《离线和实时大数据开发实战》_Hive原理实践_读书笔记
Hive原理实践
- Hive让数据的直接使用人员都能使用Hadoop的大数据处理能力,即使不会java编程
1、离线大数据处理的主要技术:Hive
1.2、Hive出现背景
- Hive是Facebook开发并贡献给Hadoop开源社区的;
- Hive是建立在Hadoop体系架构上的一层SQL抽象;
- Hive SQL是翻译为MapReduce任务后再Hadoop集群执行的,而Hadoop是一个批处理系统,所以Hive SQL是高延迟的,
- Hive不能提供数据排序和查询缓存功能,也不提供在线事务处理,更不能提供实时的查询和记录级的更新,但他能更好地处理不变的大规模数据集,
1.3、Hive基本架构
- 主要组件包括UI组件,Driver组件,Metastore组件,CLI,JDBC/ODBC,Thrift Server和Hive Web Interface(HWI)等;
- Driver组件: 核心组件,包括Complier(编译器),Optimizer(优化器)和Executor(执行器);
- Metastore组件:运输局服务组件,这个组件存储Hive的元数据;Hive的元数据存储在关系数据库里,Hive支持MySQL;默认情况下,Hive元数据保存在内嵌的Derby数据库中;实际生产环境中,mysql更适合
- CLI:命令行接口;
- Thrift Server:提供JDBC和ODBC接入的能力,用来进行可扩展且跨语言的服务开发;
- Hive Web Interface(HWI):Hive客户端提供了一种通过网页方式访问Hive所提供的服务;
[外链图片转存失败(img-L0XARUDS-1566993315493)(.\assets\1561557097673.png)]
[外链图片转存失败(img-khAH5bKB-1566993315494)(assets/1566963632873.png)]
2、Hive SQL
- Hive SQL和MySQL的SQL方言最为接近,但两者之间也有差异,比如Hive不支持行级数据插入(有insert 但不适合使用),更新和删除,也不支持事务等;
2.1、Hive关键概念
-
Hive数据库:Hive中的数据库从本质上来说仅仅是一个目录或者命名空间;但是它可以避免表名冲突,等同于关系型数据库中的数据库概念;
-
Hive表:每一个表在hive中都有一个对应的目录存储数据,如果没有指定表的数据库,那么hive会通过{HIVE_HOME}/conf/hive-site.xml配置文件中的hive.metastore.warehouse.dir属性来使用默认值(一般是/user/hive/warehouse),所有的table数据都保存在这个目录中;
-
内部表(managed table):即hive管理的表,数据将真实存在于表所在的目录中,删除内部表时,物理数据和文件也一并删除;
create table my_managed_table(coll STRING); LOAD DATA INPATH '/user/root/test_data.txt' INTO TABLE my_managed_table; --删除表 DROP TABLE my_managed_table; -
外部表(external table):新建表仅仅是指向一个外部目录而已,真实数据在外部,删除时,只是删除了引用和定义
CREATE EXTERNAL TABLE external_table(dummy STRING) LOCATIOIN '/user/root/external_table'; LOAD DATA INPATH '/user/root/data.txt' INTO TABLE external_table; --指定external关键字后,hive不会将数据移动到warehouse目录中;事实上,Hive甚至不会校验外部表的目录是否存在;这使的我们可以在创建表之后再创建数据 -
常见的模式是使用外部表访问存储的 HDFS (通常由其他工具创建)中的初始数据,然后使用 Hive 转换数据并将其结果放在内部表中;
-
使用外部表的另一种场景是针对一个数据集,关联多个 Schema;schema(发音 “skee-muh” 或者“skee-mah”,中文叫模式)是数据库的组织和结构,schemas andschemata都可以作为复数形式。模式中包含了schema对象,可以是表(table)、列(column)、数据类型(data type)、视图(view)、存储过程(stored procedures)、关系(relationships)、主键(primary key)、**外键(**foreign key)等。数据库模式可以用一个可视化的图来表示,它显示了数据库对象及其相互之间的关系;MySQL的文档中指出,在物理上,模式与数据库是同义的,所以,模式和数据库是一回事
-
-
分区和桶
-
分区(partition):
-- 创建表时要用partitioned by定义 create table logs (ts bigint, line string) partitioned by (dt stirng, country string); --当导入数据到分区表时,分区的值被显示指定: load data inpath '/user/root/path' into table logs partition (dt='2001-01-01',country='gb');--通过日期划分后,还可以通过国家分) --如下代码仅会扫描2001-01-01目录下的GB目录 select ts, dt ,line from logs where dt = '2001-01-01' and country='GB';
