对话系统 | (1) 任务导向型对话系统 -- 对话管理模型研究最新进展
原文链接
作者丨戴音培、虞晖华、蒋溢轩、唐呈光、李永彬、孙健
单位丨阿里巴巴-达摩院-小蜜Conversational AI团队,康奈尔大学
1. 对话管理模型背景
从人工智能研究的初期开始,人们就致力于开发高度智能化的人机对话系统。艾伦·图灵(Alan Turing)在 1950 年提出图灵测试 [1],认为如果人类无法区分和他对话交谈的是机器还是人类,那么就可以说机器通过了图灵测试,拥有高度的智能。
第一代对话系统主要是基于规则的对话系统,例如 1966 年 MIT 开发的 ELIZA 系统 [2] 是一个利用模版匹配方法的心理医疗聊天机器人,再如 1970 年代开始流行的基于流程图的对话系统,采用有限状态自动机模型建模对话流中的状态转移。它们的优点是内部逻辑透明,易于分析调试,但是高度依赖专家的人工干预,灵活性和可拓展性很差。
随着大数据技术的兴起,出现了基于统计学方法的数据驱动的第二代对话系统(以下简称统计对话系统)。在这个阶段,增强(强化)学习也开始被广泛研究运用,其中最具代表性的是剑桥大学 Steve Young 教授于 2005 年提出的基于部分可见马尔可夫决策过程(Partially Observable Markov Decision Process , POMDP)的统计对话系统 [3]。该系统在鲁棒性上显著地优于基于规则的对话系统,它通过对观测到的语音识别结果进行贝叶斯推断,维护每轮对话状态,再根据对话状态进行对话策略的选择,从而生成自然语言回复。
POMDP-based 对话系统采用了增强学习的框架,通过不断和用户模拟器或者真实用户进行交互试错,得到奖励得分来优化对话策略。统计对话系统是一个模块化系统,它避免了对专家的高度依赖,但是缺点是模型难以维护,可拓展性也比较受限。
近些年,伴随着深度学习在图像、语音及文本领域的重大突破,出现了以运用深度学习为主要方法的第三代对话系统,该系统依然延续了统计对话系统的框架,但各个模块都采用了神经网络模型。
由于神经网络模型表征能力强,语言分类(理解)或生成的能力大幅提高,因此一个重要的变化趋势是自然语言理解的模型从之前的产生(生成)式模型(如贝叶斯网络)演变成为深度鉴别(判别)式模型(如 CNN、DNN、RNN)[5],对话状态的获取不再是利用贝叶斯后验判决得到,而是直接计算最大条件概率。在对话策略的优化上大家也开始采用深度增强(强化)学习模型 [6]。
另一方面,由于端到端序列到序列技术在机器翻译任务上的成功,使得设计端到端对话系统成为可能,Facebook 研究者提出了基于记忆网络的任务对话系统 [4],为研究第三代对话系统中的端到端任务导向型对话系统提出了新的方向。总的来说,第三代对话系统效果优于第二代系统,但是需要大量带标注数据才能进行有效训练,因此提升模型的跨领域的迁移拓展能力成为热门的研究方向。
常见的对话系统可分为三类:聊天型,任务导向型和问答型。聊天型对话的目标是要产生有趣且富有信息量的自然回复使得人机对话可以持续进行下去 [7]。问答型对话多指一问一答,用户提出一个问题,系统通过对问题进行解析和知识库查找以返回正确答案 [8]。任务导向型对话(以下简称任务型对话)则是指由任务驱动的多轮对话,机器需要通过理解、主动询问、澄清等方式来确定用户的目标,调用相应的 API 查询后,返回正确结果,完成用户需求。
通常,任务型对话可以被理解为一个序列决策过程,机器需要在对话过程中,通过理解用户语句更新维护内部的对话状态,再根据当前的对话状态选择下一步的最优动作(例如确认需求,询问限制条件,提供结果等等),从而完成任务。
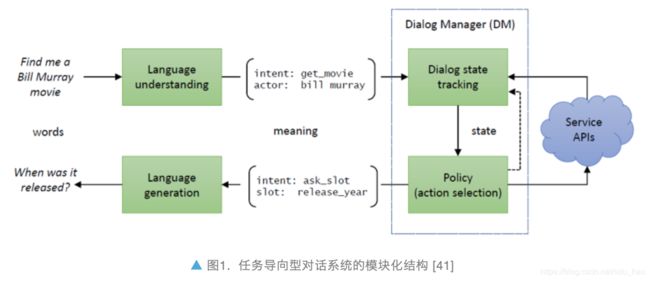
任务型对话系统从结构上可分成两类,一类是 pipeline 系统,采用模块化结构 [5](如图 1),一般包括四个关键模块:
- 自然语言理解(Natural Language Understanding, NLU)
对用户的文本输入进行识别解析,得到槽值和意图等计算机可理解的语义标签。 - 对话状态跟踪(Dialog State Tracking, DST)
根据对话历史,维护当前对话状态,对话状态是对整个对话历史的累积语义表示,一般就是槽值对(slot-value pairs)。 - 对话策略(Dialogue Policy)
根据当前对话状态输出下一步系统动作。一般对话状态跟踪模块和对话策略模块统称为对话管理模块(Dialogue manager, DM)。 - 自然语言生成(Natural Language Generation, NLG)
将系统动作转换成自然语言输出。
这种模块化的系统结构的可解释性强,易于落地,大部分业界的实用性任务型对话系统都采用的此结构。但是其缺点是不够灵活,各个模块之间相对独立,难以联合调优,适应变化的应用场景。并且由于模块之间的误差会层层累积,单一模块的升级也可能需要整个系统一起调整。
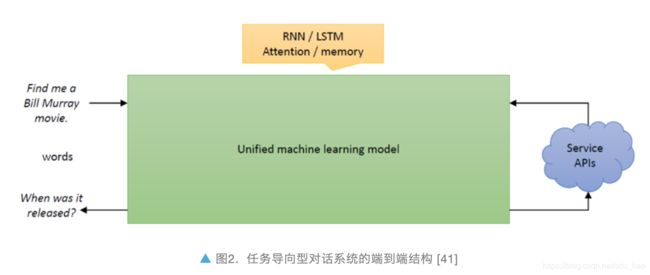
任务型对话系统的另一种实现是端到端系统,也是近年来学界比较热门的方向 [9][10][11](如图 2),这类结构希望训练一个从用户端自然语言输入到机器端自然语言输出的整体映射关系,具有灵活性强、可拓展性高的特点,减少了设计过程中的人工成本,打破了传统模块之间的隔离。然而,端到端模型对数据的数量和质量要求很高,并且对于填槽、API 调用等过程的建模不够明确,现阶段业界应用效果有限,仍处在探索中。
随着用户对产品体验的要求逐渐提高,实际对话场景更加复杂,对话管理模块也需要更多的改进和创新。传统的对话管理模型通常是建立在一个明确的话术体系内(即先查找再问询最后结束),一般会预定义好系统动作空间、用户意图空间和对话本体,但是实际中用户的行为变化难测,系统的应答能力十分有限,这就会导致传统对话系统可拓性差的问题(难以处理预定义之外的情况)。
另外,在很多的真实业界场景,存在大量的冷启动问题,缺少足量的标注对话数据,数据的清洗标注成本代价高昂。而在模型训练上,基于深度增强(强化)学习的对话管理模型一般都需要大量的数据,大部分论文的实验都表明,训练好一个对话模型通常需要几百个完整的对话 session,这样低下的训练效率阻碍了实际中对话系统的快速开发和迭代。
综上,针对传统对话管理模型的诸多局限,近几年学界和业界的研究者们都开始将焦点放在如何加强对话管理模型的实用性上,具体来说有三大问题:
- 可拓展性差
- 标注数据少
- 训练效率低
我们将按照这三个方向,为大家介绍近期最新的研究成果。
2. 对话管理模型研究前沿介绍
2.1 对话管理模型痛点一:可拓展性差
如前文所述,对话管理器由两部分组成:对话状态跟踪器(DST)和对话策略(dialog policy)。
传统的 DST 研究中,最具代表的是剑桥大学的学者们在 2017 年提出的神经信度跟踪模型(neural belief tracker, NBT)[12],利用神经网络来解决单领域复杂对话的对话状态跟踪问题。NBT 通过表征学习(representation learning)来编码上轮系统动作、本轮用户语句和候选槽值对,在高维空间中计算语义的相似性,从而检测出本轮用户提到的槽值。因此 NBT 可以不依赖于人工构建语义词典,只需借助槽值对的词向量表示就能识别出训练集未见但语义上相似的槽值,实现槽值的可拓展。
后续地,剑桥学者们对 NBT 进一步改进 [13] [44],将输入的槽值对改成领域-槽-值三元组,每轮识别的结果采用模型学习而非人工规则的方法进行累积,所有数据采用同一个模型训练,从而实现不同领域间的知识共享,模型的总参数也不随领域数目的增加而增加。
在传统的 Dialogue Policy 研究领域中,最具代表性的是剑桥学者们 [6] [14] 提出的基于 ACER 方法的策略优化。通过结合 Experience replay 技巧,作者分别尝试了 trust region actor-critic 模型和 episodic natural actor-critic 模型,验证了 AC 系列的深度增强(强化)学习算法在样本利用效率、算法收敛性和对话成功率上都达到了当时最好的表现。
然而传统的对话管理模型在可拓展性方面仍需改进,具体在三个方面:1)如何处理变化的用户意图,2)如何变化的槽位和槽值,3)如何处理变化的系统动作。
变化的用户意图
在实际应用场景中,时常会出现由于用户意图未被考虑到,使得对话系统给出不合理回答的情况。如图 3 所示的例子,用户的“confirm”意图未被考虑,这时就需要加入新的话术来帮助系统处理这样的情况。

