关于Transformer你需要知道的都在这里------从论文到代码深入理解BERT类模型基石(包含极致详尽的代码解析!)
UPDATE
2.26.2020
为代码解析部分配上了Jay Ammar The Illustrated GPT-2 的图示,为想阅读源码的朋友缓解疼痛!
深入理解Transformer------从论文到代码
- UPDATE
- 1. Attention Is All You Need
- 1.1 摘要
- 1.2 介绍
- 1.3 背景
- 1.4 模型结构
- 1.5.1 编码器与解码器
- 1.5.1.1 编码器
- 1.5.1.2 解码器
- 1.5.2 注意力
- 1.5.2.1 缩放点乘注意力
- 1.5.2.2 多头注意力
- 1.5.2.3 注意力在我们模型中的应用
- 1.5.2.4 位置前馈网络
- 1.5.2.5 Embeddings 和 Softmax
- 1.5.2.6 位置嵌入
- 1.5.3 为什么用自注意力
- 1.6 训练
- 1.6.1 优化
- 1.6.2 正则化
- 2. The Illustrated Transformer翻译
- 2.1 A High-Level Look
- 2.2 Bringing The Tensors Into The Picture
- 2.3 Now We’re Encoding!
- 2.4 Self-Attention at a High Level
- 2.5 Self-Attention in Detail
- 2.6 Matrix Calculation of Self-Attention
- 2.7 The Beast With Many Heads
- 2.8 Representing The Order of The Sequence Using Positional Encoding(使用位置编码表示序列的顺序)
- 2.9 The Residuals
- 2.10 The Decoder Side
- 2.11 The Final Linear and Softmax Layer
- 2.12 Recap Of Training(回顾)
- 2.13 The Loss Function
- 3. 代码详解
- 模型结构及参数初始化部分
- 训练部分
1. Attention Is All You Need
1.1 摘要
提出了完全基于注意力机制,避免使用循环和卷积的新的网络结构。
1.2 介绍
RNN模型通常沿输入和输出序列的符号位置进行因子计算,将位置与计算时间中的步骤对齐。它们产生一系列的隐藏状态 h t h_{t} ht,作为先前隐藏状态的函数 h t − 1 h_{t-1} ht−1和位置输入 t t t。这种内在的顺序性因为内存约束限制了跨实例的批处理,排除了并行化训练的可能性,而在处理较长的序列长度时,并行化又是至关重要的。
最近的工作通过因子分解技巧( factorization tricks)和条件计算(conditional computation)在计算效率方面取得了显著的提高,然而,序列计算的基本准则仍然存在。
注意力机制已经成为各种任务中序列模型和转换模型的一个重要组成部分,允许不考虑输入或输出序列间距离的依赖关系建模。然而,在除少数情况外的所有情况下,这种注意机制与一个递归网络结合使用。
在这项工作中,我们提出了Transformer,这是一个避免循环的模型架构,而不是完全依赖于注意机制来绘制输入和输出之间的全局依赖关系。
1.3 背景
减少顺序计算的目的也形成了扩展神经网络GPU、ByteNet和 ConvS2S的基础,所有这些都使用卷积神经网络作为基本构建块,并行计算所有输入和输出位置的隐藏表示。在这些模型中,将来自两个任意输入或输出位置的信号关联起来所需的操作数随位置之间的距离而增长, ConvS2S是线性的,ByteNet是对数的,这使得学习远距离位置之间的依赖性变得更加困难。在Transformer中,这被减少到了固定数目的操作数(this reduced to a constant number of operations),尽管由于平均注意力加权位置而降低了有效分辨率,但我们用多头注意抵消了这种影响。
自注意(Self-attention),有时被称为内注意(intra-attention),是一种注意机制,它将单个序列的不同位置联系起来,以计算序列的表示。自注意在阅读理解、抽象概括、文本蕴涵和学习任务无关的句子表征等任务中得到了成功的运用。
端到端的记忆网络是基于一种循环注意机制,而不是顺序排列的循环(sequence-aligned recurrence),在简单的语言问答和语言建模任务中表现良好。
1.4 模型结构
大多数有竞争力的神经序列转换模型都有编码器-解码器结构。在这里,编码器将由 ( x 1 , . . . , x n ) (x_{1},...,x_{n}) (x1,...,xn)符号表示的输入序列映射到连续表示序列 z = ( z 1 , . . . , z n ) \textbf{z}=(z_{1},...,z_{n}) z=(z1,...,zn)。对于给定的 z \textbf{z} z 解码器每次生成输出序列 ( y 1 , . . . , y n ) (y_{1},...,y_{n}) (y1,...,yn)的一个元素。在每一步,模型都是自回归的,在生成下一步时,将先前生成的符号作为附加输入。
Transformer遵循这个整体架构,使用堆叠的自注意(self-attention)和点对点( point-wise),编码器和解码器都具备全连接层,如图的左半部分和右半部分所示

1.5.1 编码器与解码器
1.5.1.1 编码器
编码器由 N = 6 N=6 N=6 个相同层的堆栈组成。每层有两个子层。
第一种是一种多头部的自注意机制,
第二种是一种简单的、按位置全连接的前馈网络。
我们在两个子层周围使用一个残差连接,然后进行层规范化。
也就是说,每个子层的输出是LayerNorm(x+ Sublayer(x)) 其中Sublayer(x)是子层自身应用的函数。
为了方便使用残差连接,模型中的所有子层以及嵌入层都会产生dimension d m o d e l d_{model} dmodel=512的输出。
1.5.1.2 解码器
解码器也是由 N = 6 N=6 N=6 个相同层的堆栈组成。多出来的第三个子层对编码器堆栈的输出执行多个头部注意力计算(严格来讲是对编码器的输出和解码器经过Masked多头注意力层后的输入进行计算)。
我们还修改解码器堆栈中的自注意子层,以防止位置影响后续位置(to prevent positions from attending to subsequent positions)。这种掩蔽(masking),加上输出嵌入偏移了一个位置(the output embeddings are offset by one position),确保对位置 i i i 的预测只能依赖于小于 i i i 的位置的已知输出。
1.5.2 注意力
注意力函数可以描述为将查询和一组键值对映射到输出,其中查询(Q)、键(K)、值(V)和输出都是向量。输出被计算为值的加权和,其中分配给每个值的权重由查询的兼容函数( compatibility function)和相应的键计算。
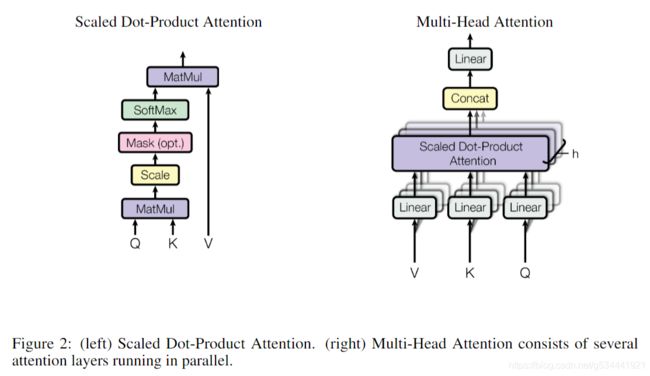
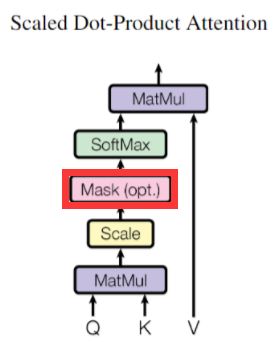
1.5.2.1 缩放点乘注意力
我们称我们特殊的注意力为 “Scaled Dot-Product Attention”,输入由 d k d_{k} dk维 的查询和键以及 d v d_{v} dv维 的值组成。我们使用所有键计算与查询的点积,每个除以 d k \sqrt{d_{k}} dk ,然后应用softmax函数获得值的权重。
实际操作时,我们同时计算一组查询的注意力函数,并将其打包成一个矩阵 Q Q Q。键和值也打包到矩阵中 K K K 和 V V V 中。我们将输出矩阵计算为:
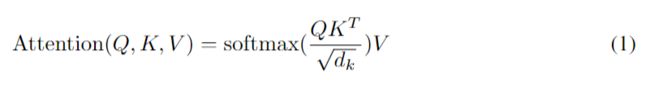
最常用的两个注意力函数是additive(加)注意力和点积注意力。点积注意力除了比例因子
1 d k \frac{1}{\sqrt{d_{k}}} dk1 之外与我们的算法相同,加注意力使用具有单个隐藏层的前馈网络计算兼容性函数。虽然二者在理论复杂度上相似,但在实际应用中,点积注意力计算速度更快,空间效率更高,因为它可以使用高度优化的矩阵乘法代码来实现。
而对于较小的 d k \sqrt{d_{k}} dk 值,两种机制的表现是相似的,加注意力在不缩放较大的 d k \sqrt{d_{k}} dk 值的情况下优于点积注意力。我们怀疑,对于大的 d k \sqrt{d_{k}} dk ,点积在数量级上增长很大,将softmax函数推到梯度极小的区域。为了抵消这一影响,我们将点积除以 d k \sqrt{d_{k}} dk 。
1.5.2.2 多头注意力
与用 d m o d e l − d i m e n s i o n a l d_{model}-dimensional dmodel−dimensional 的键、值和查询执行单个注意力函数,使用另一种可学习的线性投影(projection)分别对查询、键和值进行 h h h 次线性投影(projection)将它们投影到 d k d_{k} dk, d k d_{k} dk 和 d v d_{v} dv 维会更有效,然后,在每个查询、键和值的投影版本上,我们并行地执行注意力函数,即产生 d v − d i m e n s i o n a l d_{v}-dimensional dv−dimensional 的输出值。它们被连接在一起,然后再次投影,从而得到最终值。多头注意力允许模型在不同的位置共同关注来自不同表示子空间的信息。只有一个注意力头,平均化抑制了这种情况。
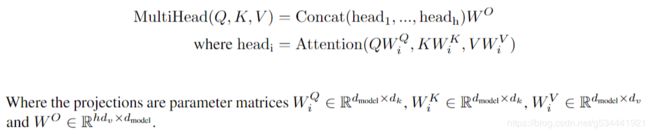
在这项工作中,我们使用了 h = 8 h=8 h=8个平行的注意力层,或者说头部。对于每一个头,我们使用 d k = d v = d m o d e l / h = 64 d_{k}=d_{v}=d_{model}/h=64 dk=dv=dmodel/h=64 。由于每个头部的维数减少,总的计算代价与全维度的单头部注意力的计算代价相似。
1.5.2.3 注意力在我们模型中的应用
Transformer以三种不同的方式使用多头注意:
- 在“encoder-decoder attention”层中,查询来自上一个解码器层,记忆键和值来自编码器的输出,这使得解码器中的每一个位置都能参与输入序列中的所有位置,这模仿了典型的编码器-解码器注意力机制。
- 编码器包含自注意力层。在自注意力层中,所有键、值和查询都来自同一个位置,在这种情况下,是编码器中前一层的输出。编码器中的每个位置都可以对应编码器前一层中的所有位置。
- 类似地,解码器中的自注意力层允许解码器中的每个位置关注解码器中直到并包括该位置的所有位置。为了保持解码器的自回归特性,需要防止解码器中的向左信息流。我们在缩放点积注意力中通过屏蔽(设置为 - ∞ -∞ -∞)softmax输入中与非法连接相对应的所有值实现了这一点。
1.5.2.4 位置前馈网络
除了注意子层之外,我们的编码器和解码器中的每个层都包含一个完全连接的前馈网络,它分别和相同地应用于每个位置。这包括两个线性转换,中间有一个ReLU激活。

