文本表示:从one-hot到word2vec
文章目录
- 从one-hot到word2vec
- one-hot向量
- word2vec
- CBOW模型
- Skip-gram模型
- 使用gensim库中的Word2Vec
- 参考资料
从one-hot到word2vec
one-hot向量
词向量的意思就是通过一个数字组成的向量来表示一个词,这个向量的构成可以有很多种。其中,比较简单的方式就是所谓的one-hot向量。
假设在一个语料集合中,一种有n个不同的词,则可以使用一个长度为n的向量,对于第i个词 ( i = 0... n − 1 ) (i=0...n-1) (i=0...n−1),向量index=i处值为1外,向量其他位置的值都为0,这样就可以唯一地通过一个 [ 0 , 0 , 1 , . . . , 0 , 0 ] [0,0,1,...,0,0] [0,0,1,...,0,0]形式的向量表示一个词。one-hot向量比较简单也容易理解,但是有很多问题。比如当加入新词时,整个向量的长度会改变,并且存在维度过高难以计算的问题,以及向量的表示方法很难体现两个词之间的关系。
- 优点:简单易懂、稀疏存储
- 缺点:维度灾难、词汇鸿沟(向量之间都是孤立的)
sklearn实现one-hot encode
from sklearn import preprocessing
enc = preprocessing.OneHotEncoder() # 创建对象
enc.fit([[0,0,3],[1,1,0],[0,2,1],[1,0,2]]) # 拟合
array = enc.transform([[0,1,3]]).toarray() # 转化
print(array)
word2vec
当今互联网迅猛发展,每天都在产生大量的文本、图片、语音和视频数据,要对这些数据进行处理并从中挖掘出有价值的信息,离不开NLP,其中统计语言模型 就是很重要的一环,它是所有NLP的基础,被广泛应用于语音识别、机器翻译、分词、词性标注和信息检索等任务。
2013年Google开源了一款直接计算低微词向量的工具----Word2Vec,不仅能够在百万级的词典亿级数据集上高效训练,而且能够很好的度量词与词之间的相似性。
对原始NNLM的改进:
- 移除前向反馈神经网络中的非线性hidden layer,直接将中间层的embedding layer 与 softmax layer连接
- 输入所有词向量到一个embedding layer 中
- 将特征词嵌入上下文环境
- 后续还在训练方法上进行了优化:层次softmax以及负采样技术
word2vec两种训练方式:
- Continuous Bag of Words Model和Skip-Gram
word2vec两种优化方式:
- hierarchical softmax 和negative sampling
所以说Word2vec一共可以有四种模型。具体参考Word2Vec
CBOW模型
模型框架:

网络结构:

损失函数:

Skip-gram模型
模型框架:

网络结构:
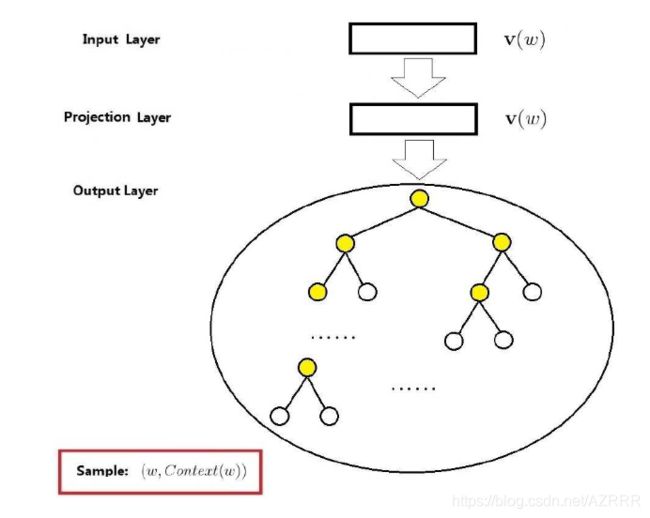
损失函数:

使用gensim库中的Word2Vec
生成的是今年某狐算法大赛的100维的词向量,allcontent是分词后的数据
from gensim.models import Word2Vec
word2vec_dir = './vector/word2vec.model'
vector_size = 100
print('word2vec')
if not os.path.exists(word2vec_dir):
model = Word2Vec(all_content, size=vector_size, min_count=1, workers=20, iter=20, window=8)
model.save(word2vec_dir)
else:
model = Word2Vec.load(word2vec_dir)
参考资料
word2vec中的数学原理详解
词向量(从one-hot到word2vec)
one-hot向量与word2vec