️ 后羿采集器——最良心的爬虫软件

2020 年如果让我推荐一款大众向的数据采集软件,那一定是后裔采集器了。和我之前推荐的 web scraper 相比,如果说 web scraper 是小而精的瑞士军刀,那后裔采集器就是大而全的重型武器,基本上可以解决所有的数据爬取问题。
下面我们就来聊聊,这款软件的优秀之处。
一、产品特点
1.跨平台
后羿采集器是一款桌面应用软件,支持三大操作系统:Linux、Windows 和 Mac,可以直接在官网上免费下载。

2.功能强大
后羿采集器把采集工作分为两种类型:智能模式和流程图模式。

智能模式就是加载网页后,软件自动分析网页结构,智能识别网页内容,简化操作流程。这种模式比较适合简单的网页,经过我的测试,识别准确率还是挺高的。
流程图模式的本质就是图形化编程。我们可以利用后裔采集器提供的各种控件,模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页的各种行为爬取数据。
3.导出无限制
这个可以说是后羿采集器最良心的功能了。
市面上有很多的数据采集软件,出于商业化的目的,多多少少会对数据导出进行限制。不清楚套路的人经常用相关软件辛辛苦苦采集了一堆数据,结果发现导出数据需要花钱。
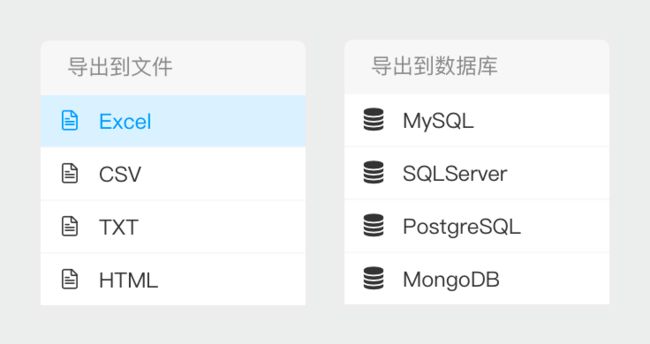
后羿采集器就没有这个问题,它的付费点主要是体现在 IP 池和采集加速等高级功能上,不但导出数据不花钱,还支持 Excel、CSV、TXT、HTML 多种导出格式,并且支持直接导出到数据库,对于普通的用户来说完全够用了。
4.教程详细
我在本文动笔之前曾经想过先写几篇后羿采集器的使用教程,但是看了他们的官网教程后就知道没这个必要了,因为写的实在是太详细了。
后羿采集器的官网提供了两种教程,一种是视频教程,每个视频五分钟左右;一种是图文教程,手把手教学。看完这两类教程后还可以看看他们的文档中心,写的也非常详细,基本覆盖了该软件的各个功能点。

二、基础功能
1.数据抓取
基本的数据抓取非常简单:我们只要点击「添加字段」那个按钮,就会出现一个选择魔棒,然后点选要抓取的数据,就能采集数据了:

2.翻页功能
我在介绍 web scraper 时曾把网页翻页分为 3 大类:滚动加载、分页器加载和点击下一页加载。

对于这三种基础翻页类型,后羿采集器也是完全支持的。
不像 web scraper 的分页功能散落在各种选择器上,后羿采集器的分页配置集中在一个地方上,只要通过下拉选择,就可以轻松配置分页模式。相关的配置教程可见官网教程:如何设置分页。

