爬虫-反爬三:requests + python 实现微博登录
文章目录
- 絮叨一下
- 分析
- 1.第一个参数su查找
- 1.1 js代码
- 1.2 python实现
- 2.nonce、pcid、rsakv、servertime
- 2.1 python实现
- 3.验证码获取
- 3.1 python实现
- 4.sp 的查找
- 4.1 js分析
- 4.2python实现
- 5.封装表单进行发送数据
- 5.1python实现
- 6.获取cookies
- 6.1 补全cookies
- 6.2 python实现
- 7.整体组合
- 写给看到最后的你
絮叨一下
反爬系列三:登录微博 微博首页
使用技术:base64加密解密、RSA非对称加密
、重定向
往期反爬一:boos直聘:boos直聘
往期反爬二:有道翻译:有道翻译
首先了解一下 两个加密技术:
base64加密的原理:直达链接
RSA非对称加密:直达链接
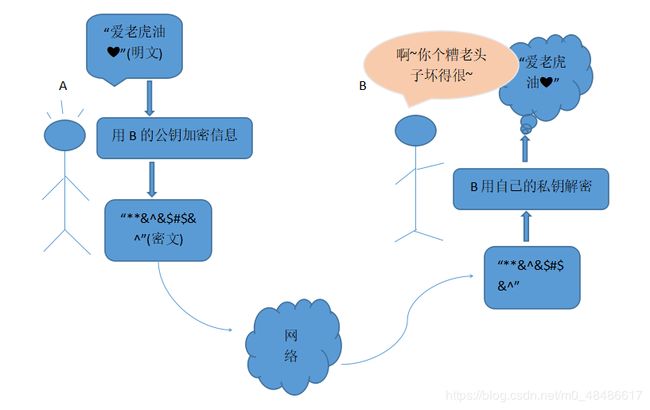
我是在整体代码中分离,分开说的,分断代码要是有误,可以留言给我我改一下,如果分开看看不明白,可以看一下最后的整体代码,看起来会全面一点。
分析
主页地址:
打开开发者工具(F12)
这里勾选上 Preserve log
以便我们抓取登录前的数据

输入账号密码验证码后点击登录

发现login.php这个应该是登录发送请求的
点进去后发现确实是

重新登录几遍发现几个变化的值
rsakv 、nonce、servertime、pcid、sp这几个值是变化的
1.第一个参数su查找
su 不知到是什么,看起来应该像是账号名 看一下js文件
1.1 js代码
然后搜索su 
发现是b 赋值 ,b 是一个base64加密的一个东西,我们可以拿到在线解析网站查看一下

确实是账号名
1.2 python实现
import base64
user = '15645817254'
base64.b64encode(user.encode()).decode()
2.nonce、pcid、rsakv、servertime
这些参数发现是前面的get请求返回后得到的

https://login.sina.com.cn/sso/prelogin.php?entry=weibo&callback=sinaSSOController.preloginCallBack&su=&rsakt=mod&client=ssologin.js(v1.4.19)&_=1592886030619
callback可以省略不写 su 应该是加密后的账号 最后那个应该是时间戳
知道这些就可以构造请求地址了

