朱有鹏老师C语言高级专题--链表、状态机与多线程学习笔记
目录
- 9.1、单链表的引入
- 9.2、单链表的实现
- 9.3 、单链表的算法(只能用头指针,不能用各个节点的指针)
- 9.4 、双链表引入
- 9.5、linux内核链表
- 9.6、什么是状态机
9.1、单链表的引入
9.1.1、数组的缺陷
(1)数组每个元素类型必须一致。
(2)数组元素个数一旦确定就不能更改(不够灵活)
(3)结构体可以解决第一个缺陷,链表可以解决元素个数不能改变的问题,可以理解链表就是可以随时扩展,元素个数可以随时变大或者变小
9.1.2动态扩展的思路
(1)整体搬迁(原来数组数据整体复制到新的数组头部,后释放原来数组内存空间)
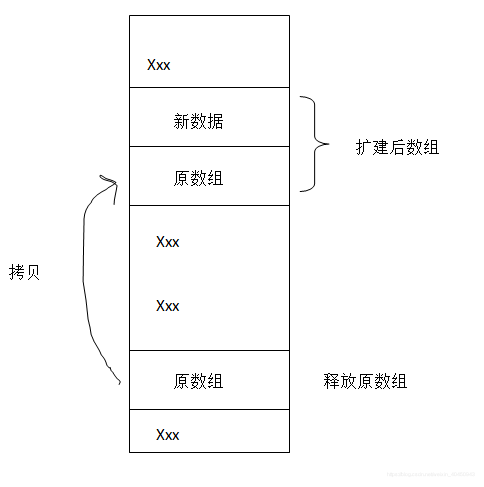
(2)外部扩展(建新校区的思路,最合理),各个校区可以看成一个个节点,节点连起来就形成链表(本质若干个节点)。
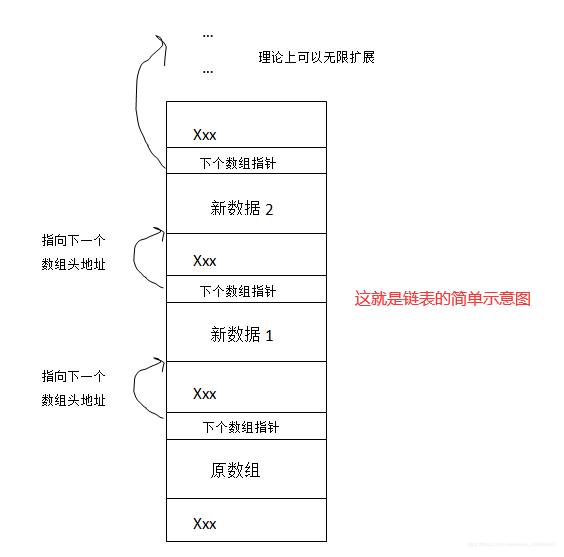
(3)C语言使用:用指针把两个节点链接起来,每个节点有个空间存放指针,指向下一个节点。
(4)每个节点都由:有效数据+指针!
9.1.4 链表是用来干什么?