3.复杂表单
对于一些多项联动筛选的网页,后羿采集器也能很好的处理。我们可以利用后裔采集器里的流程图模式,去自定义一些交互规则。
例如下图,我就利用了流程图模式里的点击组件模拟点击筛选按钮,非常方便。
三、进阶使用
1.数据清洗
我在介绍 web scraper 时,说 web scraper 只提供了基础的正则匹配功能,可以在数据抓取时对数据进行初步的清洗。
相比之下,后羿采集器提供了更多的功能:强大的过滤配置,完整的正则功能和全面的文字处理配置。当然,功能强大的同时也带来了复杂度的提升,需要有更多的耐心去学习使用。
下面是官网上和数据清洗有关的教程,大家可以参考学习:
- 如何设置数据筛选讲解了基础的数据清洗功能,可以避免采集过程中的无效采集(例如采集某个微博博主的数据时,可以过滤第一条置顶微博的数据,只采集正常时间流的微博)
- 如何设置采集范围讲解了采集过程中过滤不需要的采集项,可以方便的自定义采集范围(例如采集豆瓣电影 TOP 250 时,只采集前 100 名的数据,而不是全量的 250 条数据)
- 如何对采集字段进行配置讲解了如何定制采集的最小字段,并且支持叠加处理,可以对一个字段使用多种匹配规则。(例如只想采集「1024 个赞」这条文本里的数字,就可以设置相应的规则过滤掉汉字)
2.流程图模式
本文前面也介绍过了,流程图模式的本质就是图形化编程。我们可以利用后裔采集器提供的各种控件,模拟编程语言中的各种条件控制语句,从而模拟真人浏览网页的各种行为爬取数据。
比如说下图这个流程图,就是模拟真人浏览微博时的行为去抓取相关数据。
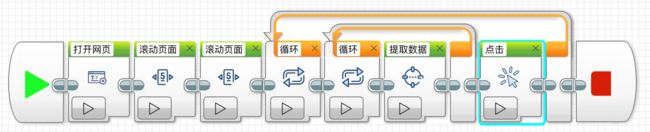
经过我个人的几次测试,我认为流程图模式有一定的学习门槛,但是和从头学习 python 爬虫比起来,学习曲线还是缓和了不少。如果对流程图模式很感兴趣,可以去官网上学习,写的非常详细。
3.XPath/CSS/Regex
无论是什么爬虫软件,他们都是基于一定的规则去抓取数据的。XPath/CSS/Regex 就是几个常见的匹配规则。后羿采集器支持自定义这几种选择器,可以更灵活的选择要抓取的数据。
比如说某个网页里存在数据 A,但只有鼠标移到对应的文字上才会以弹窗的形式显示出来,这时候我们就可以自己写一个对应的选择器去筛选数据。

XPath
XPath 是一种在爬虫中运用非常广泛的数据查询语言。我们可以通过 XPath 教程去学习这个语言的运用。
CSS
这里的 CSS 特指的 CSS 选择器,我之前介绍 web scraper 的高级技巧时,讲解过 CSS 选择器的使用场景和注意事项。感兴趣的人可以看我写的 CSS 选择器教程。
Regex
Regex 就是正则表达式。我们也可以通过正则表达式去选择数据。我也写过一些正则表达式的教程。但是个人认为在字段选择器这个场景下,正则表达式没有 XPath 和 CSS 选择器好用。
4.定时抓取/IP 池/打码功能
这几个都是后羿采集器的付费功能,我没有开会员,所以也不知道使用体验怎么样。在此我做个小小的科普,给大家解释一下这几个名词是什么意思。
定时抓取
定时抓取非常好理解,就是到了某个固定的时间爬虫软件就会自动抓取数据。市面上有一些比价软件,背后就是运行着非常多的定时爬虫,每隔几分钟爬一下价格信息,以达到价格监控的目的。
IP 池
互联网上 90% 的流量都是爬虫贡献的,为了降低服务器的压力,互联网公司会有一些风控策略,里面就有一种是限制 IP 流量。比如说互联网公司后台检测到某个 IP 有大量的数据请求,超过了正常范围,就会暂时的封锁这个 IP,不返回相关数据。这时候爬虫软件就会自己维护一个 IP 池,用不同的 IP 发送请求,降低 IP 封锁的概率。
打码功能
这个功能就是内置了验证码识别器,可以实现机器打码 or 手动打码,也是绕过网站风控的一种方法。
四、总结
个人认为后羿采集器是一款非常优秀的数据采集软件。它提供的免费功能可以解决绝大部分编程小白的数据抓取需求。
如果有一些编程基础,可以明显的看出一些功能是对编程语言逻辑的封装,比如说流程图模式是对流程控制的封装,数据清洗功能是对字符串处理函数的封装。这些高阶功能扩展了后羿采集器的能力,也增大了学习难度。
我个人看来,如果是轻量的数据抓取需求,更倾向于使用 web scraper;需求比较复杂,后羿采集器是个不错的选择;如果涉及到定时抓取等高级需求,自己写爬虫代码反而更加可控。
总而言之,后羿采集器是一款优秀的数据采集软件,非常推荐大家学习和使用。
联系我
因为文章发在各大平台上,账号较多不能及时回复评论和私信,有问题可关注公众号 ——「卤蛋实验室」,(或 wx 搜索egglabs)关注上车防失联。