后面是个时间戳使用time生成就可
2.1 python实现
import requests
import base64
import json
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.122 Safari/537.36'
}
def get_nonce():
"""获取nonce以及rsaky、pubkey、 servertime"""
nonce_url = 'https://login.sina.com.cn/sso/prelogin.php?entry=weibo&callback=&su={0}&rsakt=mod&checkpin=1&client=ssologin.js(v1.4.19)&_={0}'.format ( base64.b64encode(user.encode()).decode(), time.time () * 1000)
nonce_response = requests.get (nonce_url, headers=headers).content.decode ()
nonce_response_dist = json.loads(nonce_response)
nonce = nonce_response_dist['nonce']
rsakv = nonce_response_dist['rsakv']
pubkey = nonce_response_dist['pubkey']
time = str(nonce_response_dist['servertime'])
pcid = nonce_response_dist['pcid']
3.验证码获取
其中有一个door参数看到值很明确是验证码,这个验证码肯定是发送了某个请求获取到的
在找一下
https://login.sina.com.cn/cgi/pin.php?r=30425966&s=0&p=tc-55b7076d7f223cb2a88dd5510f7baffbf43d
发现这个地址生成了验证码
这写参数很明显可以看出来p 就是刚才第二步中生成的pcid 的值,至于r是什么我们删了r看一下能不能请求到验证码,发现也是没有任何问题的
那就可以断定,决定验证码的就是p 的值
3.1 python实现
img_url = self.session.get ('https://login.sina.com.cn/cgi/pin.php?p={}'.format (pcid))
with open('img.png','wb') as fp:
fp.write(img_url.content)
运行后发现如我们所愿验证码保存到 了本地
然后可以PIL进行处理,或者是接入打码平台;

4.sp 的查找
4.1 js分析
经过查找js 发现这样一段关键js代码
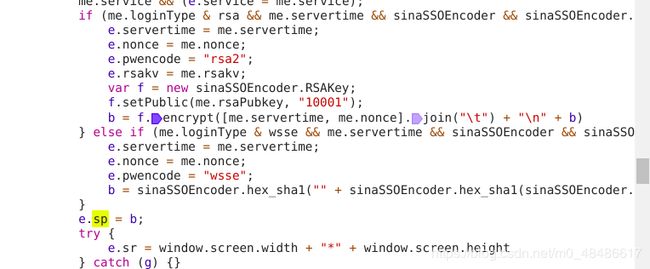
发现是RSA加密,既然是非对称加密就需要他的公钥
还有16进制的 ‘10001’
然后加上服务器时间以及nonce 在进行重新组合 加换行 加 密码
这样进行加密
也就是 时间 \t nonce \n 密码
还记得不记得 第二步 获取 nonce 等参数 有这样一个键值对
pubkey 这个应该就是他的公钥了
![]()
4.2python实现
import json
import time
from binascii import b2a_hex
import requests
import rsa
def get_sp():
"""密码"""
message = str(time) + '\t' + nonce + '\n' + password
key = rsa.PublicKey (int (pubkey, 16), 65537)
# 65537转成16进制就是10001 加载公钥 传入参数 n 和 e
pwd = rsa.encrypt(message.encode(),key)
# 加密成密文
self.sp = b2a_hex(pwd).decode()
# 转换成16进制
5.封装表单进行发送数据
5.1python实现
def login():
"""进行数据的封装,登录"""
img_url = self.requests.get ('https://login.sina.com.cn/cgi/pin.php?p={}'.format (pcid))
with open('img.png','wb') as fp:
fp.write(img_url.content)
img = input("验证码:")
data = {
'entry': 'account',
'gateway': 1,
'from': 'null',
'savestate': 30,
'useticket': 0,
'pagerefer': 'https://login.sina.com.cn/crossdomain2.php?action=login&entry=weibo&r=https%3A%2F%2Flogin.sina.com.cn%2F&sr=1476%2A830&',
'pcid': pcid,
'door': str(img),
'vsnf': 1,
'su': base64.b64encode(user.encode()).decode(),
'service': 'account',
'servertime': str(int(time)),
'nonce': nonce,
'pwencode': 'rsa2',
'rsakv': rsakv,
'sp': sp,
'sr': '1476*830',
'encoding': 'UTF-8',
'cdult': 3,
'domain': 'weibo.com',
'prelt': 448,
'returntype': 'TEXT',
}
response = response.post (self.login_url, headers=self.headers, data=data).json()
print(response)

