基于pytorch的FCN网络简单实现
参考知乎专栏实现FCN网络https://zhuanlan.zhihu.com/p/32506912
import torch
from torch import nn
import torch.nn.functional as f
import torchvision
import torchvision.transforms as tfs
from torch.utils.data import DataLoader
from torch.autograd import Variable
import torchvision.models as models
import numpy as np
import os
from PIL import Image
import matplotlib.pyplot as plt
from datetime import datetime
使用的数据集是VOC数据集,我们先读取数据
voc_root = "./data/VOC2012"
"""
读取图片
图片的名称在/ImageSets/Segmentation/train.txt ans val.txt里
如果传入参数train为True,则读取train.txt的内容,否则读取val.txt的内容
图片都在./data/VOC2012/JPEGImages文件夹下面,需要在train.txt读取的每一行后面加上.jpg
标签都在./data/VOC2012/SegmentationClass文件夹下面,需要在读取的每一行后面加上.png
最后返回记录图片路径的集合data和记录标签路径集合的label
"""
def read_images(root=voc_root, train=True):
txt_fname = root + '/ImageSets/Segmentation/' + ('train.txt' if train else 'val.txt')
with open(txt_fname, 'r') as f:
images = f.read().split()
data = [os.path.join(root, 'JPEGImages', i+'.jpg') for i in images]
label = [os.path.join(root, 'SegmentationClass', i+'.png') for i in images]
return data, label
先来看一下数据长什么样子
data, label = read_images(voc_root)
im = Image.open(data[0])
plt.subplot(2,2,1)
plt.imshow(im)
im = Image.open(label[0])
plt.subplot(2,2,2)
plt.imshow(im)
im = Image.open(data[1])
plt.subplot(2,2,3)
plt.imshow(im)
im = Image.open(label[1])
plt.subplot(2,2,4)
plt.imshow(im)
plt.show()

可以发现,图片的尺寸不固定,但是我们输入网络的尺寸必须是固定的,而且必须保证data和label相对应的位置相同,所以我们需要写一个函数随机剪裁图片以适应网络输入的大小,并且data和label剪裁的位置要相同。
"""
切割函数,默认都是从图片的左上角开始切割
切割后的图片宽为width,长为height
"""
def crop(data, label, height, width):
"""
data和lable都是Image对象
"""
box = (0, 0, width, height)
data = data.crop(box)
label = label.crop(box)
return data, label
im = Image.open(data[0])
la = Image.open(label[0])
plt.subplot(2,2,1), plt.imshow(im)
plt.subplot(2,2,2), plt.imshow(la)
im, la = crop(im, la, 224, 224)
plt.subplot(2,2,3), plt.imshow(im)
plt.subplot(2,2,4), plt.imshow(la)
plt.show()

下面我们需要将标签和像素点颜色之间建立映射关系
# VOC数据集中对应的标签
classes = ['background','aeroplane','bicycle','bird','boat',
'bottle','bus','car','cat','chair','cow','diningtable',
'dog','horse','motorbike','person','potted plant',
'sheep','sofa','train','tv/monitor']
# 各种标签所对应的颜色
colormap = [[0,0,0],[128,0,0],[0,128,0], [128,128,0], [0,0,128],
[128,0,128],[0,128,128],[128,128,128],[64,0,0],[192,0,0],
[64,128,0],[192,128,0],[64,0,128],[192,0,128],
[64,128,128],[192,128,128],[0,64,0],[128,64,0],
[0,192,0],[128,192,0],[0,64,128]]
因为图片是三通道的,并且每一个通道都有0-255一共256中取值,所以我们初始化一个256^3大小的数组就可以做映射了
cm2lbl = np.zeros(256**3)
# 枚举的时候i是下标,cm是一个三元组,分别标记了RGB值
for i, cm in enumerate(colormap):
cm2lbl[(cm[0]*256 + cm[1])*256 + cm[2]] = i
# 将标签按照RGB值填入对应类别的下标信息
def image2label(im):
data = np.array(im, dtype="int32")
idx = (data[:,:,0]*256 + data[:,:,1])*256 + data[:,:,2]
