字符串匹配算法(多模式串)
本文是数据结构与算法之美的学习笔记
上一篇了解了单模式串匹配算法,现在来学习多模式串匹配算法,首先需要了解Trie树
Trie树的概念
Trie树也叫字典树或者前缀树,它是一个树形的结构。是一种专门用来处理字符串匹配的数据结构,用来解决在一组字符串中快速查找某个字符串的问题。
谷歌,百度这种搜索引擎,输入框的关键词提示功能,底层原理就是使用了这种数据结构
Tire树是一种有序树,用于保存关联数组,一个结点的所有的子孙都有共同的前缀。Trie的本质就是利用字符串的公共前缀,把重复的前缀合并在一起。
比如现在有6个字符串:how,hi,her,hello,sou,see。Trie树中是怎么构造的呢如下:
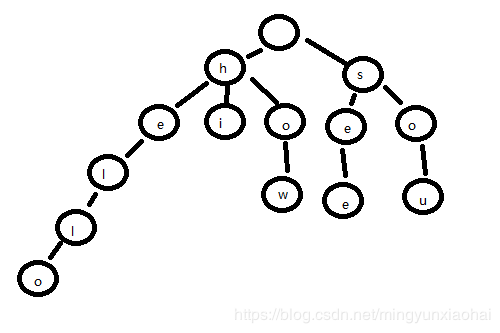
从图中可以看出Trie的几个特性
- 根节点是空的,除了根结点之外,每个结点都只包含一个字符
- 从根结点到某一个结点的路径上的字符连起来,就是该结点对应的字符串
- 每个结点对应的子结点包含的字符串不同
从Trie树中查找一个字符串的时候,先把字符串分割成字符。比如“how”,分割成h,o,w。然后从Trie树的跟结点开始一个一个的匹配直到匹配到最后一个字符为止。
Trie的存储
从上面的图中可以看到,Trie树是一个多叉树,在二叉树中我们左右两个子结点可以通过两个指针来存储,多叉树该怎么存储呢?
我么可以借助散列表的思想,通过一个下标与字符串一一映射的数组,来存储结点的指针。如下图:

假如字符串中只有26个小写字母,我们使用一个长度为26的数组来存储a到z这26个字符,如果某个字符的子节点不存在,就在对应下标位置存储null
我们可以通过字符串的ASCII码减去"a"的ASCII码来快速找到匹配的子结点的指针。比如d的ASCII码减去a的ASCII码是3,子节点d的位置就存储在数组下标为3的位置。
一个Trie的形成一般包含两步
- 把一个字符串集合构造成Trie树
- 在Trie树中查找一个字符串
public class Trie {
private TrieNode root = new TrieNode('/'); // 存储无意义字符
// 往 Trie 树中插入一个字符串
public void insert(char[] text) {
TrieNode p = root;
for (int i = 0; i < text.length; ++i) {
int index = text[i] - 'a';
if (p.children[index] == null) {
TrieNode newNode = new TrieNode(text[i]);
p.children[index] = newNode;
}
p = p.children[index];
}
p.isEndingChar = true;
}
// 在 Trie 树中查找一个字符串
public boolean find(char[] pattern) {
TrieNode p = root;
for (int i = 0; i < pattern.length; ++i) {
int index = pattern[i] - 'a';
if (p.children[index] == null) {
return false; // 不存在 pattern
}
p = p.children[index];
}
if (p.isEndingChar == false) return false; // 不能完全匹配,只是前缀
else return true; // 找到 pattern
}
public class TrieNode {
public char data;
public TrieNode[] children = new TrieNode[26];
public boolean isEndingChar = false;
public TrieNode(char data) {
this.data = data;
}
}
}
优点:
每次查询的时候,如果要查询的字符串长度是k,那么我们只需要对比大约k个节点就能完成查询操作,跟原本的那组字符串的长度和没有任何关系,效率非常高。
缺点:
由于它强制要求每个节点都有一个数组,并且数组等长,这在实际的开发中会造成大多数数组中都是null,非常浪费空间。
上面使用单数组来存储Trie树是典型的通过空间换时间的策略。效率高但是非常浪费空间。
除了使用数组实现还可以使用list,hash表,双数组等下面这个文章写的清楚https://segmentfault.com/a/1190000008877595?utm_source=tag-newest
Trie树不适合用来做动态集合数据的查找,因为这个工作使用散列表或者红黑树更适合。它主要用于查找前缀匹配的字符串。比如搜索引擎中的关键词提示,IDE中的代码补全等。
AC自动机
很多论坛网站都会有敏感词过滤的功能,用来过滤掉一些淫秽,反动,谩骂等内容,这些功能实现的最基本的原理就是字符串匹配算法。通过维护一个敏感词的字典,当用户输入一段文字内容之后,通过字符串匹配算法来查找用户输入的这段文字。
因为有很多的敏感词,所以这时候需要用到多模式匹配算法
- 单模式串匹配算法是在一个主串中查找一个模式串
- 多模式串匹配算法是在一个主串中查找多个模式串
上一篇文章字符串匹配算法(单模式串)中的BF算法,RK算法,BM算法,KMP算法都是但莫使串匹配算法,Trie树是多模式串匹配算法。
- 对敏感词进行预处理,构建成一个Trie树,这个预处理只需要处理一次,如果敏感词字典更新了,只需动态更新一下Trie树就行
- 匹配:当用户输入一段文本内容之后,我们把用户输入的内容作为主串,从第一个字符开始在Trie树中匹配。当匹配到Trie树的叶子节点或者中途遇到不匹配的字符的时候,我们将主串的开始匹配的位置后移一位,从下一个字符开始匹配。
这种处理方法跟 上一篇文章字符串匹配算法(单模式串)中的BF算法很像。上一篇文章中的KMP算法优化了BF算法,让匹配失败的时候尽可能的多往后移动几位从而提高匹配效率。这里也可以根据KMP算法的思想,给Trie树有化,这就是AC自动机
AC自动机的构建包含两个操作:
- 多个模式串构建成Trie树
- 在Trie树上构建失败指针(类似KMP算法中的next数组)
Tire的构建文章最开始已经说了,怎么构建失败指针呢?