-
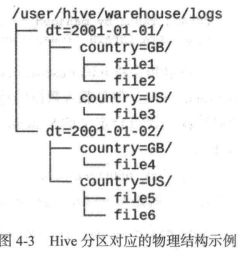
-
分桶(bucket):
--clustered by指定;根据id进行分桶,并且分为4个桶 create table bucketed_users(id int, name string) clustered by (id) into 4 buckets; --分桶时,hive根据字段哈希后取余数来决定数据应该放在哪个桶,因此每个桶都是整体数据的随机抽样 --设置hive.enforce.bucketing属性为true可以把分桶的工作交给hive完成,如果是在hive执行命令,先开启分桶和设定reduce个数;否则无效 set hive.enforce.bucketing=true; set mapreduce.job.reduces=3; --分桶加载数据,用insert overwrite;像load data只会有一个文件,数据就不符合分桶的意义了 insert overwrite table bucketed_users select * from course_common cluster by(c_id)- 可以高效查询,高效地进行抽样;分桶相当于干了MapReduce中的自定义分区;
- 分桶,就是将数据按照指定的字段进行划分到多个文件当中去
2.2、Hive数据库
-
创建数据库
create (database|schema) [if not exists] database_name [comment databese_comment] [location hdfs_path] [with dbproperties (property_name = property_value,...)]; --例如 create database my_hive_testdb if not exists comment 'this is my first hive database' with dbproperties('creator'=tone,'date'='2019-01-01'); -
切换数据库
use my_hive_testdb; -
查看数据库
describe database my_hive_testdb; -
删除数据库
drop database my_hive_testdb; --默认情况下,hive不允许用户删除一个包含表的数据库 --可以先删除库中的表,再删库 --也可以在删除命令的最后加上关键字cascade,谨慎使用; drop database my_hive_testdb cascade; -
查看所有数据库
show databases;
2.3、Hive表DDL
- 创建表
CREATE [EXTERNAL] TABLE [工 NOT EXISTS] table_name
[(col_name data_type (COMMENT col_comment ],…)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], •• • )]
[CLUSTERED BY (col_name, col_name, ••• )
[SORTED BY (col_name [ASC|DESC], ••• )]INTO num_buckets BUCKETS]
[ROW FORMAT row format]
[STORED AS file format]
[LOCATION ON hdfs_path]
-
create table:用于创建一个指定名字的表 如果相同名字的表已经存在,则抛
出异常 用户可以用 IF NOT EXIST 选项来忽略这个异常;
-
external: 该关键字可以让用户创建一个外部表,在创建表的同时指定一个指向实际数据的路径(location)
-
comment: 可以为表与字段增加描述
-
row format: 如没有指定row format 或者row format delimited ,将会使用自带的SerDe(序列化和反序列化);在创建表时,用户还需要为表指定列,同时也会指定自定义的 SerDe; Hive 通过 SerDe 确定表的具体的列的数据
DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char] [MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char] | SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value,property_name=property_value,...)]-
SerDe说明hive如何去处理一条记录,包括Serialize/Deserilize两个功能, Serialize把hive使用的java object转换成能写入hdfs的字节序列,或者其他系统能识别的流文件。Deserilize把字符串或者二进制流转换成hive能识别的java object对象。比如:select语句会用到Serialize对象, 把hdfs数据解析出来;insert语句会使用Deserilize,数据写入hdfs系统,需要把数据序列化。
