MNIST数据集基于朴素贝叶斯分类器的手写识别
一、实验目的
熟悉和掌握贝叶斯分类器的概念、原理、算法实现。并利用朴素贝叶斯分类器对 MNIST 手写数字数据集进行分类,理解训练流程和分类原理。
二、实验原理
贝叶斯决策论(Bayesian decision theory)是概率框架下实施决策的基本方法。对分类任务来说,在所有相关概率都已知的理想情形下,贝叶斯决策论考虑如何基于这些概率和误判损失来选择最优的类别标记(选择后验概率最大的那一类)。不难发现,基于贝叶斯公式来估计后验概率 P ( w i ∣ X ) P(w_i|X) P(wi∣X)的主要困难在于类条件概率 P ( X ∣ w i ) P(X|w_i) P(X∣wi)是所有属性上的联合概率,难以从有限的训练样本直接估计而得。为避开这个障碍,朴素贝叶斯分类器(naive Bayes classifier)采用了“属性条件独立性假设”(attribute conditional independence assumption):对已知类别,假设所有属性相互独立。换言之,假设每个属性独立地对分类结果发生影响。然而,想要根据贝叶斯公式计算得到后验概率,首先我们需要知道先验概率和条件概率。在样本足够大的时候,我们可以通过对样本信息进行统计,来近似的计算先验概率和条件概率,从而得到类先验概率和类条件概率,进而对样本进行分类。
具体计算细节详见实验内容。
三、实验内容
3.1、读取MNIST数据集
3.1.0 MNIST数据集简介
MNIST是一个开源数据库,它来自美国国家标准与技术研究所(National Institute of Standards and Technology, NIST)。 其中一共包含了60000条训练集数据和10000条测试集数据。其中训练集由来自 250 个不同人手写的0-9数字构成,其中50%是高中学生,50% 来自人口普查局的工作人员;而测试集的手写数字数据也拥有同样的来源及比例。
3.1.1、下载MNIST数据集
从MNIST的官网上下载数据集,得到四个文件如下(分别为训练集图片,训练集标签,测试集图片,测试集标签):
train-images-idx3-ubyte.gz: training set images (9912422 bytes)
train-labels-idx1-ubyte.gz: training set labels (28881 bytes)
t10k-images-idx3-ubyte.gz: test set images (1648877 bytes)
t10k-labels-idx1-ubyte.gz: test set labels (4542 bytes)
解压后得到四个文件:
训练集图像:t10k-images.idx3-ubyte
训练集标签:t10k-labels.idx1-ubyte
测试集图像:train-images.idx3-ubyte
测试集标签:train-labels.idx1-ubyte
3.1.2、分析MNIST数据集的数据格式
下面是训练集文件的格式说明(测试集类似,这里就不再列举):
图片文件格式说明:
----------------------------------------
[字节位置] [类型] [值] [描述]
0000 32位整型 2051 幻数
0004 32位整型 60000 图片数
0008 32位整型 28 行数
0012 32位整型 28 列数
0016 无符号字节 ?? 像素
0017 无符号字节 ?? 像素
......
xxxx 无符号字节 ?? 像素
----------------------------------------
标签文件格式说明:
----------------------------------------
[字节位置] [类型] [值] [描述]
0000 32位整型 2049 幻数
0004 32位整型 60000 标签数
0008 无符号字节 ?? 标签
0009 无符号字节 ?? 标签
......
