NOIP2015 复盘
D1T1 P2615 神奇的幻方
直接模拟,无需多说
NOIP2017初赛真题好像
#include
const int maxn = 45;
int a[maxn][maxn];
int n, x, y;//x means heng, y means shu
void print()
{
for(int i = 1; i <= n; i++)
{
for(int j = 1; j <= n; j++)
{
printf("%d", a[i][j]);
if(j != n) printf(" ");
}
printf("\n");
}
}
int main()
{
//freopen("in.txt", "r", stdin);
scanf("%d", &n);
a[x = 1][y = (n + 1) / 2] = 1;
for(int i = 2; i <= n * n; i++)
{
if(x == 1 && y != n) x = n, y++;
else if(y == n && x != 1) y = 1, x--;
else if(x == 1 && y == n) x++;
else
{
if(x - 1 >= 1 && y + 1 <= n && a[x - 1][y + 1] == 0) x--, y++;
else x++;
}
a[x][y] = i;
//print();
//printf("\n");
}
print();
return 0;
} D1T2 P2661 信息传递
我刚学OI的时候还不知道图论,就在想能用STL里面的集合处理解决,但是一直T。还是太naive啊!
把每个人都抽象成一个点,告诉别人生日就是连一条有向边,显然答案就是里面的最小环。
自己看到了三种做法:
- 大炮打蚊子,tarjan算法求最小的强联通分量。
- 带权冰茶姬求最小环。记录每一个点到其祖先的距离,如果两个点不同祖先就连起来,如果同个祖先就是两个人距离再加1。答案取最小值即可。
- 拓扑排序(自己起的)。因为入度为0的一定不成环,所以按照拓扑排序的做法一直删去,最后无法删除的时候就剩下真正的环了。并且因为每个人只有一条边连出去,所以每个人都只在一个环内,直接dfs找最小环就ok了。
给出第二种和第三种的代码(抄自luoguP2661题解区):
#include
#include
using namespace std;
int f[200002],d[200002],n,minn,last; //f保存祖先节点,d保存到其祖先节点的路径长。
int fa(int x)
{
if (f[x]!=x) //查找时沿途更新祖先节点和路径长。
{
int last=f[x]; //记录父节点(会在递归中被更新)。
f[x]=fa(f[x]); //更新祖先节点。
d[x]+=d[last]; //更新路径长(原来连在父节点上)。
}
return f[x];
}
void check(int a,int b)
{
int x=fa(a),y=fa(b); //查找祖先节点。
if (x!=y) {f[x]=y; d[a]=d[b]+1;} //若不相连,则连接两点,更新父节点和路径长。
else minn=min(minn,d[a]+d[b]+1); //若已连接,则更新最小环长度。
return;
}
int main()
{
int i,t;
scanf("%d",&n);
for (i=1;i<=n;i++) f[i]=i; //祖先节点初始化为自己,路径长为0。
minn=0x7777777;
for (i=1;i<=n;i++)
{
scanf("%d",&t);
check(i,t); //检查当前两点是否已有边相连接。
}
printf("%d",minn);
return 0;
} #include
#include
#include
#include
#include
#include
#include
using namespace std;
int n,t[200050],d[200050],ans=1000000000,r[200050];
void read(int& x){
x=0;
int y=1;
char ch=getchar();
while (ch<'0'||ch>'9'){
if (ch=='-') y=-1;
ch=getchar();
}
while (ch>='0'&&ch<='9'){
x=x*10+ch-'0';
ch=getchar();
}
x=x*y;
}
void dfs(int ti,int s,int l){
if (ti==s&&l){ //如果回到开始说明连成了环
ans=min(ans,l);
return;
}
if (!d[t[ti]]) {
d[t[ti]]=1; //标记
dfs(t[ti],s,l+1);
}
}
void rmove(int ti){ //删除ti
d[ti]=-1; //标记
r[t[ti]]--; //ti的下一个人的入度减一
if (!r[t[ti]]&&d[t[ti]]!=-1) rmove(t[ti]);
}
int main(){
memset(d,0,sizeof(d));
memset(r,0,sizeof(r)); //r[i]为第 i 个人的入度