一旦出现训练集未见的新用户意图时,传统模型由于输出的是表示旧意图类别的固定 one-hot 向量,若要包含新的意图类别,向量就需要进行改变,对应的新模型也需要进行完全的重训练,这种情况会降低模型的可维护性和可拓展性。
论文 [15] 提出了一种“老师-学生”的学习框架来缓解这一问题,他们将旧模型和针对新用户意图的逻辑规则作为“老师”,新模型作为“学生”,构成一个“老师-学生”训练架构。
该架构使用了知识蒸馏技术,具体做法是:对于旧的意图集合,旧模型的概率输出直接指导训练新模型;对于新增的意图,对应的逻辑规则作为新的标注数据来训练新模型。这样就使得在新模型不再需要与环境进行新的交互重新训练了。论文在 DSTC2 数据集上进行实验,首先选择故意去掉 confirm 这个意图,然后再将它作为新意图加入对话本体中,依次验证新模型是否具有很好的适应能力。
图 4 是实验结果,论文新模型(即 Extended System)、直接在包含所有意图的数据训练的模型(即 Contrast System)和旧模型进行比较,实验证明新模型对新意图的识别正确率在不同噪声情况下都不错的扩展识别新意图的能力。

当然这种架构仍然需要对系统进行一定的训练,[16] 提出一种语义相似性匹配的模型 CDSSM 能够在不依赖于标注数据以及模型重新训练的前提下,解决用户意图拓展的问题。
CDSSM 先利用训练集数据中用户意图的自然描述直接学习出一个意图向量(intent embedding)的编码器,将任意意图的描述嵌入到一个高维语义空间中,这样在测试时模型可以直接根据新意图的自然描述生成对应的意图向量,进而再做意图识别。
在后面的内容我们可以看到,有很多提高可拓展性的模型均采用了类似的思想,将标签从模型的输出端移到输入端,利用神经网络对标签(标签命名本身或者标签的自然描述)进行语义编码得到某种语义向量再进行语义相似性的匹配。
[43] 则给出了另外一种思路,它通过人机协同的方式,将人工客服的角色引入到系统线上运行的阶段来解决训练集未见的用户意图的问题。模型利用一个额外的神经判决器根据当前模型提取出来的对话状态向量来判断是否请求人工,如果请求则将当前对话分发给线上人工客服来回答,如果不请求则由模型自身进行预测。
由于通过数据学习出的判决器有能力对当前对话是否包含新意图作一定的判断,同时人工的回复默认是正确的,这种人机协同的方式十分巧妙地解决了线上测试出现未见用户行为的问题,并可以保持比较高对话准确率。
变化的槽位和槽值
在多领域或复杂领域的对话状态跟踪问题中,如何处理槽位与槽值的变化一直是一个难题。对于有的槽位而言,槽值可能是不可枚举的(这里的不可枚举指的是槽值没有限制,或可取值过多),例如,时间、地点和人名,甚至槽值集合是动态变化的,例如航班、电影院上映的电影。在传统的对话状态跟踪问题中,通常默认槽位和槽值的集合固定不变,这样就大大降低了系统的可拓展性。
针对槽值不可枚举的问题,谷歌研究者 [17] 提出了一个候选集(candidate set)的思路。对每个槽位,都维护一个有总量上限的候选集,它包含了对话截止目前最多个可能的槽值,并赋于每个槽值一个分数以表示用户在当前对话中对该槽值的偏好程度。
系统先利用双向 RNN 模型找出本轮用户语句包含的中某个槽位的槽值,再将它和候选集中已有的槽值进行重新打分排序,这样每轮的 DST 就只需在一个有限的槽值集合上进行判决,从而解决不可枚举槽值的跟踪问题。针对未见槽值的跟踪问题,一般可以采用序列标注的模型 [18],或者选择神经信度跟踪器 [12] 这样的语义相似匹配模型。
以上是槽值不固定的情况,如果对话本体中槽位也变化呢?论文 [19] 采用了槽位描述编码器(slot description encoder),对任何槽(已见的、未见的)的自然语言描述进行编码,得到表示该槽的语义向量,和用户语句一起作为输入送入 Bi-LSTM 模型中,采用序列标注的方式输出识别到的槽值,见图 5。

该论文做了一个可接受的假设,即任何槽的自然语言描述是很容易得到的,因此设计了一个在多个领域具有普适性的概念标注器(Concept Tagger)结构,槽描述编码器的实现是简单的词向量之和。实验表明,该模型能迅速适应新的槽位,相较于传统方法,该方法的可拓展性有很大的提升。
随着近几年序列到序列技术的发展,直接利用端到端神经网络模型将 DST 的结果作为一个序列生成出来也是一个很热门的方向,常见的技巧如注意力机制(attention mechanism)、拷贝机制(copy mechanism)均可以用来提高生成效果。
在著名的多领域对话 MultiWOZ 数据集上,来自港科大的 Pascale Fung 教授团队利用了拷贝网络,显著提高了不可枚举槽的识别精度 [20]。他们提出的 TRADE 模型如图 6 所示,每次检测槽值时,模型会将领域和槽位的不同结合进行语义编码作为 RNN 解码器的初始位置输入,解码器通过拷贝网络,直接将对应的槽值生成出来。

通过生成的方式,无论是不可枚举的槽值,还是变化的槽位的槽值,都能使用同一个模型完成,这可以做到领域间槽值信息的共享,也大大地提高了模型的泛化能力。
最近一个明显的趋势是将多领域 DST 看作一个机器阅读理解的任务,将 TRADE 这种生成式模型改进成鉴别(判别)式模型 [45] [47]。不可枚举槽的追踪利用类似 SQuAD 的机器阅读理解任务 [46],从对话历史和提问中找到对应的 text span 作为槽值,而可枚举槽的追踪则转化成一个多项选择的机器阅读理解任务,从候选值中选择正确的值作为预测出的槽值。通过结合 ELMO、BERT 等深度上下文词表示,这些新提出的模型最终在 MultiWOZ 数据集上取得目前最好结果。
变化的系统动作
可拓展性问题的最后一个方面在于系统动作空间难以预定义。如图 7 所示,在设计一个电子产品推荐系统时,也许一开始并不会考虑到用户会问到如何升级产品操作系统这样的问题,但现实的情况是你无法限定用户只问系统能解决的问题。如果系统动作空间事先框定,在用户提出新问题时就会导致一连串的答非所问,导致极差的用户体验。

对此,我们需要考虑的是,如何设计更好的对话策略网络,使得系统能够快速的扩展新的动作。首先的尝试来自微软 [21],他们试图通过改变经典的 DQN 结构来实现系统在不受限动作空间上的增强学习。
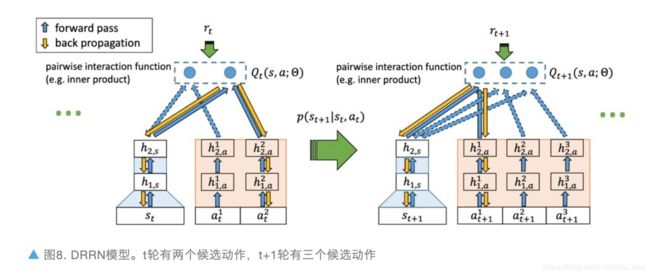
论文的对话任务是一个文字游戏闯关任务,每轮的动作是一句话,动作数目不定,选择不同的动作故事情节就会有不同的发展。作者提出了新的模型 Deep Reinforcement Relevance Network (DRRN),通过语义相似性匹配的方式将当前的对话状态和各个可选的系统动作一一匹配得到 Q 函数。
具体来看:某轮对话时,每个长度不定的动作文本会经过神经网络编码得到固定长度的系统动作向量,故事背景文本经过另一个神经网络也得到固定长度的的对话状态向量,两个向量通过交互函数(如点积)生成最后的 Q 值。图 8 是论文设计模型结构。实验表明,在“Saving John”和“Machine of Death”两个文字游戏上 DRRN 比传统 DQN(使用 padding 技巧)的表现更加优异。
论文 [22] 则希望从对话系统整体的角度来解决这个问题,作者提出了增量学习对话系统(Incremental Dialogue System, IDS),如图 9 所示。