xxxx 无符号字节 ?? 标签
----------------------------------------
注:这里的整形指的都是无符号整型
上述的32位整形遵循MSB first,即高位字节在左边,如十进制8,二进制储存形式为1000。
幻数是一个固定值,它占据文件的前4个字节,实际上表示的是这个文件储存的是图片还是标签,没有具体用处,我们可以忽略它。
图片数与标签数占据文件4~7个字节的位置,在训练集中,它为60,000,表示这个文件有60,000个图片或标签,在测试集中,它为5,000。
行数和列数描述的是每张图片的大小,它们也是固定值,都为28。
每张图片有28*28=784个像素,所以从图片文件第16个字节位置开始,每隔784个字节为一张新图片,其中每个像素的像素值为0~255。
从标签文件的第8个字节位置开始,每个字节都对应着一张图片的数字,标签的值为0~9。
3.1.3、代码
先从文件中读出附加数据,然后再读出图片数据,并对图片数据进行预处理。
图片数据可以一次读取所有的图片,然后再对数组的view进行变换,这样要比一张一张的读取快的多。
def decode_idx3_ubyte(path):
'''
解析idx3-ubyte文件,即解析MNIST图像文件
'''
'''
也可不解压,直接打开.gz文件。path是.gz文件的路径
import gzip
with gzip.open(path, 'rb') as f:
'''
print('loading %s' % path)
with open(path, 'rb') as f:
# 前16位为附加数据,每4位为一个整数,分别为幻数,图片数量,每张图片像素行数,列数。
magic, num, rows, cols = unpack('>4I', f.read(16))
print('magic:%d num:%d rows:%d cols:%d' % (magic, num, rows, cols))
mnistImage = np.fromfile(f, dtype=np.uint8).reshape(num, rows, cols)
print('done')
return mnistImage
def decode_idx1_ubyte(path):
'''
解析idx1-ubyte文件,即解析MNIST标签文件
'''
print('loading %s' % path)
with open(path, 'rb') as f:
# 前8位为附加数据,每4位为一个整数,分别为幻数,标签数量。
magic, num = unpack('>2I', f.read(8))
print('magic:%d num:%d' % (magic, num))
mnistLabel = np.fromfile(f, dtype=np.uint8)
print('done')
return mnistLabel
def normalizeImage(image):
'''
将图像的像素值正规化为0.0 ~ 1.0
'''
res = image.astype(np.float32) / 255.0
return res
读取出来的MNIST训练集中的第一张图片如下

3.2、进行二值特征提取
3.2.1、特征提取方式
首先用 c o n f i g [ ′ s i d e _ l e n g t h ′ ] config['side\_length'] config[′side_length′]代表降维之后的图片的像素边长,那么原图片将被对应的分为 c o n f i g [ ′ s i d e _ l e n g t h ′ ] ∗ c o n f i g [ ′ s i d e _ l e n g t h ′ ] config['side\_length']*config['side\_length'] config[′side_length′]∗config[′side_length′]份,每一份的边长是 n u m ∗ n u m ( n u m = 28 / c o n f i g [ ′ s i d e _ l e n g t h ′ ] ) num*num(num = 28/config['side\_length']) num∗num(num=28/config[′side_length′])
对于原图片的每一份,计算这一份中的所有像素值的平均值。如果平均值大于设定的阙值 c o n f i g [ ′ b i n a r i z a t i o n _ l i m i t _ v a l u e ′ ] config['binarization\_limit\_value'] config[′binarization_limit_value′],则此份对应的特征值为1,否则为0。
3.2.2、代码
def oneImagesFeatureExtraction(image):
'''
对单张图片进行特征提取
'''
res = np.empty((config['side_length'], config['side_length']))
num = 28//config['side_length']
for i in range(0, config['side_length']):
for j in range(0, config['side_length']):
# tempMean = (image[2*i:2*(i+1),2*j:2*(j+1)] != 0).sum()/(2 * 2)
tempMean = image[num*i:num*(i+1), num*j:num*(j+1)].mean()
if tempMean > config['binarization_limit_value']:
res[i, j] = 1
else:
res[i, j] = 0
return res
def featureExtraction(images):
res = np.empty((images.shape[0], config['side_length'],
config['side_length']), dtype=np.float32)
for i in range(images.shape[0]):
res[i] = oneImagesFeatureExtraction(images[i])
return res
对MNIST训练集中的第一张图片进行特征值提取后显示如下:(此处为14*14)
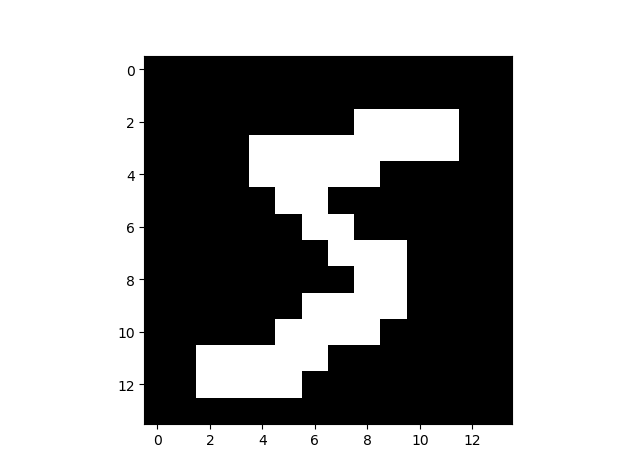
3.3、计算先验概率和类条件概率
3.3.1、计算方法
(1). 根据训练样本,计算先验概率
可由各类样本数和样本总数近似计算:
P ( w i ) ≈ N i / N i = 0 , 1 , 2 , . . . , 9 P(w_i) \approx N_i/N \quad i=0,1,2,...,9 P(wi)≈Ni/Ni=0,1,2,...,9