return np.array(cm2lbl[idx], dtype="int64")
im = Image.open(label[20]).convert("RGB")
label_im = image2label(im)
plt.imshow(im)
plt.show()
label_im[100:110, 200:210]
array([[3, 3, 3, 3, 3, 3, 3, 3, 3, 3],
[3, 3, 3, 3, 3, 3, 3, 3, 3, 3],
[3, 3, 3, 3, 3, 3, 3, 3, 3, 3],
[3, 3, 3, 3, 3, 3, 3, 3, 3, 3],
[3, 3, 3, 3, 3, 3, 3, 3, 3, 3],
[3, 3, 3, 3, 3, 3, 3, 3, 3, 3],
[3, 3, 3, 3, 3, 3, 3, 3, 3, 3],
[3, 3, 3, 3, 3, 3, 3, 3, 3, 3],
[3, 3, 3, 3, 3, 3, 3, 3, 3, 3],
[3, 3, 3, 3, 3, 3, 3, 3, 3, 3]], dtype=int64)
我们可以看到在截取出来的小区域内都是标记为3的像素点,通过标签列表,我们发现下标为3指示的是bird类
下面定义数据和标签的预处理函数
def image_transforms(data, label, height, width):
data, label = crop(data, label, height, width)
# 将数据转换成tensor,并且做标准化处理
im_tfs = tfs.Compose([
tfs.ToTensor(),
tfs.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
data = im_tfs(data)
label = image2label(label)
label = torch.from_numpy(label)
return data, label
img = Image.open(data[30]).convert("RGB")
lab = Image.open(label[30]).convert("RGB")
img, lab = image_transforms(img, lab, 224, 224)
print(img.shape)
print(lab.shape)
torch.Size([3, 224, 224])
torch.Size([224, 224])
定义VOCSegDataset类继承torch.utils.data.Dataset
class VOCSegDataset(torch.utils.data.Dataset):
# 构造函数
def __init__(self, train, height, width, transforms):
self.height = height
self.width = width
self.fnum = 0 # 用来记录被过滤的图片数
self.transforms = transforms
data_list, label_list = read_images(train=train)
self.data_list = self._filter(data_list)
self.label_list = self._filter(label_list)
if(train==True):
print("训练集:加载了 " + str(len(self.data_list)) + " 张图片和标签" + ",过滤了" + str(self.fnum) + "张图片")
else:
print("测试集:加载了 " + str(len(self.data_list)) + " 张图片和标签" + ",过滤了" + str(self.fnum) + "张图片")
# 过滤掉长小于height和宽小于width的图片
def _filter(self, images):
img = []
for im in images:
if (Image.open(im).size[1] >= self.height and
Image.open(im).size[0] >= self.width):
img.append(im)
else:
self.fnum = self.fnum+1
return img
# 重载getitem函数,使类可以迭代
def __getitem__(self, idx):
img = self.data_list[idx]
label = self.label_list[idx]
img = Image.open(img)
label = Image.open(label).convert('RGB')
img, label = self.transforms(img, label, self.height, self.width)
return img, label
def __len__(self):
return len(self.data_list)
以上就是整个VOC数据集的读取过程,对于数据读取过程也可以用于segnet网络
下面我们来实例化数据集
height = 224
width = 224
voc_train = VOCSegDataset(True, height, width, image_transforms)
voc_test = VOCSegDataset(False, height, width, image_transforms)
train_data = DataLoader(voc_train, batch_size=8, shuffle=True)
valid_data = DataLoader(voc_test, batch_size=8)
训练集:加载了 1456 张图片和标签,过滤了16张图片
测试集:加载了 1436 张图片和标签,过滤了26张图片
转置卷积输入输出图片尺寸的公式如下
n o u t = s t r i d e ∗ ( n i n − 1 ) + k e r n e l − 2 ∗ p a d d i n g n_{out} = stride*(n_{in}-1)+kernel-2*padding nout=stride∗(nin−1)+kernel−2∗padding
