spark 按照key分区之后,只要分区数量一样,数据都会在一个分区内
val userMouth = sc.parallelize(Array(
"201712",
"201801",
"201802",
"201803",
"201804",
"201805",
"beijing",
"-9223054359956171777",
"5296157422194892569")).collect()
import scala.collection.mutable.ArrayBuffer
var rdd2 = sc.parallelize(userMouth).map(x => { (x, "") }).partitionBy(new HashPartitioner(4096)).mapPartitionsWithIndex {
(x, iter) =>
{
var result = ArrayBuffer[(String)]()
var i = 0
var s = ""
while (iter.hasNext) {
var p = iter.next()
var s = (p + "|" + x)
result += s
}
result.iterator
}
}
var rdd3 = rdd2.filter { x => { x.contains("5296157422194892569") } }
for (x <- rdd2.collect()) { println(x) }
------------------------------
输出 : 如果本次数据分区为4096,以后北京这个用户都有会在1451这个分区。
(201712,)|517
(5296157422194892569,)|568
(201801,)|1446
(201802,)|1447
(201803,)|1448
(201804,)|1449
(201805,)|1450
(beijing,)|1451
(-9223054359956171777,)|3127
其实我想说的是,有了这个特点之后,为我们快速在hdfs建立索引单个用户的数据提供可能性
---------------------------------------------------------------------------------------------------------------------------------------------------------------------
接下口语分析一下spark在分问题,这里我也最常见的 HashPartitioner为例。有的数据为了业务需求我们需要把数据分区到一定数量内,确保程序执行的速度。
第一步: 在上面的代码内我指定了分区对象为HashPartitioner,分区数量为4096,即将数据按照key分成4096份
new HashPartitioner(4096)
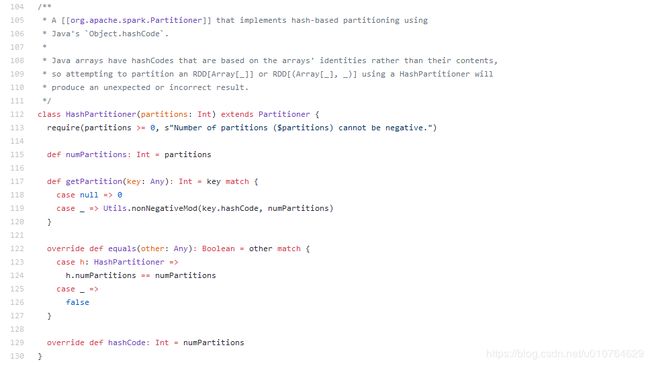
第二步: 进一步查看其实调用的是nonNegativeMod方法,org.apache.spark.util.Utils,这个方法很简单。
def nonNegativeMod(x: Int, mod: Int): Int = {
val rawMod = x % mod
rawMod + (if (rawMod < 0) mod else 0)
}
第三步:综合以上信息就可以自己定制一个自己想要的类型了