其中, N i N_i Ni为数字 i i i的样品数, N N N为样品总数
(2).根据训练样本,计算 P j ( w i ) P_j(w_i) Pj(wi),再计算类条件概率 P ( X ∣ w i ) P(X|w_i) P(X∣wi):
l e n = c o n f i g [ ′ s i d e l e n g t h ′ ] ∗ c o n f i g [ ′ s i d e l e n g t h ′ ] − 1 j = 0 , 1 , 2 , . . . , l e n P j ( w i ) = ( ∑ k = 0 , x ∈ w i N i x k j + 1 ) / ( N i + 2 ) len = config['side_length']*config['side_length']-1\\ j = 0,1,2,...,len\\ P_j(w_i)=(\sum_{k=0,x\in w_i}^{N_i}{x_{kj}}+1)/(N_i+2)\\ len=config[′sidelength′]∗config[′sidelength′]−1j=0,1,2,...,lenPj(wi)=(k=0,x∈wi∑Nixkj+1)/(Ni+2)
即在** x x x属于 w i w_i wi类的条件下, x x x的第 j j j个分量为1的概率估计值。**
由此知:
P ( x j = 1 ∣ X ∈ w i ) = P j ( w i ) P ( x j = 0 ∣ X ∈ w i ) = 1 − P j ( w i ) P(x_j=1|X\in w_i)=P_j(w_i)\\ P(x_j=0|X\in w_i)=1-P_j(w_i)\\ P(xj=1∣X∈wi)=Pj(wi)P(xj=0∣X∈wi)=1−Pj(wi)
3.3.2、代码
def bayesModelTrain(train_x, train_y):
'''
贝叶斯分类器模型训练
'''
# 计算先验概率
totalNum = train_x.shape[0]
classNumDic = Counter(train_y)
prioriP = np.array([classNumDic[i]/totalNum for i in range(10)])
# 计算类条件概率
oldShape = train_x.shape
train_x.resize((oldShape[0], oldShape[1]*oldShape[2]))
posteriorNum = np.empty((10, train_x.shape[1]))
posteriorP = np.empty((10, train_x.shape[1]))
for i in range(10):
posteriorNum[i] = train_x[np.where(train_y == i)].sum(axis=0)
# 拉普拉斯平滑
posteriorP[i] = (posteriorNum[i] + 1) / (classNumDic[i] + 2)
train_x.resize(oldShape)
return prioriP, posteriorP
3.4、计算后验概率,并进行分类
3.4.1、计算方法
(1).对于测试样本集中的每一个样本 X X X,先进行二值特征提取,然后求得样本 X X X的类条件概率为:
P ( X ∣ w i ) = P [ X = ( x 0 , x 1 , x 2 , . . . , x l e n ) ∣ X ∈ w i ] = ∏ j = 0 l e n P ( x j = a ∣ X ∈ w i ) a = 0 或 1 P(X|w_i)=P[X=(x_0,x_1,x_2,...,x_{len})|X \in w_i] \\ = \prod_{j=0}^{len}{P(x_j=a|X \in w_i)} \quad a=0或1 P(X∣wi)=P[X=(x0,x1,x2,...,xlen)∣X∈wi]=j=0∏lenP(xj=a∣X∈wi)a=0或1
(2).利用贝叶斯公式求后验概率:
P ( w i ∣ X ) = P ( w i ) P ( X ∣ w i ) P ( w 0 ) ∗ P ( X ∣ w 0 ) + P ( w 1 ) ∗ P ( X ∣ w 1 ) + . . . + P ( w 9 ) ∗ P ( X ∣ w 9 ) P(w_i|X)=\frac{P(w_i)P(X|w_i)} {P(w_0)*P(X|w_0)+P(w_1)*P(X|w_1)+...+P(w_9)*P(X|w_9)} P(wi∣X)=P(w0)∗P(X∣w0)+P(w1)∗P(X∣w1)+...+P(w9)∗P(X∣w9)P(wi)P(X∣wi)
在实际的应用中,因为我们只关心后验概率的大小关系,而不是他们的值。对于所有类别来说,他们的分母都是一样的,所以我们可以只看分子,此时有
P ( w i ∣ X ) ′ = P ( w i ) P ( X ∣ w i ) = P ( w i ) ∏ j = 0 l e n P ( x j = a ∣ X ∈ w i ) a = 0 或 1 P(w_i|X)' = P(w_i)P(X|w_i)\\ =P(w_i)\prod_{j=0}^{len}{P(x_j=a|X \in w_i)} \quad a=0或1\\ P(wi∣X)′=P(wi)P(X∣wi)=P(wi)j=0∏lenP(xj=a∣X∈wi)a=0或1
又因为小数的连乘,容易引起下溢,所以我们再次改写上式(取对数),得
P ( w i ∣ X ) ′ ′ = exp { P ( w i ) } + ∑ j = 0 l e n e x p { P ( x j = a ∣ X ∈ w i } } a = 0 或 1 P(w_i|X)'' = \exp\{P(w_i)\}+\sum_{j=0}^{len}{exp\{P(x_j=a|X \in w_i}\}\} \quad a=0或1\\ P(wi∣X)′′=exp{P(wi)}+j=0∑lenexp{P(xj=a∣X∈wi}}a=0或1
(3).后验概率的最大值的类别(0~9)就是测试数据手写数字 X X X的所属类别。
3.4.2、代码
def bayesClassifier(test_x, prioriP, posteriorP):
'''
使用贝叶斯分类器进行分类(极大似然估计)
'''
oldShape = test_x.shape
test_x.resize(oldShape[0]*oldShape[1])
classP = np.empty(10)
for j in range(10):
temp = sum([math.log(1-posteriorP[j][x]) if test_x[x] ==
0 else math.log(posteriorP[j][x]) for x in range(test_x.shape[0])])
classP[j] = np.array(math.log(prioriP[j]) + temp)