虽然不同位置的线性变换是相同的,但它们从一层到另一层使用不同的参数。另一种描述方法是两个核大小为1的卷积。输入输出的维数 d m o d e l d_{model} dmodel 为512,内层 d f f d_{ff} dff 为2048。
1.5.2.5 Embeddings 和 Softmax
与其他序列转导(transduction )模型类似,我们使用可学习的 Embeddings 将输入Tokens和输出Tokens转换为维度 d m o d e l d_{model} dmodel 的向量。我们还使用常用的可学习的线性变换和Softmax函数将解码器输出转换为预测的下一个Token的概率。在我们的模型中,我们在两个嵌入层之间共享相同的权值矩阵和预softmax linear变换。在嵌入层中,我们将这些权重乘以 d k \sqrt{d_{k}} dk 。
1.5.2.6 位置嵌入
由于我们的模型不包含循环和卷积,为了使模型能够利用序列的顺序,我们必须注入一些关于序列中tokens的相对或绝对位置的信息。为此,我们将“位置编码”添加到编码器和解码器堆栈底部的输入嵌入中。位置编码与嵌入具有相同的维度 d m o d e l d_{model} dmodel ,以使将两者相加。位置编码有很多选择,可学习的和可固定的。
这里,我们使用不同频率的正余弦函数:
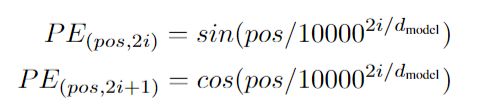
其中, p o s pos pos 是位置, i i i 是维度。也就是说,位置编码的每个维度都对应于一个正弦曲线。波长形成一个从 2 π 2π 2π到 10000 ⋅ 2 π 10000⋅2π 10000⋅2π 的几何轨迹。我们之所以选择这个函数,是因为我们假设它可以让模型很容易地通过相对位置进行学习,因为对于任何固定的偏移量 k k k, P E p o s + k PE_{pos+k} PEpos+k 都可以表示为 P E p o s PE_{pos} PEpos 的线性函数。
我们对可学习的位置嵌入进行了实验,发现两个版本产生了几乎相同的结果。我们选择正弦曲线模型是因为它可能允许模型外推到比训练中遇到的序列长度更长的序列长度。
1.5.3 为什么用自注意力
在本节中,我们将自注意力层的各个方面与通常用于将一个可变长度的符号表示 ( x 1 , . . . , x n ) (x_{1},...,x_{n}) (x1,...,xn) 序列映射到另一个同样长度序列 ( z 1 , . . . , z n ) (z_{1},...,z_{n}) (z1,...,zn) 的循环层和卷积层进行比较 。其中 x i , z i ∈ R d x_{i},\ z_{i}\in\mathbb{R}^{d} xi, zi∈Rd ,例如典型的序列转换编码器或解码器中的隐藏层。
我们使用自我注意力考虑到三个目的:
一是每层的总计算复杂度。
另一个是可以并行化的计算量,用所需的最少顺序操作数来衡量。
第三个是网络中长距离依赖关系之间的路径长度。
在许多序列转导任务中,学习长程依赖性是一个关键的挑战。影响学习这种依赖关系的一个关键因素是网络中前向和后向信号传播路径的长度。输入输出序列中任意位置组合之间的这些路径越短,就越容易学习长期依赖关系。因此,我们还比较了由不同层类型组成的网络中任意两个输入和输出位置之间的最大路径长度。

一个自注意层将所有位置与恒定数量的顺序执行操作连接起来,而一个循环层则需要 O ( N ) O(N) O(N) 顺序操作。在计算复杂度方面,当序列长度n小于表示维数d时,自注意层比循环层更快。为了提高涉及非常长序列的任务的计算性能,可以将自注意限制为仅考虑以各自输出位置为中心的输入序列中大小为 r r r 的邻域。这将让最大路径长度增加到 O ( n / r ) O(n/r) O(n/r) 。我们计划在今后的工作中进一步研究这种方法。
具有核宽度 k < n k
作为副产物,自注意可以产生更多可解释的模型。我们从我们的模型中检查注意分布,并在附录中给出和讨论示例。不仅个别注意头清楚地学会了执行不同的任务,许多似乎表现出与句子的句法和语义结构有关的行为。
1.6 训练
1.6.1 优化
我们使用Adam优化方案,其中 β 1 = 0.9 β1=0.9 β1=0.9 , β 2 = 0.98 β2=0.98 β2=0.98 , ϵ = 1 0 − 9 ϵ=10^{−9} ϵ=10−9 。根据如下的公式,我们在整个训练过程中改变了学习速度:
![]()
这相当于线性地增加第一个 w a r m u p s t e p s warmup~steps warmup steps 的学习速率,然后与步骤数的平方根成比例地降低学习速率。我们使用 w a r m u p s t e p s = 4000 warmup~steps= 4000 warmup steps=4000。
1.6.2 正则化
在训练期间,我们采用三种正规化:
Residual Dropout \textbf{Residual Dropout} Residual Dropout 我们将Dropout应用于每个子层的输出,在其被添加到子层输入并进行规范化之前。(We apply dropout to the output of each sub-layer, before it is added to the sub-layer input and normalized. )此外,我们还将dropout应用于编码器和解码器堆栈中的嵌入和位置编码之和。我们使用的是 P d r o p = 0.1 P_{drop}= 0.1 Pdrop=0.1 。
Label Smoothing \textbf{Label Smoothing} Label Smoothing 在训练过程中,我们采用了 ϵ l s = 0.1 ϵ_{ls}=0.1 ϵls=0.1 的标签平滑。这降低了 p e r p l e x i t y perplexity perplexity ,因为模型学会了更加不确定,但提高了准确性和BLEU分数。
关于训练的剩余内容及实验部分,感兴趣的朋友可以自行阅读。
论文中并没有提到具体的Attention的计算方法,对其他细节已经了解的朋友,请直接参考第二部分的
觉得还需要再加强一下的可以快速地浏览下这篇讲解清晰的博客。
2. The Illustrated Transformer翻译
大神的博客真是都能催泪啊,由衷地佩服!
The Illustrated Transformer
2.1 A High-Level Look
首先让我们将模型看作一个单独的黑盒。在机器翻译应用程序中,它将接受一种语言的句子,并将其翻译结果输出到另一种语言中。

打开Transformer,我们看到一个编码组件,一个解码组件,以及它们之间的连接。
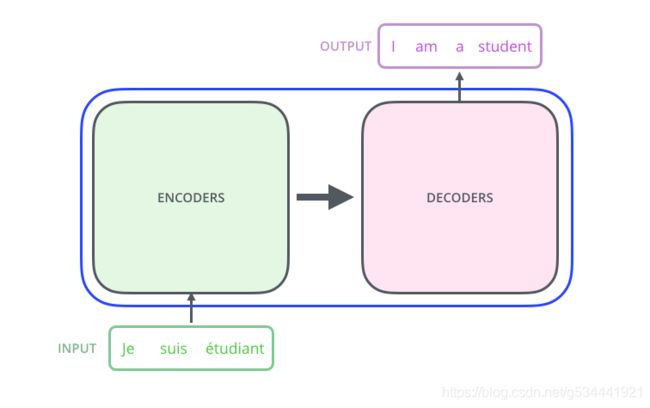
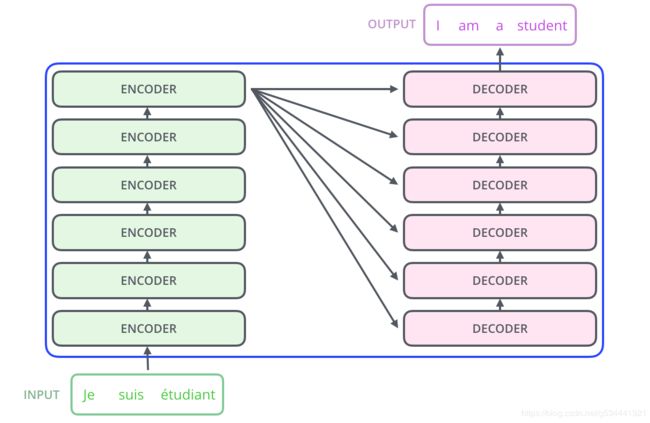
编码组件是一堆编码器(论文中将其中的六个堆叠在一起——数字六没有什么神奇之处,大家肯定可以用其他安排进行实验)。解码组件是一组相同数量的解码器。
编码器在结构上都是相同的(但它们不共享权重)。每一层都分为两个子层:
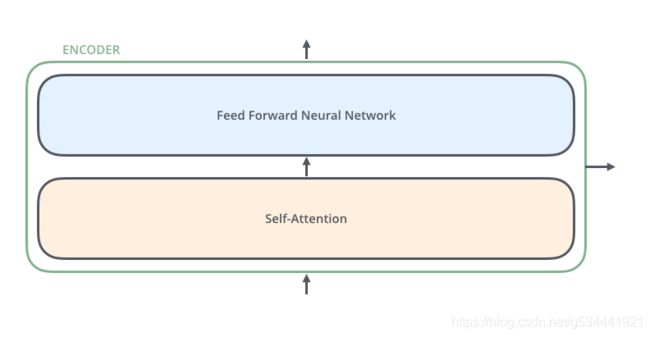
编码器的输入首先流经一个自我注意层,这一层帮助编码器在编码特定单词时查看输入语句中的其他单词。我们将在后面仔细研究自注意力。
将自注意层的输出喂给前馈神经网络。完全相同的前馈网络独立地应用于每个位置。
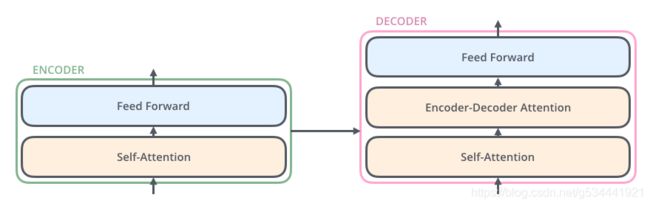
解码器也有这两个层,但它们之间是一个注意层,帮助解码器聚焦在输入语句的相关部分(类似于seq2seq模型中的注意力)。
2.2 Bringing The Tensors Into The Picture
现在我们已经看到了模型的主要组成部分,让我们开始看看各种向量/张量,以及它们如何在这些组成部分之间流动,从而将经过训练的模型的输入转化为输出。
与一般的NLP应用一样,我们首先使用嵌入算法将每个输入字转换为向量。

