PyTorch ------VGG卷积神经网络实现mnist手写体识别
-接上一篇AlexNet现实mnist手写识别
- 使用经典模型VGGNet模型实现相同的功能
- 先简单介绍一下,今天的主角VGGNet,曾获得2014年ImageNet亚军
- 原论文地址传送门
- 上图看看VGGNet系列模型的结构:
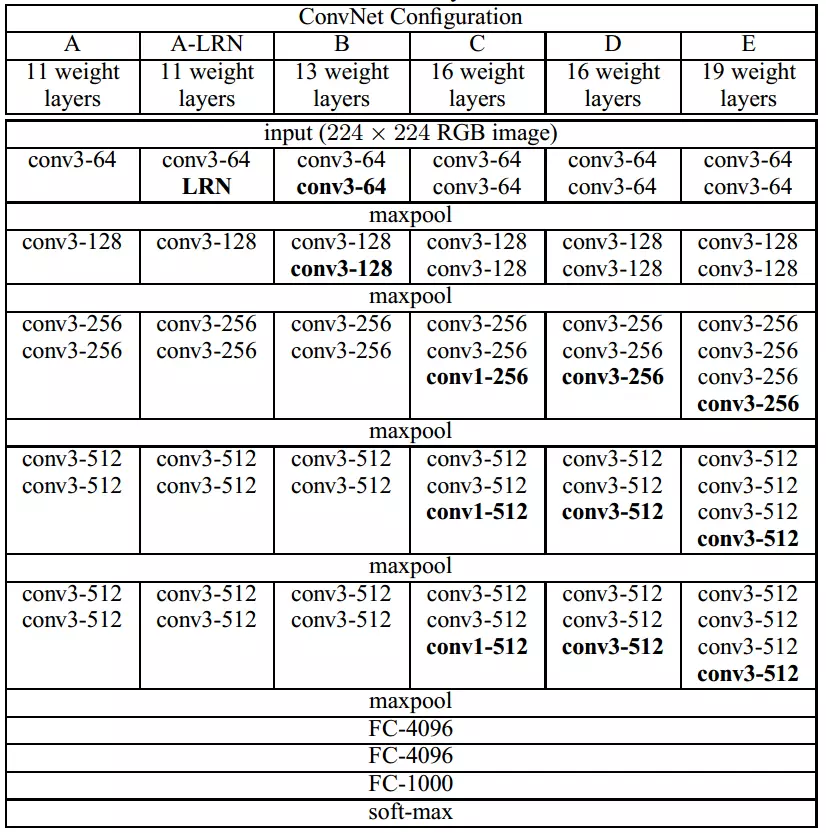
- 下面是参数个数比较

- 先看看VGGNet内部的比较
- A和A-LRN的比较,只有一个LRN的差异,在经过多次的训练比较发现,LRN增加了复杂度,损耗内存,存在的意义不是很大
- B与C相比较多使用了几个1X1的卷积层,在输入输出维度不变的情况下,增加非线性变换,提高网络的表达能力.
- C和D相比较还是C的特征提取会更好一些,虽然1X1的卷积很好很有效,但是相比较于3X3的,还是3X3的会更好一些
- 其他的几个相比较,模型越来越深
- 可训练参数的个数相差不大
VGG对于AlexNet的优势
- 通过重复使用简单的Block块来构建深度模型
- 使用了更小的卷积核
- 小池化核。AlexNet的3x3的池化核,VGG全部为2x2的池化核
- 模型深度更深,表达能力更强
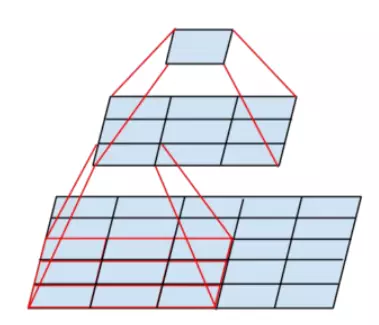
- 由于使用更小的卷积核来构建和构建更深的网络,由多个小的卷积核堆叠来增大accept field(3个33的卷积核的堆叠accept field 和 77的accept field 一样大小)
- 由于使用小的卷积核,降低了可训练参数个数,并增加了更多的非线性变化,提高了对特征的学习能力
- accept field 示意图:
下面是VGG11的代码:
import time
import torch
from torch import nn, optim
import torchvision
import numpy as np
import sys
import os
import torch.nn.functional as F
device = torch.device(“cuda” if torch.cuda.is_available() else “cpu”)
class FlattenLayer(torch.nn.Module):
def init(self):
super(FlattenLayer, self).init()
def forward(self, x): # x shape: (batch, , , …)
return x.view(x.shape[0], -1)
def vgg_block(num_convs,in_channels,out_channels):
blk = []
for i in range(num_convs):
if i == 0: 、blk.append(nn.Conv2d(in_channels=in_channels,out_channels=out_channels,kernel_size=3,padding=1))
else: blk.append(nn.Conv2d(out_channels,out_channels,kernel_size=3,padding=1))
blk.append(nn.ReLU())
blk.append(nn.MaxPool2d(kernel_size=2,stride=2))
return nn.Sequential(blk)
con_arch = ((1,1,64),(1,64,128),(2,128,256),(2,256,512),(2,512,512))
fc_features = 51277 #CW*H
fc_hidden_units = 4096 # 任意修改
def vgg(conv_arch,fc_features,fc_hidden_units = 4096):
net = nn.Sequential()
for i ,(num_convs,in_channels,out_channels)in enumerate(conv_arch):
net.add_module(“vgg_block” + str(i + 1),vgg_block(num_convs,in_channels,out_channels))
net.add_module(“fc”,nn.Sequential(FlattenLayer(),
nn.Linear(fc_features,fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units,fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units,10)
))
return net
small_conv_arch = [(1, 1, 64), (1, 64, 128), (2, 128, 256),(2, 256, 512), (2, 512, 512)]
net = vgg(small_conv_arch, fc_features, fc_hidden_units)
#输出模型结构
print(net)
X = torch.rand(1,1,224,224)
#模型每层的features map
for name ,blk in net.named_children():
X = blk(X)
print(name,“output shape :”,X.shape)
#下载数据 组装好训练数据 测试数据
def load_data_fashion_mnist(batch_size,resize = None,root = “./dataset/input/FashionMNIST2065”):
trans = []
if resize:
# 做数据增强 处理 将图片转化为 规定大小 数据内容不会丢失 等比例 处理
trans.append(torchvision.transforms.Resize(size=resize))
# 将 图片 类型 转化为Tensor类型
trans.append(torchvision.transforms.ToTensor())
# 将图片 增强方式 添加到Compose 类中处理
transform = torchvision.transforms.Compose(trans)
# 读取训练数据
mnist_train = torchvision.datasets.FashionMNIST(root=root,train=True,download=False,transform = transform)
# 读取 测试数据
mnist_test = torchvision.datasets.FashionMNIST(root = root,train=False,download=False,transform = transform)
# 数据加载器 在训练 测试阶段 使用多线程按批采样数据 默认不使用多线程 num_worker 表示设置的线程数量
train_iter = torch.utils.data.DataLoader(mnist_train,batch_size = batch_size,shuffle = True,num_workers = 2)
test_iter = torch.utils.data.DataLoader(mnist_test,batch_size = batch_size,shuffle = False,num_workers = 2)
return train_iter,test_iter
batch_size = 64
#如出现“out of memory”的报错信息,可减小batch_size或resize
train_iter,test_iter = load_data_fashion_mnist(batch_size,224)
#计算准确率
def evaluate_accuracy(data_iter,net,device = torch.device(“cpu”)):
#创建 正确率 和 总个数
acc_sum ,n = torch.tensor([0],dtype=torch.float32,device=device),0
for X,y in data_iter:
# 适配 设备
X,y = X.to(device),y.to(device)
# 设置 验证模式
net.eval()
with torch.no_grad(): #隔离开 不要计算在计算图内
y = y.long()#在这里将y转成long确实是不必要的。但是在计算交叉熵时,Pytorch强制要求y是long
acc_sum += torch.sum((torch.argmax(net(X),dim=1) == y)) # 累计预测正确的个数
n += y.shape[0] # 累计总的标签个数
return acc_sum.item() / n
def train_fit(net,train_iter,test_iter,batch_size,optimizer,device,num_epochs):
# 将读取的数据 拷贝到 指定的GPU上
net = net.to(device)
print("tainning on ",device)
# 设置 损失函数 交叉熵损失函数
loss = torch.nn.CrossEntropyLoss()
# 设置训练次数
for epoch in range(num_epochs):
train_l_sum,train_acc_sum,n,batch_count,start = 0.0,0.0,0,0,time.time()
# 读取批量数据 进行训练
for X,y in train_iter:
X = X.to(device)
y = y.to(device)
# 训练结果
y_hat = net(X)
# 计算 预测与标签分布 差异
l = loss(y_hat,y)
# 优化函数 梯度置为零
# 1、因为梯度可以累加
# 2、每批采样的梯度不同,只需记录本次样本的梯度
optimizer.zero_grad()
# 反向求导
l.backward()
# 更新权重参数
optimizer.step()
train_l_sum += l.cpu().item()
#train_acc_sum += (torch.argmax(y_hat,dim = 1) == y).cpu().item()
# 将张量元素值累计
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().cpu().item()
n += y.shape[0]
batch_count += 1
test_acc = evaluate_accuracy(test_iter,net)
print(‘epoch %d, loss %.4f, train acc %.3f, test acc %.3f, time %.1f sec’
% (epoch + 1, train_l_sum / batch_count, train_acc_sum / n, test_acc, time.time() - start))
lr , num_epochs = 0.01,5
optimizer = torch.optim.Adam(net.parameters(),lr = lr)
train_fit(net,train_iter,test_iter,batch_size,optimizer,device=device,num_epochs=num_epochs)