classP[j] = np.array(temp)
test_x.resize(oldShape)
return np.argmax(classP)
3.5、对训练好的模型进行评估
3.5.1、评估步骤
对所有的测试集的样本按照 3.4 3.4 3.4的步骤进行分类,分类完成之后统计正确率
3.5.2、代码
def modelEvaluation(test_x, test_y, prioriP, posteriorP):
'''
对贝叶斯分类器的模型进行评估
'''
bayesClassifierRes = np.empty(test_x.shape[0])
for i in range(test_x.shape[0]):
bayesClassifierRes[i] = bayesClassifier(test_x[i], prioriP, posteriorP)
return bayesClassifierRes, (bayesClassifierRes == test_y).sum() / test_y.shape[0]
四、实验完整代码和运行结果
4.1、代码如下:
# 引入需要的包
import numpy as np
from struct import unpack
import matplotlib.pyplot as plt
from PIL import Image
from collections import Counter
import math
# from tqdm import tqdm
# 配置文件
config = {
# 训练集文件
'train_images_idx3_ubyte_file_path': 'data/train-images.idx3-ubyte',
# 训练集标签文件
'train_labels_idx1_ubyte_file_path': 'data/train-labels.idx1-ubyte',
# 测试集文件
'test_images_idx3_ubyte_file_path': 'data/t10k-images.idx3-ubyte',
# 测试集标签文件
'test_labels_idx1_ubyte_file_path': 'data/t10k-labels.idx1-ubyte',
# 特征提取阙值
'binarization_limit_value': 0.14,
# 特征提取后的边长
'side_length': 14
}
def decode_idx3_ubyte(path):
'''
解析idx3-ubyte文件,即解析MNIST图像文件
'''
'''
也可不解压,直接打开.gz文件。path是.gz文件的路径
import gzip
with gzip.open(path, 'rb') as f:
'''
print('loading %s' % path)
with open(path, 'rb') as f:
# 前16位为附加数据,每4位为一个整数,分别为幻数,图片数量,每张图片像素行数,列数。
magic, num, rows, cols = unpack('>4I', f.read(16))
print('magic:%d num:%d rows:%d cols:%d' % (magic, num, rows, cols))
mnistImage = np.fromfile(f, dtype=np.uint8).reshape(num, rows, cols)
print('done')
return mnistImage
def decode_idx1_ubyte(path):
'''
解析idx1-ubyte文件,即解析MNIST标签文件
'''
print('loading %s' % path)
with open(path, 'rb') as f:
# 前8位为附加数据,每4位为一个整数,分别为幻数,标签数量。
magic, num = unpack('>2I', f.read(8))
print('magic:%d num:%d' % (magic, num))
mnistLabel = np.fromfile(f, dtype=np.uint8)
print('done')
return mnistLabel
def normalizeImage(image):
'''
将图像的像素值正规化为0.0 ~ 1.0
'''
res = image.astype(np.float32) / 255.0
return res
def load_train_images(path=config['train_images_idx3_ubyte_file_path']):
return normalizeImage(decode_idx3_ubyte(path))
def load_train_labels(path=config['train_labels_idx1_ubyte_file_path']):
return decode_idx1_ubyte(path)
def load_test_images(path=config['test_images_idx3_ubyte_file_path']):
return normalizeImage(decode_idx3_ubyte(path))
def load_test_labels(path=config['test_labels_idx1_ubyte_file_path']):
return decode_idx1_ubyte(path)
def oneImagesFeatureExtraction(image):
'''
对单张图片进行特征提取
'''
res = np.empty((config['side_length'], config['side_length']))
num = 28//config['side_length']
for i in range(0, config['side_length']):
for j in range(0, config['side_length']):
# tempMean = (image[2*i:2*(i+1),2*j:2*(j+1)] != 0).sum()/(2 * 2)
tempMean = image[num*i:num*(i+1), num*j:num*(j+1)].mean()
if tempMean > config['binarization_limit_value']:
res[i, j] = 1
else:
res[i, j] = 0
return res
def featureExtraction(images):
res = np.empty((images.shape[0], config['side_length'],
config['side_length']), dtype=np.float32)
for i in range(images.shape[0]):