嵌入只发生在最底层的编码器中。所有编码器都有一个共同的抽象,那就是它们接收一个512大小的向量列表——在底部的编码器中是单词嵌入,但在其他编码器中,则是直接位于下面的编码器的输出。这个列表的大小是我们可以设置的超参数-基本上它是训练数据集中最长句子的长度。
在我们对输入序列的单词进行嵌入之后,每个单词都会流经编码器的两层中的每一层。
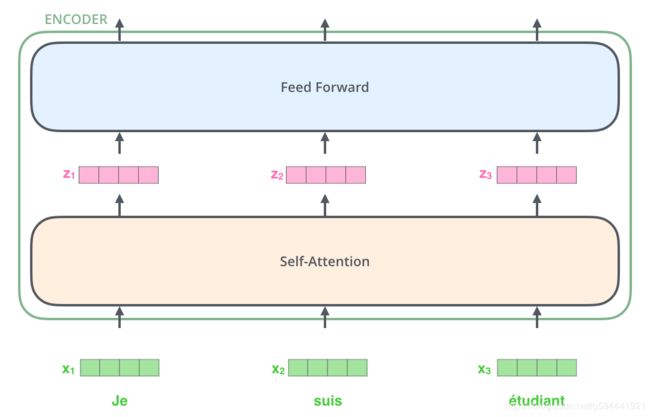
在这里,我们开始看到Transformer的一个关键特性,即每个位置的字在编码器中流过它自己的路径。
在自注意层中,这些路径之间存在依赖关系。然而,前馈层不具有这些依赖性,因此,在流经前馈层时,可以并行地执行各种路径。
接下来,我们将把这个例子转换成一个较短的句子,然后看看编码器的每个子层中发生了什么。
2.3 Now We’re Encoding!
正如我们已经提到的,编码器接收向量列表作为输入。它通过将这些向量传递到一个“自我注意”层,然后进入一个前馈神经网络,然后将输出向上发送到下一个编码器来处理这个列表。

每个位置的单词都经过一个自注意的过程。然后,它们各自通过一个前馈神经网络——每个向量分别流经的网络是完全相同的。
2.4 Self-Attention at a High Level
别被我忽悠,把“自我关注”这个词当成每个人都应该熟悉的概念。我个人从来没有遇到过这个概念,直到阅读了Attention is All You Need 。让我们提炼出它的工作原理。
假设下面的句子是我们要翻译的输入句子:
”The animal didn’t cross the street because it was too tired”
这句话中的“it”指的是什么?是指街道还是动物?对人类来说这是一个简单的问题,但对算法来说却不是那么简单。
当模型在处理“it”这个词时,自注意允许它把“it”和“animal”联系起来。当模型处理每个单词(输入序列中的每个位置)时,self-attention允许它查看输入序列中的其他位置,寻找有助于更好地编码该单词的线索。
如果您熟悉RNN,请考虑如何维护一个隐藏状态,使RNN能够将它以前处理过的单词/向量表示与当前处理的单词/向量表示结合起来。自注意是Transformer 用来将其他相关词汇的“理解”融合到我们当前正在处理的词汇中的方法。

当我们在编码器5(堆栈中的顶部编码器)中对“it”进行编码时,部分注意力机制集中在“animal”上,并将其表示的一部分融合到“it”的编码中。
一定要查看Tensor2Tensor笔记本,在那里您可以加载Transformer 模型,并使用这个交互式可视化查看它。
2.5 Self-Attention in Detail
让我们先看一下如何使用向量计算自注意,然后继续看它是如何实际实现的——使用矩阵。
计算自注意的第一步是从编码器的每个输入向量创建三个向量(在这种情况下为每个词的嵌入)。因此,对于每个单词,我们创建一个查询向量、一个键向量和一个值向量。这些向量是通过将嵌入值乘以我们在训练过程中训练的三个矩阵来创建的。
注意,这些新向量的维数小于嵌入向量。它们的维数为64,而嵌入和编码器输入/输出向量的维数为512。它们不必更小,这是一个架构选择,使多头注意力(主要)的计算保持不变。

将x1乘以WQ权重矩阵产生q1,即与该词相关联的“查询”向量。最后,我们为输入句子中的每个单词创建一个“查询”、“键”和一个“值”投影。
什么是“查询”、“键”和“值”向量?
它们是对计算和思考注意力有用的抽象概念。一旦你开始阅读下面是如何计算注意力的,你就会知道你所需要知道的关于这些向量所扮演的角色。
计算自注意的第二步是计算分数。假设我们正在计算本例中第一个单词“Thinking”的自注意力值。我们需要对输入句子中的每个单词与这个单词进行评分。分数决定了当我们在某个位置对一个单词进行编码时,在输入句子的其他部分要集中多少注意力。
分数是通过查询向量的点积和我们要评分的单词的键向量来计算的。因此,如果我们处理位置1的单词的自我注意,第一个分数将是q1和k1的点积。第二个分数是q1和k2的点积。
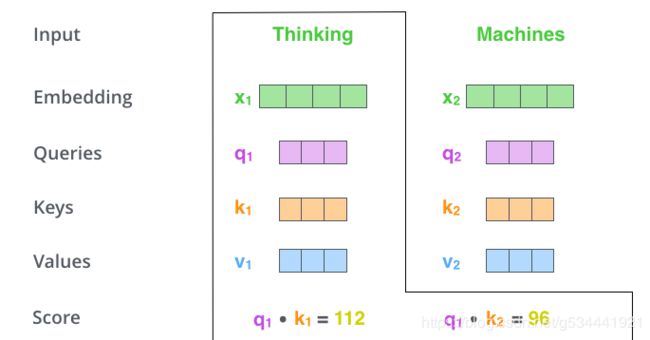
第三步和第四步是将分数除以8(论文中使用的关键向量维数的平方根–64)。这将导致更稳定的梯度。这里可能还有其他可能的值,但这是默认值),然后通过softmax操作传递结果。Softmax会将分数标准化,因此它们都是正的,加起来是1。

这个softmax分数决定了每个单词在这个位置上的表达量。很明显,这个位置上的单词会有最高的softmax分数,但有时注意与当前单词相关的另一个单词是有用的。
第五步是将每个值向量乘以softmax得分(准备将它们相加)。这里的直觉是保持我们想要关注的单词的值不变,并淹没(drown-out)掉不相关的单词(例如,通过将它们乘以0.001这样的小数字)。
第六步是加权值向量的求和。这将在这个位置(第一个单词)产生自注意层的输出。
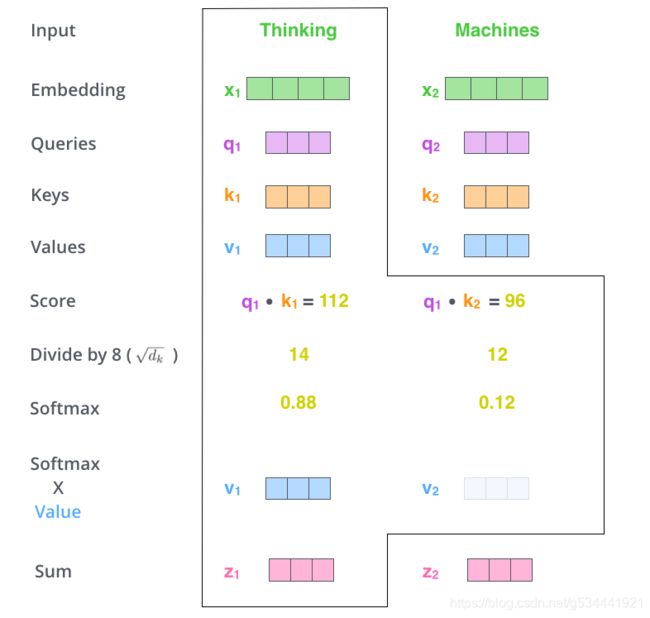
这就结束了自我注意的计算。得到的向量是一个我们可以发送到前馈神经网络的向量。然而,在实际实现中,这种计算是以矩阵的形式进行的,以便更快地处理。现在让我们看看这个,我们已经看到了计算的直观性。
2.6 Matrix Calculation of Self-Attention
第一步是计算查询、键和值矩阵。我们通过将我们的嵌入封装到矩阵X中,并将其乘以我们训练过的权重矩阵(WQ,WK,WV)来实现。

