2020美赛C题的一些想法总结
2020年的C题是一道典型的数据分析的题目,基于大数据分析处理进行相关建模。对于这道题而言,最难之处莫过于各个数据项关系的梳理总结,以及对数据的挖掘建模。网上很多大神给了很多高级的方法(深度学习、神经网络等)。其实作为小白,很多参赛的同学并不了解这方面的算法,以及背后的数学原理,很多人指望一两个高级算法就能解决问题,只想着盲目套用,只会贻误比赛的时间。
以下皆是本人对这题的一些粗浅的看法,仅供参考。
问题解决的要点:
一、数据的预处理
对于数据的预处理,个人首推Excel,简单方便快捷
导入数据:
题目所给数据时tsv文本形式的数据,需要导入Excel进行数据的预处理
 原始数据集的各个数据项:
原始数据集的各个数据项:
| marketplace | customer_id | review_id | product_id | product_parent | product_title | product_category |
|---|---|---|---|---|---|---|
| 所属地区/国家简写码 | 用户的ID | 评论的唯一标识ID | 产品的ID | 产品所属父类的标识ID | 产品的标题 | 产品所属类别 |
| star_rating | helpful_votes | total_votes | vine | verified_purchase | review_headline | review_body | review_date |
|---|---|---|---|---|---|---|---|
| 产品星级 | 赞成数(点赞数) | 评论总的获赞数(赞成与反对) | Amazon Vine的一个认证,评论具有一定的可信度和准确性 | 是否以较低折扣购买相关产品 | 评论的标题 | 评论的内容 | 评论的日期 |
注:对于verified_purchase,我是基于对英文注释的理解,也有很多人将其理解为购买认证,即评论的人是否在亚马逊平台上购买了相关产品。亚马逊上好像不买东西也可以评论,迷之操作。
利用Excel可以数据查重,缺失值填充,数据转换等预处理操作,至于怎么利用Excel进行各种预处理的操作就不赘述了
例如:可以利用Excel查重,确定数据集的各个数据项之间的关系,可以发现顾客数据项不是唯一的,即不是每一个数据都对应一个用户,存在一个顾客购买多个产品的现象,产品的ID以及产品父类也是,只有每个评论的ID是唯一的。这样的一些处理分析可以让我们更加了解这个数据集中各个数据项之间的关系。
这里就想提醒两个容易忽视的基本操作:
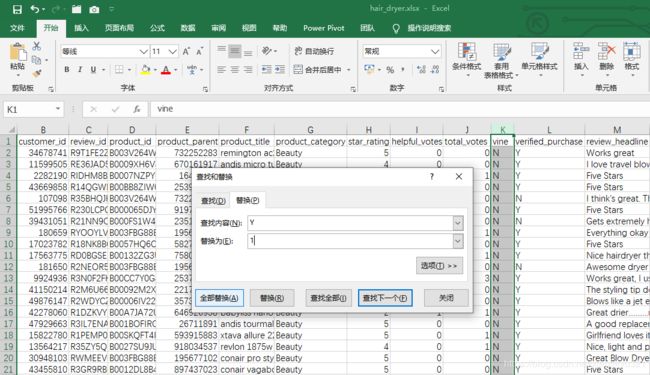
1、文本信息数值化
数据分析,分析的是数据,一般我们很不喜欢处理非数值的信息,因此需要将非数值的一些文本信息数值化,查找替换,将非数值的信息数值化便于后面的数据处理分析。
 2、顾客评论标题以及评论内容的预处理
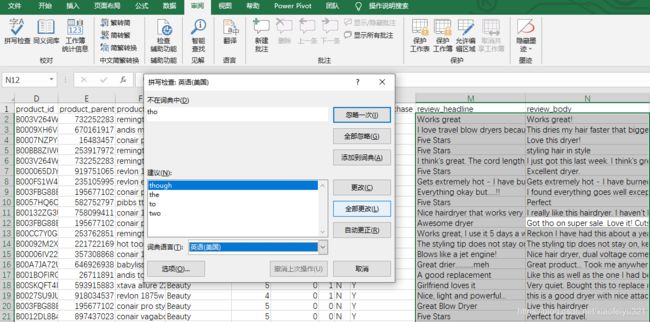
2、顾客评论标题以及评论内容的预处理
由于顾客评论中可能存在许多拼写错误,我们可以利用Excel的拼写检查对这部分的信息进行预处理。方便之后的评论种类的划分,以及评论的情感分析。
二、产品的综合评价
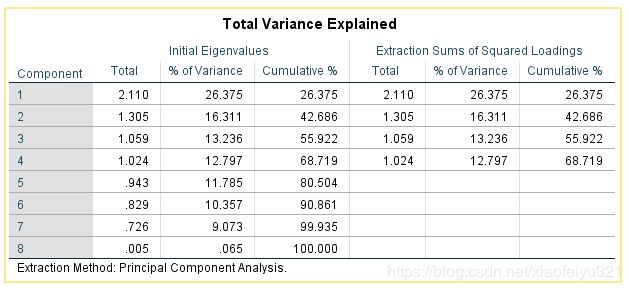
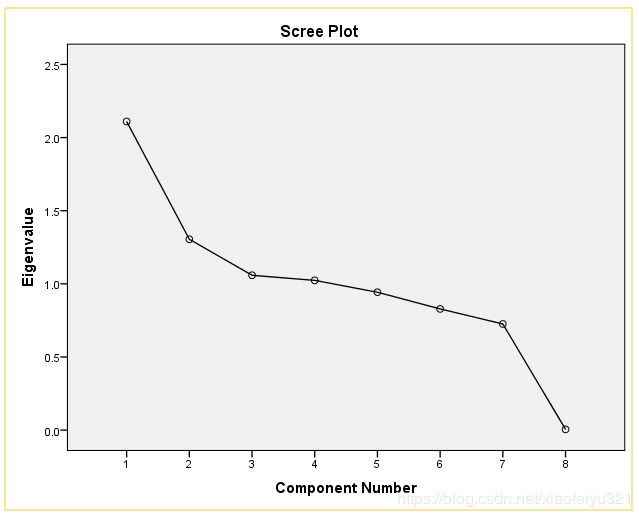
对于产品的综合评价,初始考虑使用主成分分析,将影响产品评价的几个量关联起来,进行数据降维,再计算因子得分,按总分排序来对排名靠前产品进行,但结果并不理想(捂脸)。【这里用的是Excel的数据透视表,去除部分无关信息,以产品ID为行标签将同一个产品ID的数据整合】
 分析结果:
分析结果:
后面就直接结合主成分分析结果利用对原始数据集比对分析,再综合层次分析法(权重+结合数据)进行对产品的综合评定(烂尾)。
三、评论种类的区分
本题解题的另一个关键是将评论划分种类,可以简单地划分为好评、差评或者好评、中评、差评,可以将划分好种类的评论简单地利用数字-1,0,1来表示。评论的种类划分可以基于以下几步:
1、基于评论标题以及内容进行提词
对数据项中的评论部分进行提取,利用python正则表达式进行字符匹配并分词,将评论提取为一个个的词汇,去除提取的词汇中的常用停用词,无效字符,数字等,构建相关产品的常用评论词汇库。【提词过程的代码可以多跑几次,观察提词结果再优化】
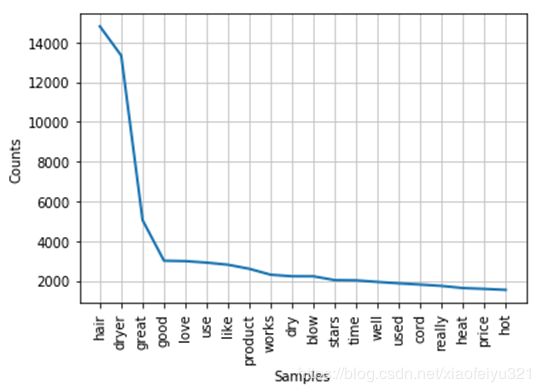

2、分析提词结果构造产品评论词库
基于提取的相关产品的常用词汇库,选取部分对划分评论种类有用的词,对词库中的词进行划分,构建产品评论相关词库。【下面为初步结果,可以结合代码进行优化】
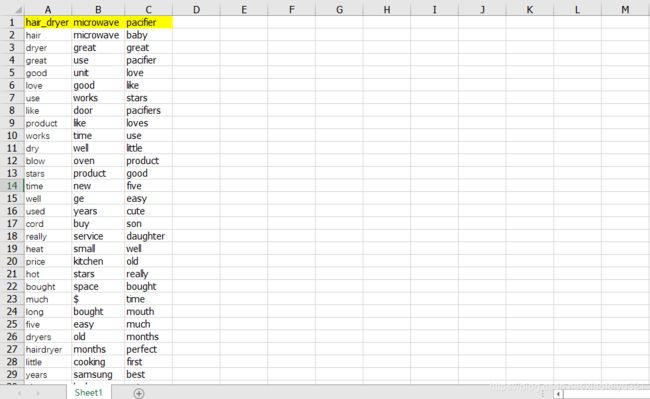 3、依据词库对评论种类进行划分
3、依据词库对评论种类进行划分
对与这部分可以直接利用Python NLTK进行比对,但考虑到NLTK相关语料库下载速度惊人,直接忽略。结合常用评价词汇修正词库,加入部分常用词汇,构建评论判别词汇库,对评论进行判别归类,将评论分为三类:好评、中评、差评。简单直接的方式就是自己构建词库进行分析,以下方法如果词库构建较为完善,结合评论内容,顾客所打星级,对初步划分结果进行修正,基本可以得到较好的评论分类结果。【网上也有很多简单粗暴的方式利用NLTK的相关词库以及算法直接莽】
参考代码:
# -*- coding: utf-8 -*-
"""
Created on Fri Mar 2020
@author: Good
"""
# NLP python自然语言处理
import re
import numpy as np
import pandas as pd
from nltk.corpus import stopwords
# 导入相关数据
data = pd.read_csv('C:/Users/Good/Desktop/Problem_C_Data/pacifier.tsv',sep = '\t')
# 获取数据标签
data_label = data.columns.values.tolist()
# 缺失观测的检测填充
print('数据集中是否存在缺失值:',any(data.isnull()))
data.fillna(method = 'ffill')
print('缺失值已前向填充!')
#------------------------------------------------------------------------------
# 获取语言文本
review_headline = pd.DataFrame(data.loc[:,data_label[12]])
review_body = pd.DataFrame(data.loc[:,data_label[13]])
# 情感词库
positive = ['happy','great','five','four','good','perfect','love','loves',
'faster','excllent','super','thanks','amazing','powerful','quickly',