(1)解决数据元素大小不能扩展的问题,可以当数组使用,链表可以完成的也可以用数组完成,数组可以完成的事前,链表也可以完成,不同的是灵活性不一样。数组的优势是使用简单,想用多小个直接定义。就要我们自己判断在什么时候使用数组和在什么时候时候链表了。
9.2、单链表的实现
(1)包括两部分:有效数据+指针(指向下一个数据单元)
(2)定义一个结构体node,
struct node //创建结构体类型
{
int data;
struct node *pNext ; //指向下一个节点
};
(3)堆的申请和使用
链表是可以动态扩展的,不适合用栈和数据段,所有必须用到堆内存。
申请完堆内存后需要进行清理才能使用,可以使用如下函数进行清理:
bzero();清理
memset();也是情理
链表头指针:不是节点,是一个普通指针。类型是struct node * ,所以它才能指向链表的节点。
下一个指针定义 struct node *pnest;
9.3 、单链表的算法(只能用头指针,不能用各个节点的指针)
9.3.4、封装链表节点
9.3.4、插入新的节点(头部插入、尾部插入)
(1)尾部插入(简单代码)
#include (2)从链表头部插入新节点
-> 箭头符号,是访问结构体成员(和指针指向没有任何关系)
创建insert_heat 函数
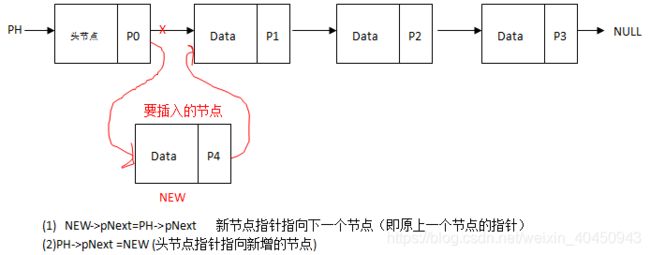
实例代码
void insert_head(struct node *pH, struct node *new) //从头部添加节点
{
new->pNext = pH->pNext; //新节点指向原来第一个节点
pH->pNext = new ; //头节点指向新增的new节点(即新第一个节点)
pH->data +=1; //计算节点数 利用空节点存储
}
9.3.5、单链表的遍历
(1)就是把我们单链表中的各个节点挨个拿出来,就叫遍历。
(2)遍历的要点:一是不能遗漏,二是不能重复、追求效率。
9.3.5.1、如何遍历单链表
(1)头指针+头节点为整个链表的起始,直到pNext = NULL为结尾。单链表只有一条路径。
(2)遍历方法:从头指针+头节点开始,顺着链表挂接的指针依次访问链表的各个节点,取出节点的数据,然后在往下一个节点,直到最后一个节点,结束返回。
9.3.5.2、编程实战(单链表遍历)
(1)void bianli(struct node *pH);
(2)通过while循环遍历节点,直到达到最后一个节点。即最后一个节点的指针为:NULL;
实例代码
void traverse(struct node *pH) //遍历一个节点
{
struct node *p = pH;
int i = 0;
while(NULL != p->pNext)
{
i++;
p = p->pNext;
printf("第%d的节点数据为 = %d\n",i,p->data);
}
}
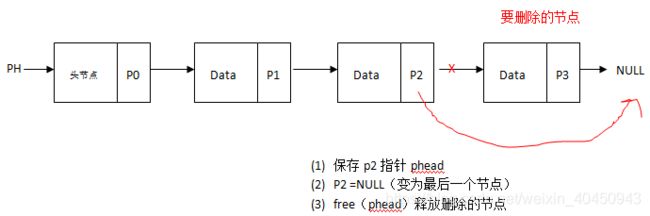
9.3.6、删除一个任意节点(给定这个节点的data,查找出包含这个值的节点并删除)
情况一:节点不在尾部
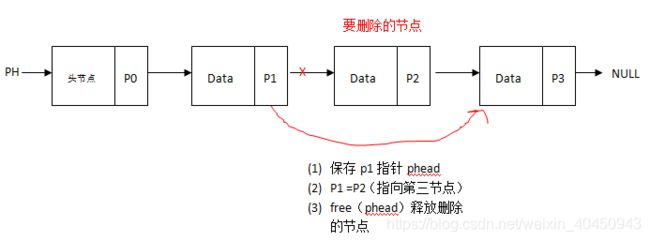
(1)步骤一:遍历节点,找到这个要删除的节点(判断是在是否在尾部或者在中部,在尾部跳转尾部处理步骤),另外保存前一个节点的指针(后面需要通过前一个节点的指针释放要删除节点的内存)
(2)步骤二:前一个节点指针指向删除节点之后的节点(即获取删除节点的指针即可)
(3)步骤三:释放删除的节点。使用我们第一步保存后的前一个节点的指针free掉即可
情况二:节点在尾部
(4)删除节点代码示例
int delete_node(struct node *pH,int data)
{
struct node *p = pH; //指向空节点
struct node *pback = NULL;
while(NULL != p->pNext)
{
pback = p ; //保存前一个节点,因为需要前一个节点操作后面一个节点。
p = p->pNext; //下一个节点
