kerberos体系下的应用(yarn,spark on yarn)
kerberos 介绍
阅读本文之前建议先预读下面这篇博客
kerberos认证原理
Kerberos实际上一个基于Ticket的认证方式。Client想要获取Server端的资源,先得通过Server的认证;而认证的先决条件是Client向Server提供从KDC获得的一个有Server的Master Key进行加密的Session Ticket(Session Key + Client Info)
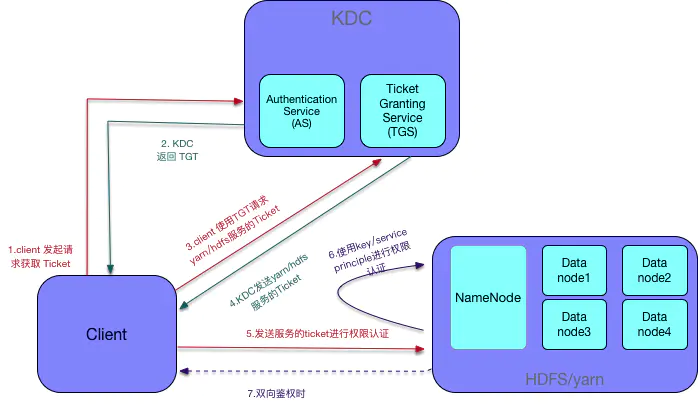
大体逻辑流程如下:
- Client向KDC申请TGT(Ticket Granting Ticket)。
- Client通过获得TGT向KDC申请用于访问Server的Ticket。
- Client最终向为了Server对自己的认证向其提交Ticket。
kerberos 中的几个概念
- Principals
简单的说, principals 类似于多用户系统中的用户名,每个server都对应一个 principals
principals由几个部分的字符串构成。
例如:
component1 / component2 @ REALM
- @ 后面是一个 principals 必不可少的部分 REALM,为大写英文字符。
- @ 前面是一个 principals 的具体身份,它可能由多个部分组成,使用/ 分割。
[email protected]
代表的是一个属于EXAMPLE.COM领域的用户reborn
这类principals 我们称之为 User Principals。
还有一类我们称之为 Service Principals。 它代表的不是具体的user,而是服务:
yarn/[email protected]
比如上面的这个, / 前面的部分为 yarn,说明它代表的是 yarn的服务,/ 后面的部分则是DNS域名,@后面的则是每个principals都必须有的 REALM
上面所提及的 Client通过获得TGT向KDC申请用于访问Server的Ticket 就是通过 Service Principals 来向KDC 来申请Ticket的。
- Keys 和 KeyTab
每个 principals 都有自己的 Master key 用来证明自己就是 principals的拥有者。同时 在 Client 、KDC、Server 对 TGT、Ticket加密。具体方式可才考开篇的 博客链接。
一般来说,User Principals的 key是用户密码,Service Principals的key是随机数串,他们都分别被存放在 KDC中一份,keytab 文件中一份。
keytab文件就是一个密码本,除非对该用户重新生成keytab,否则这个文件是不会过期的,使用该keytab即可以登录相应的principals。
获取TGT
从上面的概念上大家可以看出,为了访问有kerberos认证的服务,作为Client首先要先向KDC发起请求获取TGT 得到 KDC的授权,才继而才能申请对 service 的Ticket。
-
kerberos client 的安装
Client 所在的机器环境必须是 kerberos client 环境,具体的安装操作,网上有很多 �Installing Kerberos ,在安装的过程中,最普遍出现的问题就是默认的加解密方式 jce不支持,解决方式网上也有java-jce-hadoop-kerberos 要么改变加解密方式,要么给jre打补丁 -
使用命令行来获取TGT环境
这里列出几个简单的常用的命令:- kinit: 用来获取TGT的命令, 可以使用密码来向KDC申请,也可以直接使用keytab
kinit wanghuan70 Password for [email protected]:kinit -kt wanghuan70.keytab wanghuan70- kdestroy: 用来销毁当前的tgt情况
- klist: 用来展示当前的tgt情况
如果当前还没有申请TGT:
klist klist: Credentials cache file '/tmp/krb5cc_2124' not found如果已经通过 kinit 申请过了TGT:
-sh-4.2$ klist Ticket cache: FILE:/tmp/krb5cc_2124 Default principal: [email protected] Valid starting Expires Service principal 08/03/2017 09:31:52 08/11/2017 09:31:52 krbtgt/IDC.XXX- [email protected] renew until 08/10/2017 09:31:52klist 中的信息展示的很详细了,标明Client principal为 [email protected]
Service principal为 krbtgt/IDC.XXX- [email protected]
这个 Service principal 实际上是 上图中的 Tickt Granting Service(TGS)的principal。
TGT是有时效性的,超过过期日期就不可以再使用,但是可以在 renew时间之前 使用klist -r来刷新。
-
在代码中登录
首先要保证的是运行代码的机器上是有kerberos client 环境/** * User and group information for Hadoop. * This class wraps around a JAAS Subject and provides methods to determine the * user's username and groups. It supports both the Windows, Unix and Kerberos * login modules. */ @InterfaceAudience.LimitedPrivate({"HDFS", "MapReduce", "HBase", "Hive", "Oozie"}) @InterfaceStability.Evolving public class UserGroupInformation {在 hadoop-common 的工程下提供了如上的 UserGroupInformation 用于用户认证。我们在代码中只需要调用 其中的api即可,简单举例子,我们想用 [email protected] 这个 principal 来执行后续的代码, 只需要调用如下api:
UserGroupInformation.setConfiguration(configuration); System.setProperty("sun.security.krb5.debug", "true"); UserGroupInformation.loginUserFromKeytab("wanghuan70", "/home/wanghuan70/wanghuan70.keytab");该api会改变当前环境下的tgt。
如果我们想只对部分代码使用另一个principal来执行,那么可以使用如下api,然后调用doAs执行:ugi = UserGroupInformation.loginUserFromKeytabAndReturnUGI("hbase" , "hbase.keytab"); ugi.doAs(new PrivilegedExceptionAction() { @Override public Void run() throws Exception { try { Connection connection = ConnectionFactory.createConnection(conf); Admin admin = connection.getAdmin(); HTableDescriptor[] tables = admin.listTables(); for (HTableDescriptor descriptor : tables) { HTable hTable = new HTable(); hTable.setTableName(descriptor.getTableName().getNameAsString( )); Collection families = descriptor.getFamilies(); for (HColumnDescriptor family : families) { hTable.addFamily(family.getNameAsString()); } hTables.addhTable(hTable); } } catch (Exception ex) { logger.info("list hbase table internal failed: %s", ex); throw new Exception(ex); } return null; } });
在业务系统中访问需要kerberos认证的服务
这个比较简单,如上节例子中可以看到,只需要改变当前进程环境下的tgt即可,可以使用 命令行也可以在代码中实现。该部分暂时不讨论 tgt的过期问题,后续会扩展分析。
编写yarn application提交到kerberos认证的集群中
这类业务可能比较少,因为各种框架都自行实现了 xxx on yarn的代码,比如 spark on yarn、flink on yarn。但是也有一些热门的框架还没有来得及实现on yarn。 如 tf on yarn,storm on datax on yarn ,datax on yarn或者apache twill。我们可以自己动手去完成一个 yarn application的工程,继而可以推测 其他框架的on yarn是怎么去实现的。
官网的参考文件如下:
Hadoop: Writing YARN Applications
YARN应用开发流程
上述文章已经很详细的讲解了如何编写 yarn application,我们再这里不再累述,而我们的关注点在于提交到kerberos认证的集群中

在上面这个图大概的描述了我们的 yarn application的逻辑流程,这里需要注意的是:
- Client Node 需要使用 ApplicationClientProtocol(Client-RM之间的协议) 将应用提交给 RM。
- AM 需要使用 ApplicationMasterProtocol(AM-RM之间的协议)向RM申请资源。
- AM需要使用 ContainerManagementProtocol(AM-NM之间的协议)向NM发起启动container的命令
也就是说这三次的rpc通讯,我们的应用是需要与Yarn进行通讯的,在kerberos认证的系统中,换句话说,我们需要与yarn service 进行通讯的Ticket。
- Client Node 需要使用ClientNamenodeProtocol(DFSClient-HDFS协议)将应用需要的资源上传到HDFS上;
- AM (可能的操作)需要使用ClientNamenodeProtocol(DFSClient-HDFS协议)将资源下载下来;
- Container 需要使用ClientNamenodeProtocol(DFSClient-HDFS协议)将资源下载下来;
也就是说这三次的rpc通讯,我们的应用是需要与HDFS进行通讯的,在kerberos认证的系统中,换句话说,我们需要与hdfs service 进行通讯的Ticket。
还有一个问题需要注意的是,在应用中,我们发起RPC通讯 可能在不同的机器上这个时候如何进行构造相同的环境是我们这里需要表述的东西;
-
从上面的链接我们可以知道,Client是如何提交Application到RM,代码可如下:
ApplicationId submitApplication( YarnClientApplication app, String appName, ContainerLaunchContext launchContext, Resource resource, String queue) throws Exception { ApplicationSubmissionContext appContext = app.getApplicationSubmissionContext(); appContext.setApplicationName(appName); appContext.setApplicationTags(new HashSet()); appContext.setAMContainerSpec(launchContext); appContext.setResource(resource); appContext.setQueue(queue); return yarnClient.submitApplication(appContext); } Client调用 YarnClientApplication 向RM提交 ApplicationSubmissionContext
这里包含了- 应用的名称
- 所依赖的资源
- 提交的队列
- 还有一个重要的东西 ContainerLaunchContext 它是什么东西呢。
/** *
* *ContainerLaunchContextrepresents all of the information * needed by theNodeManagerto launch a container.It includes details such as: *
-
*
- {@link ContainerId} of the container. *
- {@link Resource} allocated to the container. *
- User to whom the container is allocated. *
- Security tokens (if security is enabled). *
- * {@link LocalResource} necessary for running the container such * as binaries, jar, shared-objects, side-files etc. * *
- Optional, application-specific binary service data. *
- Environment variables for the launched process. *
- Command to launch the container. *
我们的ApplucationMaster 本身上也是在Container里面执行的,所以也有这个上下文,构造函数如下:
public static ContainerLaunchContext newInstance( Mapcommands, Map 可以从构造函数来看到我们在设置Container中的环境、资源、执行命令等之外,还添加了 ByteBuffer tokens
* Set security tokens needed by this container. * @param tokens security tokens */ @Public @Stable public abstract void setTokens(ByteBuffer tokens);没错! 这个tokens就是我们传递给container里面的安全信息。
kerberos 和 Delegation token的关系需要说明一下,我们使用kerberos通过认证后,可以获取一个带有时效的委托token,如果我们把这个信息储存起来,在token没过期之前,使用这个token就可以直接连接服务,而无需再走kerberos那一套授权流程了。
那这个值,我们Client是从哪里获取并赋予给container的呢?
/** * setup security token given current user * @return the ByeBuffer containing the security tokens * @throws IOException */ private ByteBuffer setupTokens(FileSystem fs) throws IOException { DataOutputBuffer buffer = new DataOutputBuffer(); String loc = System.getenv().get("HADOOP_TOKEN_FILE_LOCATION"); if ((loc != null && loc.trim().length() > 0) || (!UserGroupInformation.isSecurityEnabled())) { this.credentials.writeTokenStorageToStream(buffer); } else { // Note: Credentials class is marked as LimitedPrivate for HDFS and MapReduce Credentials credentials = new Credentials(); String tokenRenewer = conf.get(YarnConfiguration.RM_PRINCIPAL); if (tokenRenewer == null || tokenRenewer.length() == 0) { throw new IOException( "Can't get Master Kerberos principal for the RM to use as renewer"); } // For now, only getting tokens for the default file-system. final org.apache.hadoop.security.token.Token tokens[] = fs.addDelegationTokens(tokenRenewer, credentials); if (tokens != null) { for (org.apache.hadoop.security.token.Token token : tokens) { LOG.info("Got dt for " + fs.getUri() + "; " + token); } } credentials.writeTokenStorageToStream(buffer); } return ByteBuffer.wrap(buffer.getData(), 0, buffer.getLength()); }不同的 xx on yarn可能代码写法不同,但是,思路都是一致的:
/** * Obtain all delegation tokens used by this FileSystem that are not * already present in the given Credentials. Existing tokens will neither * be verified as valid nor having the given renewer. Missing tokens will * be acquired and added to the given Credentials. * * Default Impl: works for simple fs with its own token * and also for an embedded fs whose tokens are those of its * children file system (i.e. the embedded fs has not tokens of its * own). * * @param renewer the user allowed to renew the delegation tokens * @param credentials cache in which to add new delegation tokens * @return list of new delegation tokens * @throws IOException */ @InterfaceAudience.LimitedPrivate({ "HDFS", "MapReduce" }) public Token[] addDelegationTokens(17/08/03 15:48:49 INFO client.LaunchCluster: tokenRenewer is yarn/[email protected] 17/08/03 15:48:49 INFO hdfs.DFSClient: Created HDFS_DELEGATION_TOKEN token 762341 for wanghuan70 on ha-hdfs:nn-idc 17/08/03 15:48:49 INFO client.LaunchCluster: Got dt for hdfs://nn- idc; Kind: HDFS_DELEGATION_TOKEN, Service: ha-hdfs:nn-idc, Ident: (HDFS_DELEGATION_TOKEN token 762341 for wanghuan70) 17/08/03 15:48:49 WARN token.Token: Cannot find class for token kind kms-dt 17/08/03 15:48:49 INFO client.LaunchCluster: Got dt for hdfs://nn- idc; Kind: kms-dt, Service: 10.214.129.150:16000, Ident: 00 0a 77 61 6e 67 68 75 61 6e 37 30 04 79 61 72 6e 00 8a 01 5d a7 14 e1 22 8a 01 5d cb 21 65 22 8d 0d d1 8e 8f d7我们这里是生成了访问hdfs的Token HDFS_DELEGATION_TOKEN 以及 在hdfs上的 KMS的token,
这里我们可以注意到,在上面的分析中,我们的AM也要去连接RM和NM,但是为什么这里没有去生成Token呢。我们可以看一下AM里面的 ** UserGroupInformation**的状态,我们通过在我们的 ApplicationMaster的启动类中,加入如下代码:LOG.info("isSecurityEnabled: {}", UserGroupInformation.getCurrentUser().isSecurityEnabled()); LOG.info("isLoginKeytabBased: {}", UserGroupInformation.getCurrentUser().isLoginKeytabBased()); LOG.info("isLoginTicketBased: {}", UserGroupInformation.getCurrentUser().isLoginTicketBased()); LOG.info("userName: {}", UserGroupInformation.getCurrentUser().getUserName()); for (org.apache.hadoop.security.token.Token token : UserGroupInformation.getCurrentUser().getTokens()) { LOG.info("Token kind is " + token.getKind().toString() + " and the token's service name is " + token.getService()); }让我们来看下AM端的日志:

可以看到 AM端的 初始UserGroupInformation是不带要tgt的, 也就是说,没办法进行kerberos认证流程,AM端不管是与yarn还是 hdfs的通讯都应该是使用Token的。在图片中Token列表中,我们看到出现了一个 名字叫 YARN_AM_RM_TOKEN ,这个并不是我们Client加进去的,但是可以确信的是AM使用该token与RM进行通讯,这个token哪里来的呢?