X矩阵中的每一行对应于输入句子中的一个单词。我们再次看到嵌入向量(图中512个或4个框)和q/k/v向量(图中64个或3个框)的大小差异
最后,由于我们处理的是矩阵,所以我们可以将步骤2到6压缩为一个公式来计算自我注意层的输出。
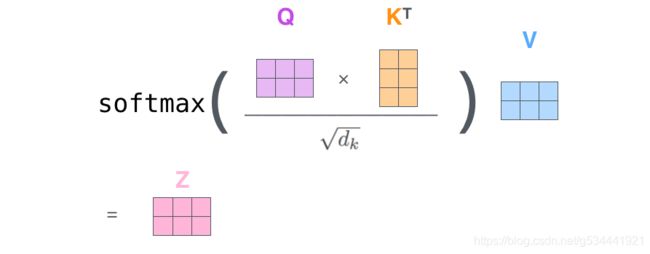
2.7 The Beast With Many Heads
本文通过增加“多头”注意机制,进一步细化了自我注意层。这从两个方面改善了注意力层的性能:
- 它扩展了模型关注不同位置的能力。是的,在上面的例子中,z1包含一点其他每个编码的信息(a little bit of every other encoding),但它可能由实际单词本身支配。如果我们翻译一个句子,比如“动物没有过马路,因为它太累了”,我们会想知道“它”指的是哪个词。
- 它给了注意层多个“表示子空间”。接下来我们将看到,对于多注意,我们不仅有一个,而且有多组查询/键/值权重矩阵(Transformer使用八个关注头,因此我们最终为每个编码器/解码器设置八个关注头)。每个集合都是随机初始化的。然后,在训练之后,使用每个集合将输入嵌入(或来自较低编码器/解码器的向量)投影到不同的表示子空间。
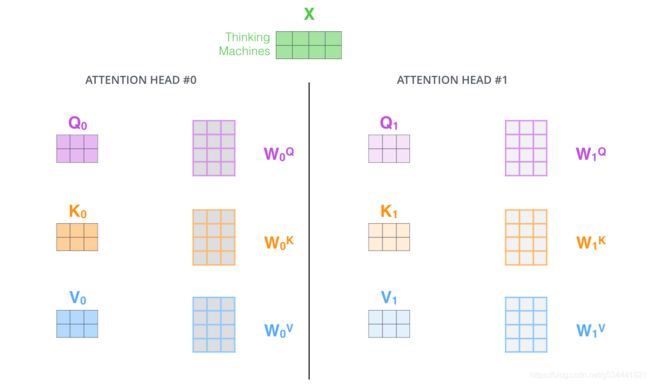
在多头注意的情况下,我们为每一个头部保持单独的Q/K/V权重矩阵,从而得到不同的Q/K/V矩阵。如前所述,我们将X乘以WQ/WK/WV矩阵,得到Q/K/V矩阵。
如果我们做同样的自我注意计算,只要八次不同的权重矩阵,我们就得到八个不同的Z矩阵。
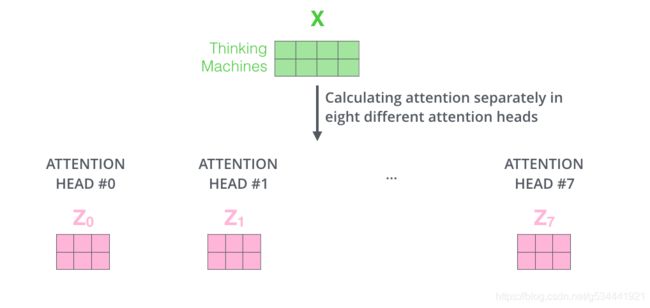
这给我们留下了一点挑战。前向层不需要8个矩阵-它需要一个矩阵(每个单词一个向量)。所以我们需要一种方法把这八个压缩成一个矩阵。
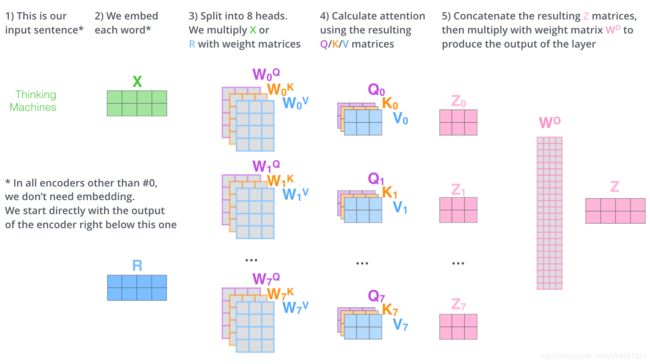
我们该怎么做?我们先对矩阵进行链接,然后用一个额外的权重矩阵WO将它们相乘。

这几乎就是多头自我关注的全部。我知道,这是相当多的矩阵。让我试着把它们放在一个视觉上,这样我们就可以在一个地方看到它们。
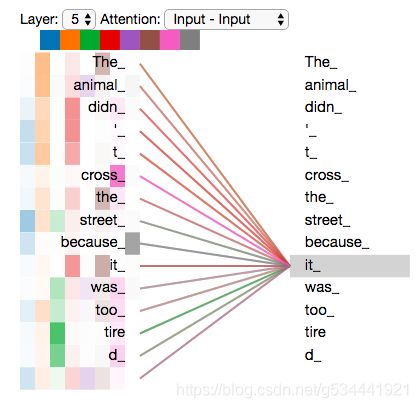
既然我们已经接触到了注意力,那么让我们回顾一下我们之前的例子,看看在我们的示例语句中对“it”这个词进行编码时,不同的注意力集中在哪里:

当我们对“it”这个词进行编码时,一个注意力集中在“the animal”身上,而另一个注意力集中在“tired”身上——从某种意义上说,模型对“it”这个词的表示在“the animal”和“tired”这两个词的表示中都有一部分被融合(bakes)。
然而,如果我们把所有的注意力都放在画面上,事情就更难解释了:
2.8 Representing The Order of The Sequence Using Positional Encoding(使用位置编码表示序列的顺序)
到目前为止,我们所描述的模型中缺少的一件事是一种解释输入序列中单词顺序的方法。
为了解决这个问题,transformer 向每个输入嵌入添加一个向量。这些向量遵循模型学习的特定模式,这有助于确定序列中每个单词的位置或不同单词之间的距离。这里的直觉是,将这些值添加到嵌入中可以在嵌入向量投影到Q/K/V向量后和点积注意期间提供它们之间有意义的距离。

为了给模型一种单词顺序的感觉,我们添加了位置编码向量——其值遵循特定的模式。
如果我们假设嵌入的维数为4,那么实际的位置编码将如下所示:

嵌入大小为4的位置编码的一个实例
这个图案可能是什么样的?
在下图中,每一行对应一个向量的位置编码。所以第一行将是我们添加到输入序列中第一个单词嵌入的向量。每行包含512个值–每个值都在1到-1之间。我们已经对它们进行了颜色编码,所以图案是可见的。

20个字(行)的位置编码的实际示例,嵌入大小为512(列)。你可以看到它在中间分成两半。这是因为左半部分的值由一个函数(使用正弦)生成,右半部分由另一个函数(使用余弦)生成。然后将它们连接起来形成每个位置编码向量。
本文描述了位置编码的公式。您可以在get_timing_signal_1d()中看到用于生成位置编码的代码。这不是唯一可能的位置编码方法。然而,它的优势在于能够扩展到看不见的序列长度(例如,如果我们的训练模型被要求翻译比我们训练集中任何一个句子都长的句子)。
2.9 The Residuals
编码器架构中的一个细节在我们继续之前需要提到,就是每个编码器中的每个子层(self-attention,ffnn)周围都有一个残差连接,然后是一个层规范化步骤。
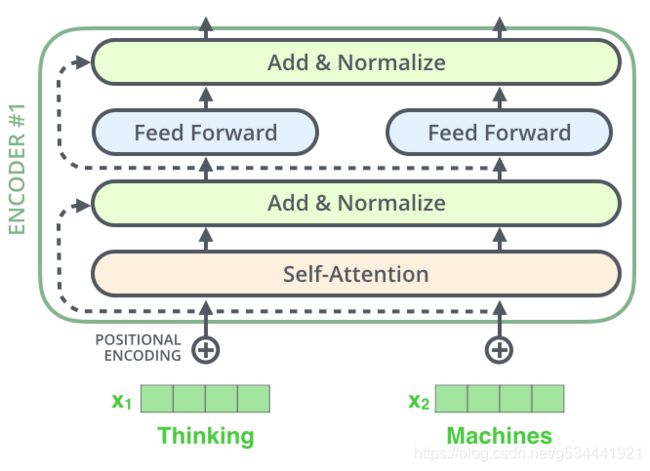
如果我们要可视化向量和与自我注意相关的层规范操作,它将如下所示:
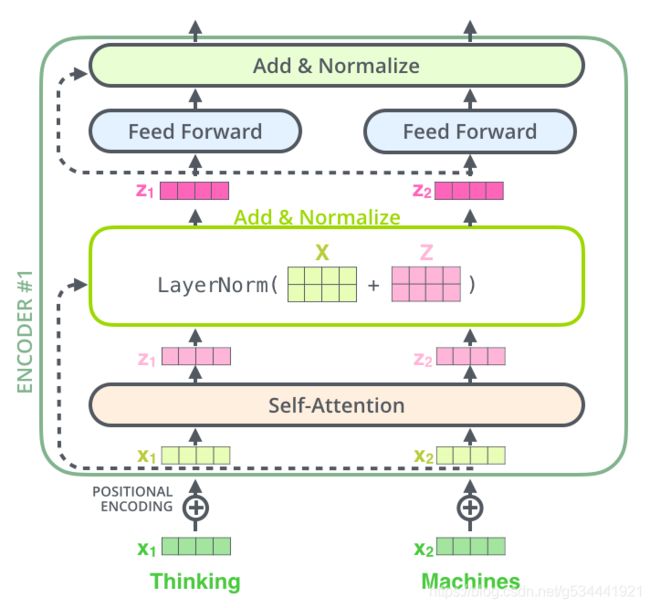
这也适用于解码器的子层。如果我们要考虑一个由两个堆叠的编码器和解码器组成的转换器,它应该是这样的:

2.10 The Decoder Side
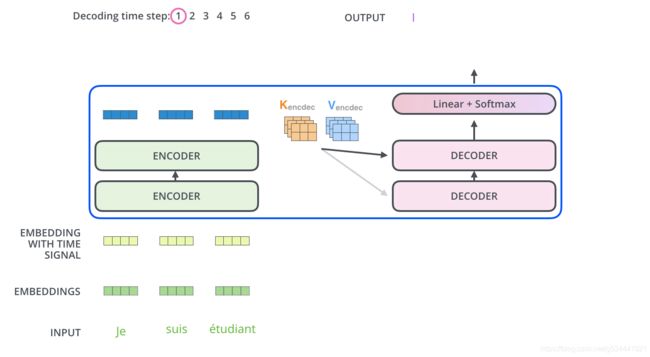
现在我们已经涵盖了编码器方面的大多数概念,我们基本上知道解码器的组件是如何工作的。但让我们看看他们是如何合作的。
编码器从处理输入序列开始。然后将顶部编码器的输出转换为一组注意向量K和V。这些向量将由每个解码器在其“编码器-解码器-注意”层中使用,这有助于解码器聚焦于输入序列中的适当位置:
在完成编码阶段之后,我们开始解码阶段。解码阶段的每个步骤从输出序列(本例中为英语翻译句子)输出一个元素。
以下步骤重复该过程,直到到达表示Transformer解码器已完成其输出的特殊符号。每一步的输出在下一个时间步被输入到底层解码器,解码器像编码器一样冒泡地提高解码结果。就像我们对编码器输入所做的那样,我们在解码器输入中嵌入并添加位置编码来指示每个单词的位置。
解码器中的自注意层的操作方式与编码器中的稍有不同:
在解码器中,自关注层只允许关注输出序列中的较早位置。这是通过在自我注意计算中的softmax步骤之前掩蔽未来位置(将其设置为-inf/即将对角线以上的值设置为-inf)来完成的。
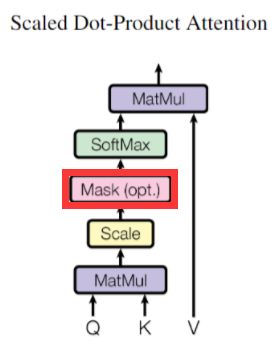

