昨晚通宵生产压测,终于算是将生产服务宕机的原因定位到了,心累。这篇博客,算作一个复盘和记录吧。。。
先来看看Redis的缓存淘汰算法思维导图:
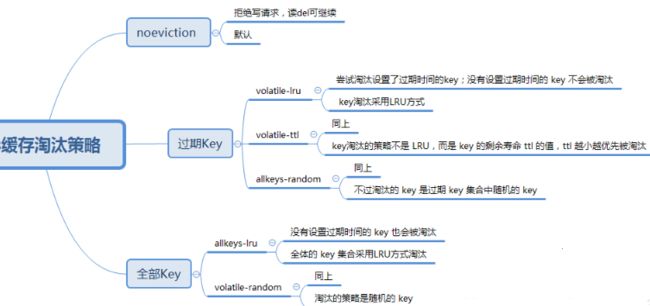
说明:当实际占用的内存超过Redis配置的maxmemory时,Redis就会根据用户选择淘汰策略清除被选中的key。
业务场景:用户通过微信入口来访问一个页面;
测试场景:通过多线程模拟定量的并发来访问页面服务;
涉及架构:springsession+Redis集群,容器部署;
问题描述:固定并发数压测10分钟,压测开始后半小时,Redis连接数激增,连接耗尽,服务重启;
处理逻辑:
①、用户通过入口页面访问服务时,springsession给每个用户创建一个session,将key存储在Redis中;
②、Redis默认配置每隔半小时,利用hGetAll函数遍历session-key所在的集合,将最近一分钟内要过期的key全部delete,释放内存;
宕机原因:
①、Redis是单线程处理,由于高并发压测,产生了百万级的key存储在set集合中,当hGetAll函数遍历集合删除过期session的key时,大量用户连接失效;
②、失效瞬间,Redis需要创建大量连接,如果TPS超过了设置的最大连接数,则Redis服务容器健康检查不通过;
③、通过选举,Redis集群主从切换时需要将master的数据复制到salve;
④、主从复制时,Redis定位区域buffer(软链接)超时,最终导致服务宕机重启。
优化方案:
①、选择Redis默认淘汰策略,每秒钟选择10次,每次不超过25个,即每秒钟淘汰≤250个key;
缺点:内存好用较高,需要通过横向扩展资源来应对该问题;
②、通过压测确定当前系统配置下的最大可处理阈值,通过网关限流、服务降级等措施来保障服务的稳定运行;
缺点:如果实际流量超过限流配置,则用户可能看到一些“友好界面”,用户体验不太好;
PS:在实际生产环境中,系统稳定性和可用性胜于一切!!!
相关参考:
Redis缓存淘汰算法
Redis的hGetAll函数的性能问题
以上就是此次问题复盘,虽然通宵带来的后遗症导致现在还有点迷糊,但从中学到了很多新的东西,值得思考与学习。。。