Sklearn 成长之路(三)Logistic回归以及L1和L2正则化影响
L1与L2正则化
在回归中设要估计的参数为 [ θ 1 , θ 2 , … , θ N ] T [\theta_1, \theta_2, …, \theta_N]^T [θ1,θ2,…,θN]T即 θ \theta θ,Loss-Function为 J ( θ ) J(\theta) J(θ)。
- L1正则化
- J ( θ ) L 1 = J ( θ ) + 1 C ∑ i = 1 N ∣ θ i ∣ J(\theta)_{L1} = J(\theta) + \frac{1}{C}\sum_{i = 1}^{N}|\theta_i| J(θ)L1=J(θ)+C1∑i=1N∣θi∣
- 加入L1正则化后会产生稀疏的 θ \theta θ参数,即其中有参数因为L1约束而为0,从后面程序输出也可以看出来有很多参数,在L1约束下等于0。
- L2正则化
- J ( θ ) L 2 = J ( θ ) + 1 C ∑ i = 1 N ( θ i ) 2 J(\theta)_{L2} = J(\theta) + \frac{1}{C}\sqrt{\sum_{i = 1}^{N}(\theta_i)^2} J(θ)L2=J(θ)+C1∑i=1N(θi)2
- 加入L2正则化同样会起到防止过拟合的作用,并且加入L2正则化的回归称为岭回归。
程序输出
传入数据集包含内容有: [‘data’, ‘target’, ‘target_names’, ‘DESCR’, ‘feature_names’]
训练集样本大小: (398, 30)
训练集标签大小: (398,)
测试集样本大小: (171, 30)
测试集标签大小: (171,)
L1正则化模型测试集准确率为: 0.9415204678362573
L2正则化模型测试集准确率为: 0.9415204678362573
L1正则化下的参数为:
[[ 3.72443117 0.05531356 -0.10692076 -0.0131987 0. 0.
0. 0. 0. 0. 0. 0.
0. -0.01176816 0. 0. 0. 0.
0. 0. 0. -0.24337485 -0.11001705 -0.0201578
0. 0. -1.80558931 0. 0. 0. ]]
L2正则化下的参数为:
[[ 1.51608502 0.16460064 0.08858714 -0.00573074 -0.07368111 -0.28769732
-0.45550276 -0.2008653 -0.1322971 -0.02288733 0.01942448 0.58497728
0.37449105 -0.06549691 -0.00913461 -0.04466828 -0.07672622 -0.02360131
-0.04451942 -0.00408327 1.06414388 -0.33328428 -0.16729646 -0.02285855
-0.14601609 -0.77196647 -1.07341452 -0.37770618 -0.40923048 -0.07920548]]
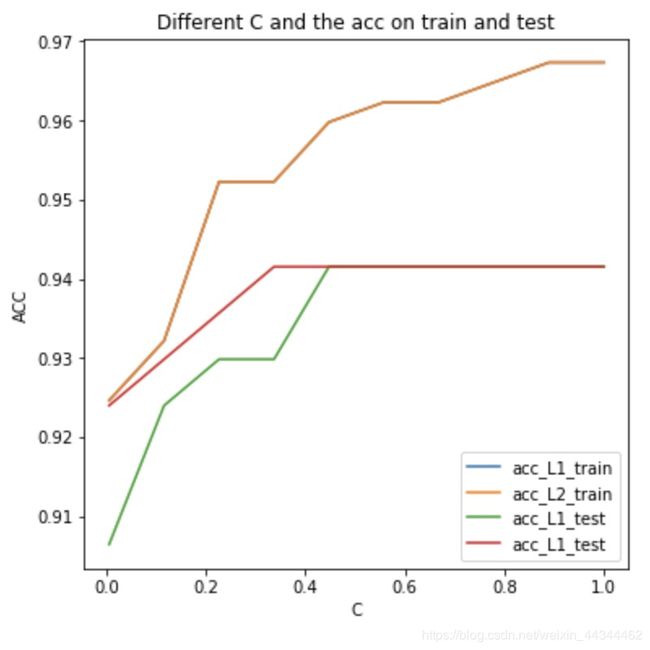
上图中acc_L1_train和acc_L2_train重合。
Show me the code
导包
# 数据集
from sklearn import datasets
# 对数回归模块
from sklearn.linear_model import LogisticRegression
# 指标模块
from sklearn.metrics import accuracy_score
# 划分测试集与训练集
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
获取数据模块
# 自定义导入数据集函数
def get_data(total_data):
# 显示total_data包含的内容
print("传入数据集包含内容有:", [x for x in total_data.keys()])
# 样本
x_true = total_data.data
# 标签
y_true = total_data.target
# 特征名称
feature_names = total_data.feature_names
# 类名
target_names = total_data.target_names
return x_true, y_true, feature_names, target_names
主函数及其调用
# 定义主函数
def main():
# 利用自定义函数导入Iris数据集
total_iris = datasets.load_breast_cancer()