下面就构建一个基于resnet34的fcn网络
初始化转置卷积卷积核的函数
def bilinear_kernel(in_channels, out_channels, kernel_size):
factor = (kernel_size + 1) // 2
if kernel_size % 2 == 1:
center = factor - 1
else:
center = factor - 0.5
og = np.ogrid[:kernel_size, :kernel_size]
filt = (1 - abs(og[0] - center) / factor) * \
(1 - abs(og[1] - center) / factor)
weight = np.zeros((in_channels, out_channels, kernel_size, kernel_size),
dtype='float32')
weight[range(in_channels), range(out_channels), :, :] = filt
return torch.from_numpy(np.array(weight))
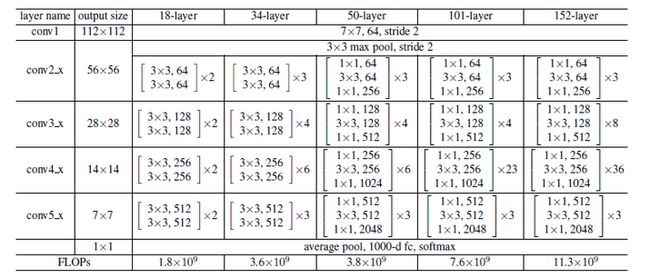
resnet的网络结构如下,我们使用的是resnet34
# 加载预训练的resnet34网络
model_root = "./model/resnet34-333f7ec4.pth"
pretrained_net = models.resnet34(pretrained=False)
pre = torch.load(model_root)
pretrained_net.load_state_dict(pre)
# 分类的总数
num_classes = len(classes)
下面就是fcn的网络结构,上采样的卷积核都使用bilinear_kernel进行初始化,一共三次上采样
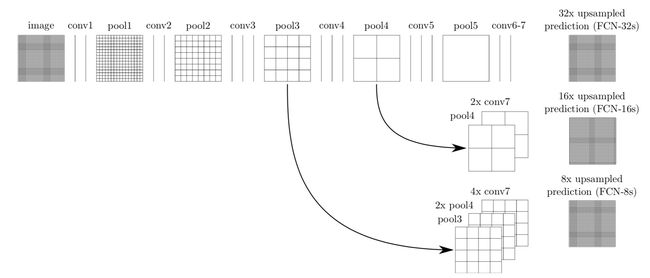
class fcn(nn.Module):
def __init__(self, num_classes):
super(fcn, self).__init__()
# 第一段,通道数为128,输出特征图尺寸为28*28
self.stage1 = nn.Sequential(*list(pretrained_net.children())[:-4])
# 第二段,通道数为256,输出特征图尺寸为14*14
self.stage2 = list(pretrained_net.children())[-4]
# 第三段,通道数为512,输出特征图尺寸为7*7
self.stage3 = list(pretrained_net.children())[-3]
# 三个1*1的卷积操作,各个通道信息融合
self.scores1 = nn.Conv2d(512, num_classes, 1)
self.scores2 = nn.Conv2d(256, num_classes, 1)
self.scores3 = nn.Conv2d(128, num_classes, 1)
# 将特征图尺寸放大八倍
self.upsample_8x = nn.ConvTranspose2d(num_classes, num_classes, kernel_size=16, stride=8, padding=4, bias=False)
self.upsample_8x.weight.data = bilinear_kernel(num_classes, num_classes, 16) # 使用双线性 kernel
# 这是放大了两倍,下同
self.upsample_4x = nn.ConvTranspose2d(num_classes, num_classes, kernel_size=4, stride=2, padding=1, bias=False)
self.upsample_4x.weight.data = bilinear_kernel(num_classes, num_classes, 4) # 使用双线性 kernel
self.upsample_2x = nn.ConvTranspose2d(num_classes, num_classes, kernel_size=4, stride=2, padding=1, bias=False)
self.upsample_2x.weight.data = bilinear_kernel(num_classes, num_classes, 4) # 使用双线性 kernel
def forward(self, x):
x = self.stage1(x)
s1 = x # 224/8 = 28
x = self.stage2(x)
s2 = x # 224/16 = 14
x = self.stage3(x)
s3 = x # 224/32 = 7
s3 = self.scores1(s3) # 将各通道信息融合
s3 = self.upsample_2x(s3) # 上采样
s2 = self.scores2(s2)
s2 = s2 + s3 # 14*14
s1 = self.scores3(s1)
s2 = self.upsample_4x(s2) # 上采样,变成28*28
s = s1 + s2 # 28*28
s = self.upsample_8x(s2) # 放大八倍,变成224*224
return s # 返回特征图
接着,我们来定义语义分割中会使用到的评价标准,这是整个笔记本中最难的部分
预测准确率,也称查准率
P r e c i s i o n = T P T P + F P Precision = \frac{TP} {TP+FP} Precision=TP+FPTP
召回率,也称查全率
R e c a l l = T P T P + F N Recall = \frac{TP} {TP+FN} Recall=TP+FNTP
F1
F 1 = 2 ∗ P r e c i s i o n + R e c a l l P r e c i s i o n + R e c a l l F1 = \frac{2*Precision+Recall} {Precision+Recall} F1=Precision+Recall2∗Precision+Recall