“Encoder-Decoder Attention”层的工作方式与多头自注意类似,只是它从它下面的层创建查询矩阵,并从编码器堆栈的输出获取键和值矩阵。
2.11 The Final Linear and Softmax Layer
解码器堆栈输出浮点向量。我们怎么把它变成一个词?这是最后一个线性层的工作,后面跟着一个Softmax层。
线性层是一个简单的完全连接的神经网络,它将解码器堆栈产生的向量投影成一个更大的向量,称为logits向量。
假设我们的模型知道10000个独特的英语单词(我们的模型的“输出词汇表”),这是从它的训练数据集中学习到的。这将使logits向量宽10000个单元格,每个单元格对应于一个唯一单词的分数。这就是模型的输出后是线性层的原因。
然后,softmax层将这些分数转换为概率(全部为正,加起来为1.0)。选择概率最高的单元格,并生成与其相关联的单词作为此时间步的输出。

此图从底部开始,向量作为解码器堆栈的输出。然后将其转换为输出字。
2.12 Recap Of Training(回顾)
现在,我们已经通过一个经过训练的Transformer涵盖了整个向前传播的过程,这将有助于了解训练模型的直觉。
在训练过程中,一个未经训练的模型会经历完全相同的前传。但由于我们是在一个有标签的训练数据集上训练它,所以我们可以将它的输出与实际的正确输出进行比较。
为了形象地说明这一点,假设我们的输出词汇表只包含六个单词(“a”、“am”、“i”、“thanks”、“student”和“”(句子结尾的缩写)。

我们模型的输出词汇表是在我们开始训练之前的预处理阶段创建的。
一旦定义了输出词汇表,就可以使用相同宽度的向量来表示词汇表中的每个单词。这也被称为一个独热编码。因此,例如,我们可以使用以下向量指示单词“am”:

在总结之后,让我们讨论一下模型的损失函数——我们在训练阶段优化的指标,从而得到一个经过训练的、希望非常精确的模型。
2.13 The Loss Function
假设我们正在训练我们的模型。假设这是我们在训练阶段的第一步,我们正在用一个简单的例子来培训它——将“merci”翻译成“thanks”。
这意味着,我们希望输出是表示“谢谢”的概率分布。但由于这一模式尚未得到训练,目前还不太可能实现。
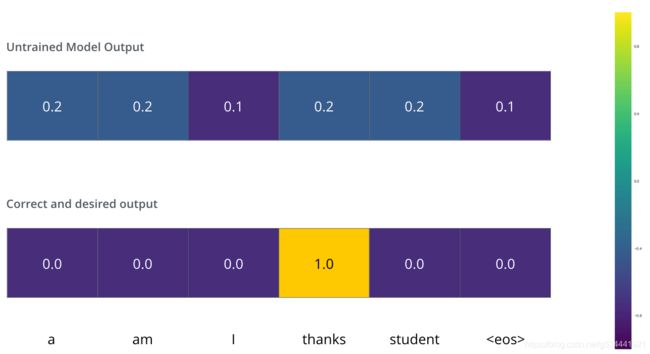
由于模型的参数(权重)都是随机初始化的,所以(未经训练的)模型会生成一个概率分布,每个单元格/单词的概率值都是任意的。我们可以将其与实际输出进行比较,然后使用反向传播调整模型的所有权重,使输出更接近所需的输出。
你如何比较两种概率分布?我们只是从另一个中减去一个。更多细节,请看交叉熵和Kullback-Leibler散度。
但请注意,这是一个过于简单化的例子。更现实地说,我们会用一个比一个词长的句子。例如,输入“je suisétudiant”和预期输出:“i am a student”。这实际上意味着,我们希望我们的模型连续输出概率分布,其中:
- 每个概率分布都由一个宽度为vocab_size的向量表示(在我们的示例中是6,但更实际的数字是3000或10000)
- 第一个概率分布在与“i”一词相关的单元格中的概率最高
- 第二个概率分布在与“am”一词相关联的单元格中的概率最高
- 依此类推,直到第五个输出分布指示“< end of sentence>”符号,该符号还具有10000个元素词汇表中与其关联的单元格。

在一个示例句子的训练示例中,我们将针对目标概率分布来训练模型。
在一个足够大的数据集上训练模型足够长的时间后,我们希望生成的概率分布如下所示:
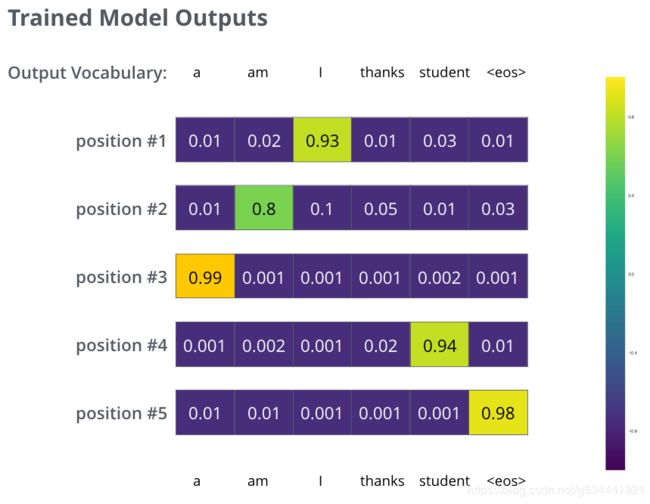
希望在训练之后,模型能输出我们期望的正确翻译。当然,这并不能说明这个短语是否是训练数据集的一部分(参见:交叉验证)。注意,每个位置都有一点概率,即使它不太可能是该时间步的输出——这是softmax的一个非常有用的特性,有助于训练过程。
现在,因为模型一次产生一个输出,我们可以假设模型是从概率分布中选择概率最高的词,然后丢弃其余的词。这是一种方法(称为贪婪解码)。另一种方法是保持前两个单词(例如,说“I”和“a”),然后在下一步中,运行模型两次:一次假设第一个输出位置是单词“I”,另一次假设第一个输出位置是单词“a”,无论哪一个版本在考虑位置1和位置2的情况下产生的误差都较小。我们对位置2和位置3等重复此操作。此方法称为“beam search”,在我们的示例中,beam大小为2(因为我们在计算位置1和位置2的beam后比较了结果),顶部beam也是2(因为我们保留了两个字)。这两个都是你可以尝试的超参数。
3. 代码详解
各个版本的Transformer大同小异。本文采用huggingface/transformers的Pytorch版本GPT-2模型中的Transformer部分来解析。
GitHub 22k+Star 最先进的自然语言处理模型集合
本文代码解析对应于下面这个项目的Transformer部分。
可能是目前效果最好的开源生成式聊天机器人项目-----深入理解“用于中文闲聊的GPT2模型”项目
基本上每个小部分都有注释,如果看到大片没有注释的代码,很可能是进入了最后注释的子函数,没有进行注释的部分会在下文进行注释!
模型结构及参数初始化部分
model = GPT2LMHeadModel(config=model_config)
class GPT2LMHeadModel(GPT2PreTrainedModel):
def __init__(self, config):
super(GPT2LMHeadModel, self).__init__(config)
self.transformer = GPT2Model(config) //我们要解析的就是这个部分
self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False)
self.init_weights() //调用apply()函数递归对所有组成部分初始化
self.tie_weights() //部分参数共享
class GPT2Model(GPT2PreTrainedModel):
def __init__(self, config):
"""
输出:`Tuple'由各种要素组成,取决于配置(配置)和输入:
**last_hidden_state**:
``torch.FloatTensor``
shape ``(batch_size, sequence_length, hidden_size)``
模型最后一层的隐藏状态序列。
**past**:
list of ``torch.FloatTensor`` (每层一个)
shape ``(batch_size, num_heads, sequence_length, sequence_length)``:
它包含预先计算的隐藏状态(pre-computed hidden-states)(注意力块中的键和值)。
可以使用(参见‘past’输入)来加快顺序解码。
**hidden_states**:
(`可选`, 当``config.output_hidden_states=True``时return)
list of ``torch.FloatTensor`` (每层一个输出 + embeddings的输出)
shape ``(batch_size, sequence_length, hidden_size)``:
模型的隐藏状态在每个层的输出加上初始嵌入输出。
**attentions**:
(`可选`, 当``config.output_attentions=True``时return)
list of ``torch.FloatTensor`` (每层一个)
shape ``(batch_size, num_heads, sequence_length, sequence_length)``:
attention softmax之后的注意力权重,用于计算自注意头的加权平均。
Examples::
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2Model.from_pretrained('gpt2')
input_ids = torch.tensor(tokenizer.encode("Hello, my dog is cute")).unsqueeze(0) # Batch size 1
outputs = model(input_ids)
last_hidden_states = outputs[0] # The last hidden-state is the first element of the output tuple
"""
super(GPT2Model, self).__init__(config) // 根据预设的config初始化参数
self.output_hidden_states = config.output_hidden_states // 是否输出output_hidden_states,本次调试中为False
self.output_attentions = config.output_attentions // 是否输出output_attentions,本次调试中为False
self.output_past = config.output_past // 是否输出预先计算的隐藏状态,本次调试中为Ture
self.wte = nn.Embedding(config.vocab_size, config.n_embd) // 注意力嵌入权重,本次调试中为(13317,768) 包含词表所有单字嵌入的嵌入矩阵
self.wpe = nn.Embedding(config.n_positions, config.n_embd) // 位置嵌入权重,本次调试中为(300,768)
self.drop = nn.Dropout(config.embd_pdrop)
self.h = nn.ModuleList([Block(config.n_ctx, config, scale=True) for _ in range(config.n_layer)]) //将子模块储存在一个List中
self.ln_f = nn.LayerNorm(config.n_embd, eps=config.layer_norm_epsilon)
self.init_weights()
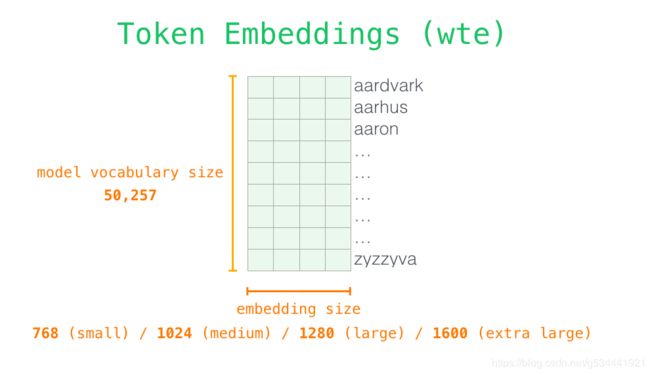

