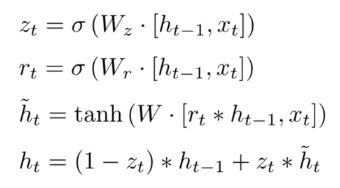pytorch nn.LSTM()参数详解
2020.5.25 补充:
h0~hn:上一刻时间产生的中间值与当前时刻的输入共同产生的状态
c0~cn:开关,决定每个神经元的隐藏状态值是否会影响下一时刻神经元的处理
lstm = nn.LSTM(3, 3)
inputs = [torch.randn(1, 3) for _ in range(5)]
inputs = torch.cat(inputs).view(len(inputs), 1, -1)
hidden = (torch.randn(1, 1, 3), torch.randn(1, 1, 3)) # clean out hidden state
out, (h,c) = lstm(inputs, hidden)
print('out2',out)
print('h:',h)
print('c:',c)
out2 tensor([[[-0.1748, 0.1860, -0.1011]],
[[ 0.0326, 0.1376, -0.0833]],
[[ 0.2356, 0.0536, 0.0080]],
[[-0.2130, -0.0126, 0.0746]],
[[-0.1240, 0.1858, -0.0489]]], grad_fn=)
h: tensor([[[-0.1240, 0.1858, -0.0489]]], grad_fn=)
c: tensor([[[-0.2078, 0.3629, -0.0833]]], grad_fn=)
这里可以看到out2的最后一个值与h的值是一样的,这是因为out2表示的是训练的这个序列所有时刻的隐藏状态值,而(h,c)表示的是最后一个时间刻的状态
输入数据格式:
input(seq_len, batch, input_size)
h0(num_layers * num_directions, batch, hidden_size)
c0(num_layers * num_directions, batch, hidden_size)
输出数据格式:
output(seq_len, batch, hidden_size * num_directions)
hn(num_layers * num_directions, batch, hidden_size)
cn(num_layers * num_directions, batch, hidden_size)
代码示例:
import torch
import torch.nn as nn
from torch.autograd import Variable
#构建网络模型---输入矩阵特征数input_size、输出矩阵特征数hidden_size、层数num_layers
inputs = torch.randn(5,3,10) ->(seq_len,batch_size,input_size)
rnn = nn.LSTM(10,20,2) -> (input_size,hidden_size,num_layers)
