《SpringCloud微服务实战》读书笔记
1、spring boot
1.1、spring boot多环境配置
application-{profile}.properties
通过spring.profiles.active=test来指定加载那个环境的配置文件
1.2、spring-boot-starter-actuator监控
1)原生端点
应用配置类:获取应用程序中加载的应用配置、环境配置、自动化配置报告等于springboot密切相关的应用配置类信息。
/autoconfig:获取应用的自动化配置报告
/beans:获取应用上下文中所有的bean
/configprops:获取应用配置信息
/env:环境变量相关 jvm
/mappings:Controller映射信息
度量指标类:用户监控的度量指标,比如内存、CPU
/metrics:当前应用的重要度量指标,包含内存信息、线程信息、垃圾回收信息等
/dump:应用暴露出来的线程信息
/trace:基本的HTTP跟踪信息
操作控制类:提供了对应用的关闭等操作
2、Eureka服务治理
1)服务注册:在服务治理框架中,通常都会构建一个注册中心,每个服务单元向注册中心登记自己提供的服务,将主机与端口号、版本号、通信协议等告知注册中心,注册中心按服务名分类组织服务清单。服务注册中心还需要以心跳的方式去监测清单中的服务是否可用,若不可用,需要从服务清单中剔除,达到排除故障服务的效果
2)服务发现:在服务治理框架下运作,服务间的调用不在通过指定具体的实例地址来实现,而是通过向服务名发起调用请求,所以服务调用方在调用服务提供方的接口时,并不知道具体的服务实例位置,因此,调用方需要向服务注册中心咨询服务,并获取所有服务的实例清单
3)服务治理机制
提供者:
服务注册:保存到双层结构Map中,第一层的key是服务名,第二次的key是具体服务的实例名
服务同步:服务提供者互相注册,当服务提供者发送注册请求到一个注册中心时,它会转发给集群中想关联的其他注册中心,从而实现注册中心的同步
服务续约:服务提供者根据心跳测试,判断服务是否存活,如果存活则续约,否则剔除
消费者:
获取服务:消费者启动时,会发送一个REST请求给服务注册中心,来获取服务清单。考虑到性能,Eureka会维护一份只读的服务清单给客户端,每30秒更新一次
服务调用:通过服务名调用。ribbon中默认轮询的方式进行调用以实现负载均衡
服务下线:服务端接收到下线请求后,将该服务的状态改为DOWN,并把下线时间传播出去
服务注册中心:
失效剔除:
自我保护:
3、ribbon客户端负载均衡
Spring cloud ribbon是一个基于HTTP和tcp的负载均衡客户端工具,基于Netflix Ribbon进行封装。
@loadbalance注解
3.1、RestTemplate注解
1)get请求:getForEntity()、getForObject()
2)post请求:postForEntity()、postForObject()
3)put请求
4)delete请求
3.2、负载均衡策略
RandomRule:随机策略
RoundRibbonRule:线性轮询策略
RetryRule:重试机制,内部实现是线性轮询策略
WeightResponseTimeRule:权重轮询策略
ZoneAvoidanceRule:区域选择策略
3.3、重试机制
Spring.cloud.loadblancer.retry.enable 是否开启重试,默认关闭
*.ribbon.ConnectTimeout 请求连接超时时间
*.ribbon.ReadTimeout 请求处理超时时间
*.ribbon.OkToRetryOnAllOperations 是否对所有操作都进行重试
*.ribbon.MaxAutoRetries 对当前实例的重试次数
*.ribbon.MaxAutoRetriesNextServer 切换实例的重试次数
4、Hystrix 服务容错保护?
当某个服务发生故障时,通过断路器的故障监控,想调用方返回错误信息,而不是长时间等待。这样就不会使得线程因为调用故障服务而长时间挂起,避免故障在分布式系统中蔓延。
5、feign client
Feign.hystrix.enable = true 开启hystrix服务
6、网关 zuul @enableZuulProxy
6.1、作用:
1)对于路由规则与服务实例维护
2)解决签名校验、登录校验等冗余的问题。可以在API网关服务上进行统一调用来对微服务入口进行前置过滤,以实现对接口的拦截和校验。校验通过则,路由到各自的服务上,否则返回错误信息
6.2、多重路由
/user-service/* 和/user-service/ext/*
1)基础的路由规则加载算法,是由linkedHashMap保存的。也就是说路由规则的保存是有顺序的。但是由于properties文件的配置内容不能保证有序性,所以应使用yml配置。
2)忽略表达式:zuul.ingore-patterns=xxx-service
3)路由前缀:zuul.prefix
4)本地跳转:forward
6.3、cookie与头信息
默认情况下,zuul会在请求路由是自动过滤掉HTTP请求中的一部分敏感信息,防止他们被传到下游服务器
Zuul.sensitiveheaders= //全局覆盖默认配置
Zuul.routes.
