python︱批量操作文件(os)、图片操作技巧(下载网络图片、skimage.io)
文章目录
- @[toc]
- . 一、遍历操作文件
- 1、文件名字获取
- **注意,不能`import glob` ,不然就会报错:**
- 2、批量重命名文件os.rename
- 直接修改了上级目录,test2、test3 . 3、判断是否为路径或文件
- . 4、路径合并与分割
- 分隔文件和扩展名 . 5、创建、改变工作目录
- 6、删除以及重命名文件
- 其中shutil.copy很关键,是文件->文件夹的迁移。 . 8、文件大小
- 二、批量操作图像函数:ImageCollection
- 1、批量导入某文件夹下的所有格式的图像
- 2、图像格式png-jpg批量转化
- 3、图像批量灰化、调整后保存
- 4、视频图像化
- 5、批量删除特定格式的照片
- . 6、imghdr 图像格式识别函数
- 延伸一:skimage.io的介绍
- 延伸二:图片如何resize
- 延伸三:批量合并文件夹+提取特定格式的图片方式
- 延伸四:视频下载神器you-get库(一个可以看片的Python库)
- 延伸五:深度学习中.jpg图像读取失败原因
- 延伸六:获取当级文件夹
- 延伸七:图像画框+写中文+python3读写中文
- 延伸八:计算图片中两个矩形框的重叠部分 IOU计算
文章目录
- @[toc]
- . 一、遍历操作文件
- 1、文件名字获取
- **注意,不能`import glob` ,不然就会报错:**
- 2、批量重命名文件os.rename
- 直接修改了上级目录,test2、test3 . 3、判断是否为路径或文件
- . 4、路径合并与分割
- 分隔文件和扩展名 . 5、创建、改变工作目录
- 6、删除以及重命名文件
- 其中shutil.copy很关键,是文件->文件夹的迁移。 . 8、文件大小
- 二、批量操作图像函数:ImageCollection
- 1、批量导入某文件夹下的所有格式的图像
- 2、图像格式png-jpg批量转化
- 3、图像批量灰化、调整后保存
- 4、视频图像化
- 5、批量删除特定格式的照片
- . 6、imghdr 图像格式识别函数
- 延伸一:skimage.io的介绍
- 延伸二:图片如何resize
- 延伸三:批量合并文件夹+提取特定格式的图片方式
- 延伸四:视频下载神器you-get库(一个可以看片的Python库)
- 延伸五:深度学习中.jpg图像读取失败原因
- 延伸六:获取当级文件夹
- 延伸七:图像画框+写中文+python3读写中文
- 延伸八:计算图片中两个矩形框的重叠部分 IOU计算
.
一、遍历操作文件
1、文件名字获取
相关帖子: 一句python,一句R︱模块导入与查看、数据读写出入、数据查看函数、数据类型、遍历文件
os.listdir:返回的是该文件夹下的所有文件名称;
os.walk:可以返回父文件夹路径+文件夹下路径,貌似比较给力。
网上有帮他们打包成函数的博客:Python遍历目录的4种方法实例介绍
#!/usr/bin/python
import os
from glob import glob
def printSeparator(func):
def deco(path):
print("call method %s, result is:" % func.__name__)
print("-" * 40)
func(path)
print("=" * 40)
return deco
@printSeparator
def traverseDirByShell(path):
for f in os.popen('ls ' + path):
print f.strip()
@printSeparator
def traverseDirByGlob(path):
path = os.path.expanduser(path)
for f in glob(path + '/*'):
print f.strip()
@printSeparator
def traverseDirByListdir(path):
path = os.path.expanduser(path)
for f in os.listdir(path):
print f.strip()
@printSeparator
def traverseDirByOSWalk(path):
path = os.path.expanduser(path)
for (dirname, subdir, subfile) in os.walk(path):
#print('dirname is %s, subdir is %s, subfile is %s' % (dirname, subdir, subfile))
print('[' + dirname + ']')
for f in subfile:
print(os.path.join(dirname, f))
if __name__ == '__main__':
path = r'~/src/py'
traverseDirByGlob(path)
traverseDirByGlob(path)
traverseDirByListdir(path)
traverseDirByOSWalk(path)
- 1、traverseDirByGlob、traverseDirByOSWalk两种函数可以拿到带全部路径的文件,直达最、最、最低层,类似:
def traverseDirByOSWalk(path):
out = []
path = os.path.expanduser(path)
for (dirname, subdir, subfile) in os.walk(path):
#print('dirname is %s, subdir is %s, subfile is %s' % (dirname, subdir, subfile))
#print('[' + dirname + ']')
for f in subfile:
#print(os.path.join(dirname, f))