h0 = torch.randn(2,3,20) ->(num_layers* 1,batch_size,hidden_size)
c0 = torch.randn(2,3,20) ->(num_layers*1,batch_size,hidden_size)
num_directions=1 因为是单向LSTM
'''
Outputs: output, (h_n, c_n)
'''
output,(hn,cn) = rnn(inputs,(h0,c0))
batch_first: 输入输出的第一维是否为 batch_size,默认值 False。因为 Torch 中,人们习惯使用Torch中带有的dataset,dataloader向神经网络模型连续输入数据,这里面就有一个 batch_size 的参数,表示一次输入多少个数据。 在 LSTM 模型中,输入数据必须是一批数据,为了区分LSTM中的批量数据和dataloader中的批量数据是否相同意义,LSTM 模型就通过这个参数的设定来区分。 如果是相同意义的,就设置为True,如果不同意义的,设置为False。 torch.LSTM 中 batch_size 维度默认是放在第二维度,故此参数设置可以将 batch_size 放在第一维度。如:input 默认是(4,1,5),中间的 1 是 batch_size,指定batch_first=True后就是(1,4,5)。所以,如果你的输入数据是二维数据的话,就应该将 batch_first 设置为True;
inputs = torch.randn(5,3,10) :seq_len=5,batch_size=3,input_size=10
我的理解:有3个句子,每个句子5个单词,每个单词用10维的向量表示;而句子的长度是不一样的,所以seq_len可长可短,这也是LSTM可以解决长短序列的特殊之处。只有seq_len这一参数是可变的。
关于hn和cn一些参数的详解看这里
而在遇到文本长度不一致的情况下,将数据输入到模型前的特征工程会将同一个batch内的文本进行padding使其长度对齐。但是对齐的数据在单向LSTM甚至双向LSTM的时候有一个问题,LSTM会处理很多无意义的填充字符,这样会对模型有一定的偏差,这时候就需要用到函数torch.nn.utils.rnn.pack_padded_sequence()以及torch.nn.utils.rnn.pad_packed_sequence()
详情解释看这里
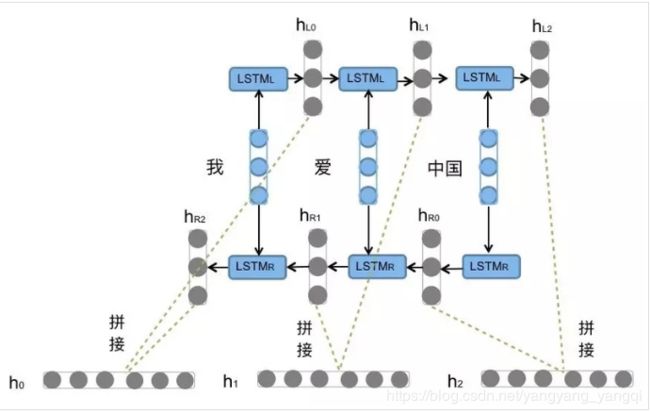
BiLSTM
BILSTM是双向LSTM;将前向的LSTM与后向的LSTM结合成LSTM。视图举例如下:

LSTM结构推导:
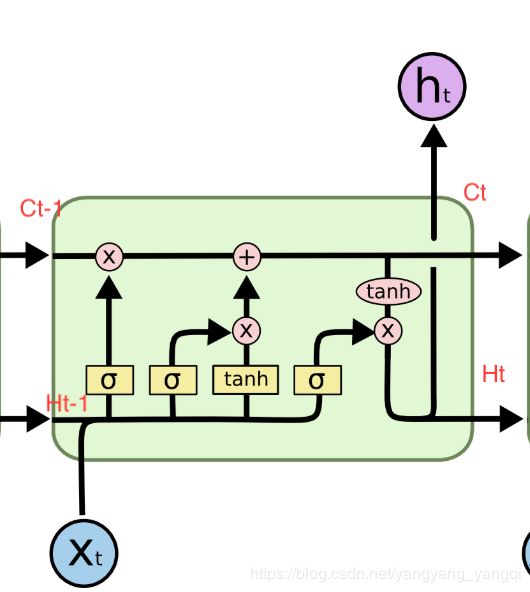
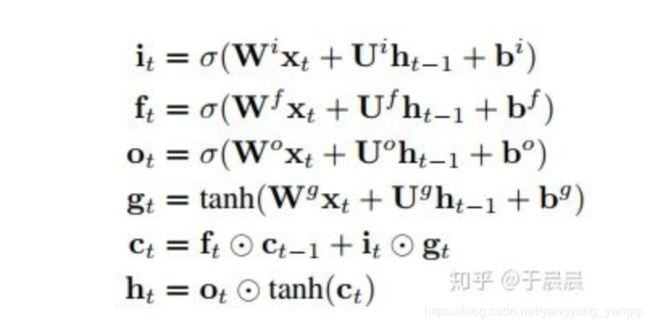
更详细公式推导https://blog.csdn.net/songhk0209/article/details/71134698
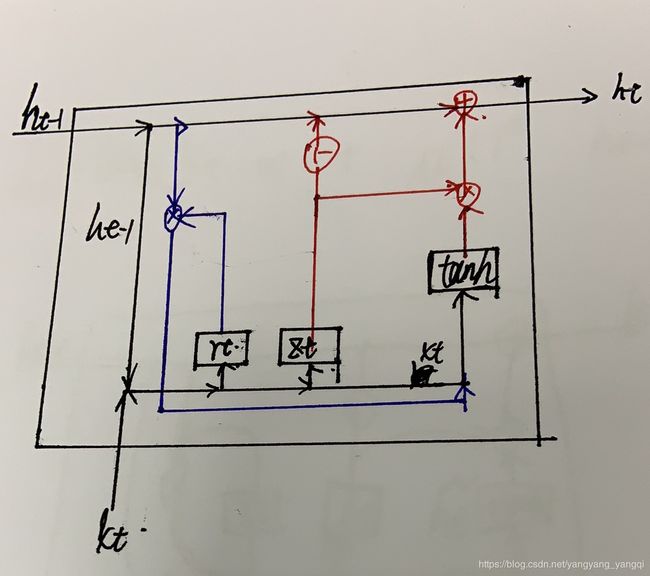
GRU公式推导:(网上的图看着有点费劲,就自己画了个数据流图)