首先系统通过 Dialogue Embedding 模块对对话历史编码得到上下文向量,再利用一个基于 VAE 的 Uncertainty Estimation 模块根据上下文向量对当前系统能否给出正确回答进行一个置信度的评估。
类似于主动学习的方式,若置信度高于阈值,则由对话管理器对当前所有可选动作一一打分,经过 softmax 函数预测出概率分布,若置信度低于阈值,则请求标注人员对本轮的回复进行标注(选择正确回复或创建新的回复),得到了新数据并入数据池里一起在线更新模型。
通过这种人类教学(human-teaching)的方式,IDS 系统不仅解决了不受限动作空间的学习问题,还可以快速地收集高质量的数据,十分贴近实际生产应用。
2.2 对话管理模型痛点二:标注数据少
随着对话系统应用领域的多样化,对数据的需求也更加多样化,若想训好一个任务型对话系统,通常都需要尽可能多的该领域的数据,但一般来说,想要获取高质量的有标注数据的成本很高。为此学者们进行了各种研究尝试,主要可分为三种思路:1)用机器自动标注数据,降低数据标注的成本;2)对话结构挖掘,尽可能高效利用无标注数据;3)加强数据采集策略,高效获取优质的数据。
机器自动标注
由于人工标注数据的代价大、效率低,学者们希望通过机器辅助人工来标注数据,方法大致可分为两大类:有监督方法和无监督方法。论文 [23] 提出一种架构 auto-dialabel,用层次聚类的无监督学习方法将对话数据中的意图和槽位自动分组,从而实现对话数据的自动标注(类别的具体标签需要人工来定)。
该方法是基于一个假设:相同意图的表达可能会共享相似的背景特征。模型提取的初始特征包括词向量、POS 标注、名词词簇和 LDA 四种特征。各个特征经由自编码器转成相同维度的向量后进行拼接,再采用 RBF(radial bias function)函数计算类间距离进行动态的层次聚类。距离最近的类将会自动合并,直到类间距离大于预设的阈值停止。模型框架如图 10 所示。

论文 [24] 则采用有监督聚类的方法来实现机器标注。作者将每条对话数据看作是一个个图节点,将聚类的过程看作是找出最小生成森林的过程。模型首先采用 SVM 在问答数据集上有监督训练出节点和节点之间的距离得分模型,再结合结构化模型和最小子树生成算法来将对话数据对应的类别信息作为隐变量推断出来,从而输出最佳的聚类结构表示用户意图类别。
对话结构挖掘
由于训练对话系统的高质量带标注数据稀缺,如何充分地挖掘无标注对话数据中隐含的对话结构或信息也成为了当今的研究热点之一,隐含的对话结构或信息在一定程度上有助于对话策略的设计和对话模型的训练。
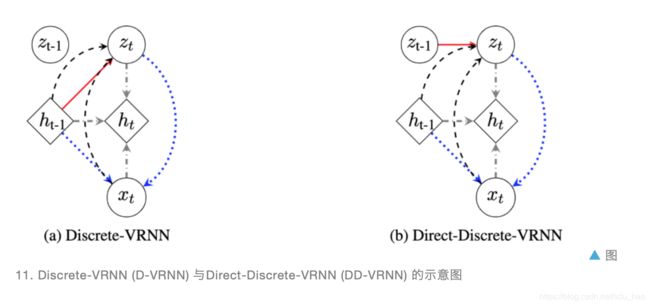
论文 [25] 提出了一种用变分循环神经网络(variational RNN, VRNN)的无监督方法自动学习对话数据中的隐藏结构。作者给出两种模型来获取对话中的动态信息:Discrete-VRNN 和 Direct-Discrete-VRNN。
如图 11 所示, x t x_t xt是第 t 轮对话, h t h_t ht表示对话历史隐变量, z t z_t zt表示对话结构隐变量(一维 one-hot 离散变量)。两种模型的差别在于:对于 D-VRNN,隐变量 z t z_t zt取决于 h t − 1 h_{t-1} ht−1;而对于 DD-VRNN,隐变量 z t z_t zt取决于 z t − 1 z_{t-1} zt−1。VRNN 通过最大整个对话的似然值,利用 VAE 的一些常用技巧,估计出隐变量的后验概率分布。
论文实验表明 VRNN 要优于传统的 HMM 的方法,同时将对话结构的信息加入到奖励函数中,也有助于增强学习模型更快地收敛。图 12 是经过 D-VRNN 挖掘出的餐馆领域的隐变量转移概率的可视化图。

CMU 学者 [26] 也尝试利用 VAE 的方法,将系统动作作为隐变量推断出来直接用于对话策略的选择,这样就能减轻预定义系统动作不够全面带来的问题。
如图 13 所示,为了简便起见,论文采用端到端的对话系统框架,基线模型是字级别的增强学习模型(即对话动作是词表中的词),通过 encoder 将对话历史编码,再利用 decoder 解码生成对话回复,奖励函数直接通过比对生成的对话回复语句和真实对话回复语句得到。

作者提出的隐动作模型和基线模型的区别是 encoder 到 decoder 之间多了离散隐变量的后验推理,对话动作由离散隐变量表示,没有任何人为的干预定义。最终实验证明,基于隐动作的端到端增强学习模型在语句生成的多样性和任务完成率上均超过了基线模型。
数据采集策略
最近,谷歌研究者们提出了一种快速收集对话数据的方法 [27](见图 14):首先利用两个基于规则的模拟器交互生成对话的 outline,即用语义标签表示的对话流骨架;然后利用模板将语义标签转写为自然语言对话;最后利用众包对自然语句进行改写,使得对话数据的语言表达更加丰富多样。这种反向收集数据方法不仅收集效率高,而且数据标注完整、可用性强,避免了收集领域数据的成本花费和大量的人工处理。