if(p->data == data)
{
if(NULL==p->pNext)
{
//是末尾节点
pback->pNext= NULL;
free(p);
}
else
{
//不是末尾节点
pback->pNext =p->pNext;
free(p);
}
return 0;
}
}
printf("没有找到节点\n");
return -1;
}
9.3.7、单链表算法之逆序
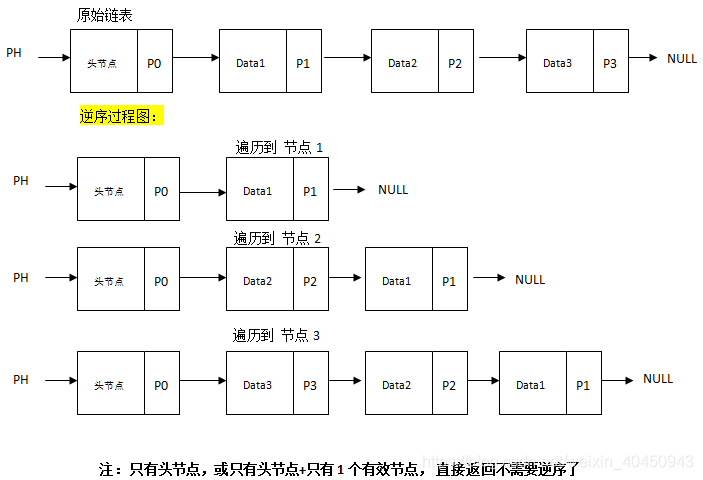
9.3.7.1、什么叫链表的逆序
(1)把链接中的有效节点在链表中的顺序给反过来(如:1,2,3,4,5 逆过来:5,4,3,2,1)
9.3.7.2、逆序算法分析1
(1)方法:遍历+头插入
(2)编程实战
void insert_tail(struct node *pH, struct node *new)
{
struct node *p = pH;
while (NULL != p->pNext)
{
p = p->pNext; // 往后走一个节点
}
p->pNext = new; //原来最后一个节点的指针(原尾部)指向新增的节点(新尾部)
}
void insert_head(struct node *pH, struct node *new) //从头部添加节点
{
new->pNext = pH->pNext; //新节点指向原来第一个节点
pH->pNext = new ; //头节点指向新增的new节点(即新第一个节点)
pH->data +=1; //计算节点数 利用空节点存储
}
void reversed_order(struct node *pH) //链表的逆序
{
struct node *p =pH->pNext ; //指向第一个有效节点。
struct node *back;
if((NULL == p)||(NULL==p->pNext)) //判断是否是只有一个有效节点,或只有空节点。
{
return ; //不需要逆序
}
while(NULL !=p->pNext) //遍历开始
{
back= p->pNext; //保存指向下一个节点的指针
if(p == pH->pNext)
{
p->pNext = NULL; //是第一个有效节点,逆序后变为最后一个节点
}
else
{
p->pNext = pH->pNext; //不是遍历的第一个节点,该节点指针指向下一个节点(即永远是头节点指针,因为头插入)
}
pH->pNext = p; //头节点从新指向新逆序节点
p = back; //往下遍历 走到最后一个节点,结束循环了,所有丢失最后一个节点
}
insert_head(pH, p); //补回最后一个节点
}
void traverse(struct node *pH) //链表遍历
{
struct node *p = pH;
int i = 0;
while(NULL != p->pNext)
{
i++;
p = p->pNext;
printf("第%d的节点数据为 = %d\n",i,p->data);
}
}
int main(void)
{
struct node *pHede = NULL;
pHede = creat_node(0); //空节点
insert_tail(pHede,creat_node(100)); //从尾部新增节点
insert_tail(pHede,creat_node(200));
insert_tail(pHede,creat_node(300));
insert_tail(pHede,creat_node(400));
insert_tail(pHede,creat_node(500));
insert_tail(pHede,creat_node(600));
printf("******************逆序前*******************\n");
traverse(pHede); //遍历
reversed_order(pHede); //逆序
printf("******************逆序后*******************\n");
