python_sklearn机器学习算法系列之LogisticRegression(逻辑回归)----识别垃圾邮件(短信)
本文主要目的是通过一段及其简单的小程序来快速学习python 中sklearn的LogisticRegression这一函数的基本操作和使用,注意不是用python纯粹从头到尾自己构建LogisticRegression,既然sklearn提供了现成的我们直接拿来用就可以了,当然其原理十分重要,下面最简单介绍:
虽然名称中有回归但其功能多实现的是分类,逻辑回归本质上是线性回归,只是在特征到结果的映射中加入了一层逻辑函数g(z),即先把特征线性求和,然后使用函数g(z)作为假设函数来预测。g(z)可以将连续值映射到0 和1。
详细的原理请大家百度,本文的主要目的是看怎么用该算法
在正式给出代码之前我们先了解一下中文短信的特点,它不像外文那样每个单词都以空格分开,我们中文的词都是连在一起的,而我们要实现识别短信这一功能最主要的就是要看词在正常和垃圾短信里面分别出现的次数这一参数,所以我们必须要做的就是对短信进行分词,关于分词技术有很多,我们这里使用jieba分词技术,大家可以使用命令pip install jieba进行安装,关于它的使用非常简单,这里给一个简单的小例子:
import jieba.posseg as pseg
words=pseg.cut("你就是我的全部")
for key in words:
print (key.word,key.flag)输出为:

接下来介绍TF-IDF权重:
TFIDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TFIDF实际上是:TF * IDF,TF词频(Term Frequency),IDF逆向文件频率(Inverse Document Frequency)。TF表示词条在文档d中出现的频率,逆向文件频率(inverse document frequency,IDF)是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。
所以我们在得到分词后就要计算每个词的TF-IDF权重依此为参数作为算法的特征值,是否为垃圾短信为分类类型值
总结下步骤就是:分词------------计算TF-IDF权重------------选用算法就行分类(本文用LogisticRegression逻辑回归)
程序分为两个模块: 模块一是测试训练后的模型的试准确率,召回率等信息
模块二是预测待判断的短信
大家可以分开运行查看结果
其中train_data.txt是用来训练的数据集如下:每一行代表一条短信,开头为0代表正常信息,1为垃圾信息
0/商业秘密的秘密性那是维系其商业价值和垄断地位的前提条件之一
1/您好,渤海银行双节理财xxx天收益x%五万起,三月十号起息,只能柜台购买,数量有限欲购从速!渤海银行祁新星
0/又来一个水乡~苏州博物馆随便一拍都好有情调
0/手机已经占领了我们整个生活
1/哦。除此之外,还有超值礼品赠送,十克金条等你来拿哦!兴力达诺贝尔磁砖 王燕期待您的光临!活动时间:xxxx.x.x-x.x !活动地址
1/陕西甲级设计单位急需一名签一年的一注结构,有考虑的请联系得士兰顾问刘鑫冉,电话:xxxxxxxxxxx,QQ:xxxxxxxxxx
1/信和有拍卖房出来,你有考虑吗?单介x.x~x万平米,要求一次性付款,税费各付。房子为限购,x月xx号起拍
0/今天去派出所办老人投靠子女落户之事
0/目前四城市已确定20家定点医疗机构
0/同时净化毛孔吸附溶解毛孔里的黑头
0/升级winxx先是搜不到自己家的路由器
0/两年期满后减为15年以上20年以下有期徒刑
0/想买一台1K以内的手机作备用机
0/与其他汽车生产厂商相同的是
0/其实每个人对旅游的观念不一样
1/祝您及家人元宵节快乐!实惠满意在国美,x.xx黑色星期五国美给您超低价!德国西门子家电,专注品质、专注卓越!家电中的领航者.
1/音,数学,英语强化班开始报名了。即日起至x月x日,凡在本中心报绘画课程,老学员享受x.x折优惠,前xx名新会员享受x折优惠。欢迎各位新
1/亲,伊芙嘉女装春款全新上市了,所有冬装清仓甩卖全场x.x折偏宜到家了,机不可失快来抢购吧! 伊芙嘉女装店
0/我直接从日本亚马逊网上买了寄回国内的
0/烟囱扰民70业主雇人强拆有关部门曾两次责令整改无果
0/但到达青岛时飞机落地分秒不差
0/现在逼着作维持决定的复议机关成为共同被告
0/总有渣的update帐号发些无图无真相的消息说莉渣在一起干嘛干嘛
1/欢迎致电聚雅酒店,酒店为你提供午晚饭市,早夜茶市,各式豪华,标准客房。我们将以最优质的服务让您宾至如归!餐饮部电话:xxxx-xxxx
0/市市场监管局于7月22日起在全市范围内开展2015红盾网剑专项行动
0/公交、地铁、办公室?甚至马桶上都埋头玩手机玩到与世隔绝的你
0/健康与财富同步启航这是我的微店
1/深圳市鱼美人减肥研究院罗湖分院欢迎您!专业为您提供减肥美容美体等.电话忙如有业务需求请拨xxxxxxxxxxx竭诚服务!