-
SerDe包括内置类型
Avro,ORC,RegEx,Thrift,Parquet,CSV,JsonSerDe
-
可以自定义serDe类型
-
-
stored as: 如果文件数据是纯文本,则使用stored as textfile;如果数据需要压缩,则使用stored as sequence;
SEQUENCEFILE | TEXTFILE | RCFILE | INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname -
like : 允许用户复制现有的表结构,但不是复制数据;
create table pokes(foo int , bar string); create table empty_key_value_store like key_value_store; --另外还可以通过create table as select创建表 create table empty_key_value_store row format serde "org.apache.Hadoop.hive.serde2.columnar.ColumnarSerDe" stored as RCFile as select (key % 1024) new_key,concat(key,value) key_value_pair from key_value_store sort by new_key,key_value_pair;
-
修改表
-
修改表名
ALTER TABLE old table name RENAME TO new table name; -
修改列名
alter table table_name change [column] old_col_name new_col_name column_type [comment col_comment] [first|after column_name]; --添加列名 alter table pokes add columns (new_col int comment 'new col comment');
-
-
删除表
drop table my_table;
– 只想删除表结构,保留表结构,跟mysql类似,使用TRUNCATE语句
truncate table my_table; -
插入表
- 向表中加载数据
load data [local] inpath 'filepath' [overwrite] into table tablename [partition (partcoll=val1,partcol2=val2 ...)]; --load操作只是单纯的复制/移动操作,将数据文件移动到hive表对应的位置 --filepath可以是相对路径,比如project/datal就是/user/hive/project/datal,也可以是绝对路径,或者包含模式的完整路径 hdfs://namenode:9000/user/hive/project/datal -- 相对路径示列 load data local inpath './examples/files/kv1.txt' overwrite into table pokes;- 将查询结果插入hive表
--基本模式 insert overwrite table tablename1 [partition (partcoll = val1,partcol2 = val2 ...)] select_statement from from_statement; --多插入模式 insert overwrite table tablename1 [partition (partcoll=val1,partcol2=val2 ...)] select_statement1 [insert overwrite table tablename2 [partition ...] select_statement2] ... --自动分区模式 insert overwrite table tablename partition (partcoll[=val1],partcol2[=val2] ..) select_statement from from_statement;
2.4、Hive表DML
-
基本的select操作
select [all | distinct] select_expr,select_expr,... from table_reference [where where_confition] [group by col_list [having condition]] [cluster by col_list | [distribute by col_list] [sort by|order by col_list]] [limit number];-
all和distinct选项区分对重复记录的处理;默认是all,查询所有记录;
-
where条件:支持and,or,between,in,not in等;
-