上述方法属于机器-机器(machine-to-machine, M2M)的数据收集策略:先生成覆盖面广的对话数据语义标签,再众包生成大量对话语料。其缺点在于,生成的对话相对局限,不能涵盖真实场景的所有可能性,并且效果依赖于模拟器的好坏。
学界还有另外两种常用于对话系统数据收集的方法:人-机对话(human-to-machine, H2M)和人-人对话(human-to-human, H2H)。H2H 方法要求用户(由众包人员扮演)和客服(由另一众包人员扮演)进行多轮对话,用户负责基于某些指定的对话目标(例如买机票)提需求,客服负责标注对话标签和创建对话回复。这种模式被称为 Wizard-of-Oz 框架,对话研究的诸多数据集如 WOZ [5], MultiWOZ [28] 均采用此方式收集。
H2H 方法可以得到最贴近实际业务场景的对话数据,但是需要为了不同的任务需要设计不一样的互动界面,而且需要耗费大量人力清理错误的标注,成本相当昂贵。H2M 的数据收集策略则是让用户和训练到一定程度的机器直接进行对话在线收集数据,并且利用增强学习不断改进对话管理模型,著名的 DSTC2&3 数据集就是通过这种方法收集得到。
H2M 方法的效果总体比较依赖于对话管理模型的初始效果,并且在线收集的数据噪声较大,清理成本也会较高,影响模型优化的效率。
2.3 对话管理模型痛点三:训练效率低
随着深度增强学习在游戏围棋领域的大获成功,该方法在任务导向型对话领域也有广泛应用。例如论文 [6] 的 ACER 对话管理方法,使用了 model-free 深度增强学习,通过结合 Experience Replay、信度域约束、预训练等技巧,大大提高了增强学习算法在任务型对话领域的训练效率和稳定性。
然而,简单地套用增强学习算法并不能满足对话系统的实际应用。这主要是因为对话领域不像游戏围棋那样有清晰的规则、奖励函数,动作空间简单明确,还有完美的环境模拟器可以生成数以亿计的高质量交互数据。
对话任务中,一般包括了多样变化的槽位槽值和动作意图,这使得对话系统的动作空间急剧增大且难以预定义。传统扁平的增强学习(flat reinforcement learning)方法由于对所有的系统动作进行 one-hot 编码,会存在维度灾难,因此不再适用于处理动作空间非常大的复杂对话问题,为此学者们进行了诸多研究尝试,包括 model-free RL、model-based RL 和 human-in-the-loop 三个方向。
Model-free 增强学习–分层增强学习
分层增强学习(Hierarchical Reinforcement Learning, HRL)基于“分而治之”的理念,将复杂任务分解成多个子任务(sub-task),解决了传统扁平的增强学习的维度灾难。
论文 [29] 首次将分层增强学习(HRL)应用到任务导向型对话领域,作者利用专家知识把复杂的对话任务在时序维度上拆分成多个子任务,例如一个复杂的旅行问题可以分解为订机票、订酒店、租车等子问题。根据这个拆分,他们设计了两个层次的对话策略网络,一个层次负责选择和安排所有的子任务,另一个层次负责具体子任务的执行。
他们提出的对话管理模型(如图 15 所示)包括:1)顶层策略(top-level policy),用于根据对话状态选择子任务;2)底层策略(low-level policy),用于完成子任务的具体的某个对话动作;3)全局对话状态追踪,记录整体对话状态。
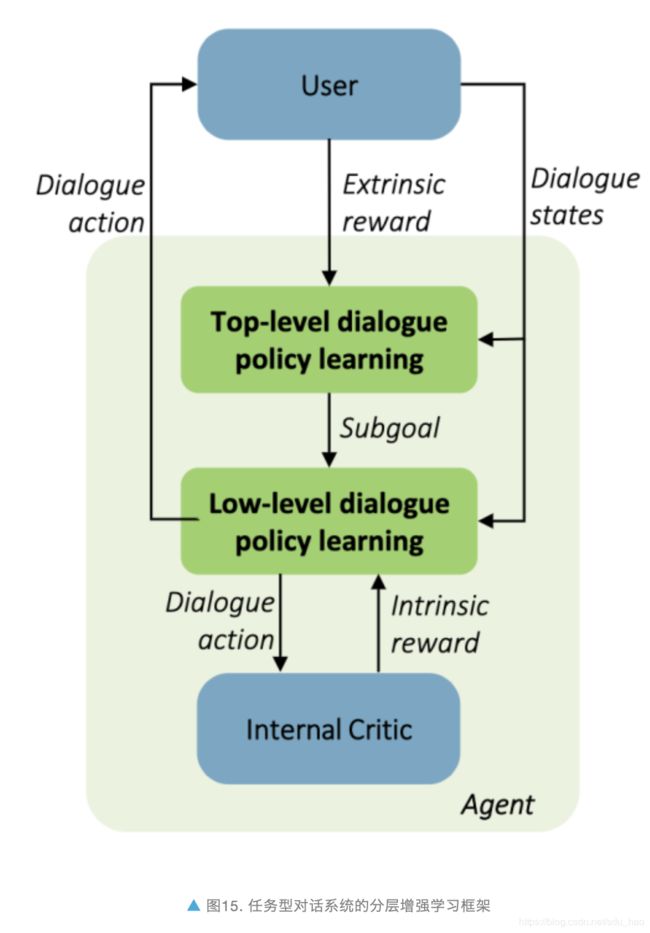
整个对话任务完成之后,顶层策略会收到外部奖励(external reward)。除此以外,模型还新增了内部评定模块(internal critic),用于根据对话状态估计子任务完成的可能性(子任务的填槽程度),底层策略会根据子任务完成程度收到内部评定模块的一个内部奖励(intrinsic reward)。
面对复杂的对话问题,传统的增强学习的每一步决策都在选择基本系统动作,比如询问槽值或者确认约束,而分层增强学习的先通过顶层策略选择一大类基本动作的集合,再通过底层策略选择当前集合的基本动作,流程如图 16 所示。