'fine','awesome','nice','helpful','like']
negative = ['one','two','bad','no','abandon','amiss','badly','blind','awful'
'terrible','awfulness','helpless','useless']
# 以上词库仅初始词库,为了更好的效果,可以多跑几次,完善词库,这里仅做参考
#------------------------------------------------------------------------------
# 对文本信息进行相关处理,构造单词列表,并对评论进行归类
# 基于评论标题的评论分类
sentiment = np.zeros((np.size(review_headline),1))
for i in range(0,np.size(review_headline)):
review_headline.iloc[i,0] = str(review_headline.iloc[i,0])
review_headline.iloc[i,0] = review_headline.iloc[i,0].lower()
review_headline.iloc[i,0] = re.sub(r'[0-9]|\s|\,|\.|\!|\-|\(|\)|\<|\>|\:|/|\*|\;|\?|\`',
' ',review_headline.iloc[i,0])
for k in '&#$':
review_headline.iloc[i,0] = re.sub(k,'',review_headline.iloc[i,0])
temp = review_headline.iloc[i,0].split()
handle_temp = []
for m in range(0,np.size(temp)):
if temp[m] not in stopwords.words('english'):
handle_temp.append(temp[m])
for j in handle_temp:
if j in positive:
sentiment[i,0] = 1
elif j in negative:
sentiment[i,0] = -1
#------------------------------------------------------------------------------
# 基于评论内容的评论分类,对初步分类结果进行修正
for i in range(0,np.size(review_body)):
review_body.iloc[i,0] = str(review_body.iloc[i,0])
review_body.iloc[i,0] = review_body.iloc[i,0].lower()
review_body.iloc[i,0] = re.sub(r'[0-9]|\s|\,|\.|\!|\-|\(|\)|\<|\>|\:|/|\*|\;|\?|\`',
' ',review_body.iloc[i,0])
for k in '&#$':
review_body.iloc[i,0] = re.sub(k,'',review_body.iloc[i,0])
temp = review_body.iloc[i,0].split()
body_temp = []
for n in range(0,np.size(temp)):
if temp[n] not in stopwords.words('english'):
body_temp.append(temp[n])
for j in body_temp:
if j in positive and sentiment[i,0] == 0:
sentiment[i,0] = 1
elif j in negative and sentiment[i,0] == 0:
sentiment[i,0] = -1
#------------------------------------------------------------------------------
# 基于评论星级,点赞数的评论归类的三次修正
star_rating = pd.DataFrame(data.loc[:,data_label[7]])
for i in range(0,np.size(star_rating)):
if star_rating.iloc[i,0] > 3 and sentiment[i,0] == -1:
sentiment[i,0] = 1
elif star_rating.iloc[i,0] == 3 and sentiment[i,0] == 1:
sentiment[i,0] = 0
elif star_rating.iloc[i,0] == 3 and sentiment[i,0] == -1:
sentiment[i,0] = -1
elif star_rating.iloc[i,0] < 3 and sentiment[i,0] == 1:
sentiment[i,0] = 0
四、评论的情感分析
情感分析与上述评论分析有很多相似的地方,最简单直接的方式就是根据评论中正面词汇以及反面词汇的个数进行加权平均,可以直接考虑利用Python textblob库,网上有现成的代码,不过推荐自己写,这样可以通过建模学到更多的东西。

这里的权重,如果嫌麻烦可以直接就对半开,如果想要客观公正的话,可以构建程度词库,结合程度词权重的方式进行模型的优化,例如:extremely等程度词在正面情感词汇前面可以怎样(可以对程度词划分级别,赋予权值,相关资料中提供了程度词词库)。主要思想就是,将正面情感词汇与负面情感词汇进行加权平均得到情感倾向。【很多NLP智能算法的做法与我这上面的想法类似,不过过程更规范,识别更准确,不过思想是相通的,也有利用机器学习的算法做的,可以去了解一下】
五、相关资料
1、题目(PDF) 链接:https://pan.baidu.com/s/1mJOawF3gibrQFnQwDaMNIQ 提取码:d60g
2、题目(Word) 链接:https://pan.baidu.com/s/1nn3E5MBdt6H4iqtYgXdyAg 提取码:dowd
3、数据 链接:https://pan.baidu.com/s/1FXrNLUYA0Ev64-HYcYHhlA 提取码:18mm
4、网上搜集的词库 链接:https://pan.baidu.com/s/1Tpk0PIev2slGZ0XYY_P2Lg 提取码:b482
六、小结
给大家也是我自己的建议,不要老想着利用某个超级算法解决问题,坐等拿奖。对于一些算法,如果我们能掌握其原理,并能灵活运用最好,如若知识水平不够,不妨尝试利用自己已有的知识去解决这类问题。我非常喜欢的xu老师曾多次教导我对于一个问题,最应该想的就是怎么利用自己已有的知识进行求解,条条大路通罗马,拘泥于一种方法往往会思维受限,钻入死胡同。我想分享给大家,也希望大家通过数学建模都能有所收获,学到更多的知识,提高分析和解决问题的能力!