带着这个疑问,我们需要从Client开始扒拉一下代码了,在client端我们使用 YarnClient 将我们的启动的信息提交给了RM,这个YarnClient是经过kerberos认证的连接,那么我们可以看下RM端是怎么来处理这个 启动ApplicationMaster请求的。我们提交给RM的是一个名叫ApplicationSubmissionContext, RM要从中创建出ContainerLaunchContext:
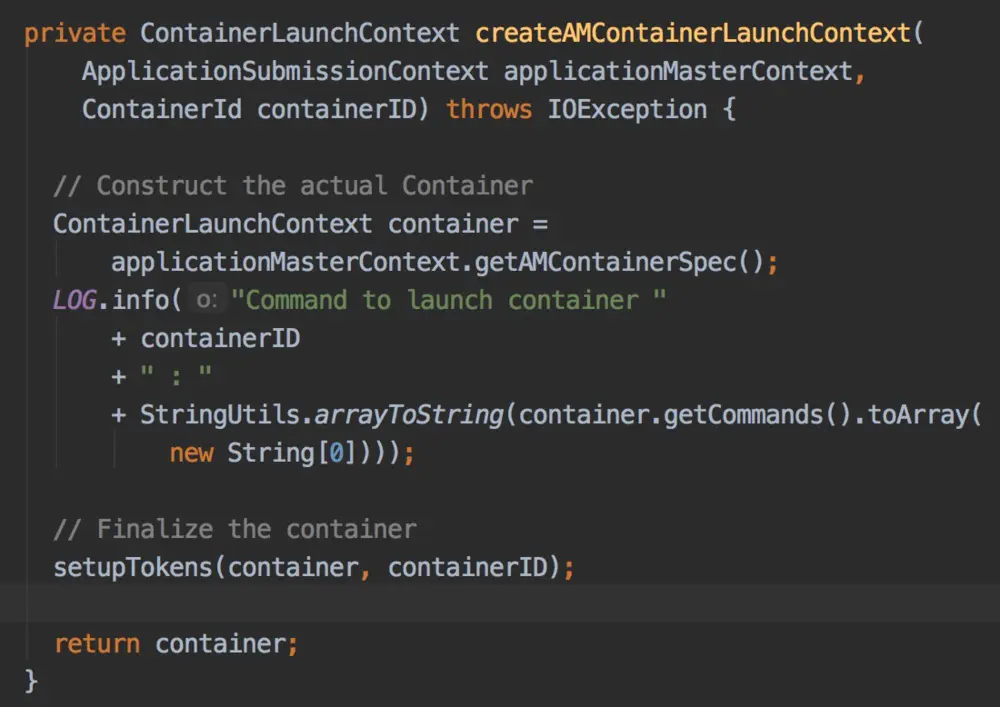
这RM端的createAMContainerLaunchContext中,我们查到了我们的疑问之处,这里出现了
// Finalize the container
setupTokens(container, containerID);
进去看看这个方法做了什么?:
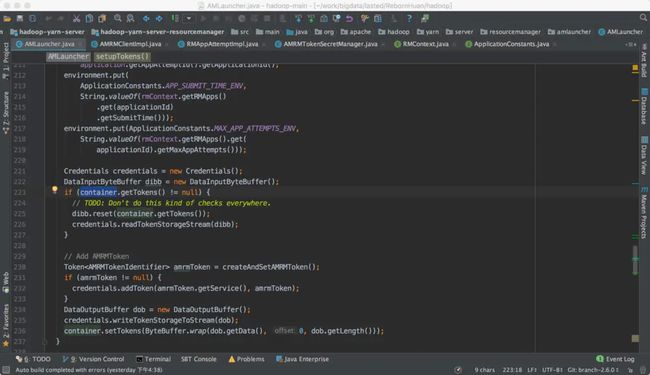

我们看到了我们想要的东西,container中新的tokens除了我们老的ContainerLaunchContext中我们从client传递过来的tokens,还额外添加了AMRMToken,到了这里我们解决了我们上面的一个疑问:
AM和RM通讯是使用Token来认证的,这个AMRMToken是RM端启动am的container的时候加塞进来的。
现在整理一下我们逻辑,启动之后AM使用** YARN_AM_RM_TOKEN来和RM通讯,使用 HDFS_DELEGATION_TOKEN**来和hdfs filesystem通讯,那么,AM是怎么通知NN来启动自己的 excutor的呢?不妨再看一下代码。
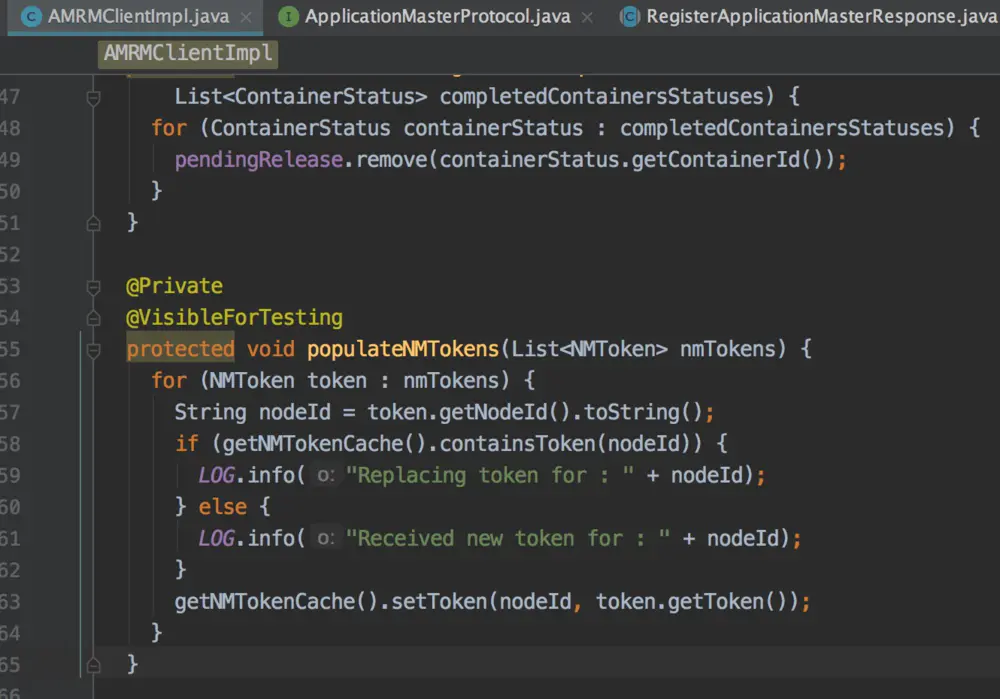
上面的图很明了了,nmTokens由RM提供给AM,在AM创建NMClientAsync的时候,
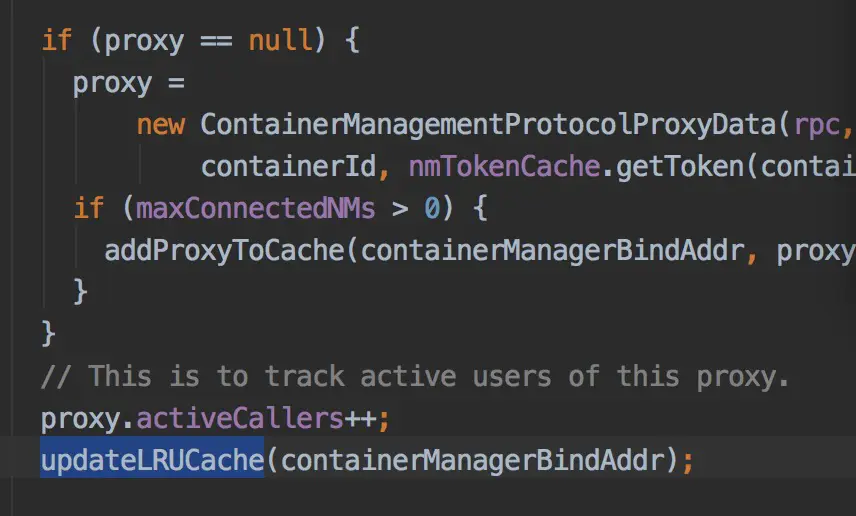
从单例 NMTokenCache 中获取到 nmTokens来进行连接NN。
到此,AM中的认证问题,我们已经整明白了,那边由AM,启动的其他的container的认证呢?,其实套路是一样的!
LOG.info("Launching a new container."
+ ", containerId=" + container.getId()
+ ", containerNode=" + container.getNodeId().getHost()
+ ":" + container.getNodeId().getPort()
+ ", containerNodeURI=" + container.getNodeHttpAddress()
+ ", containerResourceMemory="
+ container.getResource().getMemory()
+ ", containerResourceVirtualCores="
+ container.getResource().getVirtualCores()
+ ", command: " + command);
ContainerLaunchContext ctx = ContainerLaunchContext.newInstance(
localResources, env, Lists.newArrayList(command), null, setupTokens(), null);
appMaster.addContainer(container);
appMaster.getNMClientAsync().startContainerAsync(container, ctx);
只需要把AM中的token做传递即可。
长任务在kerberos系统中执行,以spark为例子
什么是长任务? 就是long-running services,长时间运行的任务,可能是流也可以不是。
那么为什么,要把长任务单独来说呢,因为从上述的yarn应用的描述,我们知道,am和excutor中使用的是token来访问hdfs和rm 的,token是有时效性的我们是知道的,那么,长时间运行,token肯定会失效,如果token失效的话,肯定就不能访问hdfs了。所以这个就是 long-running 任务需要考虑的东西。
spark on yarn模式,分为两种: 一种是 yarn client模式,一种是yarn cluster模式。一般来说业务上都会使用yarn cluster模式来执行,但是随着分析类工具的推出,比如zeppelin,jupter的使用, 常驻的yarn client 所以这两种模式都很重要。为了把事情讲清楚,我们两种方式分类来说明,本章节源码(1.6.0)通读可以较多。
yarn client 和 yarn cluter 说到底都是yarn application,那么client 和 cluster的区别到底区别在哪呢?-- Spark Driver是在本地运行还是在AM中来执行
扩展阅读
过往记忆
kerberos_and_hadoop
yarn cluster 模式

-
spark 使用SparkSubmitAction来提交作业

image.png
- prepareSubmitEnvironment 根据 master(YARN/STANDALONE/MESOS/LOCAL)和deployMode(CLIENT/CLUSTER)来得到我们需要执行的Class入口
- runMain 通过反射执行childMainClass中的main函数,因为这里是 cluster模式,所在这里执行的并不是用户的代码,而是org.apache.spark.deploy.yarn.Client
-
Client里面执行的是编译一个yarn application必要的步骤:
- 建立 yarnClient 用于和RM通信
- 向RM申请一个newApp
- 创建am需要的containerContext
- 创建ApplicationSubmissionContext并提交,amClass为
org.apache.spark.deploy.yarn.ApplicationMaster- Client完成;