traverse(pHede); //遍历
return 0;
}
结果:
逆序前*
第1的节点数据为 = 100
第2的节点数据为 = 200
第3的节点数据为 = 300
第4的节点数据为 = 400
第5的节点数据为 = 500
第6的节点数据为 = 600
后序前*
第1的节点数据为 = 600
第2的节点数据为 = 500
第3的节点数据为 = 400
第4的节点数据为 = 300
第5的节点数据为 = 200
第6的节点数据为 = 100
9.4 、双链表引入
9.4.1、单链表的局限性
(1)单链表的好处:比数组扩展性好,使用堆内存存储,数据分散到各个节点中,节点通过指针依次相连。其中节点中的内存可以不相连,因此可以有效的利用碎片化内存。
(2)单链表的局限性:单链表只由一个指针单向链接,链表单只能经过指针单向移动(从头指针开始遍历链表),不能再返回来,如果要再操作这个节点,必须从头再来遍历一遍。因此单链表在某些操作就比较麻烦(算法比较有局限)只能向前移动。
9.4.2 双链表的解决思路:
(1)单向链表的节点:有效数据+1个指针(只能往前移动)
(2)双向链表的节点:有效数据+2个指针(一个指针往前走,一个指针往回走,就是双向移动)

9.4.3:双链表的实现过程(创建节点):
struct node
{
int data;
struct node *pNext; //后向指针
struct node *pPrev; //前向指针
};
//创建一个节点
struct node *CreatNode(int data)
{
struct node *p=(struct node *)malloc(sizeof(struct node));
p->data = data;
p->pNext = NULL;
p->pPrev = NULL;
return p ;
}
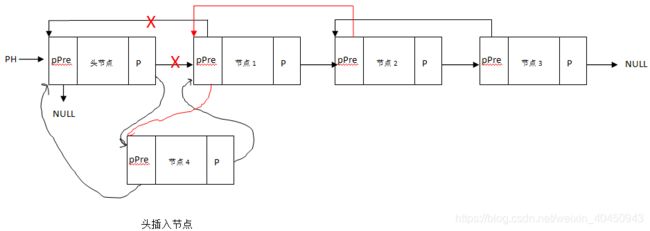
9.4.3.1 双链表的插入(头插和尾插)
(1)尾部尾插实现原理

(2)头插入实现原理
9.4.3.2双链表的算法之遍历节点
(1)跟单链表遍历一样,可以看做双链表是单链表的父类。后向遍历跟单链表遍历是一样的。
(2)所谓双链表,也就是在节点中增加了一个指针pPrev(前向指针),使得可以双向移动,也就是说对单链表带有成本的扩展。
(3)总结:单链表只能单向的向后移动或变量,也就是如果遍历到了中间想向前遍历是不可能的必须从头开始。双链表可以在任何节点上都可以向前或向后变量。也就是两个指针,一个指向后一个节点,一个指向前一个节点。
(4)示例代码
#include 运行结果:

9.4.3.3、双链表删除
(1)删除最后一个节点
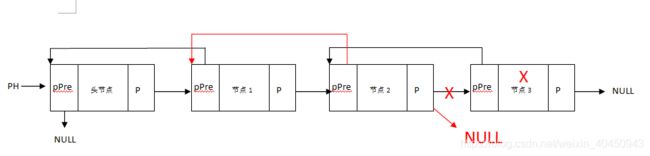
(2)删除普通节点
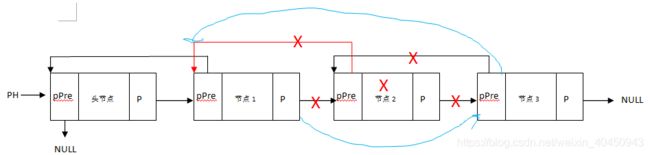
int delet_2node(struct node *pH,int data)
{
struct node *p = pH;
if(NULL == p )
{
printf("no node firt!\n");
return -1; //没有头节点返回
}
while(NULL != p->pNext)
{
p = p->pNext;
if(p->data == data)
{
//找到节点
if(NULL == p->pNext)
{
//最后一个节点
p->pPrev->pNext = NULL; //前一个节点接上后一个节点
}
else
{
//普通节点
p->pPrev->pNext = p->pNext; //前一个节点接上后一个节点
p->pNext->pPrev = p->pPrev ; //后一个节点指向前一个节点
}
free(p); //释放内存
return 0;
}
}
return -1 ; //没有找到节点
}
int main()
{
struct node *pHead = CreatNode(0);
insert_node(pHead,CreatNode(1));
insert_node(pHead,CreatNode(2));