我们下面求的hist就是一个混淆矩阵
对角线的元素就是TP的数量
列上的元素和行上的元素减去对角线元素就是FN
混淆矩阵可以如下表示
| TP | FN |
|---|---|
| FN | TP |
# 计算混淆矩阵
def _fast_hist(label_true, label_pred, n_class):
# mask在和label_true相对应的索引的位置上填入true或者false
# label_true[mask]会把mask中索引为true的元素输出
mask = (label_true >= 0) & (label_true < n_class)
# np.bincount()会给出索引对应的元素个数
"""
hist是一个混淆矩阵
hist是一个二维数组,可以写成hist[label_true][label_pred]的形式
最后得到的这个数组的意义就是行下标表示的类别预测成列下标类别的数量
比如hist[0][1]就表示类别为1的像素点被预测成类别为0的数量
对角线上就是预测正确的像素点个数
n_class * label_true[mask].astype(int) + label_pred[mask]计算得到的是二维数组元素
变成一位数组元素的时候的地址取值(每个元素大小为1),返回的是一个numpy的list,然后
np.bincount就可以计算各中取值的个数
"""
hist = np.bincount(
n_class * label_true[mask].astype(int) +
label_pred[mask], minlength=n_class ** 2).reshape(n_class, n_class)
return hist
"""
label_trues 正确的标签值
label_preds 模型输出的标签值
n_class 数据集中的分类数
"""
def label_accuracy_score(label_trues, label_preds, n_class):
"""Returns accuracy score evaluation result.
- overall accuracy
- mean accuracy
- mean IU
- fwavacc
"""
hist = np.zeros((n_class, n_class))
# 一个batch里面可能有多个数据
# 通过迭代器将一个个数据进行计算
for lt, lp in zip(label_trues, label_preds):
# numpy.ndarray.flatten将numpy对象拉成1维
hist += _fast_hist(lt.flatten(), lp.flatten(), n_class)
# np.diag(a)假如a是一个二维矩阵,那么会输出矩阵的对角线元素
# np.sum()可以计算出所有元素的和。如果axis=1,则表示按行相加
"""
acc是准确率 = 预测正确的像素点个数/总的像素点个数
acc_cls是预测的每一类别的准确率(比如第0行是预测的类别为0的准确率),然后求平均
iu是召回率Recall,公式上面给出了
mean_iu就是对iu求了一个平均
freq是每一类被预测到的频率
fwavacc是频率乘以召回率,我也不知道这个指标代表什么
"""
acc = np.diag(hist).sum() / hist.sum()
acc_cls = np.diag(hist) / hist.sum(axis=1)
# nanmean会自动忽略nan的元素求平均
acc_cls = np.nanmean(acc_cls)
iu = np.diag(hist) / (hist.sum(axis=1) + hist.sum(axis=0) - np.diag(hist))
mean_iu = np.nanmean(iu)
freq = hist.sum(axis=1) / hist.sum()
fwavacc = (freq[freq > 0] * iu[freq > 0]).sum()
return acc, acc_cls, mean_iu, fwavacc
定义损失函数和优化策略,NLLLoss()和CrossEntropyLoss()是有相似的地方的,我们先来看一下CrossEntropyLoss()的公式
l o s s ( x , l a b e l ) = − w l a b e l ∗ log ( e x l a b e l ∑ j = 1 N e x j ) = − w l a b e l ∗ ( x l a b e l − log ∑ j = 1 N e x j ) loss(x, label) = -w_{label}*\log{(\frac{e^{x_{label}}} {\begin{matrix} \sum_{j=1}^N e^{x_j} \end{matrix}})} = -w_{label}*(x_{label}-\log{\begin{matrix} \sum_{j=1}^N e^{x_j} \end{matrix}}) loss(x,label)=−wlabel∗log(∑j=1Nexjexlabel)=−wlabel∗(xlabel−log∑j=1Nexj)
其中
s o f t m a x ( x i ) = e x i ∑ j e x j softmax(x_i) = \frac {e^{x_i}} {\begin{matrix} \sum_{j} e^{x_j} \end{matrix}} softmax(xi)=∑jexjexi
我们在下面训练的时候会发现,在模型输出之后,还会做一个f.log_softmax()就是在softmax的基础上再做一次log运算
CrossEntropyLoss()=log_softmax() + NLLLoss()
我觉的这里损失函数可以直接用CrossEntropyLoss(),然后直接模型输出的结果就能计算损失值loss
net = fcn(num_classes)
if torch.cuda.is_available():
net = net.cuda()
criterion = nn.NLLLoss()
