机器阅读理解 | (1) 智能问答概述
本篇博客主要基于微软亚洲研究院段楠老师的《智能问答》第一章 概述 进行整理。
智能问答(Question Answer,QA)旨在为用户提出的自然语言问题自动提供答案,得益于大数据、硬件计算能力提高(GPU、TPU)以及自然语言处理和深度学习技术的进步,近来年取得了飞速发展,其应用场景(如搜索引擎、智能语音助手)更加贴近人们的日常生活。
目录
一. 历史沿革
1. 受限领域问答
2. 开放领域问答
二、自然语言问题分类
三、QA任务分类
1. 知识图谱问答
2. 表格问答
3. 文本问答
4. 社区问答
四、QA任务相关的评测数据集
1. 知识图谱问答
2. 表格问答
3. 文本问答
4. 社区问答
五、参考文献
一. 历史沿革
1. 受限领域问答
20世纪60年代,QA研究主要针对数据库自然语言接口任务,即如何使用自然语言检索结构化数据库。如LUNAR系统,允许月球地质学家使用自然语言检索NASA数据库,来获取月球岩石和土壤相关的信息和数据。本时期的工作需要依赖人工撰写的规则模版,完成自然语言问题到结构化数据库查询语句的转换。
20世纪70年代,QA研究聚焦于对话系统,并在末期拓展到阅读理解任务。
20世纪80年代,受限领域知识库的构建工作继续向前发展,进一步推动了基于知识库的专家系统研究。如UNIX Consultant系统,允许用户使用自然语言完成unix操作系统中的特定任务,该系统基于人工撰写的规则完成自然语言理解和回复生成任务。
早期智能问答系统大都针对特定领域(垂直领域)构建,并且需要领域专家撰写大量该领域相关的规则,用于问题理解和答案生成,这极大地限制了该类智能问答系统的规模和通用性,此外,受限于自然语言处理水平和计算机的运算能力,这类系统的准确度也差强人意。
2. 开放领域问答
1993年第一个基于互联网的智能问答系统START由MIT开发上线。该系统使用结构化知识库和非结构化文档作为问答知识库。对于能够被结构化知识库回答的问题,系统直接返回问题对应的精准答案。否则START首先对输入问题进行句法分析,并根据分析结果抽取关键词,然后基于抽取出来的关键词从非结构化文档集合中找到与之相关的文档集合,最后采用答案抽取技术,从相关文档中抽取可能的答案候选进行打分,并选择得分最高的句子作为答案输出。
1999年,TREC举办第一届开放领域智能问答评测任务TREC-8,目标是从大规模文档集合中找到输入问题对应的相关文档,该任务从信息检索角度开创了智能问答研究的一个崭新方向,TREC问答评测是世界范围上最受关注和最具影响力的问答评测任务之一。
2000年,CLEF提出跨语言问答评测任务,在该任务中问题和检索文档集合分别使用不同的语言,这就需要在问答中考虑并用机器翻译技术。此外,还引入了包括推理类和动机类在内的复杂问题,用于检验问答系统处理这类问题的水平。
Evi是2005年上线的问答型搜索引擎。和传统搜索引擎不同,Evi基于开放领域知识库,对用户提出了自然语言问题进行问题理解,并根据问题理解的结果,从知识库中查找出问题对应的精准答案,核心技术是基于知识图谱的智能问答技术。
Wolfram Aplha是2009年上线的计算知识引擎。支持计算机代数、符号和数值运算、可视化和统计等功能。它还提供基于结构化知识库的问答功能。
2011年,由IBM构建的智能问答系统Watson参加了美国电视问答比赛节目Jeopardy!,并在比赛中击败了人类冠军选手。Jeopardy!问答比赛涵盖了包括历史、语言、文学、艺术、科技、流行文化、体育、地理和文字游戏等多方面问题(开放/水平领域)。每个问题对应的线索在逐条展示给选手的过程中,选手需要根据已有的提示尽快猜出问题对应答案。IBM Watson系统框架图如下,主要由四个模块组成:
1)问题分析。该模块负责对输入问题进行包含命名实体识别(人名、地名、机构名等)、关系分类、句法解析、指代消歧在内的多种自然语言处理操作,并根据处理结果抽取问题焦点、词汇化答案类型和问题类型(事实类问题/非事实类问题).
2)候选生成。该模块负责从不同类型的数据源(包括结构化数据库和非结构化文档)中抽取答案候选。维基百科是Watson使用的主要数据源,这是由于Jeopardy!95%的问题对应的答案,都能在维基百科的标题中找到,除了维基百科外,知识图谱、词典、新闻文档和其他类型百科文档也被用于答案候选抽取。需要注意的是,问题分析模块预测得到的答案类型并不会作为答案候选抽取的硬性过滤条件,而是在答案候选排序中作为特征使用。
3)候选打分。该模块使用多种特征,从不同角度对每个答案候选进行置信度打分(每个答案有多个置信度打分)。
4)答案合并和排序。该模块基于每个答案候选对应的多个置信度打分,使用逻辑斯蒂回归计算每个答案候选对应的最终得分。答案候选集合可能包含同一个答案的不同表达形式(比如JF、John Frank表示同一个人),系统将会对不同表达形式的得分再进行合并。
从2015年起,TREC引入LiveQA评测任务。该任务在测试过程中,每隔一分钟向所有参赛系统发送一个雅虎Answer上尚未被回答的问题,并要求参赛系统在一分钟内返回问题对应的答案,答案质量由人工进行标注和评分。任务场景十分贴近真实的需求。
斯坦福在2016年发布了SQuAD数据集,该数据集针对智能问答中的机器阅读理解任务进行构建,要求问答系统从给定自然语言文本中找到输入问题对应的精准答案。该数据集提供了10万量级的高质量标注数据.截止到2018年1月初,由微软亚洲研究院和阿里巴巴提出的方法几乎同时在精准匹配(exact match,EM)这一指标上超过了Amazon Mechanical Turk标注者的平均水平。在中文方面,百度发布的中文机器阅读理解数据集DuReader,并在2018年3月联合CCF共同举办了2018机器阅读理解技术竞赛。哈工大讯飞联合实验室从2017年起举办讯飞杯中文机器阅读理解评测。
在现代搜索引擎中,智能问答技术所起的作用越来越重要。不同于以文档作为检索和结果展示基本单位的传统搜索引擎,必应搜索引擎中的智能问答模块能够基于知识图谱问答、表格问答和文本问答等问答知识库,直接生成问题对应的精准答案。

智能问答技术在智能对话系统中起着同样重要的作用,这是由于人机对话中相当比例的场景都是问答场景。苹果、谷歌和微软等公司发布的智能对话产品中都集成了智能问答模块,作为其重要组成部分。
二、自然语言问题分类
在智能问答任务中,不同类型的问题通常基于不同类型的问答知识库生成答案,根据对搜索引擎查询日志中用户查询记录的分析和统计,可以将自然语言问题大致分为七类,事实类(factoid)问题、是非类(yes/no)问题、定义类(definition)问题、列表类(list)问题,比较类(comparison)问题、意见类(opinion)问题和指导类(how-to)问题.
(1)事实类问题对应的答案是现实世界中的一个或多个实体。 例如,问题Where was Barack Obama born?对应的答案是地点类型实体 Honolulu。事实类问题通常比较客观,适合基于知识图谱或文本生成问题对应的答案。
(2)是非类问题对应的答案只能是yes或者no。例如,问题Is sky blue?对应的答案是Yes;问题Is sky green?对应的答案是No。 是非类问题在搜索引擎查询日志中的占比较高,适合基于知识图谱或常识知识库进行推理并生成问题对应的答案。
(3)定义类问题对应的答案是关于问题中提到的某个实体的术语解释。 例如,问题 What does AI mean?对应的答案是AI这个术语的解释。 定义类问题的提问模式通常较为固定,适合基于知识图谱、词典或文本生成问题对应的答案。
(4)列表类问题对应的答案通常是一个集合。例如,问题 List of highest mountains on earth 对应的答案是一组山峰的名字。 和事实类问题类似,列表类问题可以基于知识图谱生成列表类问题对应的答案。 此外,由于网络表格经常包含对某类信息的总结和整理,因此也很适合用来生成列表类问题的答案。
(5)比较类、意见类和指导类问题对应的答案通常较为主观。 这三类问题适合基于来自问答社区网站的《问题,答案》对进行解答。
下表对上述介绍的七种问题分类分别给出一个问题示例,以及该问题对应的答案。

三、QA任务分类
根据上述不同类型问题的特点以及适合使用的问答知识库,可以将智能问答任务分为知识图谱问答(knowledge-based QA)、表格问答(table-based QA)、文本问答(text-based QA)和社区问答(community QA)四大类。
1. 知识图谱问答
知识图谱,又称knowledge graph或KB,指通过人工编辑方式构建的图结构知识库。知识图谱中的基本单元称为事实(fact),每个事实记录了现实世界中的一条知识,由若干实体(节点)和谓词/关系(边)构成。 具体来说,事实在知识图谱中的表示方式分为两类
- 三元组事实(triple fact)

![]() 和
和![]() 是知识图谱中的两个节点,分别表示该事实对应的主语实体(subject entity)和宾语实体(object entity),pred表示
是知识图谱中的两个节点,分别表示该事实对应的主语实体(subject entity)和宾语实体(object entity),pred表示![]() 和
和![]() 之间满足的谓词关系。
之间满足的谓词关系。
-
CVT事实(CVT fact)
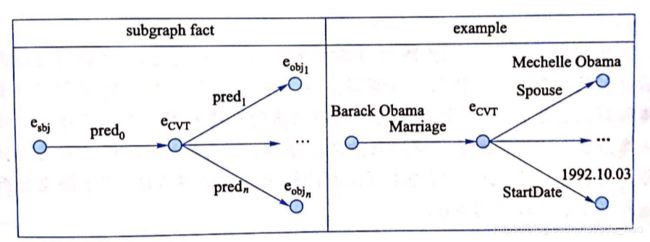
上图中,![]() 表示该事实对应的主语实体,
表示该事实对应的主语实体,![]() 表示该事实对应的n个宾语实体,
表示该事实对应的n个宾语实体,![]() 称为复合值类型节点(compound value type,CVT),该节点通过连接
称为复合值类型节点(compound value type,CVT),该节点通过连接![]() 和
和![]() 表示一个复杂事实。例如,上图中给出的例子是知识图谱中关于 Barack Obama 婚姻的一个事实,该事实不仅包含 Barack Obama配偶的名字-Mechelle Obama,还包含二者婚姻的起始时间-1992.10.03。如果将这些信息分成不同的三元组单独存储,就破坏了该信息的完整性。