本次调试中位置嵌入预设宽度只有300哦(只要大于输入序列最大长度即可)。
ModuleList (n_layer=10)

我们将从模型函数进一步深入,我用序号和箭头来标记所在的位置。
0 Model -> 1 Block
class Block(nn.Module):
def __init__(self, n_ctx, config, scale=False):
super(Block, self).__init__()
nx = config.n_embd //嵌入层的列维度
self.ln_1 = nn.LayerNorm(nx, eps=config.layer_norm_epsilon)
self.attn = Attention(nx, n_ctx, config, scale) // 见Attention部分
self.ln_2 = nn.LayerNorm(nx, eps=config.layer_norm_epsilon)
self.mlp = MLP(4 * nx, config) // 见MLP部分
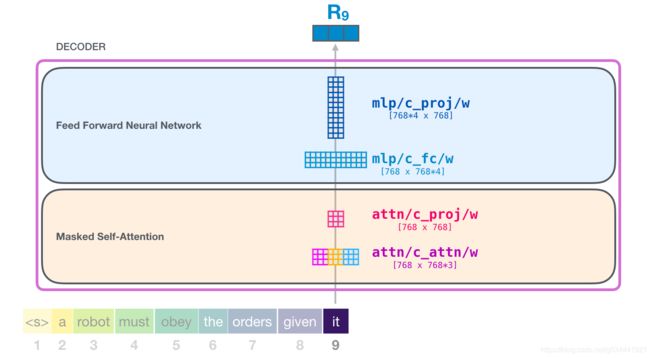
1 Block -> 2 Attention
class Attention(nn.Module):
def __init__(self, nx, n_ctx, config, scale=False):
super(Attention, self).__init__()
self.output_attentions = config.output_attentions // 是否输出output_attentions,本次调试中为False
n_state = nx # in Attention: n_state=768 (nx=n_embd)
# [switch nx => n_state from Block to Attention to keep identical to TF implem]
assert n_state % config.n_head == 0 // n_state需要能被注意头数目整除
self.register_buffer("bias", torch.tril(torch.ones(n_ctx, n_ctx)).view(1, 1, n_ctx, n_ctx)) // register_buffer
self.n_head = config.n_head // 注意头数
self.split_size = n_state // 本次调试为768
self.scale = scale // 本次调试为True
self.c_attn = Conv1D(n_state * 3, nx)
self.c_proj = Conv1D(n_state, nx)
self.attn_dropout = nn.Dropout(config.attn_pdrop) // 注意力层dropout
self.resid_dropout = nn.Dropout(config.resid_pdrop) //残差连接处dropout
self.pruned_heads = set()
register_buffer
向模块添加持久缓冲区。
这通常用于注册不应被视为模型参数的缓冲区。例如,BatchNorm的running_mean不是参数,而是持久状态的一部分。
bias shape: torch.Size([1, 1, 300, 300])
![]()
torch.tril (input, diagonal=0, out=None) → Tensor
返回矩阵的下三角部分(二维张量)或一批矩阵输入,结果张量输出的其他元素设置为0。
矩阵的下三角部分被定义为对角线上和对角线下的元素。
Example:
>>> a = torch.randn(3, 3)
>>> a
tensor([[-1.0813, -0.8619, 0.7105],
[ 0.0935, 0.1380, 2.2112],
[-0.3409, -0.9828, 0.0289]])
>>> torch.tril(a)
tensor([[-1.0813, 0.0000, 0.0000],
[ 0.0935, 0.1380, 0.0000],
[-0.3409, -0.9828, 0.0289]])
Conv1D
class Conv1D(nn.Module):
def __init__(self, nf, nx):
""" Conv1D layer as defined by Radford et al. for OpenAI GPT (and also used in GPT-2)
Basically works like a Linear layer but the weights are transposed
"""
super(Conv1D, self).__init__()
self.nf = nf
w = torch.empty(nx, nf) //发现了吗,这里是反过来的
nn.init.normal_(w, std=0.02)
self.weight = nn.Parameter(w) //正态分布初始化权重
self.bias = nn.Parameter(torch.zeros(nf)) // 偏置初始为0
def forward(self, x): //前向计算详见下文
size_out = x.size()[:-1] + (self.nf,)
x = torch.addmm(self.bias, x.view(-1, x.size(-1)), self.weight)
x = x.view(*size_out)
return x
基本上与线性层类似,但权重是转置的。前向计算训练部分再进行解析。
MLP
图示见计算部分
class MLP(nn.Module):
def __init__(self, n_state, config): # in MLP: n_state=3072 (4 * n_embd)
super(MLP, self).__init__()
nx = config.n_embd
self.c_fc = Conv1D(n_state, nx)
self.c_proj = Conv1D(nx, n_state)
self.act = gelu // 激活函数采用gelu
self.dropout = nn.Dropout(config.resid_pdrop)
def forward(self, x): // 详解见下文
h = self.act(self.c_fc(x))
h2 = self.c_proj(h)
return self.dropout(h2)
1 Block <- 2 Attention
0 Model <- 1 Block
self.init_weights()
0 Model -> 1 init_weights
def init_weights(self):
""" Initialize and prunes weights if needed. """
# Initialize weights
self.apply(self._init_weights)
这里递归调用 _init_weights 函数对所有的子项(源码中的submodule / .children())进行权重初始化。
def _init_weights(self, module):
""" Initialize the weights.
"""
//判断是否是(nn.Linear, nn.Embedding, Conv1D)类型中的一个
if isinstance(module, (nn.Linear, nn.Embedding, Conv1D)):
# Slightly different from the TF version which uses truncated_normal for initialization
# cf https://github.com/pytorch/pytorch/pull/5617
// @1
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if isinstance(module, (nn.Linear, Conv1D)) and module.bias is not None:
// @2
module.bias.data.zero_()
elif isinstance(module, nn.LayerNorm):
// @3
module.bias.data.zero_()
module.weight.data.fill_(1.0)
@1
torch.nn.init.normal_(tensor, mean=0.0, std=1.0)
对所有的Embedding,Linear,Conv1D的weight值使用从正态分布 N ( mean , std 2 ) \mathcal{N}(\text{mean}, \text{std}^2) N(mean,std2)中提取的值填充输入张量。
@2
对Linear,Conv1D存在bias的项的偏置(bias)值置0。
@3
对LayerNorm偏置置0,权重赋1。
训练部分
我们要解析的这一句代码。
transformer_outputs = self.transformer(input_ids,
past=past,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask)
进入到Transformer的forward部分,由于代码过长,我们就一段一段解释了。
def forward(self, input_ids, past=None, attention_mask=None, token_type_ids=None, position_ids=None, head_mask=None):
// 这里我们的输入是size=8的一个batch,序列长度为133,故shape为torch.Size([8, 133])
input_shape = input_ids.size()
// 由于iput本身事整齐的,这里input_ids 没有发生变化
input_ids = input_ids.view(-1, input_shape[-1])
// 本次调试token_type_ids和position_ids均为NONE
if token_type_ids is not None:
token_type_ids = token_type_ids.view(-1, input_shape[-1])
if position_ids is not None:
position_ids = position_ids.view(-1, input_shape[-1])
// 初始化past List为层数个NONE
if past is None:
past_length = 0
past = [None] * len(self.h)
else:
past_length = past[0][0].size(-2)
// 这里的位置编码其实是采用随机初始化后进行训练的方式,并没有采用原文的正余弦曲线初始化。这里只是为每个位置创立一个索引
if position_ids is None:
position_ids = torch.arange(past_length, input_ids.size(-1) + past_length, dtype=torch.long, device=input_ids.device)
position_ids = position_ids.unsqueeze(0).expand_as(input_ids)
position_ids shape: torch.Size([8, 133])
tensor([[ 0, 1, 2, ..., 130, 131, 132],
[ 0, 1, 2, ..., 130, 131, 132],
[ 0, 1, 2, ..., 130, 131, 132],
...,
[ 0, 1, 2, ..., 130, 131, 132],
[ 0, 1, 2, ..., 130, 131, 132],
[ 0, 1, 2, ..., 130, 131, 132]])
# Attention mask.
// 本次调试未用到attention_mask,是masked self-attention的另一种简单实现,两种实现方式作用相同。
if attention_mask is not None:
attention_mask = attention_mask.view(-1, input_shape[-1])
# We create a 3D attention mask from a 2D tensor mask.
# Sizes are [batch_size, 1, 1, to_seq_length]
# So we can broadcast to [batch_size, num_heads, from_seq_length, to_seq_length]
# this attention mask is more simple than the triangular masking of causal attention
# used in OpenAI GPT, we just need to prepare the broadcast dimension here.
attention_mask = attention_mask.unsqueeze(1).unsqueeze(2)
# Since attention_mask is 1.0 for positions we want to attend and 0.0 for
# masked positions, this operation will create a tensor which is 0.0 for
# positions we want to attend and -10000.0 for masked positions.
# Since we are adding it to the raw scores before the softmax, this is
# effectively the same as removing these entirely.
attention_mask = attention_mask.to(dtype=next(self.parameters()).dtype) # fp16 compatibility
attention_mask = (1.0 - attention_mask) * -10000.0
# Prepare head mask if needed
# 1.0 in head_mask indicate we keep the head
# attention_probs has shape bsz x n_heads x N x N
# head_mask has shape n_layer x batch x n_heads x N x N
// 也未用到head_mask,等什么时候看到先关论文时再做尝试,了解的朋友可以评论告知
if head_mask is not None:
if head_mask.dim() == 1:
head_mask = head_mask.unsqueeze(0).unsqueeze(0).unsqueeze(-1).unsqueeze(-1)
head_mask = head_mask.expand(self.config.n_layer, -1, -1, -1, -1)
elif head_mask.dim() == 2:
head_mask = head_mask.unsqueeze(1).unsqueeze(-1).unsqueeze(-1) # We can specify head_mask for each layer
head_mask = head_mask.to(dtype=next(self.parameters()).dtype) # switch to fload if need + fp16 compatibility
else:
// 所以这里最后head_mask定义为n_layer(10)个NONE的List
head_mask = [None] * self.config.n_layer
inputs_embeds = self.wte(input_ids) // 获取输入序列的Embedding
position_embeds = self.wpe(position_ids) //获取位置序列的Embedding
按照我解释习惯,本应将这里也深挖一下的。但具体的实现实在是很简单,我之前看过Tensorflow索引Embedding的实现,扫了一下pytoch版本的实现,大同小异。建议感兴趣的朋友自行调试一下,就能对Embedding的“查表”操作有比较深的印象了。为了方便不太了解的朋友能有个直观的印象,我们通过shape的变换简单做一介绍:
input_ids (8,133) look in wte (13317,768) -> inputs_embeds (8,133,768)
position_embeds (8,133) look in wpe (300,768) -> position_embeds(8,133,768)
想象input_ids是 8 8 8 行文字,每行 133 133 133 个字。而wte是一个字典,其中包含了 13317 13317 13317 个字的解释(长度为 768 768 768 的信息是对应于这一行的那个字的解释)。而这里look up的操作其实是我们查出这 8 8 8 行文字每个字的意思,一个字可以查出长度768的信息,那么 8 ∗ 133 8*133 8∗133个字呢?当然就是 8 ∗ 133 ∗ 768 8*133*768 8∗133∗768了,而这长度为 768 768 768 的信息,就是对应这个字的词向量(当然也可能不止是字,甚至是词或者其他什么东西,但我们要有这样的概念,不管是一个字还是一个词,都是由一个确定的 t o k e n token token (一般可以认为是一个整数序号)来表示的)。
// 本次调试token_type_ids为NONE,不过理解方式是一样的。
if token_type_ids is not None:
token_type_embeds = self.wte(token_type_ids)
else:
token_type_embeds = 0
// 这里就到了将 输入嵌入和位置嵌入相加了,至于类型嵌入属于某种本次调试未使用的改进
hidden_states = inputs_embeds + position_embeds + token_type_embeds
hidden_states = self.drop(hidden_states) // 使用dropout
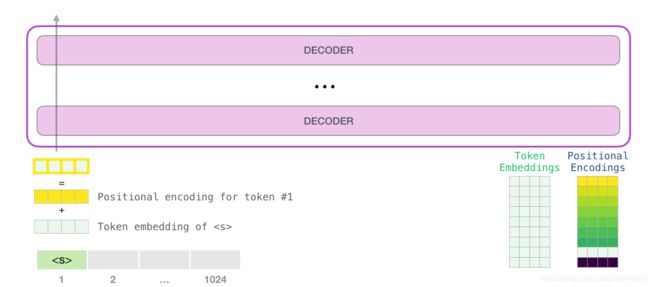
// (8,133,768) = (8,133) + (768,)
output_shape = input_shape + (hidden_states.size(-1),)
presents = ()
all_attentions = []
all_hidden_states = ()
// 按层处理
for i, (block, layer_past) in enumerate(zip(self.h, past)):
// 把当前的hidden_states加入all_hidden_states,本次调试不输出all_hidden_states
if self.output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states.view(*output_shape),)
// 进入该子函数,后续详解见下文
outputs = block(hidden_states,
layer_past=layer_past,
attention_mask=attention_mask,
head_mask=head_mask[i])
hidden_states, present = outputs[:2]
if self.output_past:
presents = presents + (present,)
if self.output_attentions:
all_attentions.append(outputs[2])
0 transformer_forward -> 1 block_forward
def forward(self, x, layer_past=None, attention_mask=None, head_mask=None):
// 进入该子函数,后续详解见下文
output_attn = self.attn(self.ln_1(x),
layer_past=layer_past,
attention_mask=attention_mask,
head_mask=head_mask)
a = output_attn[0] # output_attn: a, present, (attentions)
x = x + a
m = self.mlp(self.ln_2(x))
x = x + m
outputs = [x] + output_attn[1:]
return outputs # x, present, (attentions)
1 block_forward -> 2 atten_forward