-
ApplicationMaster
- 启动用户的代码线程:
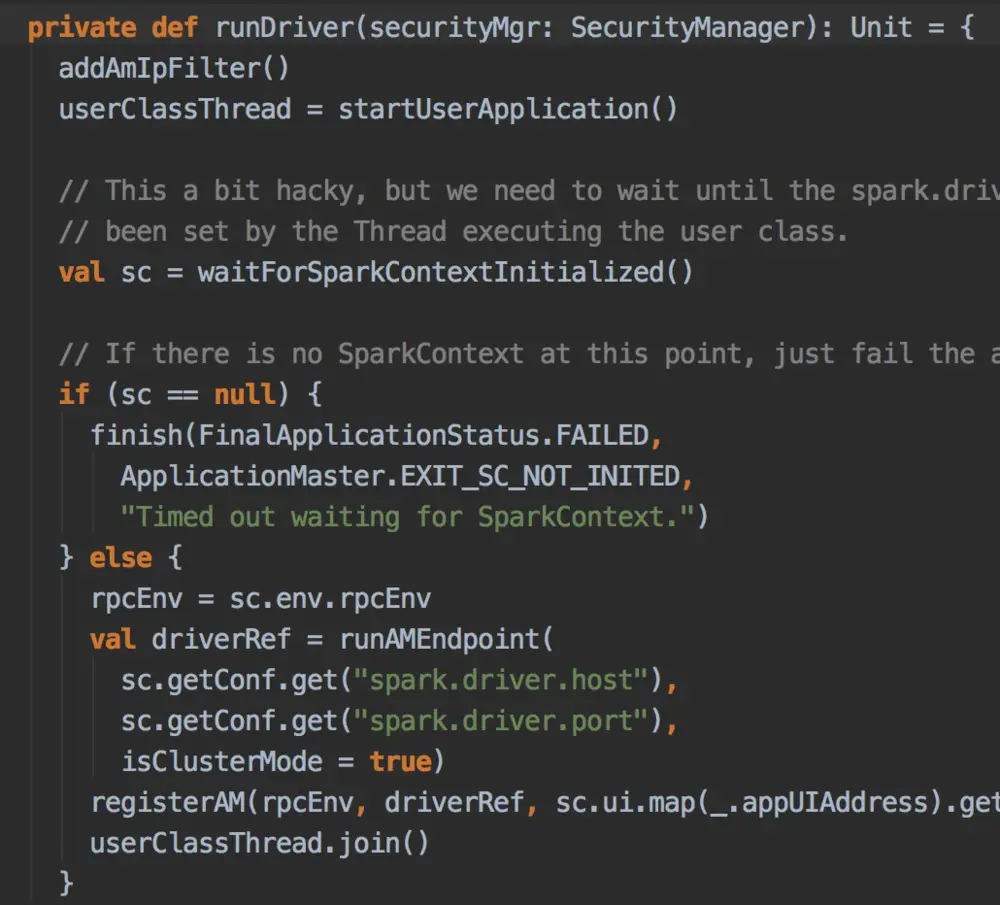
- 当SparkContext、Driver初始化完成的时候,通过amClient向ResourceManager注册ApplicationMaster
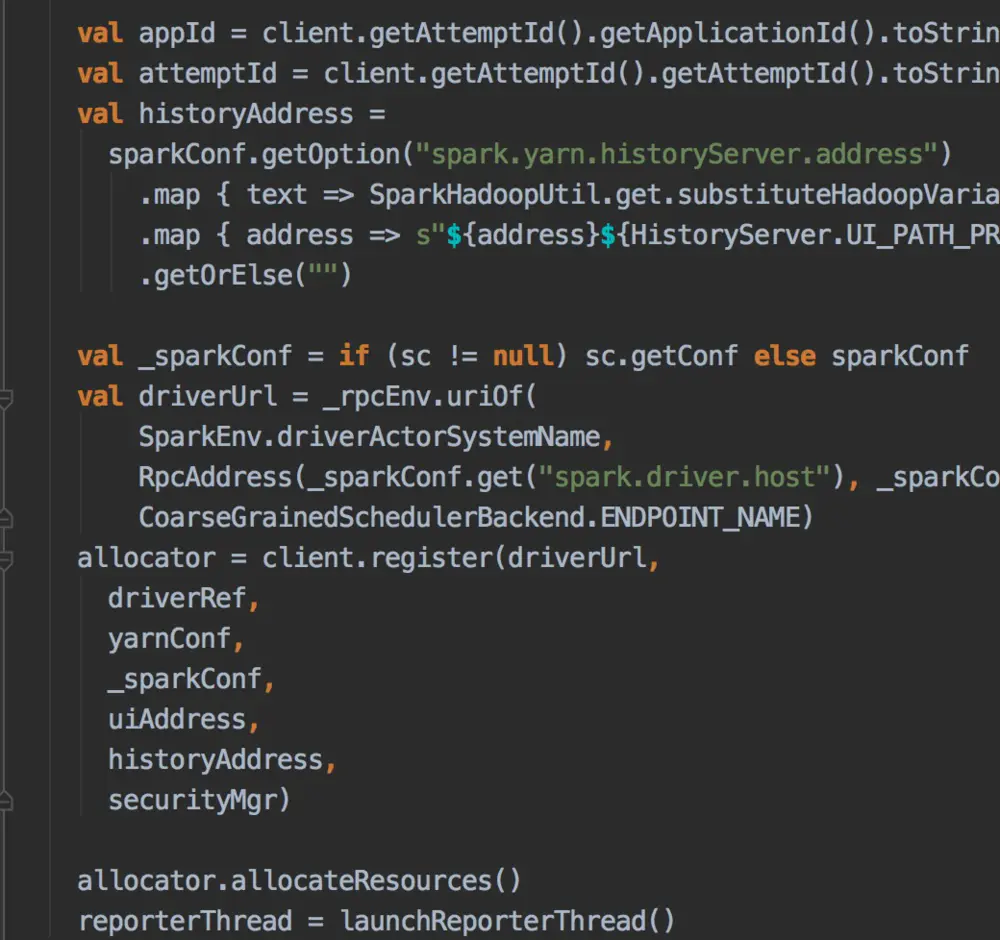
- 上面的逻辑是yarn application必须的步骤,我们注意来看看spark 如何来处理 token失效的:
// If the credentials file config is present, we must periodically renew tokens. So create // a new AMDelegationTokenRenewer if (sparkConf.contains("spark.yarn.credentials.file")) { delegationTokenRenewerOption = Some(new AMDelegationTokenRenewer(sparkConf, yarnConf)) // If a principal and keytab have been set, use that to create new credentials for executors // periodically delegationTokenRenewerOption.foreach(_.scheduleLoginFromKeytab()) }1.如果用户在提交应用的过程中,使用 --keytab 参数上传了kerberos认证文件的话,AM里面会启动一个线程专门用来处理,我们可以看看 AMDelegationTokenRenewer 里面都做了什么:
private[spark] def scheduleLoginFromKeytab(): Unit = { val principal = sparkConf.get("spark.yarn.principal") val keytab = sparkConf.get("spark.yarn.keytab") /** * Schedule re-login and creation of new tokens. If tokens have already expired, this method * will synchronously create new ones. */ def scheduleRenewal(runnable: Runnable): Unit = { val credentials = UserGroupInformation.getCurrentUser.getCredentials val renewalInterval = hadoopUtil.getTimeFromNowToRenewal(sparkConf, 0.75, credentials) // Run now! if (renewalInterval <= 0) { logInfo("HDFS tokens have expired, creating new tokens now.") runnable.run() } else { logInfo(s"Scheduling login from keytab in $renewalInterval millis.") delegationTokenRenewer.schedule(runnable, renewalInterval, TimeUnit.MILLISECONDS) } } // This thread periodically runs on the driver to update the delegation tokens on HDFS. val driverTokenRenewerRunnable = new Runnable { override def run(): Unit = { try { writeNewTokensToHDFS(principal, keytab) cleanupOldFiles() } catch { case e: Exception => // Log the error and try to write new tokens back in an hour logWarning("Failed to write out new credentials to HDFS, will try again in an " + "hour! If this happens too often tasks will fail.", e) delegationTokenRenewer.schedule(this, 1, TimeUnit.HOURS) return } scheduleRenewal(this) } } // Schedule update of credentials. This handles the case of updating the tokens right now // as well, since the renenwal interval will be 0, and the thread will get scheduled // immediately. scheduleRenewal(driverTokenRenewerRunnable) }private def writeNewTokensToHDFS(principal: String, keytab: String): Unit = { // Keytab is copied by YARN to the working directory of the AM, so full path is // not needed. // HACK: // HDFS will not issue new delegation tokens, if the Credentials object // passed in already has tokens for that