basic_optim = torch.optim.SGD(net.parameters(), lr=1e-2, weight_decay=1e-4)
optimizer = basic_optim
下面就可以开始训练网络了
EPOCHES = 20
# 训练时的数据
train_loss = []
train_acc = []
train_acc_cls = []
train_mean_iu = []
train_fwavacc = []
# 验证时的数据
eval_loss = []
eval_acc = []
eval_acc_cls = []
eval_mean_iu = []
eval_fwavacc = []
for e in range(EPOCHES):
_train_loss = 0
_train_acc = 0
_train_acc_cls = 0
_train_mean_iu = 0
_train_fwavacc = 0
prev_time = datetime.now()
net = net.train()
for img_data, img_label in train_data:
if torch.cuda.is_available:
im = Variable(img_data).cuda()
label = Variable(img_label).cuda()
else:
im = Variable(img_data)
label = Variable(img_label)
# 前向传播
out = net(im)
out = f.log_softmax(out, dim=1)
loss = criterion(out, label)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
_train_loss += loss.item()
# label_pred输出的是21*224*224的向量,对于每一个点都有21个分类的概率
# 我们取概率值最大的那个下标作为模型预测的标签,然后计算各种评价指标
label_pred = out.max(dim=1)[1].data.cpu().numpy()
label_true = label.data.cpu().numpy()
for lbt, lbp in zip(label_true, label_pred):
acc, acc_cls, mean_iu, fwavacc = label_accuracy_score(lbt, lbp, num_classes)
_train_acc += acc
_train_acc_cls += acc_cls
_train_mean_iu += mean_iu
_train_fwavacc += fwavacc
# 记录当前轮的数据
train_loss.append(_train_loss/len(train_data))
train_acc.append(_train_acc/len(voc_train))
train_acc_cls.append(_train_acc_cls)
train_mean_iu.append(_train_mean_iu/len(voc_train))
train_fwavacc.append(_train_fwavacc)
net = net.eval()
_eval_loss = 0
_eval_acc = 0
_eval_acc_cls = 0
_eval_mean_iu = 0
_eval_fwavacc = 0
for img_data, img_label in valid_data:
if torch.cuda.is_available():
im = Variable(img_data).cuda()
label = Variable(img_label).cuda()
else:
im = Variable(img_data)
label = Variable(img_label)
# forward
out = net(im)
out = f.log_softmax(out, dim=1)
loss = criterion(out, label)
_eval_loss += loss.item()
label_pred = out.max(dim=1)[1].data.cpu().numpy()
label_true = label.data.cpu().numpy()
for lbt, lbp in zip(label_true, label_pred):
acc, acc_cls, mean_iu, fwavacc = label_accuracy_score(lbt, lbp, num_classes)
_eval_acc += acc
_eval_acc_cls += acc_cls
_eval_mean_iu += mean_iu
_eval_fwavacc += fwavacc
# 记录当前轮的数据
eval_loss.append(_eval_loss/len(valid_data))
eval_acc.append(_eval_acc/len(voc_test))
eval_acc_cls.append(_eval_acc_cls)
eval_mean_iu.append(_eval_mean_iu/len(voc_test))
eval_fwavacc.append(_eval_fwavacc)
# 打印当前轮训练的结果
cur_time = datetime.now()
h, remainder = divmod((cur_time - prev_time).seconds, 3600)
m, s = divmod(remainder, 60)
epoch_str = ('Epoch: {}, Train Loss: {:.5f}, Train Acc: {:.5f}, Train Mean IU: {:.5f}, \
Valid Loss: {:.5f}, Valid Acc: {:.5f}, Valid Mean IU: {:.5f} '.format(
e, _train_loss / len(train_data), _train_acc / len(voc_train), _train_mean_iu / len(voc_train),