out.append(os.path.join(dirname, f))
return out
/data/trainlmdb/val/test_female/image_00009.jpg
返回的是一个list
- 2、traverseDirByListdir(path)可以拿到里面的文件名:
image_00009.jpg
当然这个函数里面是print出来的。基于笔者的小白级写函数方法,笔者改进:
from glob import glob
def traverseDirByGlob(path):
path = os.path.expanduser(path)
list={}
i=0
for f in glob(path + '/*'):
list[i]=f.strip()
i=i+1
return list
就可以跟其他的def函数一样return出来。
注意,不能import glob ,不然就会报错:
TypeError: 'module' object is not callable
2、批量重命名文件os.rename
本节内容参考:python下os模块强大的重命名方法renames
import os, sys
ImageNames=os.listdir('C:\\Users\\Desktop')
for i in range(len(ImageNames)):
os.rename(ImageNames[1],np.str(i))
#
#reanames还可以修改二级目录
文件重命名函数有两个:rename,renames
rename可以修改最后文件名称,renames更厉害,连前一个目录都是可以修改。
把桌面上的文件名称都改为数字np.str(i)
renames则更强大的是:
os.renames("/tmp/test1/test3/test","/tmp/test/test2/test3")
# 批量修改文件名和目录名,嘿嘿,果然也成功了。
直接修改了上级目录,test2、test3
.
3、判断是否为路径或文件
参考博客《Python 文件夹及文件操作》
- os.path.isabs()
判断是否绝对路径
- os.path.exists()
判断是否真实存在
- os.path.isdir()
判断是否是个目录
- os.path.isfile()
判断是否是个文件
- ‘0.jpg’.endswith(’.jpg’)
返回true/false,可以判定数据格式是什么类型的
对大小写不敏感,并消除潜在的大型else-if链: - m.lower().endswith((’.png’, ‘.jpg’, ‘.jpeg’))
.
4、路径合并与分割
参考博客《Python 文件夹及文件操作》
- file_dir1=os.path.join(‘C:\desktop’,‘01.jpg’)
不要直接拼字符串,而要通过 os.path.join(part1,part2) 函数,这样可以正确处理不同操作系统的路径分隔符
- os.path.split(file_dir1)
分隔目录和文件名/文件夹名
- os.path.splitdrive(file_dir1)
分隔盘符(windows系统)
- os.path.splitext(file_dir1)
分隔文件和扩展名
.
5、创建、改变工作目录
参考博客《Python 文件夹及文件操作》
- os.getcwd()
获取当前工作目录
- os.chdir(…)
改变工作目录
- os.listdir(…)
列出目录下的文件
- os.mkdir(…)
创建单个目录 ,注意:创建多级用 os.makedirs()
- os.makedirs(…)
创建多级目录
for i in range(2,6):
dir_name = "test" + str(i)
os.mkdir(dir_name)
.
6、删除以及重命名文件
参考博客《Python 文件夹及文件操作》
- os.rmdir(…)
删除空文件夹
注意:必须为空文件夹 如需删除文件夹及其下所有文件,需用 shutil
- os.remove(…)
删除单一文件
- shutil.rmtree(…)
删除文件夹及其下所有文件
- shutil.rmtree(“test_mkdir”)
删除 test_mkdir 及其下所有文件
- os.rename(oldfileName, newFilename)
.
7、复制、移动文件/文件夹 shutil
参考博客《Python 文件夹及文件操作》
import os
import shutil
file_dir = "D:\\Python_shutil"
os.chdir(file_dir)
shutil.copyfile("test_org.txt","test_copy.txt")
# copy test_org.txt 为 test_copy.txt 若存在,则覆盖
shutil.copyfile("test_org.txt","test1.txt")
# 存在,覆盖
shutil.copytree("test_org","test_copytree")
# copy test_org 为 test_copytree(不存在的新目录)
shutil.copy("test_org.txt","test_copy1.txt")
# 同 copyfile
shutil.copy("test_org.txt","test_copy")
# 将文件 copy 至 目标文件夹中(须存在)
shutil.copy("test_org.txt","test_xxx")
# 将文件 copy 至 目标文件(该文件可不存在,注意类型!)
print os.listdir(os.getcwd())
shutil.move("test_org.txt","test_move") # 将文件 move 至 目标文件夹中
shutil.move("test_org","test_move") # 将文件夹 move 至 目标文件夹中
print os.listdir(os.getcwd())
其中shutil.copy很关键,是文件->文件夹的迁移。
.