order by与sort by的不同:order by指全局排序,只有一个Reduce任务,而sort by只在本机做排序,单个MapReduce内部排序;
-
limit:限制查询的记录数;也可以实现Top K查询,比如先的查询语句可以查询销售记录最多的5个销售代表:
set mapred .reduce.tasks=1; select * from test sort by amount desc limit 5; -
regex column specification:select语句可以使用正则表达式做列选择;如下面的语句查询了ds和hr之外的所有列
select '(ds|hr)?+.+' from test;
-
-
join表
join_table:
table_reference (INNER] JOIN table_factor (join_condition]
| table_reference {LEFTIRIGHTjFULL} (OUTER] JOIN table_reference join_ condition
| table_reference LEFT SEM JOIN table_reference join_condition
| table_reference CROSS JOIN table_reference (join_condition] (as of Hive 0.10)
table reference:
table_factor
| join_table
table_factor:
tbl_name [alias]
| table_subquery alias
| (table_references)
join_condition:
on expression-
Hive中只支持等值连接,外连接和左半连接(left semi join),(从2.2.0版本后支持非等值连接);
-
可以连接2个以上的表,如
select a.val, b.val,c.val from a join b on (a.key=b.key1) join c on(c.key = b.key2); -
如果连接中多个表的join key是同一个,则连接会被转化为单个Map/Reduce任务,如;
select a.val,b.val,c.val from a join b on (a.key=b.key1) join c on(c.key=b.key1);
-
-
join时大表放在最后: Reduce会缓存join序列中除最后一个表之外的所有表的记录,再通过最后一个表将结果序列化到文件系统;
-
如果想限制join的输出, 应该在where子句中写过滤条件,或是在join子句中写;
-
但是有表分区的情况,,比如下面的第一个 SQL 语句所示,如果d表中找不到对应c表的记录, d表的所有列都会列出 NULL ,包括 ds列。 也就是说, join 会过滤d表中不能找到匹配c表 join key 的所有记录。 这样, LEFT OUTER 就使得查询结果与 WHERE 子句无关,解决办法是在join 时指定分区(如下面的第二个 QL 语句所示):
--第一个 SQL 语句 SELECT c.val, d.val FROM c LEFT OUTER JOIN d ON (c.key=d.key) WHERE a.ds='2010-07-07' AND b.ds='2010-07-07' -- 第二个 SQL 语句 SELECT c.val, d.val FROM c LEFT OUTER JOIN d ON (c.key=d.key AND d.ds=’ 2009-07-07 ’ AND c.ds='2009-07-07')
-
-
left semi join是in/exists子查询的一种更高效的实现; join子句中右边的表只能在on子句中设置过滤条件,在where中,select中或其他地方过滤都不行;
SELECT a.key, a.value FROM a WHERE a.key in (SELECT b.key FROM B); --可以被重写为: SELECT a.key, a.val FROM a LEFT SEMI JOIN b on (a.key = b.key)
3、Hive SQL执行原理图解
3.1、select语句执行图解
-
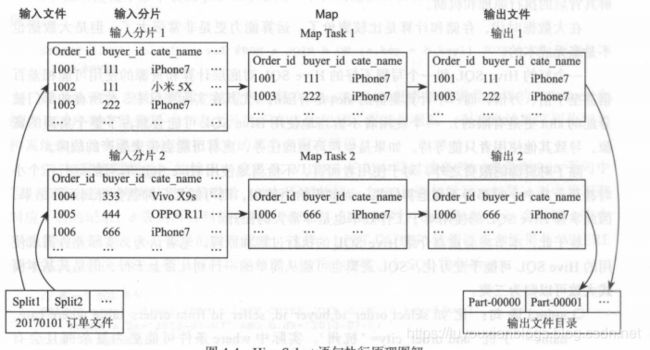
考虑如下的Hsql语句
select order_id,buyer_id,cate_name from orders_table where day='20170101' and cate_name='iphone7';-
业务背景:分析苹果手机iPhone7的客户情况
-
底层MapReduce执行过程如图:
-
-
即输入分片、Map阶段、shuffle阶段和Reduce阶段等
- 输入分片: 分片(split)大小为128MB,
- Map阶段: map任务的个数有分片阶段的split个数决定;在map函数中将其过滤, 获取select语句中指定的列值,并保存到本地文件中;
- Shuffle和Reduce阶段: 此SQL任务不涉及数据的重新分发和分布,不需要启动任何的Reduce任务;
- 输出文件: Hadoop直接合并Map任务的输出文件到输出目录; map任务是并行执行的;
3.2、group by语句执行图解
-
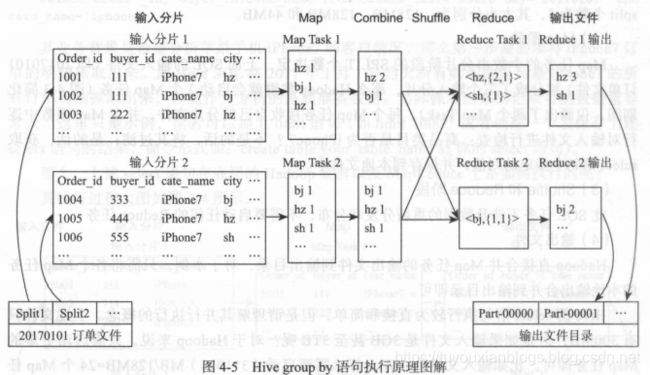