_eval_loss / len(valid_data), _eval_acc / len(voc_test), _eval_mean_iu / len(voc_test)))
time_str = 'Time: {:.0f}:{:.0f}:{:.0f}'.format(h, m, s)
print(epoch_str + time_str)
F:\anaconda\lib\site-packages\ipykernel_launcher.py:21: RuntimeWarning: invalid value encountered in true_divide
F:\anaconda\lib\site-packages\ipykernel_launcher.py:23: RuntimeWarning: invalid value encountered in true_divide
Epoch: 0, Train Loss: 0.89404, Train Acc: 0.80017, Train Mean IU: 0.43920, Valid Loss: 0.59104, Valid Acc: 0.84774, Valid Mean IU: 0.50936 Time: 0:1:27
Epoch: 1, Train Loss: 0.51664, Train Acc: 0.86132, Train Mean IU: 0.54667, Valid Loss: 0.48522, Valid Acc: 0.86401, Valid Mean IU: 0.55262 Time: 0:1:27
Epoch: 2, Train Loss: 0.40172, Train Acc: 0.88439, Train Mean IU: 0.58591, Valid Loss: 0.44904, Valid Acc: 0.87099, Valid Mean IU: 0.56364 Time: 0:1:27
Epoch: 3, Train Loss: 0.32737, Train Acc: 0.90327, Train Mean IU: 0.61723, Valid Loss: 0.42495, Valid Acc: 0.87468, Valid Mean IU: 0.56595 Time: 0:1:27
Epoch: 4, Train Loss: 0.27786, Train Acc: 0.91646, Train Mean IU: 0.64725, Valid Loss: 0.41857, Valid Acc: 0.87723, Valid Mean IU: 0.57392 Time: 0:1:26
Epoch: 5, Train Loss: 0.24334, Train Acc: 0.92617, Train Mean IU: 0.67217, Valid Loss: 0.41588, Valid Acc: 0.87783, Valid Mean IU: 0.57639 Time: 0:1:26
Epoch: 6, Train Loss: 0.22022, Train Acc: 0.93164, Train Mean IU: 0.68780, Valid Loss: 0.40879, Valid Acc: 0.88109, Valid Mean IU: 0.57920 Time: 0:1:26
Epoch: 7, Train Loss: 0.19871, Train Acc: 0.93806, Train Mean IU: 0.70573, Valid Loss: 0.40266, Valid Acc: 0.88111, Valid Mean IU: 0.57825 Time: 0:1:26
Epoch: 8, Train Loss: 0.18534, Train Acc: 0.94148, Train Mean IU: 0.72089, Valid Loss: 0.40759, Valid Acc: 0.88186, Valid Mean IU: 0.58314 Time: 0:1:26
Epoch: 9, Train Loss: 0.17048, Train Acc: 0.94596, Train Mean IU: 0.73194, Valid Loss: 0.39852, Valid Acc: 0.88562, Valid Mean IU: 0.58331 Time: 0:1:26
Epoch: 10, Train Loss: 0.16377, Train Acc: 0.94723, Train Mean IU: 0.74323, Valid Loss: 0.40123, Valid Acc: 0.88615, Valid Mean IU: 0.58643 Time: 0:1:26
Epoch: 11, Train Loss: 0.15865, Train Acc: 0.94870, Train Mean IU: 0.74345, Valid Loss: 0.41540, Valid Acc: 0.88248, Valid Mean IU: 0.57651 Time: 0:1:26
Epoch: 12, Train Loss: 0.15183, Train Acc: 0.95047, Train Mean IU: 0.75301, Valid Loss: 0.40960, Valid Acc: 0.88507, Valid Mean IU: 0.58469 Time: 0:1:26
Epoch: 13, Train Loss: 0.14406, Train Acc: 0.95247, Train Mean IU: 0.75719, Valid Loss: 0.40888, Valid Acc: 0.88587, Valid Mean IU: 0.58250 Time: 0:1:26
Epoch: 14, Train Loss: 0.13584, Train Acc: 0.95521, Train Mean IU: 0.77002, Valid Loss: 0.41031, Valid Acc: 0.88634, Valid Mean IU: 0.58399 Time: 0:1:26