insert_node(pHead,CreatNode(3));
insert_node(pHead,CreatNode(4));
insert_node(pHead,CreatNode(5));
printf("***************删除前遍历********************\n");
traverse(pHead);
delet_2node(pHead,5);
printf("***************删除后遍历********************\n");
traverse(pHead);
return 0;
}
9.5、linux内核链表
(位置: \kernel\include\linux\listh.h)
数据区封装为一个结构体,链表结构是多种多样的。
结构体内嵌结构体(相当于继承其他方法)
部分纯链表函数定义
#ifndef CONFIG_DEBUG_LIST
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}
#else
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}
/**
* list_is_last - tests whether @list is the last entry in list @head
* @list: the entry to test
* @head: the head of the list
*/
static inline int list_is_last(const struct list_head *list,
const struct list_head *head)
{
return list->next == head;
}
/**
* list_empty - tests whether a list is empty
* @head: the list to test.
*/
/**
* list_empty_careful - tests whether a list is empty and not being modified
* @head: the list to test
*
* Description:
* tests whether a list is empty _and_ checks that no other CPU might be
* in the process of modifying either member (next or prev)
*
* NOTE: using list_empty_careful() without synchronization
* can only be safe if the only activity that can happen
* to the list entry is list_del_init(). Eg. it cannot be used
* if another CPU could re-list_add() it.
*/
static inline int list_empty_careful(const struct list_head *head)
{
struct list_head *next = head->next;
return (next == head) && (next == head->prev);
}
__list_cut_position
分割链表
这里提供的函数接口是:
static inline void __list_cut_position(struct list_head *list,
struct list_head *head, struct list_head *entry)
list:将剪切的结点要加进来的链表
head:被剪切的链表
entry:所指位于由head所指领头的链表内,它可以指向head,但是这样的话,head就不能被剪切了,在代码中调用了INIT_LIST_HEAD(list)
static inline void INIT_LIST_HEAD(struct list_head *list)