x_true, y_true, feature_names, target_names = get_data(total_iris)
# 分割数据集
rate_test = 0.3 # 训练集比例
x_train, x_test, y_train, y_test = train_test_split(x_true,
y_true,
test_size= rate_test)
print("\n训练集样本大小:", x_train.shape)
print("训练集标签大小:", y_train.shape)
print("测试集样本大小:", x_test.shape)
print("测试集标签大小:", y_test.shape)
# 针对L1与L2正则化分别设置两个分类器
c = 0.5 # 正则化系数的倒数,这个c越小对theta的约束越强
L1LR = LogisticRegression(penalty= 'l1', C= c)
L2LR = LogisticRegression(penalty= 'l2', C= c)
# 训练模型
L1LR.fit(x_train, y_train)
L2LR.fit(x_train, y_train)
# 评价模型
score_L1LR = accuracy_score(L1LR.predict(x_test), y_test)
score_L2LR = accuracy_score(L2LR.predict(x_test), y_test)
print("\nL1正则化模型测试集准确率为:", score_L1LR)
print("L2正则化模型测试集准确率为:", score_L2LR)
# 显示两种正则化下的参数
print("\nL1正则化下的参数为:")
print(L1LR.coef_)
print("\nL2正则化下的参数为:")
print(L2LR.coef_)
######正则化项的系数倒数C对模型的影响######
c = np.linspace(0.005, 1, 10) # 不同的系数值
acc_L1_train = [] # 不同C下的L1训练集正确率
acc_L2_train = [] # 不同C下的L2训练集正确率
acc_L1_test = [] # 不同C下的L1测试集正确率
acc_L2_test = [] # 不同C下的L2测试集正确率
for i in range(len(c)):
# 针对当前的系数值训练模型
L1LR = LogisticRegression(penalty= 'l1', C= c[i]) # 构建模型
L2LR = LogisticRegression(penalty= 'l2', C= c[i])
L1LR.fit(x_train, y_train)
L2LR.fit(x_train, y_train)
# 得到当前的正确率
score_L1LR_train = accuracy_score(L1LR.predict(x_train), y_train) # 训练集
score_L2LR_train = accuracy_score(L1LR.predict(x_train), y_train)
score_L1LR_test = accuracy_score(L1LR.predict(x_test), y_test) # 测试集
score_L2LR_test = accuracy_score(L2LR.predict(x_test), y_test)
# 将当前正确率append到四个list
acc_L1_train.append(score_L1LR_train) # 训练集
acc_L2_train.append(score_L2LR_train)
acc_L1_test.append(score_L1LR_test) # 测试集
acc_L2_test.append(score_L2LR_test)
# 绘制
plt.figure(figsize= (6, 6))
plt.plot(c, acc_L1_train, label= "acc_L1_train",)
plt.plot(c, acc_L2_train, label= "acc_L2_train")
plt.plot(c, acc_L1_test, label= "acc_L1_test")
plt.plot(c, acc_L2_test, label= "acc_L1_test")
plt.legend(loc= 4)
plt.title("Different C and the acc on train and test")
plt.xlabel("C")
plt.ylabel("ACC")
plt.show()
######################################
# 调用主函数
if __name__ == "__main__":
main()