Epoch: 15, Train Loss: 0.14069, Train Acc: 0.95458, Train Mean IU: 0.76772, Valid Loss: 0.41782, Valid Acc: 0.88556, Valid Mean IU: 0.58485 Time: 0:1:26
Epoch: 16, Train Loss: 0.12429, Train Acc: 0.95829, Train Mean IU: 0.78024, Valid Loss: 0.41319, Valid Acc: 0.88821, Valid Mean IU: 0.59027 Time: 0:1:26
Epoch: 17, Train Loss: 0.12226, Train Acc: 0.95835, Train Mean IU: 0.78092, Valid Loss: 0.41565, Valid Acc: 0.88775, Valid Mean IU: 0.58749 Time: 0:1:26
Epoch: 18, Train Loss: 0.12359, Train Acc: 0.95825, Train Mean IU: 0.78601, Valid Loss: 0.41982, Valid Acc: 0.88620, Valid Mean IU: 0.57921 Time: 0:1:26
Epoch: 19, Train Loss: 0.11613, Train Acc: 0.96046, Train Mean IU: 0.78581, Valid Loss: 0.41853, Valid Acc: 0.88722, Valid Mean IU: 0.58796 Time: 0:1:26
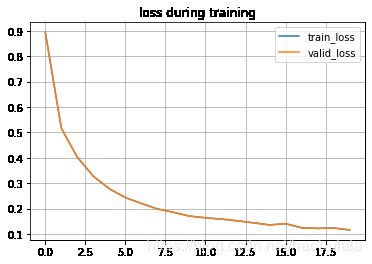
绘图
epoch = np.array(range(EPOCHES))
plt.plot(epoch, train_loss, label="train_loss")
plt.plot(epoch, train_loss, label="valid_loss")
plt.title("loss during training")
plt.legend()
plt.grid()
plt.show()
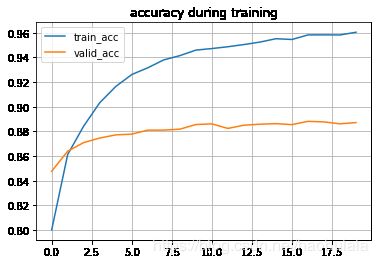
plt.plot(epoch, train_acc, label="train_acc")
plt.plot(epoch, eval_acc, label="valid_acc")
plt.title("accuracy during training")
plt.legend()
plt.grid()
plt.show()
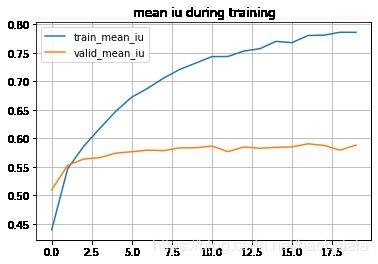
plt.plot(epoch, train_mean_iu, label="train_mean_iu")
plt.plot(epoch, eval_mean_iu, label="valid_mean_iu")
plt.title("mean iu during training")
plt.legend()
plt.grid()
plt.show()
下面我们定义函数来测试模型的性能
# 保存模型
PATH = "./model/fcn-resnet34.pth"
torch.save(net.state_dict(), PATH)
# 加载模型
# model.load_state_dict(torch.load(PATH))
cm = np.array(colormap).astype('uint8')
def predict(img, label): # 预测结果
img = Variable(img.unsqueeze(0)).cuda()
out = net(img)
pred = out.max(1)[1].squeeze().cpu().data.numpy()
# 将pred的分类值,转换成各个分类对应的RGB值
pred = cm[pred]
# 将numpy转换成PIL对象
pred = Image.fromarray(pred)
label = cm[label.numpy()]
return pred, label
size = 224
num_image = 10
_, figs = plt.subplots(num_image, 3, figsize=(12, 22))
for i in range(num_image):
img_data, img_label = voc_test[i]
pred, label = predict(img_data, img_label)
img_data = Image.open(voc_test.data_list[i])
img_label = Image.open(voc_test.label_list[i]).convert("RGB")
img_data, img_label = crop(img_data, img_label, size, size)
figs[i, 0].imshow(img_data) # 原始图片
figs[i, 0].axes.get_xaxis().set_visible(False) # 去掉x轴
figs[i, 0].axes.get_yaxis().set_visible(False) # 去掉y轴
figs[i, 1].imshow(img_label) # 标签
figs[i, 1].axes.get_xaxis().set_visible(False) # 去掉x轴
figs[i, 1].axes.get_yaxis().set_visible(False) # 去掉y轴
figs[i, 2].imshow(pred) # 模型输出结果
figs[i, 2].axes.get_xaxis().set_visible(False) # 去掉x轴
figs[i, 2].axes.get_yaxis().set_visible(False) # 去掉y轴
# 在最后一行图片下面添加标题
figs[num_image-1, 0].set_title("Image", y=-0.2)
figs[num_image-1, 1].set_title("Label", y=-0.2)
figs[num_image-1, 2].set_title("fcns", y=-0.2)
