;
/*!50003 SET @OLD_COMPLETION_TYPE=@@COMPLETION_TYPE,COMPLETION_TYPE=0*/;
DELIMITER /*!*/;
# at 4
#200723 8:05:42 server id 2 end_log_pos 120 CRC32 0xf44bc0a5 Start: binlog v 4, server v 5.6.46-log created 200723 8:05:42 at startup
# Warning: this binlog is either in use or was not closed properly.
ROLLBACK/*!*/;
BINLOG '
VtQYXw8CAAAAdAAAAHgAAAABAAQANS42LjQ2LWxvZwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAABW1BhfEzgNAAgAEgAEBAQEEgAAXAAEGggAAAAICAgCAAAACgoKGRkAAaXA
S/Q=
'/*!*/;
# at 120
#200723 8:16:52 server id 2 end_log_pos 208 CRC32 0x65d2cf88 Query thread_id=6 exec_time=0 error_code=0
SET TIMESTAMP=1595463412/*!*/;
SET @@session.pseudo_thread_id=6/*!*/;
SET @@session.foreign_key_checks=1, @@session.sql_auto_is_null=0, @@session.unique_checks=1, @@session.autocommit=1/*!*/;
SET @@session.sql_mode=1075838976/*!*/;
SET @@session.auto_increment_increment=1, @@session.auto_increment_offset=1/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
SET @@session.lc_time_names=0/*!*/;
SET @@session.collation_database=DEFAULT/*!*/;
create database xs
/*!*/;
# at 208
#200723 8:20:15 server id 2 end_log_pos 301 CRC32 0x52edbfa7 Query thread_id=7 exec_time=1 error_code=0
use `xs`/*!*/;
SET TIMESTAMP=1595463615/*!*/;
create table xs(id int) 'create'
/*!*/;
# at 301
#200723 8:20:46 server id 2 end_log_pos 376 CRC32 0x8ff0ec90 Query thread_id=7 exec_time=0 error_code=0
SET TIMESTAMP=1595463646/*!*/;
BEGIN
/*!*/;
# at 376
#200723 8:20:46 server id 2 end_log_pos 473 CRC32 0xe9d72178 Query thread_id=7 exec_time=0 error_code=0
SET TIMESTAMP=1595463646/*!*/;
insert xs values(0),(1),(2) 'insert'
/*!*/;
# at 473
#200723 8:20:46 server id 2 end_log_pos 504 CRC32 0x75c0d272 Xid = 64
COMMIT/*!*/;
# at 504 #####drop之前的位置点(end_log_pos 615)-------------
#200723 8:21:15 server id 2 end_log_pos 615 CRC32 0xa77379b1 Query thread_id=7 exec_time=0 error_code=0
SET TIMESTAMP=1595463675/*!*/;
SET @@session.pseudo_thread_id=7/*!*/;
DROP TABLE `xs` /* generated by server */ 'drop'
/*!*/;
DELIMITER ;
# End of log file
ROLLBACK /* added by mysqlbinlog */;
/*!50003 SET COMPLETION_TYPE=@OLD_COMPLETION_TYPE*/;
/*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=0*/;
----------------------------------------------------------------------------
#配置row工作模式(binlog起始大小167)
[root@db03 data]# vim /etc/my.cnf
binlog_format=row
mysql> show variables like '%binlog_format%';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| binlog_format | ROW |
+---------------+-------+
#查看binlog
[root@db02 data]# mysqlbinlog mysql-bin.000002
/*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=1*/;
/*!40019 SET @@session.max_insert_delayed_threads=0*/;
/*!50003 SET @OLD_COMPLETION_TYPE=@@COMPLETION_TYPE,COMPLETION_TYPE=0*/;
DELIMITER /*!*/;
# at 4
#200723 20:18:15 server id 1 end_log_pos 120 CRC32 0xfefb1228 Start: binlog v 4, server v 5.6.46-log created 200723 20:18:15 at startup
