【图文详细 】Hive中DDL如何创建表呢?
创建表
1.语法结构:

详情请参见:
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualD
DL-CreateTable
2、 建表语句相关解释
CREATE TABLE:创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用 户可以用 IF NOT EXISTS 选项来忽略这个异常。
EXTERNAL 关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的 路径(LOCATION), 如果不存在,则会自动创建该目录。Hive 创建内部表时,会将数据 移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置 做任何改变。
在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删 除数据。(经典面试问题)
外部表和内部表的选择:
1、 如果数据已经存储在 HDFS 上了,然后需要使用 Hive 去进行分析,并且该份数据还 有可能要使用其他的计算引擎做计算之用,请使用外部表
2、 如果一份数据仅仅只是使用 Hive 做统计分析,那么可以使用内部表
不管使用内部表和外部表,表的数据存储路径都是可以通过 location 指定的!!!!!! 推荐方式:
1、 创建内部表的时候,最好别指定 location,就存储在默认的仓库路径
2、 如果要指定外部路径,那么请创建该表为外部表
PARTITIONED BY 在 Hive Select 查询中一般会扫描整个表内容,会消耗很多时间做没必要 的工作。有时候只需要扫描表中关心的一部分数据,因此建表时引入 partition 概念。个表可以拥有一个或者多个分区,每个分区以文件夹的形式单独存在表文件夹的目录下, 分区是以字段的形式在表结构中存在,通过 desc table 命令可以查看到字段存在,但是 该字段不存放实际的数据内容,仅仅是分区的表示。
分区建表分为 2 种:
一种是单分区,也就是说在表文件夹目录下只有一级文件夹目录
一种是多分区,表文件夹下出现多文件夹嵌套模式
LIKE:允许用户复制现有的表结构,但是不复制数据。 示例:create table tableA like tableB(创建一张 tableA 空表复制 tableB 的结构)
COMMENT:可以为表与字段增加描述
ROW FORMAT
DELIMITED [FIELDS TERMINATED BY char]
[COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char]
[LINES TERMINATED BY char]
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)] 用户在建表的时候可以自定义SerDe或者使用自带的SerDe。如果没有指定ROW FORMAT 或者 ROW FORMAT DELIMITED,将会使用自带的 SerDe。在建表的时候,用户还需要为 表指定列,用户在指定表的列的同时也会指定自定义的 SerDe,Hive 通过 SerDe 确定表 的具体的列的数据。
STORED AS TEXTFILE | SEQUENCEFILE | RCFILE 如果文件数据是纯文本,可以使用 STORED AS TEXTFILE,默认也是 textFile 格式,可以通 过执行命令 set hive.default.fileformat,进行查看,如果数据需要压缩,使用 STORED AS SEQUENCEFILE。

CLUSTERED BY
对于每一个表(table)或者分区,Hive 可以进一步组织成桶,也就是说桶是更为细 粒度的数据范围划分。Hive 也是针对某一列进行桶的组织。Hive 采用对列值哈希,然后 除以桶的个数求余的方式决定该条记录存放在哪个桶当中。
把表(或者分区)组织成桶(Bucket)有两个理由:
(1)获得更高的查询处理效率。桶为表加上了额外的结构,Hive 在处理有些查询 时能利用这个结构。具体而言,连接两个在(包含连接列的)相同列上划分了桶的表, 可以使用 Map 端连接(Map Join)高效的实现。比如 JOIN 操作。对于 JOIN 操作两个表 有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同列值的桶进行 JOIN 操作就可以,可以大大较少 JOIN 的数据量。
(2)使取样(Sampling)更高效。在处理大规模数据集时,在开发和修改查询的 阶段,如果能在数据集的一小部分数据上试运行查询,会带来很多方便。
LOCATION:指定数据文件存放的 HDFS 目录,不管内部表还是外表,都可以指定。不指 定就在默认的仓库路径。
最佳实践:
如果创建内部表请不要指定 location 如果创建表时要指定 location,请创建外部表。
3、 Hive 建表示例

执行命令查看表结构:hive> desc formatted page_view;