int i;
read(n);
for (i=1;i<=n;i++){
read(t[i]);
r[t[i]]++;
}
for (i=1;i<=n;i++){
if (!r[i]&&d[i]!=-1) rmove(i); //如果 i 的入度为 0 且还未被删除,则删除i
}
for (i=1;i<=n;i++){
if (!d[i]){ //如果i还未搜过且未被删除,则从i开始搜索
//cout< D1T3 P2668 斗地主
大模拟大搜索毒瘤题!做完不会斗地主了
这道题总共有的出牌方式就是这几种(不然做不了):
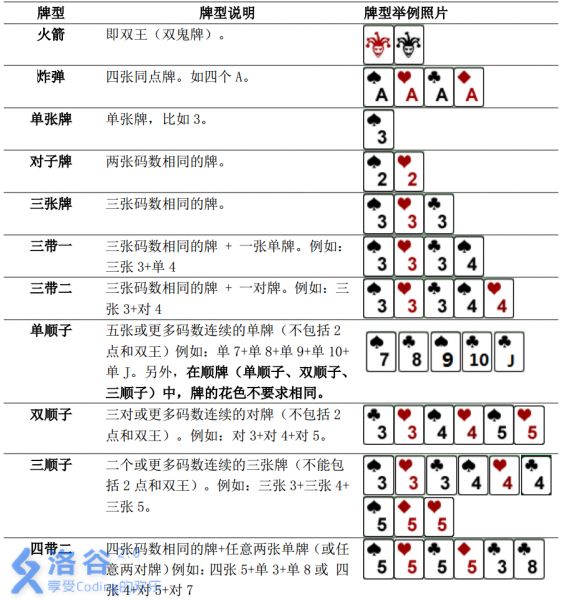
牌的储存不需要花色,只需要牌的号数。为了方便你可以钦定下标来对应牌,因为有A和2的存在挺麻烦的。
正确的思路是暴力枚大牌,能带的枚举带或不带,剩下的散牌就以单张或对子打出。整体套上回溯的框架。
王炸可以放到最后当对子或单张处理,就不预先处理了。
先依次考虑三顺子,双顺子和单顺子,暴力找到最长的合法顺子,直接出掉。
接下来考虑四带和三带。以四带为例,我们先找到四炸,然后分为三个部分,一部分出四带一对和四带两对,另一部分出四带一和四带二,最后别忘了炸弹。三带也是同理,可以单出三张牌。
剩下的其实就只有单张,对子和双王而已。我们把两个王看成同一张牌,跟其他的普通牌一样出了就行。
最后当某个状态中剩下的牌为0时,若比当前答案小就计入答案。
当然可以乱套一个最优性剪枝。
增强版比这个难多了!
代码:
#include
#include
#include
const int maxn = 25;
const int order[15] = {0, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 1, 2, 0};
const int INF = 0x3f3f3f3f;
int card[maxn];
int n, ans;
int read()
{
int ans = 0, s = 1;
char ch = getchar();
while(ch > '9' || ch < '0'){ if(ch == '-') s = -1; ch = getchar(); }
while(ch >= '0' && ch <= '9') ans = ans * 10 + ch - '0', ch = getchar();
return s *ans;
}
void dfs(int left, int res)
{
if(res >= ans) return;
if(left == 0)
{
ans = std::min(ans, res);
return;
}
for(int i = 1; i <= 11; i++)// san shun zi
{
if(card[order[i]] >= 3)
{
int p;
for(p = i + 1; p <= 12; p++)
{
if(card[order[p]] < 3) break;
}
p--;
if(p - i + 1 >= 2)
{
for(int j = i; j <= p; j++) card[order[j]] -= 3;
dfs(left - (p - i + 1) * 3, res + 1);
for(int j = i; j <= p; j++) card[order[j]] += 3;
}
}
}
for(int i = 1; i <= 10; i++)// shuang shun zi
{
if(card[order[i]] >= 2)
{
int p;
for(p = i + 1; p <= 12; p++)
{
if(card[order[p]] < 2) break;
}
p--;
if(p - i + 1 >= 3)
{
for(int j = i; j <= p; j++) card[order[j]] -= 2;
dfs(left - (p - i + 1) * 2, res + 1);
for(int j = i; j <= p; j++) card[order[j]] += 2;
}
}
}
for(int i = 1; i <= 8; i++)// dan shun zi
{
if(card[order[i]] >= 1)
{
int p;
for(p = i + 1; p <= 12; p++)
{
if(card[order[p]] < 1) break;
}
p--;
if(p - i + 1 >= 5)
{
for(int j = i; j <= p; j++) card[order[j]]--;
dfs(left - (p - i + 1), res + 1);
for(int j = i; j <= p; j++) card[order[j]]++;
}
}
}
for(int i = 1; i <= 13; i++)// si dai
{
if(card[order[i]] >= 4)
{
card[order[i]] -= 4;
for(int j = 1; j <= 14; j++)
{
if(card[order[j]] >= 2)
{
card[order[j]] -= 2;
for(int k = j; k <= 14; k++)