def forward(self, x, layer_past=None, attention_mask=None, head_mask=None):
x = self.c_attn(x) // 见下文c_attn详解
// split_size=768
query, key, value = x.split(self.split_size, dim=2)
query = self.split_heads(query)
key = self.split_heads(key, k=True)
value = self.split_heads(value)
if layer_past is not None:
past_key, past_value = layer_past[0].transpose(-2, -1), layer_past[1] # transpose back cf below
key = torch.cat((past_key, key), dim=-1)
value = torch.cat((past_value, value), dim=-2)
present = torch.stack((key.transpose(-2, -1), value)) # transpose to have same shapes for stacking
attn_outputs = self._attn(query, key, value, attention_mask, head_mask)
a = attn_outputs[0]
a = self.merge_heads(a)
a = self.c_proj(a)
a = self.resid_dropout(a)
outputs = [a, present] + attn_outputs[1:]
return outputs # a, present, (attentions)
2 atten_forward -> 3 c_attn
class Attention(nn.Module):
def __init__(self, nx, n_ctx, config, scale=False):
...
self.c_attn = Conv1D(n_state * 3, nx)
...

3 c_attn -> 4 Conv1D
def forward(self, x):
'''
x.size()[:-1]为前两维的shape,即(torch.Size([8, 133]))
self.nf即n_state * 3 = 2304 ,见上边c_attn定义
size_out : torch.Size([8, 133, 2304])
'''
size_out = x.size()[:-1] + (self.nf,)
'''
self.bias: torch.Size([2304])
x.view(-1, x.size(-1)): torch.Size([1064, 768])
self.weight: torch.Size([768, 2304]) 发现了吗,这里的权重是被转置的,这是在Conv1D init的时候定义的
x: torch.Size([8, 133, 768]) -> torch.Size([1064, 2304])
这里的三个参数的运算规则:
x(output)= ([2304]) + ([1064, 768]) @ ([768, 2304])
'''
x = torch.addmm(self.bias, x.view(-1, x.size(-1)), self.weight)
// x: torch.Size([1064, 2304]) -> torch.Size([8, 133, 2304])
x = x.view(*size_out)
return x
torch.addmm (input, mat1, mat2, *, beta=1, alpha=1, out=None) → Tensor
执行矩阵 mat1 和 mat2 的矩阵乘法。矩阵输入被添加到最终结果中。
如果 mat1 是(n×m)张量,mat2 是(m×p)张量,那么输入必须可传播为(n×p)张量,输出必须是(n×p)张量。
alpha 和 beta 分别是 mat1 和 mat2 之间矩阵向量积的比例因子和矩阵输入的相加。
o u t = β i n p u t + α ( m a t 1 i @ m a t 2 i ) out=β input+α (mat1_{ i} @mat2_{ i} ) out=βinput+α(mat1i@mat2i)
@表示矩阵乘法。
其他细节可以阅读Pytorch里addmm()和addmm_()的用法详解
3 c_attn <- 4 Conv1D
2 atten_forward <- 3 c_attn
torch.split (tensor, split_size_or_sections, dim=0)
把张量分成块。每个块都是原始张量的view。
如果 split_size_or_sections 是整数类型,则张量将被拆分为大小相等的块(如果可能)。如果给定维度维度上的张量大小不能被拆分大小整除,则最后一个块将更小。
如果 split_size_or_sections 是一个列表,则张量将被拆分为len(split_size_or_sections)块,块的大小根据 split_size_or_sections 以dim表示。
def forward(self, x, layer_past=None, attention_mask=None, head_mask=None):
x = self.c_attn(x)
// 定义的时候定义成三倍的n_state长度,然后将其分成三份,这么曲折就是为了给Q,K,V赋初值。。。
query, key, value = x.split(self.split_size, dim=2)
// Q,K,V: torch.Size([8, 133, 768]) -> torch.Size([8, 12, 133, 64]),为什么会有这么奇怪的变形,请看下文split_heads的分析
query = self.split_heads(query)
key = self.split_heads(key, k=True)
value = self.split_heads(value)
// 是否要输出历史值,本次调试为NONE
if layer_past is not None:
past_key, past_value = layer_past[0].transpose(-2, -1), layer_past[1] # transpose back cf below
key = torch.cat((past_key, key), dim=-1)
value = torch.cat((past_value, value), dim=-2)
// 将K的最后两维互换(和V同纬度),然后和V堆叠 shape: torch.Size([2, 8, 12, 133, 64])
present = torch.stack((key.transpose(-2, -1), value)) # transpose to have same shapes for stacking
// 终于到注意力计算了,进入!
attn_outputs = self._attn(query, key, value, attention_mask, head_mask)
a = attn_outputs[0]
a = self.merge_heads(a)
a = self.c_proj(a)
a = self.resid_dropout(a)
outputs = [a, present] + attn_outputs[1:]
return outputs # a, present, (attentions)

split_heads
def split_heads(self, x, k=False):
'''
x: torch.Size([8, 133, 768])
x.size()[:-1]: torch.Size([8, 133]) x.size(-1): 768 n_head: 12
(self.n_head, x.size(-1) // self.n_head): : (12, 64)
new_x_shape : torch.Size([8, 133, 12, 64])
'''
new_x_shape = x.size()[:-1] + (self.n_head, x.size(-1) // self.n_head)
x = x.view(*new_x_shape) # in Tensorflow implem: fct split_states
if k: // K: ([8, 133, 12, 64]) -> ([8, 12, 64, 133])
return x.permute(0, 2, 3, 1) # (batch, head, head_features, seq_length)
else: // Q,V: ([8, 133, 12, 64]) -> ([8, 12, 133, 64])
return x.permute(0, 2, 1, 3) # (batch, head, seq_length, head_features)
可以看出,这是Q,K,V对应多头的分解。

2 atten_forward -> 3 _attn
def _attn(self, q, k, v, attention_mask=None, head_mask=None):
w = torch.matmul(q, k)
if self.scale:
w = w / math.sqrt(v.size(-1))
nd, ns = w.size(-2), w.size(-1)
b = self.bias[:, :, ns-nd:ns, :ns]
w = w * b - 1e4 * (1 - b)
if attention_mask is not None:
# Apply the attention mask
w = w + attention_mask
w = nn.Softmax(dim=-1)(w)
w = self.attn_dropout(w)
# Mask heads if we want to
if head_mask is not None:
w = w * head_mask
outputs = [torch.matmul(w, v)]
if self.output_attentions:
outputs.append(w)
return outputs
w = torch.matmul(q, k) // w: torch.Size([8, 12, 133, 133])
Q ∗ K T Q*K^T Q∗KT 还记得K之前已经被转置过了吗,所以代码中就直接相乘了。

if self.scale:
w = w / math.sqrt(v.size(-1))
Q ∗ K T d k \frac{Q*K^T}{\sqrt{d_{k}}} dkQ∗KT
// 133,133
nd, ns = w.size(-2), w.size(-1)
// self.bias: torch.Size([1, 1, 300, 300]) 初始化时我们预设的最大长度为300
// b: torch.Size([1, 1, 133, 133]) 我们每个序列的长度为133
b = self.bias[:, :, ns-nd:ns, :ns]
w = w * b - 1e4 * (1 - b)
b torch.Size([1, 1, 133, 133]) 还记得那个下三角矩阵吗?
tensor([[[[1., 0., 0., ..., 0., 0., 0.],
[1., 1., 0., ..., 0., 0., 0.],
[1., 1., 1., ..., 0., 0., 0.],
...,
[1., 1., 1., ..., 1., 0., 0.],
[1., 1., 1., ..., 1., 1., 0.],
[1., 1., 1., ..., 1., 1., 1.]]]])
这部分建议参看可能是目前效果最好的开源生成式聊天机器人项目-----深入理解“用于中文闲聊的GPT2模型”项目中The Illustrated GPT-2 博客翻译中Masked Self-Attention部分详解