8、文件大小
使用os.path.getsize函数,参数是文件的路径。
.
二、批量操作图像函数:ImageCollection
ImageCollection(load_pattern,load_func=None)
# load_func是一个回调函数,我们对图片进行批量处理就可以通过这个回调函数实现。用法可以自定义,很灵活
# load_pattern,图像路径
1、批量导入某文件夹下的所有格式的图像
import matplotlib.pyplot as plt
import skimage.io as io
from skimage import data_dir
str='C:\\Users\\Desktop\\image/*.jpg : C:\\Users\\Desktop\\image2/*.jpg'
coll = io.ImageCollection(str)
print(len(coll))
io.imshow(coll[2])
# 用:来串联
# 可以跨文件夹提取
io.ImageCollection可以通过并联加":"的方式将文件夹里面符合某一种格式的图像全部导入进来。导进来之后是RGB的numpy的array格式。
与caffe的ImageData很像。
可以通过io.imshow来展示图像。
2、图像格式png-jpg批量转化
ImagePath='C:\\Users\\Desktop\\image2'
# 保存路径
str=data_dir + ImagePath+'/*.png'
coll = io.ImageCollection(str)
for i in range(len(coll)):
io.imsave(ImagePath+'/'+np.str(i)+'.jpg',coll[i])
# 循环保存图片,保存函数,io.imsave
ImagePath是图片所在的文件夹,io.ImageCollection读入过,通过io.imsave将原来的图片,以数字为名字,jpg格式为后缀进行保存。
3、图像批量灰化、调整后保存
本节内容参考: http://www.cnblogs.com/denny402/p/5123772.html
from skimage import data_dir,io,transform,color
import numpy as np
def convert_gray(f):
rgb=io.imread(f) #依次读取rgb图片
gray=color.rgb2gray(rgb) #将rgb图片转换成灰度图
dst=transform.resize(gray,(256,256)) #将灰度图片大小转换为256*256
return dst
ImagePath='C:\\Users\\Desktop\\image2'
# 保存路径
str=data_dir + ImagePath+'/*.png'
coll = io.ImageCollection(str,load_func=convert_gray)
for i in range(len(coll)):
io.imsave(ImagePath+'/'+np.str(i)+'.jpg',coll[i]) #循环保存图片
convert_gray灰化+翻转函数,通过ImageCollection函数中的参数 load_func对导入图像进行处理。
然后通过io.imsave进行保存。
4、视频图像化
from skimage import data_dir,io,color
class AVILoader:
video_file = 'myvideo.avi'
def __call__(self, frame):
return video_read(self.video_file, frame)
avi_load = AVILoader()
frames = range(0, 1000, 10) # 0, 10, 20, ...
ic =io.ImageCollection(frames, load_func=avi_load)
这段代码的意思,就是将myvideo.avi这个视频中每隔10帧的图片读取出来,放在图片集合中。
5、批量删除特定格式的照片
def del_Image(root_dir):
file_list = os.listdir(root_dir)
for f in file_list:
file_path = os.path.join(root_dir, f)
if os.path.isfile(file_path):
if f.endswith(".BMP") or f.endswith(".bmp") or f.endswith(".gif") or f.endswith(".png"):
os.remove(file_path)
print " File removed! " + file_path
# elif os.path.isdir(file_path):
# print ' Done! '
# del_Image(file_path)
if __name__ == "__main__":
del_Image(path)
删除bmp,gif,png,BMP格式的图像。先用os.listdir遍历图像名称,os.path.join绝对路径,
os.path.isfile是否在这个文件夹里面,f.endswith像正则表达式类似。
.
6、imghdr 图像格式识别函数
# 了解图像的格式
imghdr.what(file)
# 转换格式
if imghdr.what(name) == "png":
Image.open(name).convert("RGB").save(name)
7、批量下载网络图片
来源于github:https://gist.github.com/dervn/1906384
import urllib
import urllib2# urllib.request
import os
picurl="http://images.51cto.com/files/uploadimg/20100630/104906665.jpg"
save_path="d:\\"
imgData = urllib2.urlopen(picurl).read()
# 给定图片存放名称
fileName = save_path + "\\ddd.jpg"
# 文件名是否存在
if os.path.exists(fileName):
output = open(fileName,'wb+')
output.write(imgData)
output.close()
print "Finished download \n"
print "运行完成"
如果是py3,那么需要改urllib2成: urllib.request
.