# Warning: this binlog is either in use or was not closed properly.
ROLLBACK/*!*/;
BINLOG ' #该位置为加密后的SQL语句
B4AZXw8BAAAAdAAAAHgAAAABAAQANS42LjQ2LWxvZwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAHgBlfEzgNAAgAEgAEBAQEEgAAXAAEGggAAAAICAgCAAAACgoKGRkAASgS
+/4=
'/*!*/;
# at 120
create alter 仍会记录,show use select drop updata不会记录
#查看row模式的binlog(mysqlbinlog --help)(@1=1所在位置附近为SQL语句)
[root@db03 data]# mysqlbinlog --base64-output=decode-rows -vvv mysql-bin.000016
# at 759
#200723 20:31:27 server id 1 end_log_pos 806 CRC32 0x53bad73a Table_map: `cs`.`css` mapped to number 72
# at 806
#200723 20:31:27 server id 1 end_log_pos 852 CRC32 0x07f740a8 Update_rows: table id 72 flags: STMT_END_F
### UPDATE `cs`.`css` #row模式下的SQL语句,语句多,占用空间大
### WHERE
### @1=2 /* INT meta=0 nullable=1 is_null=0 */
### @2=NULL /* INT meta=10 nullable=1 is_null=1 */
### SET
### @1=100 /* INT meta=0 nullable=1 is_null=0 */
### @2=NULL /* INT meta=10 nullable=1 is_null=1 */
# at 852
----------------------------------------------------------------
#二进制不同的工作模式产生的binlog,肯定不能导入另一种工作模式的库,所以mixed一般不会使用
慢日志
概念:
作用:
1.是将mysql服务器中'影响数据库性能'的相关SQL语句'记录'到日志文件
2.通过对这些特殊的'SQL语句分析',改进以达到'提高数据库性能'的目的(优化)
#配置慢日志
[root@db01 ~]# vim /etc/my.cnf
[mysqld]
#指定是否开启慢查询日志
slow_query_log = 1
#指定慢日志文件存放位置(默认在data)
slow_query_log_file=/service/mysql/data/slow.log
#设定慢查询的阀值(默认10s)
long_query_time=0.05
#不使用索引的慢查询日志是否记录到日志
log_queries_not_using_indexes
#查询检查返回少于该参数指定行的SQL不被记录到慢查询日志
min_examined_row_limit=100(鸡肋)
slow_query_log = 1
slow_query_log_file=/service/mysql/data/slow.log
long_query_time=3
log_queries_not_using_indexes
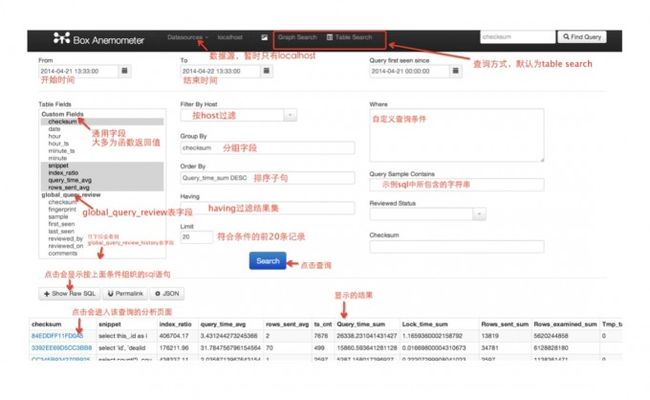
慢日志测试
#建表
mysql> create table solwlog2 select * from city;
Query OK, 4079 rows affected (0.07 sec)
Records: 4079 Duplicates: 0 Warnings: 0
#反复插入
mysql> insert solwlog select * from solwlog;
Query OK, 2088448 rows affected (9.00 sec)
Records: 2088448 Duplicates: 0 Warnings: 0
#查看慢日志
[root@db03 data]# less slow.log
-----------------------------------------------------------------------
分析慢日志
#输出记录次数最多的10条SQL语句
mysqldumpslow -s c -t 10 /database/mysql/slow-log
-s:
是表示按照何种方式'排序',c、t、l、r分别是按照记录次数、时间、查询时间、返回的记录数来排序,ac、at、al、ar,表示相应的'倒叙';
-t:
是top n的意思,即为返回前面'多少条'的数据;
-g:
后边可以写一个正则匹配模式,大小写不敏感的;(过滤)
#例子:
#得到返回记录集最多的10个查询
mysqldumpslow -s r -t 10 /database/mysql/slow-log
#得到按照时间排序的前10条里面'含有'左连接的查询语句
mysqldumpslow -s t -t 10 -g "left join" /database/mysql/slow-log
-------------------------------------------------------------------
有能力的可以做成可视化界面:
Anemometer基于pt-query-digest将MySQL慢查询可视化
https://www.percona.com/downloads/percona-toolkit/LATEST/ 慢日志分析工具下载
https://github.com/box/Anemometer 可视化代码下载
第三方推荐(扩展):
yum install -y percona-toolkit-3.0.11-1.el6.x86_64.rpm
使用percona公司提供的pt-query-digest工具分析慢查询日志
[root@mysql-db01 ~]# pt-query-digest /application/mysql/data/mysql-db01-slow.log
备份
#mysql客户端
1.mysql
2.mysqldump
3.mysqladmin
#备份的作用
恢复,防止数据丢失
#备份的类型
1.冷备,停库,停服务,再备份
2.温备,不停库,不停服务,锁表(阻止数据写入),再备份
3.热备,不停库,不停服务,再备份
#备份的方式