-1e4 * (1 - b): torch.Size([1, 1, 133, 133])
tensor([[[[ -0., -10000., -10000., ..., -10000., -10000., -10000.],
[ -0., -0., -10000., ..., -10000., -10000., -10000.],
[ -0., -0., -0., ..., -10000., -10000., -10000.],
...,
[ -0., -0., -0., ..., -0., -10000., -10000.],
[ -0., -0., -0., ..., -0., -0., -10000.],
[ -0., -0., -0., ..., -0., -0., -0.]]]])
还记得这里吗:在解码器中,自关注层只允许关注输出序列中的较早位置。这是通过在自我注意计算中的softmax步骤之前掩蔽未来位置(将其设置为-inf/即将对角线以上的值设置为-inf)来完成的。
那么大家可以想象这两部分相减的情形了,与动辄小于一的权重参数相比,-10000和-inf没有太大区别。
if attention_mask is not None:
# Apply the attention mask
w = w + attention_mask
我们这里没有用attention_mask,但是也很简单不是吗?
w = nn.Softmax(dim=-1)(w)
w = self.attn_dropout(w) // 加dropout
s o f t m a x ( Q ∗ K T d k ) softmax(\frac{Q*K^T}{\sqrt{d_{k}}}) softmax(dkQ∗KT)

# Mask heads if we want to
if head_mask is not None:
w = w * head_mask
当然我们这里也没有用head_mask。
outputs = [torch.matmul(w, v)]
if self.output_attentions:
outputs.append(w)
return outputs
是不是几乎完全一致?
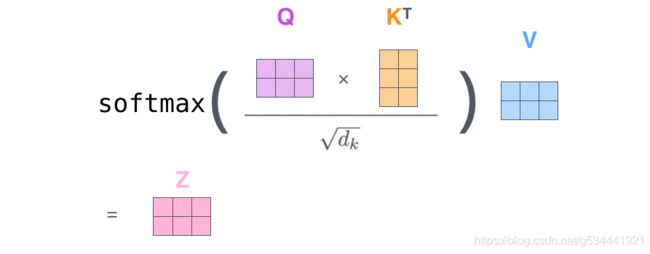
2 atten_forward <- 3 _attn
def forward(self, x, layer_past=None, attention_mask=None, head_mask=None):
...
...
attn_outputs = self._attn(query, key, value, attention_mask, head_mask)
a = attn_outputs[0]
// 详解见下文
a = self.merge_heads(a)
a = self.c_proj(a)
a = self.resid_dropout(a) // 残差连接的dropout
outputs = [a, present] + attn_outputs[1:]
return outputs # a, present, (attentions)
为什么要[0]:

attn_outputs[0] torch.Size([8, 12, 133, 64])
a = self.merge_heads(a)
def merge_heads(self, x):
// x: torch.Size([8, 12, 133, 64])-> torch.Size([8, 133, 12, 64])
x = x.permute(0, 2, 1, 3).contiguous()
// new_x_shape: torch.Size([8, 133, 768])
new_x_shape = x.size()[:-2] + (x.size(-2) * x.size(-1),)
return x.view(*new_x_shape) # in Tensorflow implem: fct merge_states
对多头进行合并。

a = self.c_proj(a)
class Attention(nn.Module):
def __init__(self, nx, n_ctx, config, scale=False):
...
...
self.c_proj = Conv1D(n_state, nx)
...
...
这里其实就相当于加了一个线性层,额外训练了一层参数,shape不变。
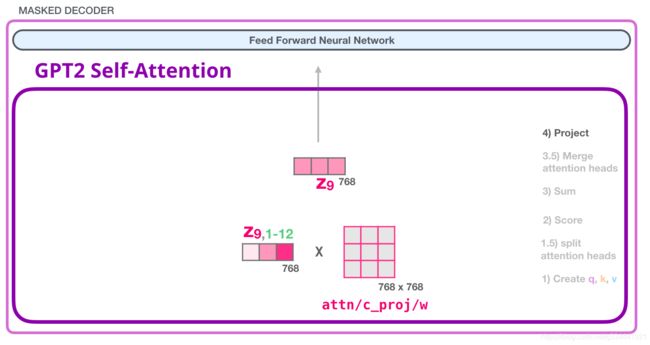
a = self.c_proj(a)
a = self.resid_dropout(a)
// 我们本次调试没有attn_outputs,所以也就是输出a(attentions),present(计算出的K和V)打包成List输出
outputs = [a, present] + attn_outputs[1:]
return outputs # a, present, (attentions)
1 block_forward <- 2 atten_forward
def forward(self, x, layer_past=None, attention_mask=None, head_mask=None):
output_attn = self.attn(self.ln_1(x),
layer_past=layer_past,
attention_mask=attention_mask,
head_mask=head_mask)
a = output_attn[0] # output_attn: a, present, (attentions)
x = x + a
m = self.mlp(self.ln_2(x))
x = x + m
outputs = [x] + output_attn[1:]
return outputs # x, present, (attentions)
2 atten_forward -> 3 MLP_forward
class MLP(nn.Module):
def __init__(self, n_state, config): # in MLP: n_state=3072 (4 * n_embd)
super(MLP, self).__init__()
nx = config.n_embd
self.c_fc = Conv1D(n_state, nx) // c_fc 的定义
self.c_proj = Conv1D(nx, n_state)
self.act = gelu
self.dropout = nn.Dropout(config.resid_pdrop)
def forward(self, x):
h = self.act(self.c_fc(x)) // 进入子函数
h2 = self.c_proj(h)
return self.dropout(h2)
c_fc(x)

class Block(nn.Module):
def __init__(self, n_ctx, config, scale=False):
super(Block, self).__init__()
...
...
self.mlp = MLP(4 * nx, config) // 如果忘了这里的定义,就会疑惑为什么下面x的第三维为什么成了3072
def forward(self, x):
size_out = x.size()[:-1] + (self.nf,)
x = torch.addmm(self.bias, x.view(-1, x.size(-1)), self.weight)
x = x.view(*size_out)
// x: torch.Size([8, 133, 3072]) 3072 = 768 * 4
return x
act
def gelu(x): //这里采用的是gelu作为激活函数
return 0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3))))
def forward(self, x):
h = self.act(self.c_fc(x)) // h: torch.Size([8, 133, 3072])
h2 = self.c_proj(h) // h2: torch.Size([8, 133, 768])
return self.dropout(h2)
self.c_fc = Conv1D(n_state, nx)
// h-> torch.Size([1064, 3072]) @ torch.Size([3072, 768])
// 3072是因为此时还在MLP模块中 1064 = 8 * 133
// 可以看出c_proj和c_fc定义相反,所以c_proj的权重未转置。
self.c_proj = Conv1D(nx, n_state)

回顾一下,我们的输入向量主要遇到了这些权矩阵:

2 atten_forward <- 3 MLP_forward
def forward(self, x, layer_past=None, attention_mask=None, head_mask=None):
output_attn = self.attn(self.ln_1(x),
layer_past=layer_past,
attention_mask=attention_mask,
head_mask=head_mask)
a = output_attn[0] # output_attn: a, present, (attentions)
x = x + a // 残差连接
m = self.mlp(self.ln_2(x)) m: torch.Size([8, 133, 768])
x = x + m // 残差连接
MLP其实对应的就是Feed Forward,这部分的操作等价于接上
( 768 , 768 ∗ 4 ) (768,768*4) (768,768∗4)-> ( 768 ∗ 4 , 768 ) (768*4,768) (768∗4,768)的全连接层。

// 打包输出
outputs = [x] + output_attn[1:]
return outputs # x, present, (attentions)
1 block_forward <- 2 atten_forward
0 transformer_forward <- 1 block_forward
for i, (block, layer_past) in enumerate(zip(self.h, past)):
if self.output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states.view(*output_shape),)
outputs = block(hidden_states,
layer_past=layer_past,
attention_mask=attention_mask,
head_mask=head_mask[i])

outputs[0]: torch.Size([8, 133, 768])
outputs[1]: torch.Size([2, 8, 12, 133, 64]) // K,V
// outputs[0] -> hidden_states
// outputs[1] -> present
hidden_states, present = outputs[:2]
if self.output_past: // 保存对应每次输入的 K,V 值
presents = presents + (present,)
if self.output_attentions: // 本次调试未对all_attentions进行保存
all_attentions.append(outputs[2])
for i, (block, layer_past) in enumerate(zip(self.h, past)):
...
...
// 循环结束后即已经通过了所有的Encoder层,对输出进行Layer Normalize后即为最终hidden_states
hidden_states = self.ln_f(hidden_states)
// 这里维度不变torch.Size([8, 178, 768])
hidden_states = hidden_states.view(*output_shape)
# Add last hidden state
// 本次调试未保存
if self.output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
outputs = (hidden_states,)
if self.output_past:
outputs = outputs + (presents,)
if self.output_hidden_states:
outputs = outputs + (all_hidden_states,)
if self.output_attentions:
# let the number of heads free (-1) so we can extract attention even after head pruning
attention_output_shape = input_shape[:-1] + (-1,) + all_attentions[0].shape[-2:]
all_attentions = tuple(t.view(*attention_output_shape) for t in all_attentions)
outputs = outputs + (all_attentions,)
return outputs # last hidden state, (presents), (all hidden_states), (attentions)
打包保存所有结果。
至此,huggingface/transformers的Pytorch版本GPT-2模型中的Transformer部分就结束了。
可能大家会问,这怎么看上去像只有Encoder部分啊?事实上这是因为GPT2虽然只用到的是Decoder部分,但既然没有Encoder部分,自然就没有Encoder输出的K,V与Decoder的Q计算的“encoder-decoder attention”层了。所以只是将Encoder中的Multi-Head Attention换成了Masked Multi-Head Attention。而后者在论文中是Decoder部分的,所以才有了GPT2用了Transformer的Decoder部分,BERT用了Transformer的Encoder部分的说法。
之后我会继续更新其他BERT类模型的论文,博客摘要及翻译,还有详细的代码分析!