我们获取到了这样的一个json文件
这样是可以证明我们已经登录成功,,但是我们要访问主页是不行的,是确实cookies 的
6.获取cookies
6.1 补全cookies
想要获取到完整的cookies 还需要在发送一个请求 也就是上面返回数据的第一个url
6.2 python实现
cross_url = response['crossDomainUrlList'][0]
这样就获取到了第一个链接,然后去请求
当然了 访问主页是需要使用cookies 的 那我们就新建一个session对象,岂不是更好
7.整体组合
# coding:utf-8
import json
import time
from binascii import b2a_hex
import requests
import base64
import rsa
class Sina:
def __init__(self):
self.session = requests.session ()
# 获取nonce、rsakv、pubkey、 srevertime 等 的请求链接,返回的这些数据
self.login_url = 'https://login.sina.com.cn/sso/login.php?client=ssologin.js(v1.4.19)&_={0}'.format(time.time()*1000)
self.user = '15645817254'
self.password = 'ff00456789'
self.headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.122 Safari/537.36'
}
def get_nonce(self):
"""获取nonce以及rsaky、pubkey、 servertime"""
nonce_url = 'https://login.sina.com.cn/sso/prelogin.php?entry=weibo&callback=&su={0}&rsakt=mod&checkpin=1&client=ssologin.js(v1.4.19)&_={0}'.format ( base64.b64encode(self.user.encode()).decode(), time.time () * 1000)
nonce_response = self.session.get (nonce_url, headers=self.headers).content.decode ()
nonce_response_dist = json.loads(nonce_response)
self.nonce = nonce_response_dist['nonce']
# 获取nonce
self.rsakv = nonce_response_dist['rsakv']
# 获取rsakv
self.pubkey = nonce_response_dist['pubkey']
# 获取pubkey
self.time = str(nonce_response_dist['servertime'])
# 获取服务器时间servertime
self.pcid = nonce_response_dist['pcid']
# 获取pcid
def get_sp(self):
"""获取加密的密码"""
message = str(self.time) + '\t' + self.nonce + '\n' + self.password
key = rsa.PublicKey (int (self.pubkey, 16), 65537)
pwd = rsa.encrypt(message.encode(),key)
self.sp = b2a_hex(pwd).decode()
def login(self):
"""进行数据的封装,登录"""
img_url = self.session.get ('https://login.sina.com.cn/cgi/pin.php?p={}'.format (self.pcid))
# 请求验证码获取地址,获取验证码
with open('img.png','wb') as fp:
fp.write(img_url.content)
# 保存验证码
img = input("验证码:")
# 手动输入验证码
data = {
'entry': 'account',
'gateway': 1,
'from': 'null',
'savestate': 30,
'useticket': 0,
'pagerefer': 'https://login.sina.com.cn/crossdomain2.php?action=login&entry=weibo&r=https%3A%2F%2Flogin.sina.com.cn%2F&sr=1476%2A830&',
'pcid': self.pcid,
'door': str(img),
'vsnf': 1,
'su': base64.b64encode(self.user.encode()).decode(),
'service': 'account',
'servertime': str(int(self.time)),
'nonce': self.nonce,
'pwencode': 'rsa2',
'rsakv': self.rsakv,
'sp': self.sp,
'sr': '1476*830',
'encoding': 'UTF-8',
'cdult': 3,
'domain': 'weibo.com',
'prelt': 448,
'returntype': 'TEXT',
}
response = self.session.post (self.login_url, headers=self.headers, data=data).json()
# 进行post登录
cross_url = response['crossDomainUrlList'][0]
# 解析返回的json 获取第一个url
self.session.get(cross_url)
# 请求第一个链接进行补全cookies
mysian = self.session.get(url = 'https://my.sina.com.cn/').content.decode()
# 然后访问主页
print(mysian)
def run(self):
self.get_nonce()
# 获取nonce等
self.get_sp()
# 密码
self.login()
# 登录
if __name__ == '__main__':
sina = Sina()
sina.run()
运行起来后输入验证码就会发现返回了正常数据给我们,可以查到微博名了。证明访问成功

还有一点就是 文中的微博号是我买的,可以测试使用
写给看到最后的你
朋友,感谢你看到了最后,新手报道,技术不成熟的地方请多多指点,感谢!
公众号:Linux下撸python
期待和你再次相遇
愿你学的愉快