FS even if the tokens are expired (it really only // checks if there are tokens for the service, and not if they are valid). So the only real // way to get new tokens is to make sure a different Credentials object is used each time to // get new tokens and then the new tokens are copied over the the current user's Credentials. // So: // - we login as a different user and get the UGI // - use that UGI to get the tokens (see doAs block below) // - copy the tokens over to the current user's credentials (this will overwrite the tokens // in the current user's Credentials object for this FS). // The login to KDC happens each time new tokens are required, but this is rare enough to not // have to worry about (like once every day or so). This makes this code clearer than having // to login and then relogin every time (the HDFS API may not relogin since we don't use this // UGI directly for HDFS communication. logInfo(s"Attempting to login to KDC using principal: $principal") val keytabLoggedInUGI = UserGroupInformation.loginUserFromKeytabAndReturnUGI(principal, keytab) logInfo("Successfully logged into KDC.") val tempCreds = keytabLoggedInUGI.getCredentials val credentialsPath = new Path(credentialsFile) val dst = credentialsPath.getParent keytabLoggedInUGI.doAs(new PrivilegedExceptionAction[Void] { // Get a copy of the credentials override def run(): Void = { val nns = YarnSparkHadoopUtil.get.getNameNodesToAccess(sparkConf) + dst hadoopUtil.obtainTokensForNamenodes(nns, freshHadoopConf, tempCreds) null } }) // Add the temp credentials back to the original ones. UserGroupInformation.getCurrentUser.addCredentials(tempCreds) val remoteFs = FileSystem.get(freshHadoopConf) // If lastCredentialsFileSuffix is 0, then the AM is either started or restarted. If the AM // was restarted, then the lastCredentialsFileSuffix might be > 0, so find the newest file // and update the lastCredentialsFileSuffix. if (lastCredentialsFileSuffix == 0) { hadoopUtil.listFilesSorted( remoteFs, credentialsPath.getParent, credentialsPath.getName, SparkHadoopUtil.SPARK_YARN_CREDS_TEMP_EXTENSION) .lastOption.foreach { status => lastCredentialsFileSuffix = hadoopUtil.getSuffixForCredentialsPath(status.getPath) } } val nextSuffix = lastCredentialsFileSuffix + 1 val tokenPathStr = credentialsFile + SparkHadoopUtil.SPARK_YARN_CREDS_COUNTER_DELIM + nextSuffix val tokenPath = new Path(tokenPathStr) val tempTokenPath = new Path(tokenPathStr + SparkHadoopUtil.SPARK_YARN_CREDS_TEMP_EXTENSION) logInfo("Writing out delegation tokens to " + tempTokenPath.toString) val credentials = UserGroupInformation.getCurrentUser.getCredentials credentials.writeTokenStorageFile(tempTokenPath, freshHadoopConf) logInfo(s"Delegation Tokens written out successfully. Renaming file to $tokenPathStr") remoteFs.rename(tempTokenPath, tokenPath) logInfo("Delegation token file rename complete.") lastCredentialsFileSuffix = nextSuffix }代码很长,逻辑可以概括为如下:
1.根据token时效判断是否需要进行token刷新行为;
2.使用hdfs上的keytab获取新的tgt -- keytabLoggedInUGI
3.在新的UserGroupInformation下,重新获取新的 HDFS_DELEGATION_TOKEN 加到当前的 UserGroupInformation中,这里大家留意一下
freshHadoopConf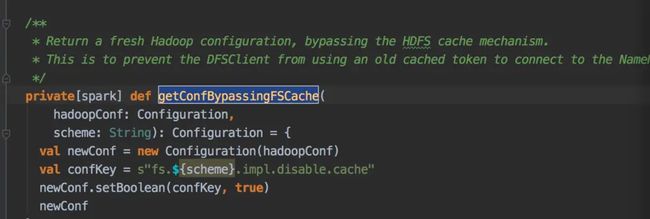
我们后面紧接着会具体讲 如何与hdfs通讯的时候分析一下https://issues.apache.org/jira/browse/HDFS-9276
4.将新的token信息更新到hdfs目录下。-
Excutor的启动的类为org.apache.spark.executor.org.apache.spark.executor
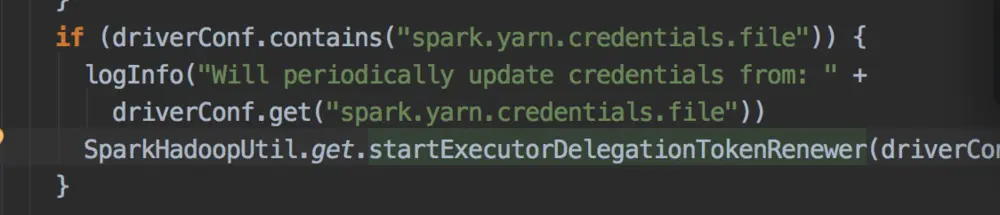
如果需要刷新token,excutor会启动一个更新token程序
def updateCredentialsIfRequired(): Unit = { try { val credentialsFilePath = new Path(credentialsFile) val remoteFs = FileSystem.get(freshHadoopConf) SparkHadoopUtil.get.listFilesSorted( remoteFs, credentialsFilePath.getParent, credentialsFilePath.getName, SparkHadoopUtil.SPARK_YARN_CREDS_TEMP_EXTENSION) .lastOption.foreach { credentialsStatus => val suffix = SparkHadoopUtil.get.getSuffixForCredentialsPath(credentialsStatus.getPath) if (suffix > lastCredentialsFileSuffix) { logInfo("Reading new delegation tokens from " + credentialsStatus.getPath) val newCredentials = getCredentialsFromHDFSFile(remoteFs, credentialsStatus.getPath) lastCredentialsFileSuffix = suffix UserGroupInformation.getCurrentUser.addCredentials(newCredentials) logInfo("Tokens updated from credentials file.") } else { // Check every hour to see if new credentials arrived. logInfo("Updated delegation tokens were expected, but the driver has not updated the " + "tokens yet, will check again in an hour.") delegationTokenRenewer.schedule(executorUpdaterRunnable, 1, TimeUnit.HOURS) return } } val timeFromNowToRenewal = SparkHadoopUtil.get.getTimeFromNowToRenewal( sparkConf, 0.8, UserGroupInformation.getCurrentUser.getCredentials) if (timeFromNowToRenewal <= 0) { executorUpdaterRunnable.run() } else { logInfo(s"Scheduling token refresh from HDFS in $timeFromNowToRenewal millis.") delegationTokenRenewer.schedule( executorUpdaterRunnable, timeFromNowToRenewal, TimeUnit.MILLISECONDS) } } catch { // Since the file may get deleted while we are reading it, catch the Exception and come // back in an hour to try again case NonFatal(e) => logWarning("Error while trying to update credentials, will try again in 1 hour", e) delegationTokenRenewer.schedule(executorUpdaterRunnable, 1, TimeUnit.HOURS) } }逻辑也很明了:
- 从 hdfs相应目录读取由AM写入的token文件信息;
- 更新到自己的ugi中;
这里也需要 对

image.png
也和上述https://issues.apache.org/jira/browse/HDFS-9276有关。
至此,实际上启动的过程大概就是这样,那么现在我们需要对我们关心的问题来具体分析:
-
我们的应用是怎么连接到hdfs的?
