【数据挖掘】基于K均值聚类的离群点检测(python实现)
一、python代码
'''
Author: Vici__
date: 2020/5/21
'''
import math
import random
import numpy as np
'''
Point类,记录坐标x,y和点的名字id
'''
class Point:
'''
初始化函数
'''
def __init__(self, x, y):
self.x = x # 横坐标
self.y = y # 纵坐标
'''
计算两点之间的欧几里得距离
'''
def calc_Euclidean_distance(self, p2):
return math.sqrt((self.x - p2.x) * (self.x - p2.x) + (self.y - p2.y) * (self.y - p2.y))
'''
1. 获取数据集
'''
def get_dataset():
# 原始数据集以元组形式存放,(横坐标,纵坐标,名字)
datas = [(0, 0), (1, 2), (3, 1), (8, 8), (9, 10), (10, 7), (10, 1)]
dataset = [] # 用于计算两点之间的距离,形式 [point1, point2...]
id_point_dict = {} # 编号和点的映射
temp_list = []
for i in range(len(datas)): # 遍历原始数据集
point = Point(datas[i][0], datas[i][1]) # 利用(横坐标,纵坐标,编号)实例化
id_point_dict[str(i)] = point
dataset.append(point) # 放入dataset中
temp_list.append(point)
return dataset, id_point_dict # [p1, p2], {id: point}
'''
2. 计算离散因子,找到离散群
'''
def find_discrete(group, id_point_dict, n):
print("2. 计算离散因子,找出离散群")
index_centroids = {}
for k, v in group.items():
xs = [] # 当前簇的所有x坐标
ys = [] # 当前簇的所有y坐标
for i in v: # 遍历当前簇集合
point = id_point_dict[str(i)] # 获取点的x,y坐标
xs.append(point.x)
ys.append(point.y)
x_mean = np.mean(np.array(xs), axis=0) # 计算x均值
y_mean = np.mean(np.array(ys), axis=0) # 计算y均值
index_centroids[k]= (x_mean, y_mean)
dis = {}
OF2 = {}
for k1, v1 in index_centroids.items():
for k2, v2 in index_centroids.items():
if k1 == k2:
continue
dis[(k1, k2)] = ((v1[0]-v2[0])**2 + (v1[1]-v2[1])**2)**0.5
res = None
Max = -1
for k1, v1 in group.items():
OF2[k1] = 0
for k2, v2 in group.items():
if k1 == k2:
continue
OF2[k1] += (len(group[k2]) / n) * dis[(k1, k2)]
if OF2[k1] > Max:
Max = OF2[k1]
res = k1
print("簇心间的距离:")
for k, v in dis.items():
print(group[k[0]], group[k[1]], v)
print("离散因子:")
for k, v in OF2.items():
print(group[k], v)
print("离散群为:")
print(group[res])
'''
3. KMeans主函数
'''
def KMeans(dataset, k, id_point_dict):
n = len(dataset) # 数据集中点的个数
centroids = random.sample([x for x in range(len(dataset))], k) # 随机选取k个点作为初始质心点
index = n # 用于给新的质心点编号
pre_answer = {} # 上一次的分成的簇的结果,用于和新生成的作比较,判断是否继续执行算法
while True:
answer = {} # 根据质心分的簇
for j in centroids: # 遍历质心,给每一个质心编号定义一个集合
answer[str(j)] = set()
for i in range(n): # 遍历数据集
Min = float("INF") # 用于寻找当前点最接近哪个质心
Min_index = -1
for j in centroids: # 遍历质心
point_i = id_point_dict[str(i)] # 数据集中的点
point_j = id_point_dict[str(j)] # 质心点
dist = point_j.calc_Euclidean_distance(point_i) # 计算两点距离
print(i, j, dist)
if dist < Min: # 寻找当前点最接近哪个质心
Min = dist
Min_index = j
# 得到结果:i这个点是Min_index的小弟
answer[str(Min_index)].add(i) # 放入相应集合中
centroids.clear() # 清除之前的质心点
# 遍历answer计算新的质心
for v in answer.values():
xs = [] # 当前簇的所有x坐标
ys = [] # 当前簇的所有y坐标
for i in v: # 遍历当前簇集合
point = id_point_dict[str(i)] # 获取点的x,y坐标
xs.append(point.x)
ys.append(point.y)
x_mean = np.mean(np.array(xs), axis=0) # 计算x均值
y_mean = np.mean(np.array(ys), axis=0) # 计算y均值
print(x_mean, y_mean)
new_point = Point(x_mean, y_mean) # 定义新质心点
id_point_dict[str(index)] = new_point # 放入编号到点的映射中
centroids.append(index) # 放入质心列表中
index += 1
# 检查是否继续
count = 0
for v1 in answer.values(): # 遍历旧簇组合
for v2 in pre_answer.values(): # 遍历新簇组合
if list(v1) == list(v2): # 如果两个集合相同
count += 1 # 计数
if count == k: # 如果集合相同的个数等于簇的个数,说明answer和pre_answer相同
break # 结束算法即可
pre_answer = answer.copy() # 更新旧结果
# 打印每次循环得到的结果:
for v in answer.values():
print(v)
print("---------------------------------------")
find_discrete(pre_answer, id_point_dict, n)
# 测试
dataset, id_point_dict = get_dataset()
k = 3
KMeans(dataset, k, id_point_dict)二、测试
数据:
![]()
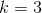
结果: