再夺第一,深度解析依图行为识别的技术高墙与创新突围

江湖三十年鏖战,AI 即出,多方势力涌入让这个世界重新异彩纷呈,也经历了新一轮洗牌。
在这场战役中留下姓名的企业,皆因技术、产品、服务等硬实力,成为了行业中的佼佼者。
在同样起跑线,有些企业总是能独占鳌头,以不卑不亢的姿态,成为“别人家的孩子”。
AI 独角兽依图也是这样一位“别人家的孩子”。
最近,在国际权威机构 ACM MM(ACM MM’20 Grand Challenge)主办的“大规模复杂场景下人体视频解析”挑战赛(Large-scale Human-centric Video Analysis in Complex Events)的核心赛道——行为识别中,依图科技再夺一冠。
ACM MM 被认为是多媒体技术领域奥运级别的顶级盛会,也是中国计算机学会(CCF)认证和多媒体研究领域评级中唯一的A类国际顶级会议。此次挑战赛集结了国内外约 100 支参赛队伍,包括亚马逊、大华、腾讯、中山大学等知名企业和院校。
同时,此次竞赛是该方向最接近真实场景的大规模挑战赛,主要基于各类人群和复杂事件(如地震逃生、食堂用餐、下火车等)来分析人的行为,包括多人追踪、姿态估计、姿态追踪、行为识别等四大任务;目的在于考察算法在复杂场景下对人体的解析能力,鼓励研究者在以人为中心的分析中解决非常具有挑战性和现实的问题。
更为关键的一点是,与其他举办过多次的国际竞赛不同,作为首届竞赛,参赛队伍在赛前无法了解识别的类别、数据集的大小和识别的具体需求,也就是说,对即将面对的行为类别、数据模型、比赛需求一无所知,这意味着没有经验可借鉴,没有路径可学习。依图是如何在短短两个月的挑战时间内,实现最优的算法性能,拿下世界第一?
挑战不可能
顾名思义,大规模复杂场景挑战赛必然需要大规模和复杂场景。大规模即丰富的场景、大额的数据量(一般情况下,100 万以上的数据量在学术界会被称为大规模)。
作为首届比赛,HiEve 数据集标注超 100 万个,内容以真实视频场景为主,囊括了当前姿态数量最多的数据集。其中,有超 56000 个复杂事件下的人体行为,包括但不限于排队、打架、俯身、同行、跑动等;平均轨迹长度超过 480,是轨迹数量最多的数据集之一。
结合到比赛的具体任务而言,行为识别,简单场景指的是一个视频里只分析一个行为的主体;复杂场景指的是视频里有多个人,在密集、拥挤的场景下,分析的行为还需要包含人和人之间的互动。
1)数据量大,但有效数据少
比赛中,考察的行为种类非常多,且每种行为可以有多种表达方式,例如出拳、拉扯、扇巴掌等都属于打架,而训练集很难覆盖所有可能的组合。
虽然数据总量达到 100 万,但由于视频数据帧之间的相似性很高,包含了大量冗余数据。这些数据对算法提升泛化性的作用有限。如果去除这些极为相似的连续帧冗余数据,整个训练数据中的数据也只有几万个,仅仅覆盖 20 个左右的视频场景。这意味着有效的数据且测试分布一致的数据量并不多, 极大的增加了泛化难度。
换句话说,在训练过程中,大量测试的场景,并没有被算法系统直接学习过。这就需要算法具备强大的泛化性能,让算法学会“举一反三”。
2)场景复杂
此外,场景的复杂性无法一言以概。例如,摄像头的拍摄质量(清晰、抖动、模糊、扭曲)不一, 不同场景的布局不同 (例如:商场、走廊、马路、大厅、餐厅、公园等), 场景光线受到室内、室外、晴天、阴天的影响也比较大;甚至还存在摄像头俯拍、平拍、斜拍各个角度的差异、人体框的大小和远近不同、乃至人之间(人与物之间)还会经常发生相互遮挡。
解决了算法的泛化能力问题,克服了场景的复杂性,还有其他待解难题。
3)行为差异大
要知道,实际中行为分析是非常复杂的。即使是同一类行为,在不同时刻、不同场景也具有很大差异性。比如不同的人在不同时刻行走,速度、姿态和场景遮挡都会不同。或者同一行为具有多种不同的表现形式,比如单“打架”一个行为,可能包含踢人、扇耳光、拉扯等不同形式。