1/东会计名额紧张收尾中,高效权威,几小时轻松掌握,xxx%包过线,Q;xxxxxxxx,欢迎咨询了解
0/乌拉盖管理区司法局不断创新工作方式
0/呈U型的厨房采用镂空的木质墙壁作为隔断
1/您好!现jeep 休闲内衣专柜全场五折!时间三月五号至八号、欢迎光临选购
1/新年愉快!工银信用卡中心办理信用卡,额度xx-xxx万。下卡快,前期无费用,下卡后付费x%。李主任,xxxxxxxxxxx
0/他们就是看公司不作为才更加放肆
1/优惠券+空调清洗、三元催化系统清洗、喷油嘴清洗折扣券;x无限次免费抢修服务;x精美礼品一份。联系电话:xxx-xxxx-xxxx/xx
1/业管理师培训,ABC证,七大员证,特种工证,学历高起专,专升本,研究生,企业资质升级咨询服务等 业务电话:xxxxxxxxxxx徐老师
1/亲爱的会员朋友们或咨询朋友们,力魄尔舞蹈工作室世纪城店已开始正常营业上课了哦,现准备开设新项目课程----晨瑜伽。有意愿的朋友欢迎咨询
0/甚至新款诺基亚1100也出现在了Geekbench跑分网站
0/亳州机动车违法行为交警正在严查
1/蒙娜丽莎瓷砖全体员工祝您及家人元宵节快乐!x月xx日之前预订可享受全场买一赠一及多款出厂价,可免费上门测量、设计,兴华北大街路东蒙娜丽
1/万方首席生态大盘,千亩湿地公园近在咫尺,毗邻康桥国际学校,周边生活配套完善,约xx-xx㎡N+x户型即将上市!智能生活从这里开始!期待
0/家价格即x.x折扣,并且还有许多精美礼品相送!请大家千万别错过这省钱又能得大礼的好机会哦!石柱爱戴内衣(金鼎店)
0/河南淅川公安针对农资市场特点
1/正月十五闹元宵! 士林夜市祝福到! x月x号下午x:xx在台湾士林不夜城举行元宵节客户推介会,凡到场客户均有礼品相送: 一重礼:精美汤
1/友邦吊顶A股成功上市一周年x.xx粉丝众筹节开幕啦!x元抢购,xx元抢厨卫板材,xxx元抢暖风!全国限量,开抢吧!世贸广场一楼xxx
0/家用锁APP上还有“摇摇开锁”功能
0/本人已经报警了未婚无子的赌博是违法的我不可能参与的制造玛氏病毒杀我本人马上就要死了死刑必须死刑
0/我院将于9月3日推出抗战题材特色原创展览“皖江洪流——安徽军民抗战史实展”
1/您好,元宵快乐。我是安贞美容科全医生,安贞美容迎x.x优惠活动正进行:双眼皮、眼袋、提眉各xxxx元,其他手术x.x折酬宾。预定从速。
1/魅力女人节,实惠在迎宾!玉兰油专柜买满xxx元立减xx元,欢迎光临选购![玫瑰][玫瑰][玫瑰]
0/乔丹的身体力量在NBA是什么水平
demand prediction.txt为要预测的短信:(每一行代表一条短信)
我要当Google的脑残粉了
换了高透膜觉得整个手机都不一样了
妹,嘉宝奶粉x月xx曰在爱婴室上架销售了,促销力度很大购买x箱x听立减xOO元,在其他宝宝店上市后口碑很好深受家长欢迎,你瑞铂奶粉留x
患有心里疾病的人是不负法律责任的
暑假去旅游怎么能少了旅游装呢
我公司的x万-xx万的无抵押无担保信用贷款,欢迎您来电详询!VIP专线xxxxxxxxxxx
前二十名报名还可得xxxx元理财基金!现场还有免费抽奖活动,丰厚大奖等着你哦!中凯装饰咨询顾问:小李欢迎您的到来!