延伸一:skimage.io的介绍
- 1、从外部读取图片并显示
from skimage import io
img=io.imread('d:/dog.jpg')
# 读取彩图
io.imshow(img)
skimage.io.imread(fname,as_grey=True)
# 读取灰度图
io.imshow(img)
- 2、图片信息展示
io.imread之后,可以在spyder编辑器的右上角显示,也可以直接以程序方式打印输出:
from skimage import io,data
img=data.chelsea()
io.imshow(img)
print(type(img)) #显示类型
print(img.shape) #显示尺寸
print(img.shape[0]) #图片宽度
print(img.shape[1]) #图片高度
print(img.shape[2]) #图片通道数
print(img.size) #显示总像素个数
print(img.max()) #最大像素值
print(img.min()) #最小像素值
print(img.mean()) #像素平均值
3 如果读入是四通道的话,如何resize成三通道
from skimage import io
import numpy as np
post_url = "https://test-1d90ff.tcb.qcloud.la/wx3f25693fa7cc59a6-oHEZN5auAZM493O6AkCjgMOuxmBE-1589294298844.jpg"
#
img=io.imread(post_url)
# 读取彩图
io.imshow(img)
# 四通道,直接去掉最后一列的信息,也是等价的
img_2 = [[i[:3] for i in im] for im in img]
io.imshow(np.array(img_2))
.
延伸二:图片如何resize
笔者看到两种方式,一种是通过caffe内嵌的data.reshape,还有一种是PIL( Python Image Library ).
PIL 是 Python 平台处理图片的事实标准,兼具强大的功能和简洁的 API。PIL 的更新速度很慢,而且存在一些难以配置的问题,不推荐使用;而 Pillow 库则是 PIL 的一个分支,维护和开发活跃,Pillow 兼容 PIL 的绝大多数语法,推荐使用。
1、PIL
def resize_image(data, sz=(256, 256)):
"""
Resize image. Please use this resize logic for best results instead of the
caffe, since it was used to generate training dataset
:param str data:
The image data
:param sz tuple:
The resized image dimensions
:returns bytearray:
A byte array with the resized image
"""
img_data = str(data)
im = Image.open(StringIO(img_data))
if im.mode != "RGB":
im = im.convert('RGB')
imr = im.resize(sz, resample=Image.BILINEAR)
fh_im = StringIO()
imr.save(fh_im, format='JPEG')
fh_im.seek(0)
return bytearray(fh_im.read())
其中,先通过StringIO,将图片缓冲在内存中,
Image.open打开图片
2、caffe
net = caffe.Net(model_def,model_weights,caffe.TEST)
net.blobs['data'].reshape(50,3,227, 227)
.
延伸三:批量合并文件夹+提取特定格式的图片方式
额… 本节不是什么技巧,哈哈~
这批图像用windows里面的搜索功能,
键入:.jpg,就可以把所有图片全部找出来了,然后…你懂得!
.
延伸四:视频下载神器you-get库(一个可以看片的Python库)
github链接:https://github.com/soimort/you-get
是一种轻量级的命令行工具。
这是用you-get从该网站下载视频的运行效果图
网站链接:http://www.fsf.org/blogs/rms/20140407-geneva-tedx-talk-free-software-free-society
你可以为你做什么:
从流行的网站(如YouTube,优酷,Niconico等)下载视频/音频。 (查看支持的网站的完整列表)
在媒体播放器中串流播放线上影片。没有网络浏览器,没有更多的广告。
通过抓取网页下载图像(感兴趣的)。
下载任意非HTML内容,即二进制文件。
详细教程可以参考:视频下载神器you-get库(一个可以看片的Python库)
.
延伸五:深度学习中.jpg图像读取失败原因
笔者在导入.jpg会出现两种情况:
- 1、.jpg导入不了,报错truncated;
- 2、图片尤其是png.(虽然后缀是jpg)格式的图片会出现,无法转换为np.array
情况一(参考链接):
ValueError: Could not load ""
Reason: "image file is truncated (2 bytes not processed)"
笔者在使用caffe时候,出现以上报错,明明是一个好的jpg图像,为啥读不进去呢?
这时候就需要额外导入以下代码:
from PIL import ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True
情况二:(参考链接)
libpng error: Read Error
以上的解决方法:
import cv2, random
import os
import numpy as np
from PIL import Image
from PIL import ImageFile
import imghdr
ImageFile.LOAD_TRUNCATED_IMAGES = True
if imghdr.what(name) == "png":
Image.open(name).convert("RGB").save(name)
img = cv2.imread(name)
img = np.array(Image.open(name))
转换一下格式为RGB
.