{
list->next = list;
list->prev = list;
}
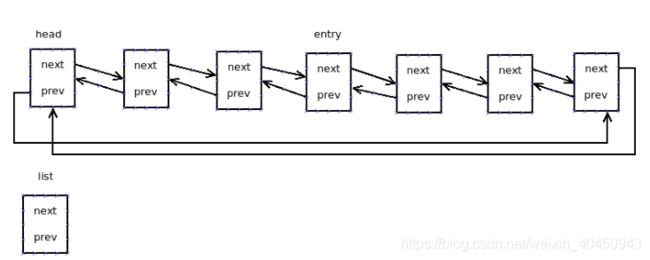
循环链表设计思路: 头节点的prev指向最后一个链表,最后一个链表next指向头节点。
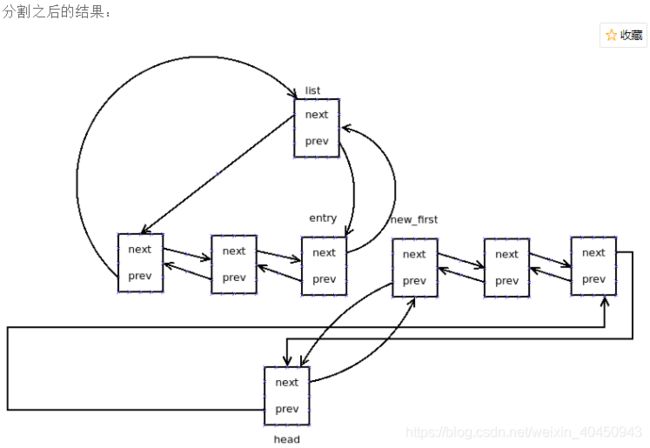
是将head(不包括head)到entry之间的所有结点剪切下来加到list所指向的链表中。这个操作之后就有了两个链表head和list。
static inline void __list_cut_position(struct list_head *list,
struct list_head *head, struct list_head *entry)
{
struct list_head *new_first = entry->next;
list->next = head->next;
list->next->prev = list;
list->prev = entry; //新的头节点的prev指向最后一个节点 形成一个链表环
entry->next = list; //分割出来的最后一个节点next指向新的头节点
head->next = new_first;
new_first->prev = head;
}
/**
* list_cut_position - cut a list into two
* @list: a new list to add all removed entries
* @head: a list with entries
* @entry: an entry within head, could be the head itself
* and if so we won't cut the list
*
* This helper moves the initial part of @head, up to and
* including @entry, from @head to @list. You should
* pass on @entry an element you know is on @head. @list
* should be an empty list or a list you do not care about
* losing its data.
*
*/
static inline void list_cut_position(struct list_head *list,
struct list_head *head, struct list_head *entry)
{
if (list_empty(head))
return;
if (list_is_singular(head) &&
(head->next != entry && head != entry))
return;
if (entry == head)
INIT_LIST_HEAD(list);
else
__list_cut_position(list, head, entry);
}
/**
内核中链表的删除实现思路,我们只要传递要删除节点的prev 和next指针下去就可以,内核链表函数会把给链表节点删除并从新链接。
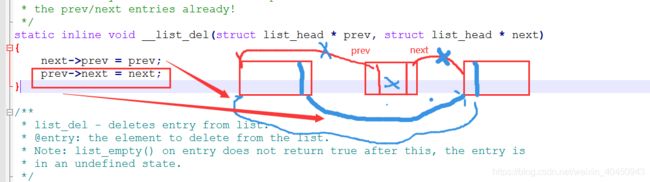
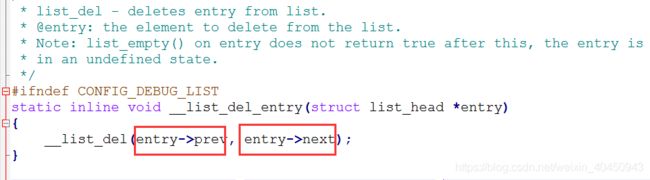
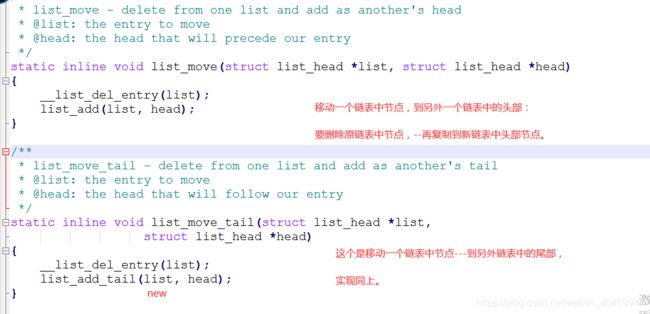
内核中的实现方法目录:
9.6、什么是状态机
(1)(常说的)有限状态机:有限状态FSM。FSM指的是有限个状态(状态变量的值),在当前状态下只接受当前状态下支持的命令,并且根据当前的命令跳转到相应的状态继续执行,其他命令在当前状态下是无效的,可以由运算结果或者外部输入觉得跳转到下一个状态。接受另一状态的命令。
(2)有两种状态机:Moore 和Mealy型
Moore特点:输出只与当前状态有关(与输入信号无关)
Mealy特点:输出与输入和当前状态有关。