{
if(card[order[k]] >= 2)
{
card[order[k]] -= 2;
dfs(left - 8, res + 1);// si dai liang dui
card[order[k]] += 2;
}
}
dfs(left - 6, res + 1);// si dai yi dui
card[order[j]] += 2;
}
}
for(int j = 1; j <= 14; j++)
{
if(card[order[j]] >= 1)
{
card[order[j]]--;
for(int k = j; k <= 14; k++)
{
if(card[order[k]] >= 1)
{
card[order[k]]--;
dfs(left - 6, res + 1);// si dai liang zhang
card[order[k]]++;
}
}
dfs(left - 5, res + 1);// si dai yi zhang
card[order[j]]++;
}
}
dfs(left - 4, res + 1);// zha dan
card[order[i]] += 4;
}
}
for(int i = 1; i <= 13; i++)// san dai
{
if(card[order[i]] >= 3)
{
card[order[i]] -= 3;
for(int j = 1; j <= 14; j++)
{
if(card[order[j]] >= 2)
{
card[order[j]] -= 2;
dfs(left - 5, res + 1);// san dai yi dui
card[order[j]] += 2;
}
if(card[order[j]] >= 1)
{
card[order[j]]--;
dfs(left - 4, res + 1);// san dai yi zhang
card[order[j]]++;
}
}
dfs(left - 3, res + 1);// san zhang pai
card[order[i]] += 3;
}
}
for(int i = 1; i <= 14; i++)
{
if(card[order[i]] == 1 || card[order[i]] == 2)
{
left -= card[order[i]];
res++;
}
}
if(left == 0) ans = std::min(ans, res);
}
int main()
{
int T = read(); n = read();
while(T--)
{
memset(card, 0, sizeof card);
ans = INF;
for(int i = 1; i <= n; i++)
{
int x = read(), y = read();
card[x]++;
}
dfs(n, 0);
printf("%d\n", ans);
}
return 0;
} D2T1 P2678 跳石头
经典二分答案入门题。
先发现题目的单调性:当最短跳跃距离越小时,需要搬掉的石头越少,而当最短跳跃距离越大时,需要搬掉的石头就越多。
所以刚刚好移走最多的\(M\)块岩石时,最短跳跃距离最大。
所以确定二分答案的思路,开始思考如何判定一个答案\(mid\)是否符合条件?
check函数一般都是贪心的。当我们确定了最短跳跃距离时,在前方距离当前点小于最短跳跃距离的,都必须搬走,不然这个答案就不是最短跳跃距离。一次遍历之后看看总共需要搬走多少块,如果少于等于\(M\)则合法,多于的话就不合法。
代码:
#include
using namespace std;
const int maxn = 50005;
int l, n, m;
int d[maxn];
int ans;
bool check(int x)
{
int last = 0, cnt = 0;
for(int i = 1; i <= n; i++)
{
if(d[i] - d[last] < x)
{
cnt++;
}
else last = i;
}
if(cnt <= m) return true;
return false;
}
int main()
{
scanf("%d%d%d", &l, &n, &m);
d[0] = 0;
for(int i = 1; i <= n; i++) scanf("%d", &d[i]);
d[n + 1] = l;
int left = 1, right = l;
while(left <= right)
{
int mid = (left + right) >> 1;
if(check(mid)) ans = mid, left = mid + 1;
else right = mid - 1;
}
printf("%d\n", ans);
return 0;
} D2T2 P2679 子串
题意很简单,直接看就能理解。
先讲讲部分分:
\(k=1\)部分分,总共10pts。
显然直接暴力字符串匹配就行了。送的
\(k=2\)部分分,总共20pts。
由于数据很小,我们继续暴力。
暴力枚举第一次匹配多少位,剩下的再做一次匹配就行了。
\(k=m\)部分分,总共20pts。
这不就是经典的dp吗?