这种对动作空间的层次划分,能够考虑到不同子任务之间的时序约束关系,有助于完成复合对话任务(composite task)。并且论文通过加入内部奖励的方式,有效缓解了奖励稀疏的问题,加快了增强学习的训练,也在一定程度上避免了对话在不同子任务之间频繁切换,提高了动作预测准确率。
当然动作的分层设计比较依赖专家知识,需要通过专家来确定子任务的种类,近期相应地出现了一些对话子任务自动发现的工作 [30] [31],通过无监督的方法,对整个对话历史的对话状态序列进行自动切分,从而避免人工构建对话子任务结构。
Model-free 增强学习–封疆增强学习
封疆增强学习(Feudal Reinforcement Learning, FRL)是另一种适用于大维度问题的增强学习方法。分层增强学习是把对话策略按照时间维度上的不同任务阶段划分成子策略,从而降低策略学习的复杂度;而封疆增强学习(FRL)是在空间维度上把策略进行划分,限制子策略负责的动作范围,划分了“管辖疆域”,从而降低子策略的复杂度。
封疆增强学习(FRL)不划分子任务,而是应用了状态空间的抽象化函数,从对话状态中提取有用的特征。这种抽象化有利于封疆增强学习(FRL)在大型问题中的应用以及在不同领域之间的迁移,具有较强的扩展性。
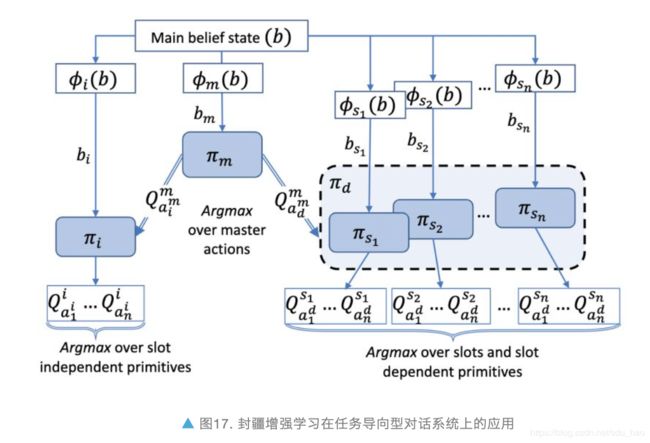
剑桥学者们首次将封疆增强学习 [32] 运用到任务导向对话系统领域,将动作空间按照是否和槽位相关来进行划分,这样只利用了动作空间的自然结构而不需要额外的专家知识。
他们提出了如图 17 所示的封疆策略结构,该结构的决策过程分两步:1)决定下一步动作是否需要槽位作为参数;2)根据第一步的决策,以及对应的不同槽位采用不同的底层策略选择下一步动作。
总的来说,分层增强学习(HRL)与封疆增强学习(HRL)都是将高维度的复杂动作空间进行不同方式的拆分,以解决传统 RL 动作空间维度大导致训练效率低的问题。分层增强学习(HRL)对任务的分割合理,比较符合人类的理解,但是需要专家知识来拆分子任务。封疆增强学习(FRL)对复杂问题的拆分则直接考虑其动作本身的逻辑结构,不考虑不同子任务之间的相互约束。
Model-based 增强学习
以上讨论的属于无模型(model-free)增强学习,它是通过和环境交互试错得到大量弱监督数据,再去训练一个价值网络或者策略网络,而不关心环境本身。与之相对的是基于模型的(model-based)增强学习,它的学习过程如图 18。

其特点是对环境直接进行建模,利用和环境交互得到的数据学习出一个状态和奖励的概率转移函数,即环境模型,然后系统可以和环境模型交互产生更多的训练数据,因此 model-based 增强学习一般比 model-free 增强学习的训练效率要高,尤其是在和环境交互代价昂贵的场景。但其效果取决于环境建模的好坏。
采用 model-based 增强学习来提高训练效率是最近研究热点,微软首先将经典的 Deep Dyna-Q(DDQ)算法应用到对话中 [33]。
如图 19c 所示,DDQ 训练开始之前,先利用少量已有的对话数据对策略模型和环境模型(world model)进行预训练,之后 DDQ 的训练不断循环三个步骤:1)直接增强学习 — 通过和真实用户在线对话交互,更新策略模型并且储存对话数据;2)训练环境模型 — 利用收集到的真实对话数据更新环境模型;3)规划(planning)— 利用和环境模型交互得到的对话数据来训练策略模型。

其中环境模型(如图 20)是一个神经网络,对环境的状态转换和奖励进行概率建模,输入是当前对话状态以及系统动作,输出是下一轮用户动作、环境奖励和对话终止变量。环境模型使得 DDQ 降低了在线增强学习(如图 19a)对人机交互数据量的需求,也避免了和用户模拟器交互(如图 19b)质量不高的问题。

环境模型与对话领域中的用户模拟器比较相似,它们都可以用于模拟真实用户的动作并和系统的对话管理模块交互。但两者不同之处在于用户模拟器本质是系统的外部环境,用于模拟真实用户,环境模型是系统的一部分,属于系统内部模型。
在 DDQ 的工作基础上,微软研究者们做了更多的扩展:为了提高环境模型产生的对话数据的真实性,他们提出 [34] 采用对抗训练的思想提高对话数据的生成质量;针对何时使用和真实环境交互的数据,何时使用和环境模型交互的数据,论文 [35] 探讨了可行方案;为了将真人交互也纳入进来,论文 [36] 给出了一个统一的对话框架。这种人类教学(human-teaching)的思想也是目前业界构建对话管理模型的关注热点,我们在下小节给出更多阐述。
Human-in-the-loop
我们希望能充分引入人的知识经验来生成高质量数据,提高模型训练效率。Human-in-the-loop 增强学习 [37] 就是一种将人类引入机器人训练过程的方法,通过设计好的人机交互方式,人类可以高效地指导训练增强学习模型。为了进一步提升任务导向对话系统的训练效率,针对对话问题的特性设计有效的 human-in-the-loop 方式成为了研究人员新的探索方向。
谷歌研究者提出了一种人类教学和增强学习结合的复合学习方法 [37](如图 21),在有监督预训练和在线增强学习之间增加一个人类教学阶段,让人介入进来打标签,避免了有监督预训练导致的 covariate shift 问题 [42]。
亚马逊研究者也提出一种类似的人类教学框架 [37]:每轮对话中,系统都推荐 4 条回复供客服专家选择;然后客服专家决定是选择 4 条回复中的一条,还是另外编辑新的回复;最后由客服专家把选择好或者编辑好的回复发给用户。利用这种方式,开发人员可以快速地更新对话系统能力,适合落地。
以上是系统被动地接受人对数据进行标注,但是好的系统也应该学会主动提问、寻求人的帮助。论文 [40] 提出了陪伴式学习(companion learning)的架构(如图 22),在传统的增强学习框架中加入老师的角色(即人),老师可以纠正对话系统(即学生)的回复(图左侧开关),也能以内部 reward 的形式对学生的回复进行评价(图右侧开关)。
对于主动学习的实现,作者提出了对话决策确信度(decision certainty)的概念,通过 dropout 技巧对学生策略网络进行多次采样,得到可取动作的最大概率近似估计,再通过计算该最大概率的若干对话轮次的滑动平均值作为学生策略网络的决策确信度。确信度若低于目标值,则根据确信度与目标值的差距,决定老师是否参与进来纠正错误和提供奖励函数,确信度高于目标值,则停止向老师学习,系统自行进行判决