延伸六:获取当级文件夹
folder_descriptors(folder) for folder in glob.glob(input_folder + '/*')
看看这段代码中的,glob.glob,获得了input_folder文件夹,平级的所有文件夹内容
延伸七:图像画框+写中文+python3读写中文
1.python3,中文路径,读写
python3中,路径中若有中文,比较麻烦,跟一般的读写方式不一样(参考)。
import cv2
from matplotlib import pyplot as plt
# 读入
img = cv2.imdecode(np.fromfile('..\\1.jpg',dtype = np.uint8),1)
# 写出
cv2.imwrite("..\\1.jpg",img, [int(cv2.IMWRITE_JPEG_QUALITY), 100] )
cv2.imencode('/中文路径/1.jpg', img)[1].tofile('..\\file')
2.写文字 + 画框
(187,176),(241,205)代表左上角,右下角,或者是(x,y)(x+width,y+height)或者另外一种写法:(left,top)(left+width,top+height),当然还有一些写法:(x,y,x+w,y+h)
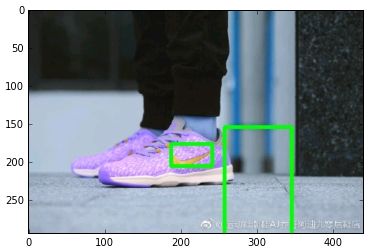
这里得看清楚,x,y的起始位置。(x/left代表横轴-左起,y/top代表竖轴-上起)
# 画框
plt.imshow(cv2.rectangle(img,(187,176),(241,205),(0,255,0),3), cmap = 'gray', interpolation = 'bicubic')
# 写文字
plt.text(187,176, 'words') # plt的方式
cv2.putText(img,'words',(187,176) ,0, 1,(255,255,255),2) #cv2的方式
# 添加文字,1.2表示字体大小,(0,40)是初始的位置,(255,255,255)表示颜色,2表示粗细
以上只能写英文,中文的话,会出现????
187,176代表左上角的点
3.写中文
opencv写中文字,可以参考:python+freetype+opencv 图片中文(汉字)显示 详细图文教程和项目完整源代码
当然,我在自己尝试的时候失败了,因为没找到ft2这个packages,难道py3没有这个吗?
#
import cv2
import freetype as ft2
import freetype
face = freetype.Face("Vera.ttf")
img = cv2.imread('pic/lena.jpg')
line = '你好,我是 lena'
color = (0, 255, 0) # Green
pos = (3, 3)
text_size = 24
# ft = put_chinese_text('wqy-zenhei.ttc')
ft = ft2.put_chinese_text('msyh.ttf')
image = ft.draw_text(img, pos, line, text_size, color)
之后用ImageDraw可以实现用中文,但是需要加载中文的字体结构。.ttc文件(参考)。
msyh.ttc是中文简体字
from matplotlib import pyplot as plt
import matplotlib
from PIL import Image, ImageDraw, ImageFont
# 显示中文 plt
fnt = "...\\msyh.ttc"
fnt = ImageFont.truetype(fnt, 20)
img = Image.open('..\\1.jpg')
draw = ImageDraw.Draw(img)
draw.rectangle((187,176,241,205), outline=(255, 255, 255, 30))
draw.text((187,176),'你好',(0,0,0), font=fnt)
img.save("..\\t1.jpg")

延伸八:计算图片中两个矩形框的重叠部分 IOU计算
def calculateIoU(candidateBound, groundTruthBound):
'''https://www.lao-wang.com/?p=114 '''
cx1 = candidateBound[0]
cy1 = candidateBound[1]
cx2 = candidateBound[2]
cy2 = candidateBound[3]
gx1 = groundTruthBound[0]
gy1 = groundTruthBound[1]
gx2 = groundTruthBound[2]
gy2 = groundTruthBound[3]
carea = (cx2 - cx1) * (cy2 - cy1) #C的面积
garea = (gx2 - gx1) * (gy2 - gy1) #G的面积
x1 = max(cx1, gx1)
y1 = max(cy1, gy1)
x2 = min(cx2, gx2)
y2 = min(cy2, gy2)
w = max(0, x2 - x1)
h = max(0, y2 - y1)
area = w * h #C∩G的面积
iou = area / (carea + garea - area)
return iou