直接设
dp[i][j]为\(A\)字符串前\(i\)位,\(B\)字符串前\(j\)位的方案数。不管如何都有\(dp[i][j] +=dp[i-1][j]\)。
如果当前字符串相同的话就还能把\(dp[i-1][j-1]\)加上。
骗分代码:
#include
#define ll long long
const int maxn = 505;
const ll MOD = 1e9 + 7;
int n, m, p;
char a[maxn], b[maxn];
ll dp[maxn][maxn];
int main() {
scanf("%d %d %d", &n, &m, &p);
scanf("%s %s", a + 1, b + 1);
if(p == 1) {
ll ans = 0;
for(int i = 1; i <= n; i++) {
bool flag = true;
for(int j = 1; j <= m; j++) {
if(a[i + j - 1] != b[j]) {
flag = false; break;
}
}
if(flag) ans++;
}
printf("%lld\n", ans % MOD);
} else if(p == 2) {
ll ans = 0;
for(int t = 1; t < m; t++) {
for(int i = 1; i <= n; i++) {
bool flag = true;
for(int j = 1; j <= t; j++) {
if(a[i + j - 1] != b[j]) {
flag = false; break;
}
}
if(flag) {
//printf("1: t=%d i=%d\n", t, i);
for(int j = i + t; j <= n; j++) {
bool flag2 = true;
for(int k = 1; k <= m - t; k++) {
if(a[j + k - 1] != b[k + t]) {
flag2 = false; break;
}
}
if(flag2) {
//printf("2: j=%d\n", j);
ans++;
}
}
}
}
}
printf("%lld\n", ans % MOD);
} else if(p == m) {
for(int i = 1, j = 0; i <= n; i++) {
if(a[i] == b[1]) j++;
dp[i][1] = j;
}
for(int i = 1; i <= n; i++) {
for(int j = 2; j <= std::min(i, m); j++) {
dp[i][j] += dp[i - 1][j], dp[i][j] %= MOD;
if(a[i] == b[j]) dp[i][j] += dp[i - 1][j - 1], dp[i][j] %= MOD;
}
}
printf("%lld\n", dp[n][m]);
} else {
printf("I AK IOI\n");
}
return 0;
} 剩下的就是正解部分了。我参考了这个博客
设dp[i][j][k][0/1]为\(A\)字符串前\(i\)个字符,\(B\)字符串前\(j\)个字符,总共用\(k\)个子串,第\(i\)个字符有没有被用上的情况。
然后就有转移方程:
\(dp[i][j][k][0]=dp[i-1][j][k][0]+dp[i-1][j][k][1]\)
在\(a[i]=b[j]\)的前提下,有\(dp[i][j][k][1]=dp[i-1][j-1][k-1][0]+dp[i-1][j-1][k][1]+dp[i-1][j-1][k-1][1]\)
边界情况有:
\(dp[i][1][1][0]=\sum_{j=1}^{i-1}a[j]==b[1]\)
当\(a[i]=b[1]\)时,有\(dp[i][1][1][1] =1\)
最后你还需要滚动掉\(i\)那一维,具体实现是用now和pre两个下标轮着换。
用过的滚动数组记得清空。
代码:
#include
#define ll long long
const int maxn = 1005, maxm = 205;
const ll MOD = 1e9 + 7;
int n, m, p;
ll dp[2][maxm][maxm][2];
char a[maxn], b[maxm];
int main() {
scanf("%d %d %d", &n, &m, &p);
scanf("%s %s", a + 1, b + 1);
int cnt = 0;
int now = 0, pre = 1;
for(int i = 1; i <= n; i++) {
std::swap(now, pre);
dp[now][1][1][0] = cnt;
if(a[i] == b[1]) dp[now][1][1][1] = 1, cnt++;
for(int j = 2; j <= m; j++) {
for(int k = 1; k <= p; k++) {
if(a[i] == b[j]) dp[now][j][k][1] = ((dp[pre][j - 1][k - 1][1] + dp[pre][j - 1][k - 1][0]) % MOD + dp[pre][j - 1][k][1]) % MOD;
dp[now][j][k][0] = (dp[pre][j][k][0] + dp[pre][j][k][1]) % MOD;
}
}
for(int j = 1; j <= m; j++) {
for(int k = 1; k <= p; k++) {
dp[pre][j][k][0] = dp[pre][j][k][1] = 0;
}
}
}
printf("%lld\n", (dp[now][m][p][0] + dp[now][m][p][1]) % MOD);
return 0;
} D2T3 P2680 运输计划