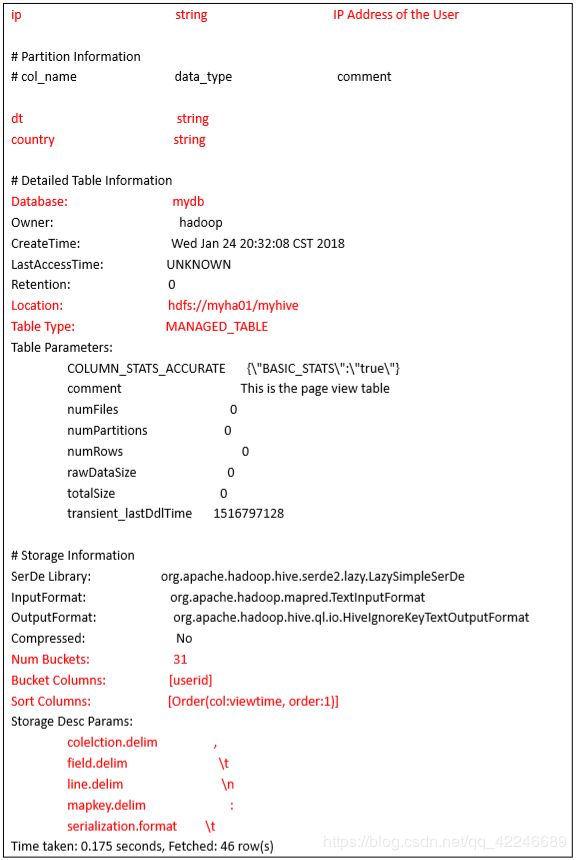
Hive 使用一个 Inputformat 对象将输入流分割成记录;使用一个 Outputformat 对象将记录格 式化为输出流,使用序列化/反序列化器 SerDe 做记录的解析(记录和列的转换) 。 它们的默认值分别是:
Inputformat:org.apache.hadoop.mapred.TextInputFormat Outputformat:org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat SerDe:org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
4、 具体实例
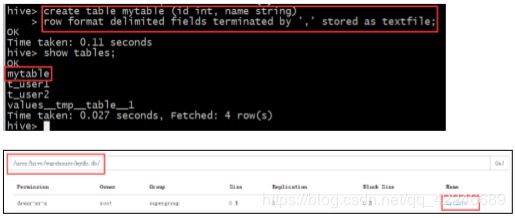
a、 创建内部表
create table mytable (id int, name string)
row format delimited fields terminated by ',' stored as textfile;
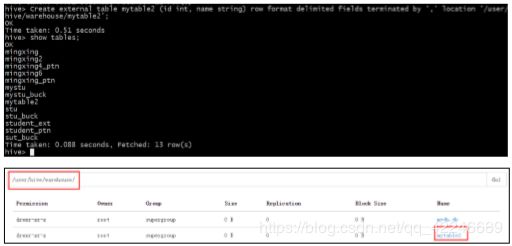
b、 创建外部表
create external table mytable2 (id int, name string) row format delimited fields terminated by ',' location '/user/hive/warehouse/mytable2';
c、 创建分区表
create table mytable3(id int, name string) partitioned by(sex string)
row format delimited fields terminated by ',' stored as textfile;

插入数据 插入男分区数据:load data local inpath '/root/hivedata/mingxing.txt' overwrite into table mytable3 partition(sex='boy'); 插入女分区数据:load data local inpath '/root/hivedata/mingxing.txt' overwrite into table mytable3 partition(sex='girl');
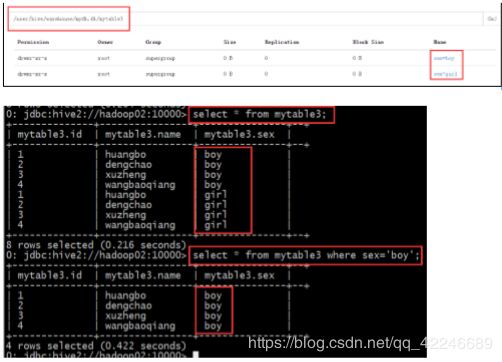
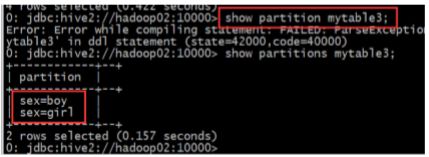
查询表分区: show partitions mytable3
d、 创建分桶表
create table stu_buck(Sno int,Sname string,Sex string,Sage int,Sdept string) clustered by(Sno) sorted by(Sno DESC) into 4 buckets row format delimited fields terminated by ',';

e、 使用 like 关键字拷贝表
// 不管老表是内部表还是外部表,new_table 都是内部表
create table new_table like mytable;
// 不管老表是内部表还是外部表,如果加 external 关键字,new_table 都是外部表
create external table if not exists new_table like mytable;