主动学习的关键在于估计出对话系统对自身决策的确信度,除了上述对策略网络进行 dropout 的方法,还有以隐变量为条件变量,计算策略网络分布 Jensen-Shannon 散度的方法 [22]、根据当前系统对话成功率做判断的方法 [36]。
3. 小蜜Conversational AI团队的对话管理框架
为了保证稳定性和可解释性,目前业界对话管理模块多采用基于规则的方法。阿里巴巴-达摩院-小蜜 Conversational AI 团队在去年就开始尝试对话管理模型化的工作,并进行了深入地探索。在真实的对话系统建设中,我们需要解决两个问题:1)如何获得特定场景的大量对话数据;2)怎么利用算法充分发挥数据的价值?
对于整个模型化的框架设计,目前我们规划成四步走的路线(如图 23 所示):

第一步,先利用小蜜 Conversational AI 团队自主研发的对话工厂(dialog studio)快速构建一个基于规则对话流的对话引擎(称为TaskFlow),同时用类似的对话流去构建一个用户模拟器。在构建好用户模拟器和对话引擎之后,两者采用 M2M 方式持续交互沉淀出大量的对话数据。
第二步,有了一定量的对话数据后,我们再利用有监督学习训练一个神经网络,构建和规则对话引擎能力基本相当的对话管理模型,实现对话管理的初步模型化。模型的设计采用语义相似匹配和端到端生成两种方法结合来实现可拓展性,对于动作空间较大的对话任务采用 HRL 进行动作划分。
第三步,有了初步的对话管理模型,在开发阶段,我们让系统和改进的用户模拟器或人工智能训练师进行交互,通过 off-policy ACER 增强学习算法让系统的对话能力持续地增强。
第四步,人机对话体验达到初步实用之后,就可以上线运行,引入人的因素,收集用户真实交互数据,同时通过一些 UI 设计方便地引入用户的反馈,持续不断地更新强化模型。沉淀出大量人机对话数据也会进一步进行做数据分析和挖掘,用于客户洞察。
目前,我们打造的基于增强学习的对话管理模型,在订会议室这种中等复杂规模的对话任务上,和用户模拟器交互的对话完成率可达 80%,如图 24 所示。

