第一讲一条SQL查询是如何执行的?
问在开篇:
1、MySQL的基础架构是什么?
2、一条查询sql语句执行后,返回查询结果,MySQL的内部经历了什么?
一、MySQL基础架构
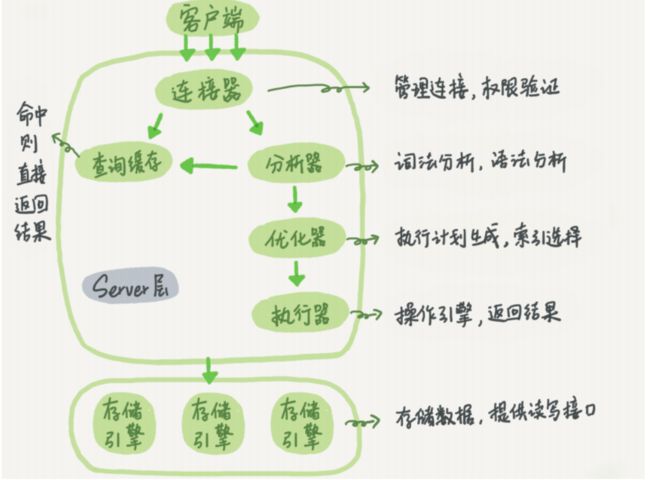
由上图可见MySQL的基础架构可以归类为三层,第一层客户端、第二层server层、第三层存储引擎层 明白了这些之后,需要考虑的就是每一层具体的含义,也就是说每一层要做的工作有哪些
客户端&&连接器:要想搞清楚一条查询sql如何执行的那么必然条件就是需要连接数据库,而客户端和连接器则就是为了让我们更好的操作数据库的连接
Server层:从图上可知,server层包含了很多东西如连接器、MySQL缓存、分析器、优化器、执行器等,但是这并不是他的全部,server包含了MySQL的所有的内置函数(时间、日期、加密函数等),所有的跨存储引擎的功能都在这一层当中,所以一条查询语句的执行过程必然在server中可以找到 答案
存储引擎层:这一层就很容易理解了,这就是MySQL存储和提取数据的地方,也可以把他理解为数据的仓库,存储引擎我们并不陌生,如InnoDB、MyISAM
由此我们就可以大概的清楚MySQL的基础架构,这对我们下面思考的问题有决定性的帮助
二、一条查询的sql执行的过程之"五步成诗"
示例语句:select * from T where pid = 10;
第一步:建立连接
上文中我们提到了server中的内容,并且解释了连接器的作用就是为了连接客户端,并且获取当前用户的权限,如果你看过MySQL中的user表你觉得不会陌生权限是什么
第二步:查询缓存有无
当我们和数据库建立连接之后,我们键入一条查询的sql,这个时候MySQL会像我们经手的项目一样,首先到缓存中看看这条语句有没有被执行过,如果有的话则直接返回结果,如果没有的则进行下一步但是在执行完整个过程之后结果还是会被放到缓存中的,也就是说缓存中存放的是你所有的查询语句的key-value,在MySQL中缓存同样以key-value的形式存在
key:查询的sql语句 value:查询结果
衍生问题一:为什么不大量的使用查询缓存
在第二步中介绍了MySQL查询语句执行会先查询缓存,那么你一定会有一个问题,为什么不大量的使用缓存来提升效率?根本原因在于缓存的生存周期问题 就像我们的项目中的缓存一样,他不是永久有效的,他是有生命周期的,除非我们做的静态缓存,不会有数据上的改变,但是MySQL中缓存的失效更加容易,MySQL中的缓存失效非常的频繁,只要该表存在更新,那么该表上的所有查询缓存都会失效,这样的话,我们如果大量的使用缓存反而降低了效率
第三步:分析器--词法分析,语法分析
这一步就是承接上文中提到的,一条查询sql没有在缓存中找到对应的结果之后要执行的,在这一步中,首先要做的就是词法分析,MySQL先将关键词过滤出来,也就是说要识别出查询哪张表,哪一行的数据,然后再进行语法分析
语法分析:我们在实际的应用中遇到的sql错误都是在分析器中发生的,比如select少个t 或者是查询的字段不在要查的表中,这些报错都是经过语法分析之后返回给我的错误信息,所以在查询的时候的错误,其实并没有到实际的数据上
第四步:优化器
在查询的sql没有任何问题的情况下,MySQL会通过优化器来优化你的sql ,这其中包含了应该使用哪一个索引,join的时候应该先查谁,在查谁,而我们在面试的过程中经常会被问道,MySQL的优化方案,涉及到业务上的也就是写一个优雅的sql语句了,sql语句优雅了,那么优化器就更好的执行,这样不失为一种提升效率的办法
第五步:执行器
顾名思义,执行器就是执行我们键入的查询sql,但是他在执行之前还是会先判断一下你有没有对这个表的查询权限,如果没有的话则直接返回没有权限。
有无索引:比如我们的查询语句如下
select * from T where pid = 10
没有索引的情况下
取这个表的第一行然后 判断id是否等于10,如果是存到结果集中,如果不是则跳过,然后再取下一行,在进行判断,知道这个表的最后一行,然后执行器将上述中过程中的所有满足条件的数据返回给客户端,也就是我们看到的符合条件的结果集
有索引的情况下
取满足条件的第一行,然后再取满足条件的第二行,知道最后一个满足条件的数据,然后执行器会将该过程中的所有数据返回个客户端
这也是为什么说索引可以提升查询效率,但是索引也有自己的使用原则,后续接着探讨
问在最后
MySQL连接器建立的连接是一只保持连接状态吗?
答案当然不是,MySQL连接器建立的连接分为长连接,短链接,短链接就是执行几次查询之后就断开了,需要再次重连,长连接就是当客户端持续有操作的时候一直保持链接状态,有点像websocket,但是客户端长时间没有反应的话也是会断开的默认时间是8小时,可以通过参数wait_timeout来指定时长