业务背景:分析购买iPhone7客户在各城市中的分布情况,即哪个城市购买得最多、哪个最少;
select city,count(order_id) as iphone7_count from orders_table where day='201901010' and cat_name='iphone7' group by city;- 底层MapReduce执行过程
-
输入分片
-
Map阶段:每个 ma 任务处理 其对应分片文件中的每行,检查其商品类目是否为 Phone7 ,如果是,则输出形如<city,1 >的键值对,因为需要按照 city 对订单数目进行统计(注意和 select 语句的不同)
-
Combiner阶段
- Combiner 阶段是可选的,如果指定了 Combiner 操作,那么 Hadoop 会在 Map 任务的地输出中执行 Combiner 操作,其好处是可以去除冗余输出,避免不必要的后续处理和网络传输开销等
- 此列中,Map Task1 的输出中< hz,1 >出现了两次,那么 Combi ner 操作就可以将其合并为
- Combiner 操作是有风险的,使用它的原则是 Combiner 的输出不会影响到 Reduce 计算的最终输入,例如,如果计算只是求总数、最大值和最小值,可以使用 combiner ,但是如果做平均值计算使用了 Combiner ,最终的 Reduce 计算结果就会出错;
-
shuffle阶段;完整的shuffle包括分区(partition),排序(sort)和分隔(spill),复制(copy),合并(merge)等过程;
- 对于理解group by语句,关键的过程实际就两个,即分区和合并;所谓分区,即 Hadoop 如何决定将每个 Map 任务的、每个输出键值对分配到那个 Reduce Task 所谓合井,即在 一个Reduce Task 中,如何将来自于多个 Map Task 的同样一个键的值进行合并;
- Hadoop 中最为常用的分区方法是 Hash Partitioner ,即 Hadoop 会对每个键取 hash 值,然后再对此 hash值按照reduce 任务数目取模,从而得到对应的 reducer ,这样保证相同的键,肯定被分配到同一个 reducr 上,同时 hash 函数也能确保 Map 任务的输出被均匀地分配到所有的 Reduce务上。
-
Reduce阶段: 调用reduce函数,每个reduce任务的输出存到本地文件中;
-
输出文件: hadoop合并Reduce Task任务的输出文件到输出目录;
3.3、join语句执行图解
-
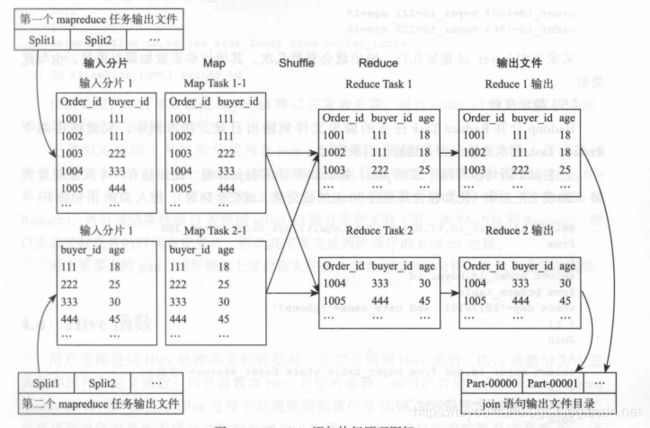
业务背景:分析购买iPhone7的客户的年龄分布情况,订单表只包含了客户的ID看,客户的年龄保存在另一个买家表中
Select tl.order_id,tl.buyer_id,t2.age From ( select order id,buyer id from orders table where day='20170101' and cate_name='iphone7' ) tl Join ( select buyer_id,age from buyer_table where buyer_status ='有效' ) t2 On tl.buyer_id=t2.buyer_id ;-
上述的join SQL在Hadoop集群中会被拆分为成三个MapReduce任务。即t1表部分、t2表部分、t1和t2表join过程;
-
Hive SQL join 语句也涉及数据的重新分发和分布,但不同于 group by 语句的是, group by 语句会根据 group by 的列进行数据重分布和分发,而 join 语句则根据 join 列进行数据的重分布和分发(在此即为根据 buyer_id 进行数据 分发和分布)
-
下图是第三个MapReduce任务的执行过程
-
-
输入分片
-
Map阶段
-
Shuffle阶段: 主要是partiotion,
-
Reduce阶段:
-
输出文件
4、Hive函数
-
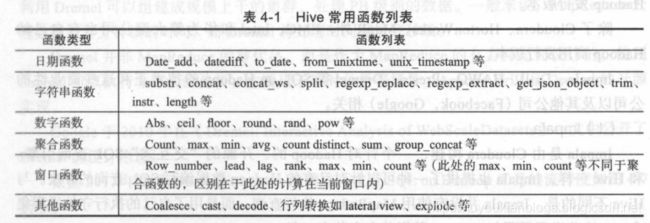
内置函数
[外链图片转存失败(img-9IrOQKKc-1566993315496)(.\assets\1561631546464.png)]
-
用户自定义函数:请参考Hive的UDF开发指南
5、其他SQL on Hadoop技术
- 如Impala、Drill、HAWQ、Presto、Dremel等;
roup by 语句的是, group by 语句会根据 group by 的列进行数据重分布和分发,而 join 语句则根据 join 列进行数据的重分布和分发(在此即为根据 buyer_id 进行数据 分发和分布)
-
下图是第三个MapReduce任务的执行过程
[外链图片转存中…(img-KSeHUfli-1566993315496)]
-
输入分片
-
Map阶段
-
Shuffle阶段: 主要是partiotion,
-
Reduce阶段:
-
输出文件
4、Hive函数
- 内置函数
- 用户自定义函数:请参考Hive的UDF开发指南
5、其他SQL on Hadoop技术
- 如Impala、Drill、HAWQ、Presto、Dremel等;