在多人场景甚至是密集场景下,除了要准确识别个人行为,还要标出人与人之间的互动,需要对每个人,在任何一个时间点上,给出此刻的行为判断。
4)连续动作和长时间动作捕捉
难通俗的说,读懂一个动作,需要长期、连续跟进,还需要结合上下文,才能做“阅读理解”。这就需要同时具备时间和空间的感知能力,准确的捕捉到人在前几秒每帧的动作, 并集合时间上动作发生的变化推测出行为。
以“挥拳”为例,整个过程经历了开始的靠近阶段、挥动拳脚的高潮阶段以及结束阶段。只有结合了人体每个时刻的姿态,才能更准确地判别出动作。

更重要的是,需要在短短两个月的时间内解决以上问题并夺冠,做到世界第一,没有极其深厚的技术积累、行业经验以及快速解决问题的能力,难之又难。
算法“凿山”, 算力“开路”,解锁智能未来
当然,也有一些业界人士毫不讳言:相较于人脸领域这种算法流程已经相对确定、算法框架的技术水准也趋于稳定的成熟领域而言,行为识别,尤其是人的行为识别,还处于学术界的摸索阶段,正因如此,很可能成为 AI 界的下一掘金地。
学术界的探索意味着没有多少前人指路,依图能在囊括如此复杂难题的行为识别赛道夺冠,并非偶然,除了对场景的深度理解、创新融合,还有硬实力的支撑。
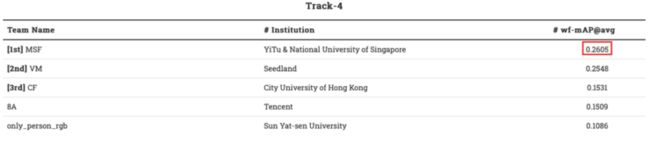
学术界常用 frame mAP (f-mAP@avg)来作为行为识别的评价指标,f-mAP@avg 代表的含义是以关键帧为单位,评判行为的位置与分类是否准确;与学术界对行为识别的考察指标不同,此次竞赛的评价标准是 wf-mAP@avg,这意味着更注重对难度较大的拥挤场景的考察,以及比较少见的动作的识别,同时对于人体框的定位的精确性要求也更高。
在短短两个月的挑战时间内,依图算法的指标达到了 [email protected],将以往学术界中的基准算法提升了近 3 倍。
掘金不易,凿山开路更不易。何况视频相较于图像的行为识别更加复杂,如何建模、视频帧之间的相关性仍是学术界一直存在的难题。
依图深谙这一点,优化算法来“凿山”。
研发团队透露,当应用场景明确后,在已知分析的对象是人体且明确知道要识别的类别后,就可以针对性的进行算法优化,通过算法定制化来提升算法性能,解决以往不能很好解决的问题。
此外,依图还创新性地将算法与场景进行了深度结合——一方面创新性的从视频中自动提取到丰富准确的场景信息,结合先进的行人检测、行人重识别算法,全面构建了人与人、人与场景、人与物之间在视频中的关系;另一方面,借助长期在智能城市场景下的算法积淀和对行业场景的理解,从需求出发,对比赛中要求的特定的 14 类任务进行了深度算法优化。
与其他队伍追求复杂的多模态融合策略不同,依图在此次竞赛中竟然是用单模型夺冠。也就是说,他们借助背景提取和分割算法,将行为的解析与场景结合,大大降低了问题难度。
敢在比赛中用单模型与其他多模型融合策略 PK,不外乎自信中带着点跟自己较真的狠劲,又一次展现了在有限的时间内依图算法可以做到极致。
算法“凿山”的依图,在开拓 AI 新领域的版图上一直策马长驱,离不开算力的“开路”。
此前,依图科技自主研发的全球首款云端视觉智能芯片求索(questcore™),可以提供强大算力,单路摄像头功耗不到 1W,开启了算法设计与芯片设计相结合的时代。
集合了高性能 AI 算法和芯片耦合设计优化的芯片平台,结合世界领先的行为识别算法的依图,将更有利于赋能智能城市、安全生产、智能商业等领域,打造新一代 AI 基础设施。
细观依图半年来的动态,在疫情爆发初期快速研发出业界首个新冠肺炎辅助诊断系统并投入全国的医院,同时,频频刷新顶级赛事的世界纪录,分别在贵阳和福州落地千万量级规模的城市级人工智能应用、通过全球权威隐私认证管理国际认证,发布语音超级本、入选工信部知识图谱案例集……技术愈加成熟、落地经验愈加丰富。
这些会给未来带来什么?借用依图科技创始人朱珑近期在《人民日报》署名文章中所说:未来 10 年,低阶感知智能将向高阶决策智能跃迁;人工智能将向具有高度不确定性、多任务融合、复杂推理等特点的高阶智能突破,有望实现看、听、理解、规划和控制等能力的重大跃升。