MASS: Masked Sequence to Sequence Pre-training for Language Generation阅读笔记
文章目录
- 模型
- 实验和结果
- Pre-training
- Fine-tuning
- NMT
- text summarization
- conversational response generation
模型
主要思想就是受到bert的启发,在生成领域搞一个预训练模型。
作者提出一个无监督的预测任务:
给定一个句子x∈X,对其中从u到v的token进行掩盖,形成一个序列:
![]()
被遮盖的token统一用一个标识符替换:
![]()
模型输入遮盖后的序列:
![]()
输出被遮盖的片段:
![]()
用对数似然作为目标函数:
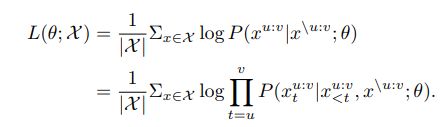
模型图:
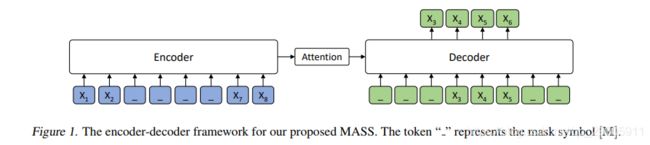
模型采用transformer,因为考虑到它在多个sequence to sequence learning任务上取得了最佳性能。
模型有一个重要的超参数k,k表示被掩盖的token数量,当k取一些特殊值时,模型对应了masked language modeling in bert或standard language modeling in GPT。


MASS设计用于联合预训练encoder和decoder,以完成语言生成任务。首先,通过一个sequence to sequence的框架,MASS只预测被屏蔽的token,从而迫使encoder理解未屏蔽令牌的含义,并鼓励decoder从encoder端提取有用的信息。其次,通过预测decoder端连续的token,decoder可以构建比仅预测离散token更好的语言建模能力。第三,通过进一步屏蔽在encoder中没有被屏蔽的decoder的input token(比如在上面的例子中,在预测片段x3x4x5x6时,只将token x3x4x5作为输入,并对其他token进行屏蔽),鼓励decoder从encoder端提取更多有用的信息,而不是利用前面token中的丰富信息。
实验和结果
Pre-training
选择Transformer作为基本的模型结构,包括6层的encoder和6层的decoder,1024 embedding/hidden size和4096 feed-forward filter size。
对于神经机器翻译任务,在源语言和目标语言的单语数据上对模型进行了预训练。分别对三种语言对进行实验:英法,英德,英罗。对于其他语言生成任务,包括文本摘要和会话响应生成,分别用英语单语数据对模型进行预训练。在神经机器翻译中,为了使模型能够区分源语言和目标语言,对encoder和decoder的每一个input token,都增加一个language embedding。
预训练细节:
选择一个随机的position u,然后对序列进行屏蔽替换。encoder中的屏蔽token 80%是[M],10%是随机token,10%是不变token。将片段长度k设置为句子中token总数的50%左右,并研究不同的k来比较它们的准确性变化。为了减少计算压力,移除了对屏蔽片段的填充,但是其他的token位置不变。使用Adam optimizer,学习速率是10−4。该模型在8张NVIDIA V100 GPU卡上进行训练,每个mini-batch包含3000个token用于pre-training。
Fine-tuning
NMT