1.全量备份,全部数据备份
这些备份在用户不能访问数据时进行,因此无法读取或修改数据。这些脱机备份会'阻止'执行任何使用数据的活动。这些类型的备份'不会干扰'正常运行的系统的性能。但是,对于某些应用程序,会无法接受必须在一段较长的时间里锁定或完全阻止用户访问数据。
2.增量备份,针对于上一次备份,将新数据备份
这些备份在读取数据时进行,但在多数情况下,在进行备份时不能修改数据本身。这种中途备份类型的优点是不必完全锁定最终用户。但是,其不足之处在于无法在进行备份时修改数据集,这可能使这种类型的备份不适用于某些应用程序。在备份过程中无法修改数据可能产生性能问题。
3.差异备份,基于上一次'全备'进行新数据的备份
这些动态备份在读取或修改数据的过程中进行,很少中断或者不中断传输或处理数据的功能。使用热备份时,系统仍可供读取和修改数据的操作访问。
#备份的方式
1.逻辑备份
基于SQL语句的备份
1.binlog
2.into outfile(需要配置文件中配置:secure-file-priv)
[root@db03 data]# vim /etc/my.cnf
[mysqld]
secure-file-priv=/tmp
mysql> select * from world.city into outfile '/tmp/world_city.data';
3.主从复制,为了读写分离 MHA打下基础
4.mysqldump(###)
5.replication
2.物理备份
1.备份整个data目录,停库,打包,拷贝,解压即用,查看(占用磁盘空间大,需要取出drop前的那段binlog)
2.xtrabackup可以进行增量备份,但是不易恢复
#旧库初始化数据库
/etc/init.d/mysqld stop && rm -rf ../data/* && ./mysql_install_db --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data/
四、mysqldump客户端
1.常用参数
1.不加参数:用于备份单个表
1)备份库
[root@db02 ~]# mysqldump ku > /tmp/ku.sql
2)备份表
[root@db02 ~]# mysqldump ku test > /tmp/ku.sql
3)备份多个表
[root@db02 ~]# mysqldump ku test test2 test3 > /tmp/ku.sql
#注意:当不加参数时命令后面跟的是库名,库的后面全都是必须是该库下面的表名
2.连接服务端参数(基本参数):-u -p -h -P -S
3.-A, --all-databases:全库备份
4.-B:指定库备份
[root@db01 ~]# mysqldump -uroot -p123 -B db1 > /backup/db1.sql
[root@db01 ~]# mysqldump -uroot -p123 -B db1 db2 > /backup/db1_db2.sql
5.-F:flush logs在备份时自动刷新binlog(不怎么常用)
[root@db01 backup]# mysqldump -uroot -p123 -A -F > /backup/full_2.sql
6.--master-data=2:备份时加入change master语句,在文件的22行,记录binlog的位置点
1)等于2:记录binlog信息,并注释(使用最多)
2)等于1:记录binlog信息,不注释(扩展多个从库的时候使用,不需要再指定位置点 master_log_file master_log_pos)
0)等于0:不记录binlog信息
[root@db01 backup]# mysqldump -uroot -p123 --master-data=2 >/backup/full.sql
7.--single-transaction:快照备份(该参数与 --master-data=2 一起,组成'热备')
8.-d:仅表结构(x)
9.-t:仅数据(x)
10.-R, --routines:备份存储过程和函数数据
11.--triggers:备份触发器数据,也是个表(相当于外键)
12.gzip:压缩备份(备份处理的'文件较大'的时候使用)
#备份成压缩包
[root@db01 ~]# mysqldump -uroot -p123 -A | gzip > /backup/full.sql.gz
#恢复压缩包中的数据
[root@db03 ~]# zcat /tmp/full.sql.gz | mysql -uroot -p123
[root@db03 ~]# mysql -uroot -p123 < zcat /tmp/full.sql.gz
#完整的备份命令:
mysqldump -uroot -p -A -R --triggers --master-data=2 --single-transaction > /tmp/full.sql
#使用mysqldump命令备份的库保存在文件中,该文件中含有(create--drop)语句
#位置点
[root@db02 tmp]# head -22 full.sql |tail -1
-- CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000005', MASTER_LOG_POS=1464;
#删除drop语句
[root@db02 tmp]# vim full.sql
DROP TABLE IF EXISTS `cs`; ###################
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!40101 SET character_set_client = utf8 */;
CREATE TABLE `cs` (
`id` int(11) DEFAULT NULL,
`status` enum('1','0') DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
/*!40101 SET character_set_client = @saved_cs_client */;
2.注意:
1)mysqldump在备份和恢复时都需要MySQL实例'启动'为前提
2)一般数据量级'100G以内',大约15-30分钟可以恢复
3)mysqldump是以'覆盖'的形式恢复数据的(因为导出的时候添加了drop语句)
五、企业案例
1.背景
1.正在运行的网站系统,MySQL数据库,数据量25G,日业务增量10-15M。
2.备份策略:每天23:00,计划任务调用'mysqldump执行全备脚本'
3.故障时间点:上午10点开发人员'误删除一个核心业务表',如何恢复?
2.思路
1.'停库',避免二次伤害
2.'创建新库'(在这个库做恢复数据的实验)
3.倒入前一天的'全备'
4.通过'binlog'找到前一天23:00到第二天10点之间的数据
5.导入找到的新数据
6.恢复业务
a.直接使用临时库顶替原生产库,前端应用'割接'到新库(数据量特别大的时候)
b.'将误删除的表单独导出',然后导入到原生产环境(数据量小的时候)
3.模拟案例
1)模拟生产数据
create database dump;
use dump;
create table dump(id int);
insert dump values(1),(2),(3),(4);
select * from dump;
2)模拟23:00全备(定时任务)
[root@db03 mysql]# mysqldump -uroot -p -A -R --triggers --master-data=2 --single-transaction > /tmp/full.sql
3)模拟23:00到10:00的数据操作(全备后,数据损坏之前)
use dump;
insert dump values(1000),(2000),(3000),(4000);
select * from dump;
4)模拟删库
drop database dump; #删除的是库,binlog里面只有建表语句
show databases;
4.恢复数据
1)停库,避免二次伤害
[root@db03 mysql]# /etc/init.d/mysqld stop && netstat -lntup
2)创建新的数据库
3)导入前一天的全备
#老库将数据传输到新库
[root@db03 ~]# scp /tmp/full.sql 172.16.1.52:/tmp/
#新库导入全备数据
[root@db02 ~]# mysql -uroot -p < /tmp/full.sql
4)通过binlog找到前一天23:00到第二天10点之间的数据
1.找到binlog的起始位置点
[root@db03 data]# head -22 /tmp/full.sql | tail -1
-- CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000005', MASTER_LOG_POS=682815;
2.找到结束位置点
[root@db03 data]# mysqlbinlog mysql-bin.000006 > 1.txt && grep -A 4 'drop database dump' 1.txt
COMMIT/*!*/;
# at 682325 #########
#200724 20:16:00 server id 1 end_log_pos 682417(不是这个)
drop database dump
3.取出位置点之间的数据(通过位置点大小判断)
[root@db03 data]# mysqlbinlog -d dump --start-position=971790 --stop-position=972068 mysql-bin.000006 > /tmp/new.sql
5)导入找到的新数据
#老库将binlog数据传到新库
[root@db03 ~]# scp /tmp/new.sql 172.16.1.52:/tmp/
#新库导入新的数据
[root@db02 ~]# mysql -uroot -p < /tmp/new.sql
6)确认数据
mysql> use dump
mysql> show tables;
+----------------+
| Tables_in_dump |
+----------------+
| dump |
+----------------+
mysql> select * from dump;
+------+
| id |
+------+
| 1 |
| 2 |
| 3 |
| 4 |
| 1000 |
| 2000 |
| 3000 |
| 4000 |
+------+
7)恢复业务
1.直接使用临时库顶替原生产库,前端应用割接到新库(数据量特别大的时候)
2.将误删除的表单独导出,然后导入到原生产环境(数据量小的时候)
#如果采用第一种方法的话,到这交给开发就好
#采用第二种方法如下
1)新库导出指定业务库
[root@db02 ~]# mysqldump dump > /tmp/dump.sql
2)新库将数据推送回老库
[root@db02 ~]# scp /tmp/dump.sql 172.16.1.53:/tmp
3)将恢复的数据导入老库
mysql> create database dump;
mysql> use dump;
mysql> create database dump;
mysql> source /tmp/dump.sql; #数据量大的时候建议使用
#mysqldump指定库导出,那么mysql -uroot -p dump < xx就指定库导入