4. 总结
本综述围绕对话管理(Dialog Management, DM)模型的最新前沿研究做了一个详细的介绍,针对传统对话管理的痛点划分了三个大的方向:1)可拓展性差;2)标注数据少;3)训练效率低。
在可拓展性方面,我们介绍了处理变化的用户意图、对话本体、系统动作空间的常用方法,主要有语义相似匹配方法、知识蒸馏方法和序列生成方法;对于标注数据稀缺问题,我们介绍了机器自动标注、对话结构有效挖掘和数据高效收集策略三部分内容;而针对传统 DM 中 RL 模型训练效率低下的问题,学界有尝试引入 HRL、FRL 等方法对动作空间进行层次划分,也有利用 model-based RL 对环境进行建模提高训练效率,将 human-in-the-loop 引入对话系统训练框架亦是当下十分活跃的研究方向。
最后我们对阿里巴巴-达摩院-小蜜 Conversational AI 团队目前在 DM 模型化的进展做了一个比较详细的汇报介绍,希望本综述能为大家的对话管理研究提供一些启发和思考。
5. 参考文献
[1]. TURING A M. I.—COMPUTING MACHINERY AND INTELLIGENCE[J]. Mind, 1950, 59(236): 433-460.
[2]. Weizenbaum J. ELIZA—a computer program for the study of natural language communication between man and machine[J]. Communications of the ACM, 1966, 9(1): 36-45.
[3]. Young S, Gašić M, Thomson B, et al. Pomdp-based statistical spoken dialog systems: A review[J]. Proceedings of the IEEE, 2013, 101(5): 1160-1179.
[4]. Bordes A, Boureau Y L, Weston J. Learning end-to-end goal-oriented dialog[J]. arXiv preprint arXiv:1605.07683, 2016.
[5]. Wen T H, Vandyke D, Mrksic N, et al. A network-based end-to-end trainable task-oriented dialogue system[J]. arXiv preprint arXiv:1604.04562, 2016.
[6]. Su P H, Budzianowski P, Ultes S, et al. Sample-efficient actor-critic reinforcement learning with supervised data for dialogue management[J]. arXiv preprint arXiv:1707.00130, 2017.
[7]. Serban I V, Sordoni A, Lowe R, et al. A hierarchical latent variable encoder-decoder model for generating dialogues[C]//Thirty-First AAAI Conference on Artificial Intelligence. 2017.
[8]. Berant J, Chou A, Frostig R, et al. Semantic parsing on freebase from question-answer pairs[C]//Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. 2013: 1533-1544.
[9]. Dhingra B, Li L, Li X, et al. Towards end-to-end reinforcement learning of dialogue agents for information access[J]. arXiv preprint arXiv:1609.00777, 2016.
[10]. Lei W, Jin X, Kan M Y, et al. Sequicity: Simplifying task-oriented dialogue systems with single sequence-to-sequence architectures[C]//Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018: 1437-1447.
[11]. Madotto A, Wu C S, Fung P. Mem2seq: Effectively incorporating knowledge bases into end-to-end task-oriented dialog systems[J]. arXiv preprint arXiv:1804.08217, 2018.
[12]. Mrkšić N, Séaghdha D O, Wen T H, et al. Neural belief tracker: Data-driven dialogue state tracking[J]. arXiv preprint arXiv:1606.03777, 2016.
[13]. Ramadan O, Budzianowski P, Gašić M. Large-scale multi-domain belief tracking with knowledge sharing[J]. arXiv preprint arXiv:1807.06517, 2018.
[14]. Weisz G, Budzianowski P, Su P H, et al. Sample efficient deep reinforcement learning for dialogue systems with large action spaces[J]. IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP), 2018, 26(11): 2083-2097.
[15]. Wang W, Zhang J, Zhang H, et al. A Teacher-Student Framework for Maintainable Dialog Manager[C]//Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018: 3803-3812.
[16]. Yun-Nung Chen, Dilek Hakkani-Tur, and Xiaodong He, “Zero-Shot Learning of Intent Embeddings for Expansion by Convolutional Deep Structured Semantic Models,” in Proceedings of The 41st IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2016), Shanghai, China, March 20-25, 2016. IEEE.
[17]. Rastogi A, Hakkani-Tür D, Heck L. Scalable multi-domain dialogue state tracking[C]//2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2017: 561-568.
[18]. Mesnil G, He X, Deng L, et al. Investigation of recurrent-neural-network architectures and learning methods for spoken language understanding[C]//Interspeech. 2013: 3771-3775.
[19]. Bapna A, Tur G, Hakkani-Tur D, et al. Towards zero-shot frame semantic parsing for domain scaling[J]. arXiv preprint arXiv:1707.02363, 2017.
[20]. Wu C S, Madotto A, Hosseini-Asl E, et al. Transferable Multi-Domain State Generator for Task-Oriented Dialogue Systems[J]. arXiv preprint arXiv:1905.08743, 2019.
[21]. He J, Chen J, He X, et al. Deep reinforcement learning with a natural language action space[J]. arXiv preprint arXiv:1511.04636, 2015.
[22]. Wang W, Zhang J, Li Q, et al. Incremental Learning from Scratch for Task-Oriented Dialogue Systems[J]. arXiv preprint arXiv:1906.04991, 2019.
[23]. Shi C, Chen Q, Sha L, et al. Auto-Dialabel: Labeling Dialogue Data with Unsupervised Learning[C]//Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018: 684-689.