在hadoop api中提供 FileSystem 接口用于与各种文件系统进行连接,HDFS也不除外,其具体类为DistributedFileSystem,进入这个类,可以看到连接hdfs的客户端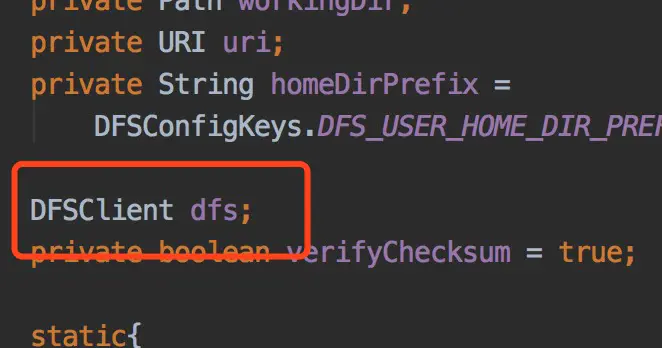
image.png
DEBUG [2017-07-28 13:24:46,255] ({main} DFSClient.java[]:455) - dfs.client.use.legacy.blockreader.local = false DEBUG [2017-07-28 13:24:46,255] ({main} DFSClient.java[ ]:458) - dfs.client.read.shortcircuit = false DEBUG [2017-07-28 13:24:46,256] ({main} DFSClient.java[ ]:461) - dfs.client.domain.socket.data.traffic = false DEBUG [2017-07-28 13:24:46,256] ({main} DFSClient.java[ ]:464) - dfs.domain.socket.path = /var/run/hdfs- sockets/dn DEBUG [2017-07-28 13:24:46,282] ({main} HAUtil.java[cloneDelegationTokenForLogicalUri]:329) - No HA service delegation token found for logical URI hdfs://nn-idc DEBUG [2017-07-28 13:24:46,282] ({main} DFSClient.java[ ]:455) - dfs.client.use.legacy.blockreader.local = false DEBUG [2017-07-28 13:24:46,282] ({main} DFSClient.java[ ]:458) - dfs.client.read.shortcircuit = false DEBUG [2017-07-28 13:24:46,283] ({main} DFSClient.java[ ]:461) - dfs.client.domain.socket.data.traffic = false DEBUG [2017-07-28 13:24:46,283] ({main} DFSClient.java[ ]:464) - dfs.domain.socket.path = /var/run/hdfs- sockets/dn DEBUG [2017-07-28 13:24:46,285] ({main} RetryUtils.java[getDefaultRetryPolicy]:75) - multipleLinearRandomRetry = null DEBUG [2017-07-28 13:24:46,290] ({main} ClientCache.java[getClient]:63) - getting client out of cache: org.apache.hadoop.ipc.Client@416b681c DEBUG [2017-07-28 13:24:46,514] ({main} NativeCodeLoader.java[ ]:46) - Trying to load the custom-built native-hadoop library... DEBUG [2017-07-28 13:24:46,515] ({main} NativeCodeLoader.java[ ]:50) - Loaded the native-hadoop library DEBUG [2017-07-28 13:24:46,520] ({Thread-36} DomainSocketWatcher.java[run]:453) - org.apache.hadoop.net.unix.DomainSocketWatcher$2@dbe5911: starting with interruptCheckPeriodMs = 60000 DEBUG [2017-07-28 13:24:46,524] ({main} DomainSocketFactory.java[ ]:110) - Both short-circuit local reads and UNIX domain socket are disabled. DEBUG [2017-07-28 13:24:46,530] ({main} DataTransferSaslUtil.java[getSaslPropertiesResolver]:183) - DataTransferProtocol not using SaslPropertiesResolver, no QOP found in configuration for dfs.data.transfer.protection DEBUG [2017-07-28 13:24:46,534] ({main} Logging.scala[logDebug]:62) - delegation token renewer is: yarn/[email protected] INFO [2017-07-28 13:24:46,535] ({main} Logging.scala[logInfo]:58) - getting token for namenode: hdfs://nn- idc/user/wanghuan70/.sparkStaging/application_1499341382704_7 8490 DEBUG [2017-07-28 13:24:46,537] ({main} Client.java[ ]:434) - The ping interval is 60000 ms. DEBUG [2017-07-28 13:24:46,537] ({main} Client.java[setupIOstreams]:704) - Connecting to ctum2f0302002.idc.xxx-group.net/10.214.128.51:8020 DEBUG [2017-07-28 13:24:46,538] ({main} UserGroupInformation.java[logPrivilegedAction]:1715) - PrivilegedAction as:[email protected] (auth:KERBEROS) from:org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Cli ent.java:725) DEBUG [2017-07-28 13:24:46,539] ({main} SaslRpcClient.java[sendSaslMessage]:457) - Sending sasl message state: NEGOTIATE DEBUG [2017-07-28 13:24:46,541] ({main} SaslRpcClient.java[saslConnect]:389) - Received SASL message state: NEGOTIATE auths { method: "TOKEN" mechanism: "DIGEST-MD5" protocol: "" serverId: "default" challenge: "realm=\"default\",nonce=\"FsxK1F2sX0QvIYFTYdwpNFYlB+uCuXr x7se1tCAa\",qop=\"auth\",charset=utf-8,algorithm=md5-sess" } auths { method: "KERBEROS" mechanism: "GSSAPI" protocol: "hdfs" serverId: "ctum2f0302002.idc.xxx-group.net" } DEBUG [2017-07-28 13:24:46,541] ({main} SaslRpcClient.java[getServerToken]:264) - Get