构造失败指针的过程就是:假设这个节点上的字母为c,沿着它父亲的失败指针走,直到走到一个节点,它儿子中也有字母c的节点,然后把当前节点的失败指针指向那个字母也为c的儿子,如果走到root也没找到,就把失败指针指向root如下图:
使用4个模式串ce,bc,bcd,abcd构建一个AC自动机,如果这个字符是一个模式串的结尾就给它一个标记,如下图标记为黄色。

- root根节点先入队,根节点的子节点的失败指针都指向root,图中a,b,b都指向root,同时a,b,c入队。
- a出队,找a的子节点b的失败指针,首先a的失败指针指向root,有个节点为b的子节点,所以a的子节点b的失败指针指向root的子节点b,然后a的子节点b入队。
- root的子节点b出队,找这个b的子节点c的失败指针,首先b的失败指针指向root,root有一个子节点为c,所以b的子节点c就指向这个root的子节点c,然后c入队。
- root的子节点c出队,找这个c的子节点e的失败指针,首先c的失败指针指向root,root没有一个为e的子节点,所以e的失败指针直接指向root。
- a的子节点b出队,找他的子节点c的失败指针,首先b的失败指针指向root的子节点b,而这个b的子节点为c,所以前面的c的失败指针就指向这个c。
- 依次类推。
代码:
public void buildFailurePointer() {
Queue<AcNode> queue = new LinkedList<>();
root.fail = null;
queue.add(root);
while (!queue.isEmpty()) {
AcNode p = queue.remove();
for (int i = 0; i < 26; ++i) {
AcNode pc = p.children[i];
if (pc == null) continue;
if (p == root) {
pc.fail = root;
} else {
AcNode q = p.fail;
while (q != null) {
AcNode qc = q.children[pc.data - 'a'];
if (qc != null) {
pc.fail = qc;
break;
}
q = q.fail;
}
if (q == null) {
pc.fail = root;
}
}
queue.add(pc);
}
}
}
至此AC自动机就构建完成了,如何在AC自动机上匹配主串呢?
比如主串是abbcdef
主串从i=0开始,AC自动机的指针p==root开始,
- 对于i=0,1也就是a,b,指针p走到最左侧的节点b,b的子节点c跟主串的下一个位置也就是i=2不一样,因为b的失败指针指向root的子节点b,所以跳到root的子节点b开始匹配。
- 匹配到c,因为这个c是黄的,所以匹配到的结果+1,并把这个c标记为已找出。然后继续匹配到d,d也是黄的,所以结果继续+1。
3.继续匹配e,d的失败指针指向root,从root开始匹配没有继续匹配f,也没有完成匹配。
代码:
public void match(char[] text) { // text 是主串
int n = text.length;
AcNode p = root;
for (int i = 0; i < n; ++i) {
int idx = text[i] - 'a';
while (p.children[idx] == null && p != root) {
p = p.fail; // 失败指针发挥作用的地方
}
p = p.children[idx];
if (p == null) p = root; // 如果没有匹配的,从 root 开始重新匹配
AcNode tmp = p;
while (tmp != root) { // 打印出可以匹配的模式串
if (tmp.isEndingChar == true) {
int pos = i-tmp.length+1;
System.out.println(" 匹配起始下标 " + pos + "; 长度 " + tmp.length);
}
tmp = tmp.fail;
}
}
}
game over