[24]. Haponchyk I, Uva A, Yu S, et al. Supervised clustering of questions into intents for dialog system applications[C]//Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018: 2310-2321.
[25]. Shi W, Zhao T, Yu Z. Unsupervised Dialog Structure Learning[J]. arXiv preprint arXiv:1904.03736, 2019.
[26]. Zhao T, Xie K, Eskenazi M. Rethinking action spaces for reinforcement learning in end-to-end dialog agents with latent variable models[J]. arXiv preprint arXiv:1902.08858, 2019.
[27]. Shah P, Hakkani-Tur D, Liu B, et al. Bootstrapping a neural conversational agent with dialogue self-play, crowdsourcing and on-line reinforcement learning[C]//Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 3 (Industry Papers). 2018: 41-51.
[28]. Budzianowski P, Wen T H, Tseng B H, et al. Multiwoz-a large-scale multi-domain wizard-of-oz dataset for task-oriented dialogue modelling[J]. arXiv preprint arXiv:1810.00278, 2018.
[29]. Peng B, Li X, Li L, et al. Composite task-completion dialogue policy learning via hierarchical deep reinforcement learning[J]. arXiv preprint arXiv:1704.03084, 2017.
[30]. Kristianto G Y, Zhang H, Tong B, et al. Autonomous Sub-domain Modeling for Dialogue Policy with Hierarchical Deep Reinforcement Learning[C]//Proceedings of the 2018 EMNLP Workshop SCAI: The 2nd International Workshop on Search-Oriented Conversational AI. 2018: 9-16.
[31]. Tang D, Li X, Gao J, et al. Subgoal discovery for hierarchical dialogue policy learning[J]. arXiv preprint arXiv:1804.07855, 2018.
[32]. Casanueva I, Budzianowski P, Su P H, et al. Feudal reinforcement learning for dialogue management in large domains[J]. arXiv preprint arXiv:1803.03232, 2018.
[33]. Peng B, Li X, Gao J, et al. Deep dyna-q: Integrating planning for task-completion dialogue policy learning[J]. ACL 2018.
[34]. Su S Y, Li X, Gao J, et al. Discriminative deep dyna-q: Robust planning for dialogue policy learning.EMNLP, 2018.
[35]. Wu Y, Li X, Liu J, et al. Switch-based active deep dyna-q: Efficient adaptive planning for task-completion dialogue policy learning.AAAI, 2019.
[36]. Zhang Z, Li X, Gao J, et al. Budgeted Policy Learning for Task-Oriented Dialogue Systems. ACL, 2019.
[37]. Abel D, Salvatier J, Stuhlmüller A, et al. Agent-agnostic human-in-the-loop reinforcement learning[J]. arXiv preprint arXiv:1701.04079, 2017.
[38]. Liu B, Tur G, Hakkani-Tur D, et al. Dialogue learning with human teaching and feedback in end-to-end trainable task-oriented dialogue systems[J]. arXiv preprint arXiv:1804.06512, 2018.
[39]. Lu Y, Srivastava M, Kramer J, et al. Goal-Oriented End-to-End Conversational Models with Profile Features in a Real-World Setting[C]//Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Industry Papers). 2019: 48-55.
[40]. Chen L, Zhou X, Chang C, et al. Agent-aware dropout dqn for safe and efficient on-line dialogue policy learning[C]//Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. 2017: 2454-2464.
[41]. Gao J, Galley M, Li L. Neural approaches to conversational AI[J]. Foundations and Trends® in Information Retrieval, 2019, 13(2-3): 127-298.
[42]. Ross S, Gordon G, Bagnell D. A reduction of imitation learning and structured prediction to no-regret online learning[C]//Proceedings of the fourteenth international conference on artificial intelligence and statistics. 2011: 627-635.
[43]. Rajendran J, Ganhotra J, Polymenakos L C. Learning End-to-End Goal-Oriented Dialog with Maximal User Task Success and Minimal Human Agent Use[J]. Transactions of the Association for Computational Linguistics, 2019, 7: 375-386.
[44]. Mrkšić N, Vulić I. Fully Statistical Neural Belief Tracking[C]//Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2018: 108-113.
[45]. Zhou L, Small K. Multi-domain Dialogue State Tracking as Dynamic Knowledge Graph Enhanced Question Answering[J]. arXiv preprint arXiv:1911.06192, 2019.
[46]. Rajpurkar P, Jia R, Liang P. Know What You Don’t Know: Unanswerable Questions for SQuAD[J]. arXiv preprint arXiv:1806.03822, 2018.
[47]. Zhang J G, Hashimoto K, Wu C S, et al. Find or Classify? Dual Strategy for Slot-Value Predictions on Multi-Domain Dialog State Tracking[J]. arXiv preprint arXiv:1910.03544, 2019.