res[i] = oneImagesFeatureExtraction(images[i])
return res
def bayesModelTrain(train_x, train_y):
'''
贝叶斯分类器模型训练
'''
# 计算先验概率
totalNum = train_x.shape[0]
classNumDic = Counter(train_y)
prioriP = np.array([classNumDic[i]/totalNum for i in range(10)])
# 计算类条件概率
oldShape = train_x.shape
train_x.resize((oldShape[0], oldShape[1]*oldShape[2]))
posteriorNum = np.empty((10, train_x.shape[1]))
posteriorP = np.empty((10, train_x.shape[1]))
for i in range(10):
posteriorNum[i] = train_x[np.where(train_y == i)].sum(axis=0)
# 拉普拉斯平滑
posteriorP[i] = (posteriorNum[i] + 1) / (classNumDic[i] + 2)
train_x.resize(oldShape)
return prioriP, posteriorP
def bayesClassifier(test_x, prioriP, posteriorP):
'''
使用贝叶斯分类器进行分类(极大似然估计)
'''
oldShape = test_x.shape
test_x.resize(oldShape[0]*oldShape[1])
classP = np.empty(10)
for j in range(10):
temp = sum([math.log(1-posteriorP[j][x]) if test_x[x] ==
0 else math.log(posteriorP[j][x]) for x in range(test_x.shape[0])])
# 很奇怪,在降维成7*7的时候,注释掉下面这一句正确率反而更高
classP[j] = np.array(math.log(prioriP[j]) + temp)
classP[j] = np.array(temp)
test_x.resize(oldShape)
return np.argmax(classP)
def modelEvaluation(test_x, test_y, prioriP, posteriorP):
'''
对贝叶斯分类器的模型进行评估
'''
bayesClassifierRes = np.empty(test_x.shape[0])
for i in range(test_x.shape[0]):
bayesClassifierRes[i] = bayesClassifier(test_x[i], prioriP, posteriorP)
return bayesClassifierRes, (bayesClassifierRes == test_y).sum() / test_y.shape[0]
if __name__ == '__main__':
print('loading MNIST Data')
train_images = load_train_images()
train_labels = load_train_labels()
test_images = load_test_images()
test_labels = load_test_labels()
print('loading done')
nowMnistLabel = train_labels[0].copy()
nowMnistImage = train_images[0].copy()
# print(nowMnistLabel)
# plt.imshow(nowMnistImage, cmap='gray')
# plt.pause(0.001)
# plt.show()
print('feature extraction start')
train_images_feature = featureExtraction(train_images)
print('feature extraction done')
nowMnistLabel = train_labels[0].copy()
nowMnistImage = train_images_feature[0].copy()
# print(nowMnistLabel)
# plt.imshow(nowMnistImage, cmap='gray')
# plt.pause(0.001)
# plt.show()
print('bayes model train start')
prioriP, posteriorP = bayesModelTrain(train_images_feature, train_labels)
print('bayes model train done')
# print(prioriP)
# print(posteriorP)
print('bayes model evaluation start')
test_images_feature = featureExtraction(test_images)
res, val = modelEvaluation(
test_images_feature, test_labels, prioriP, posteriorP)
print('贝叶斯分类器的准确度为%.2f %%' % (val*100))
print('bayes model evaluation done')
4.2、运行结果
loading MNIST Data
loading data/train-images.idx3-ubyte
magic:2051 num:60000 rows:28 cols:28
done
loading data/train-labels.idx1-ubyte
magic:2049 num:60000
done
loading data/t10k-images.idx3-ubyte
magic:2051 num:10000 rows:28 cols:28
done
loading data/t10k-labels.idx1-ubyte
magic:2049 num:10000
done
loading done
feature extraction start
feature extraction done
bayes model train start
bayes model train done
bayes model evaluation start
贝叶斯分类器的准确度为83.58 %
bayes model evaluation done