6.4、过滤器
1)过滤器必备的4个特性
过滤类型 String filterType() --->pre routing post(在routing和error之后调用) error
执行顺序 int filterOrder() --->数值越小优先级越高
执行条件 boolean shouldFilter()
具体操作 Objec run()
2)核心过滤器
- -3 ServletDetectionFilter 标记处理Servlet的类型
- -2 Servlet30WrapperFilter 包装httpServletRequest类型
- -1 FormBodyWrapperFilter 包装请求提
- 1 DebugFilter 标识调试标识
- 5 PreDecorationFilter 处理请求上下文供后续使用
- 10 RibbonRoutingFilter ServiceId请求转发
- 100 SimpleHostRoutingFilter url请求转发
- 500 SendForwardFilter forward转发
- 0 SendErrorFilter 处理有错误的请求
- 1000 SendResponseFilter 处理正常的请求
7、配置中心
7.1、执行流程:
1)应用启动时,根据bootstrap.yml配置的应用名{application}、环境名{profile}、分支名{label}向Config Server请求获取配置信息
2)Config Server根据自己维护的Git仓库和客户端传递的配置信息,定向去查找配置
3)通过git clone命令将找到的配置文件,克隆到Config Server文件系统中
4)Config Server创建Spring的applicationContext实例,并从config server中加载配置文件,将这些配置读取到客户端使用
5)客户获取的外部配置文件,优先级高于本地配置文件,所以重复的配置不会被加载。
// 通过git clone方式,即便git server不可用, 仍然可以根据缓存内容正常运行应用
- 0 SendErrorFilter 处理有错误的请求
- 1000 SendResponseFilter 处理正常的请求
- 10 RibbonRoutingFilter ServiceId请求转发
- 100 SimpleHostRoutingFilter url请求转发
- 500 SendForwardFilter forward转发
- -3 ServletDetectionFilter 标记处理Servlet的类型
- -2 Servlet30WrapperFilter 包装httpServletRequest类型
- -1 FormBodyWrapperFilter 包装请求提
- 1 DebugFilter 标识调试标识
- 5 PreDecorationFilter 处理请求上下文供后续使用
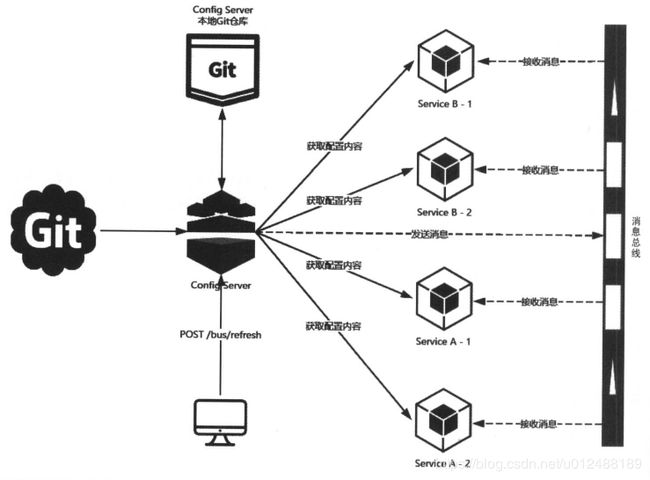
8、消息总线 spring cloud bus
8.1、rabbitMQ
1)客户端连接到消息队列,打开一个channel
2)客户端声明一个exchange,并设置相关属性
3)客户端声明一个queue,并设置相关属性
4)客户端使用route key,在exchange和queue间建立绑定关系
5)客户端投递到exchange
6)exchange根据消息的key和binding,进行路由,将消息传递到一个或多个queue
8.2、架构
9、服务跟踪
9.1、服务跟踪原理
1)为了实现跟踪请求,当请求发送到分布式系统的入口时,只需要服务跟踪框架为改请求创建唯一的TraceID跟踪标识,同时在系统内部流转时,框架始终保持传递这个跟踪标识,知道返回给请求放为止。
2)为了统计各单元的处理时间,当请求到达服务组件时,通过spanID来标记它的开始、具体过程以及结束。对于每个spanID,必须要有开始和结束两个时间戳,以及其他元数据,比如时间名称、请求信息等