不要贪玩携带仿真枪进站乘车
美国股市自2008年至今一路飚升
尊敬的电信用户您好,中国电信x月提速xxM仅需xxx元/年!高清电视直播仅需xxx元/年!详情请拨打[吴松烨xxxxxxxxxxx]
教授给大家罗列了无锡的一些老话
在飞机上三四个小时熬夜画的orzzz有APH有LL有海囚有东方
简单的认为她是straightgirl
新年快乐,北城中环城抢房拉 隆重开启不是降价是清盘,首次年关前大优惠,合肥独一无二的优惠项目、限量、限价,机会不容错
属您楼盘的方案深度解析,xxx万红包疯抢,主材返现,百家知名材料商现场助阵给予最大优惠!地址:合作化路与望江路交汇处!来时电话,李秀齐
碰见一位1米74象全智贤的新疆医生
交通路唐朱迪服装店,三八妇女节活动开始了,x月x号~x月x号(x_x件折上再x折,x件起再x折)欢迎新老顾客光临惠顾。
源程序如下:
#总体思路就是:分词-----计算TF-IDF权重-----选用模型预测
import warnings
import numpy as np
import matplotlib.pyplot as plt
from sklearn.externals import joblib
import pandas as pd
import matplotlib as mpl
from sklearn import metrics
import jieba.posseg as pseg
from sklearn.cross_validation import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model.logistic import LogisticRegression
#忽略一些版本不兼容等警告
warnings.filterwarnings("ignore")
#从磁盘读取y原始数据进行训练
X = []
Y1 = []
Y2 = []
f = open('train_data.txt')
for v in f:
X.append([v.strip('\n').split('/')[0],v.strip('\n').split('/')[1]]) #strip('\n')是去除换行符\n
f.close()
#进行分词,分词后保存在Y中
for i in range(len(X)):
words=pseg.cut(X[i][1])
str1=""
for key in words:
str1+=key.word
str1+=' '
Y1.append(str1) #短信内容
Y2.append(X[i][0]) #是否是垃圾的标志
#将样本分为训练集和测试集
x_train_Chinese, x_test_Chinese, y_train, y_test = train_test_split(Y1,Y2,train_size=0.99)
#通过TfidfVectorizer算出TF-IDF权重
vectorizer=TfidfVectorizer()
x_train=vectorizer.fit_transform(x_train_Chinese)
'''
#模块一:测试准确率,召回率等信息表
#核心代码
classifier=LogisticRegression()
classifier.fit(x_train,y_train)
y_tanin_predict=classifier.predict(x_train)
print(metrics.classification_report(y_train,y_tanin_predict)) #包含准确率,召回率等信息表
print(metrics.confusion_matrix(y_train,y_tanin_predict)) #混淆矩阵
'''
#模块二:预测信息
#读取待预测的短息读取到X1中
X1 = []
X2 = []
f = open('demand prediction.txt')
for v in f:
X1.append(v.strip('\n'))
f.close()
#进行分词,分词后保存在X2中
for i in range(len(X1)):
words=pseg.cut(X1[i])
str1=""
for key in words:
str1+=key.word
str1+=' '
X2.append(str1) #短信内容
#计算待预测短息的TF-IDF权重
x_demand_prediction=vectorizer.transform(X2)
#预测
classifier=LogisticRegression()
classifier.fit(x_train,y_train)
y_predict=classifier.predict(x_demand_prediction)
#输出
print('----------------------------------------短信预测结果------------------------------------------')
for i in range(len(X1)):
if int(y_predict[i])==0:
print('正常短信:'+X1[i]+'\n')
else:
print('垃圾短信:'+X2[i]+'\n')
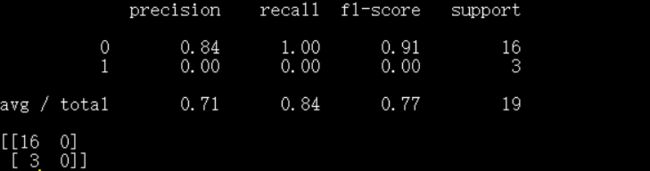
模块一的结果:
模块二结果:

从结果来看并不是很理想起码第六条短信(我公司的X万...........)就没有预测成功,因为我的学习集太少了,如果给与足够多的样本让其学习,结果会更好,本文重在说明原理,所以就选取了很少的样本,大家可以自己去下载一些数据测试
关于预测英文的类同,一定程度上更简单,因为不用分词,关于英文的数据网上有很多,这里就可出一个吧
https://github.com/Mryangkaitong/python-Machine-learning/tree/master/LogisticRegression
其中结尾的ham代表正常邮件,Spam代表垃圾邮件,如果大家感兴趣可以自己试一试吧!!!
更多算法可以参看博主其他文章,或者github:https://github.com/Mryangkaitong/python-Machine-learning