token info proto:interface org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolPB info:@org.apache.hadoop.security.token.TokenInfo(value=class org.apache.hadoop.hdfs.security.token.delegation.DelegationToken Selector) DEBUG [2017-07-28 13:24:46,542] ({main} SaslRpcClient.java[getServerPrincipal]:291) - Get kerberos info proto:interface org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolPB info:@org.apache.hadoop.security.KerberosInfo(clientPrincipal=, serverPrincipal=dfs.namenode.kerberos.principal) DEBUG [2017-07-28 13:24:46,545] ({main} SaslRpcClient.java[createSaslClient]:236) - RPC Server's Kerberos principal name for protocol=org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProto colPB is hdfs/[email protected] GROUP.NET DEBUG [2017-07-28 13:24:46,546] ({main} SaslRpcClient.java[createSaslClient]:247) - Creating SASL GSSAPI(KERBEROS) client to authenticate to service at ctum2f0302002.idc.wanda-group.net DEBUG [2017-07-28 13:24:46,547] ({main} SaslRpcClient.java[selectSaslClient]:176) - Use KERBEROS authentication for protocol ClientNamenodeProtocolPB DEBUG [2017-07-28 13:24:46,564] ({main} SaslRpcClient.java[sendSaslMessage]:457) - Sending sasl message state: INITIATE 这里摘录了部分debug日志,这样就很好的逻辑描述清楚了
- DFSClient 通过 ClientNamenodeProtocolPB协议来和namenode建立联系。底层RPC在简历连接的时候如果有token则使用token进行建立连接,如果没有token再进行kerberos认证后建立连接。

image.png
在dfsclient中使用 DelegationTokenSelector来选取即id为 HDFS_DELEGATION_TOKEN的token。在我们没有使用YarnSparkHadoopUtil.get.obtainTokensForNamenodes(nns, hadoopConf, credentials)当前的UGI中是不能使用token进行连接的。
在初始化 DFSClient 中,使用的 dfs.client.failover.proxy.provider 是 org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider 在构造过程中会调用// The client may have a delegation token set for the logical // URI of the cluster. Clone this token to apply to each of the // underlying IPC addresses so that the IPC code can find it. HAUtil.cloneDelegationTokenForLogicalUri(ugi, uri, addressesOfNns);这里的作用在 HA mode下很重要,在HA mode的形式下,我们使用 obtainTokensForNamenodes 生成的 token的 service name 为 ha-hdfs:nn-idc
DFSClient.java[getDelegationToken]:1066) - Created HDFS_DELEGATION_TOKEN token 735040 for wanghuan70 on ha-hdfs:nn-idc
但是呢,在rpc连接的时候,使用的host或者ip加port的 service name来寻找 token的,换句话说,即时我们获取了token,saslRPC在连接的时候也找不到,这里就是使用 HAUtil.java[cloneDelegationTokenForLogicalUri]:329) 将 service name为ha-hdfs:nn-idc 拷贝成和 ip对应的token,这样
saslRPC才可以顺利使用token。但是要注意的是 只有在DFSClient初始化过程中,才会进行这个token的拷贝。 可是呢,
image.png
在获取 FileSystem的时候,默认的情况下,这个实例会被cache的,也就是说,DFSClient就不会初始化了,我们更新的token就不会使用 HAUtil.java[cloneDelegationTokenForLogicalUri]:329) 将 service name为ha-hdfs:nn-idc 拷贝成和 ip对应的token,这样即使这样
saslRPC使用仍然是老token,就会过期掉,这就是 https://issues.apache.org/jira/browse/HDFS-9276的描述的问题。针对这个问题,hadoop版本升级后可以修复,还有一个方法就是,如果不cache的话,就会调用 DFSClient 初始化方法,所以,我们可以设置这个默认参数为 true。 -
spark的excutor并不一定一开始就是给定的,是动态的增加的,也就是说一个长应用的AM可能在很长的一段时间内都会和 RM通讯,我们回顾一下上面的内容,我们知道AMRMToken是RM在启动AM的时候下发的,而且,我们在刷新机制中,仅仅刷新了HDFS_DELEGATION_TOKEN,那边怎么来处理AMRMToken过期呢,这spark里面其实并没有在对此做处理,为什么呢?
建立的saslRPC连接只有空闲时间超过10s中,连接才会被关闭,如果我们的AM保持着对RM的心跳,也就不需要重新与RM建立连接(读者可以推演一下RM发生准备切换的情景)。
yarn client 模式

image.png
这里只讲一下和 yarn cluster的不同之处:
-
因为Spark Driver是在本地执行,所以在使用SparkSubmit提交的时候 runMain 通过反射执行childMainClass中的main函数,这里的childMainClass 是用户的代码。
-
在SparkContext生成的过程,根据提交方式,使用YarnClientSchedulerBackend来调度
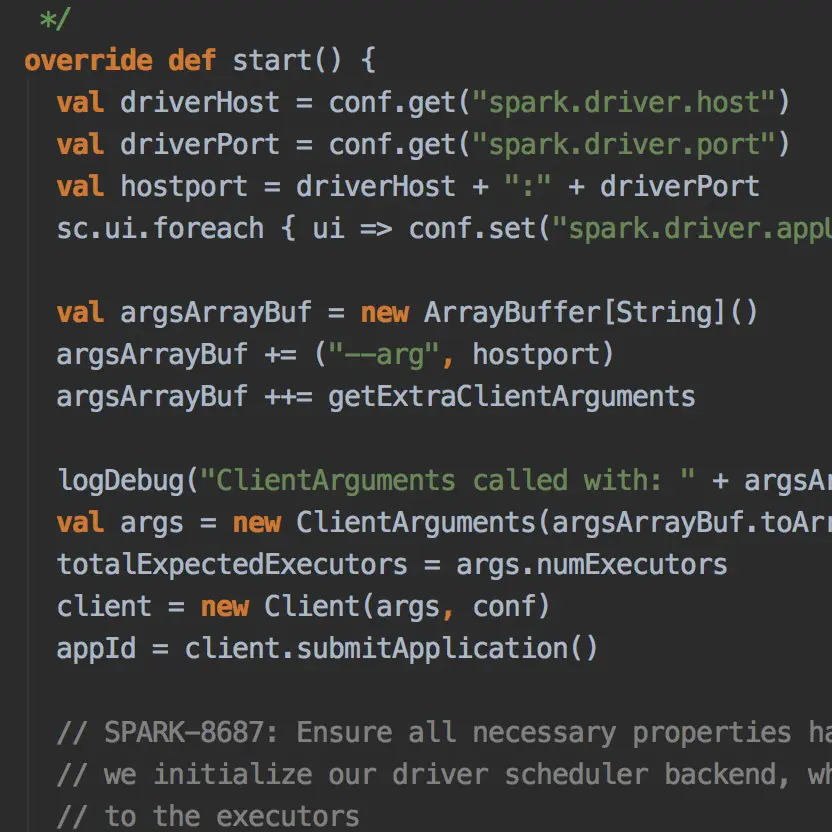
image.png
-
因为用户的代码已经本地启动了,那么启动的AM里面执行什么呢?
什么业务代码都不执行,只负责向RM申请资源。 -
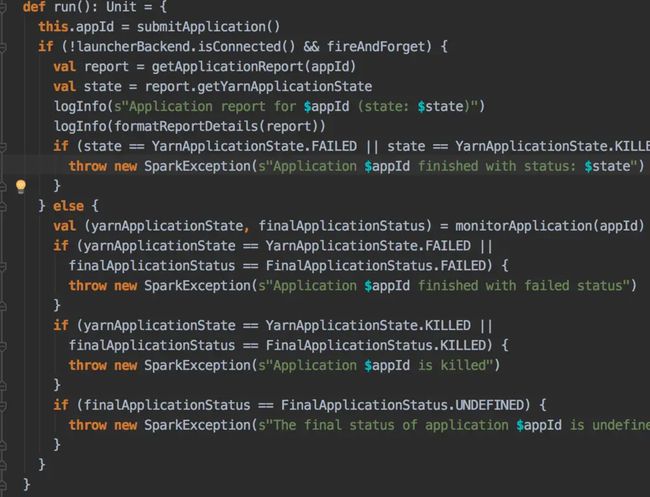
Driver 因为需要获悉application的执行情况,启动了一个监控线程,每1s钟向RM咨询一次状态,也不需要刷新token

image.png
我们上面所说的 hdfs的token刷新都是在用户使用 --keytab的方式提交的,如果不是以这种方式提交的长任务,token肯定会失效,会报错。