个人感觉这道D2T3比上面的简单。
不考虑骗分了,因为我根本不会骗
把题意抽象一下,就是给你一个无根树,每条边有边权,有若干条路径,允许把一条边的边权置为0,让这些路径所需最长的时间最短。
显然需要考虑二分答案,求最大的最小。
接下来考虑如何判定一个答案\(mid\)是否满足。
我们先预处理出每条路径的长度,那些长度小于等于\(mid\)的就不要去考虑了,只考虑那些超时的路径。
接下来考虑把这些路径打上标记,我们试着贪心地减掉那些所有超时路径都走过的最长的一条边。
给路径打标记怎么做?把边权按进下面的点变成点权之后直接树上差分即可。
最后,最长路径的长度减去这条最优的边如果小于等于\(mid\),则成功,否则失败。
思路真的很简单。。。
代码:
#include
const int maxn = 300005;
const int INF = 0x3f3f3f3f;
struct Edges {
int next, to, weight;
} e[maxn << 1];
int head[maxn], tot;
int dep[maxn], size[maxn], wson[maxn], fa[maxn], dist[maxn];
int top[maxn], w[maxn];
int n, m;
int maxlen;
int diff[maxn];
struct Queries {
int u, v, lca, len;
} s[maxn];
int read() {
int ans = 0;
char ch = getchar();
while(ch > '9' || ch < '0') ch = getchar();
while(ch >= '0' && ch <= '9') ans = ans * 10 + ch - '0', ch = getchar();
return ans;
}
void link(int u, int v, int w) {
e[++tot] = (Edges){head[u], v, w};
head[u] = tot;
}
void dfs1(int u, int f) {
dep[u] = dep[f] + 1; fa[u] = f; size[u] = 1;
for(int i = head[u]; i; i = e[i].next) {
int v = e[i].to;
if(v == f) continue;
dist[v] = dist[u] + e[i].weight;
w[v] = e[i].weight;
dfs1(v, u);
size[u] += size[v];
if(size[wson[u]] < size[v]) wson[u] = v;
}
}
void dfs2(int u, int topf) {
top[u] = topf;
if(wson[u]) dfs2(wson[u], topf);
for(int i = head[u]; i; i = e[i].next) {
int v = e[i].to;
if(v == fa[u] || v == wson[u]) continue;
dfs2(v, v);
}
}
int getlca(int u, int v) {
while(top[u] != top[v]) {
if(dep[top[u]] < dep[top[v]]) std::swap(u, v);
u = fa[top[u]];
}
if(dep[u] > dep[v]) std::swap(u, v);
return u;
}
int cnt, maxd;
void dfs(int u) {
for(int i = head[u]; i; i = e[i].next) {
int v = e[i].to;
if(v == fa[u]) continue;
dfs(v);
diff[u] += diff[v];
}
if(diff[u] == cnt) maxd = std::max(maxd, w[u]);
}
bool check(int mid) {
memset(diff, 0, sizeof diff);
cnt = maxd = 0;
for(int i = 1; i <= m; i++) {
if(s[i].len > mid) {
diff[s[i].u]++; diff[s[i].v]++;
diff[s[i].lca] -= 2;
cnt++;
}
}
dfs(1);
if(maxlen - maxd <= mid) return true;
return false;
}
int main() {
n = read(), m = read();
int left = 0;
for(int i = 1; i < n; i++) {
int u = read(), v = read(), w = read();
left = std::max(left, w);
link(u, v, w); link(v, u, w);
}
dfs1(1, 0); dfs2(1, 1);
for(int i = 1; i <= m; i++) {
s[i].u = read(), s[i].v = read();
s[i].lca = getlca(s[i].u, s[i].v);
s[i].len = dist[s[i].u] + dist[s[i].v] - 2 * dist[s[i].lca];
maxlen = std::max(maxlen, s[i].len);
}
int right = maxlen; left = maxlen - left; int ans = -1;
while(left <= right) {
int mid = (left + right) / 2;
if(check(mid)) ans = mid, right = mid - 1;
else left = mid + 1;
}
printf("%d\n", ans);
return 0;
}