表示一个复杂事实。例如,上图中给出的例子是知识图谱中关于 Barack Obama 婚姻的一个事实,该事实不仅包含 Barack Obama配偶的名字-Mechelle Obama,还包含二者婚姻的起始时间-1992.10.03。如果将这些信息分成不同的三元组单独存储,就破坏了该信息的完整性。
知识图谱问答(knowledge-based QA),基于给定知识图谱生成问题对应的答案。下图给出知识图谱问答的一个示例。给定问题where was Barack Obama born?,首先采用实体链接(entity linking)技术识别出问题实体 Barack Obama。然后采用关系分类(relation classification)技术识别出问题所表达的谓词关系PlaceOfBirth。接下来,根据实体链接和关系分类的结果生成问题对应的语义表示,PlaceOfBirth(Barack Obama,x),该过程可以看做是一个简单的语义分析(semantic parsing)过程。 最后,根据语义分析结果从知识图谱中推理得到问题对应的答案实体 Honolulu。
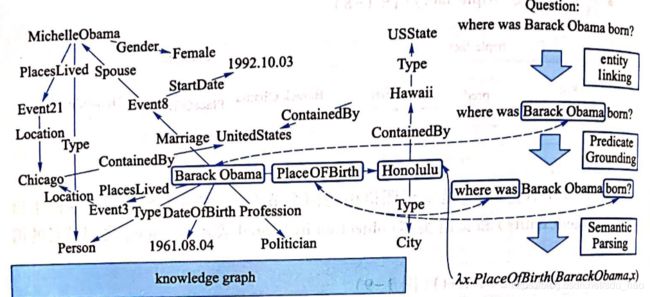
注意,上述示例只是知识图谱问答中最简单的一种情况,即问题对应的语义表示仅包括一个问题实体和一个谓词关系。 在真实情况中,问题通常包含多个实体和谓词关系,这就需要更复杂的知识图谱问答技术了。知识图谱问答涉及的两个基本任务:实体链接任务和关系分类任务。两种不同类型的知识图谱问答方法:基于语义分析的方法和基于答案排序的方法。
2. 表格问答
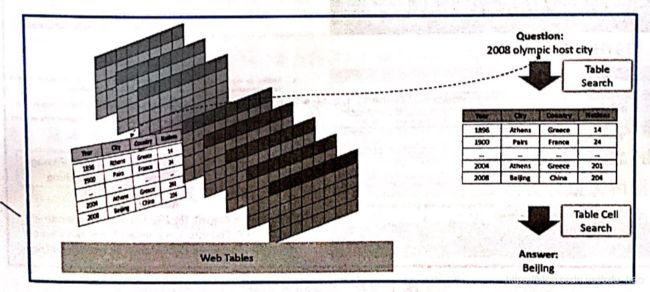
表格由M行N列数据组成。每一行由N个表格单元构成,表示一条信息记录。每一列由M个表格单元构成,同一列中的所有表格单元具有相同的类型。下图给出一个表格示例,每一行数据表示某个国家在奥运会上的奖牌统计情况。

表格与知识图谱相比,二者既有共性又有区别。共性在于这两类数据都有清晰的结构:位于同一列的表格单元具有相同的类型,这可以类比于知识图谱中具有相同类型的实体集合;每一行表示一条信息记录,这可以类比于知识图谱中的三元组或由多个节点组成的子图。 区别在于知识图谱具有更为复杂的本体结构,并且对实体和谓词进行了归一化,这使得知识图谱中不同事实之间的连接度很高,但该类知识库数据的维护和更新需要大量人工成本,因此知识图谱的实效性通常较低;与之相比,单个表格所包含的内容非常有限,不同表格之间不必遵循统一的本体结构和命名规范,因此对表格的编辑和修改操作可以高效地进行。这些特点使得表格类数据通常具有较高的时效性,例如金融报表、产品属性和体育比赛结果等。
表格问答(table-based QA),基于给定表格集合生成问题对应的答案。该任务又细分为表格检索和答案生成两步,前者负责从表格集合中找到与输入问题最相关的表格,后者负责基于检索回来的相关表格生成问题对应的答案。
下图给出一个简单的表格问答示例。给定问题2008 olympic host city,表格检索首先从表格集合中找到和该问题最相关的一个表格,其内容列举了历届奥林匹克运动会的举办年份、举办城市、举办国和参加国家数目。这一步骤既可以采用传统的信息检索技术,即将表格内容打散看成是一种特殊的文档,也可以设计专门的表格检索模型,在问题-表格匹配中考虑表格的结构特性。答案生成从该表格中进一步找出问题对应的答案 Beijing。表格问答主要涉及表格检索和答案生成两个方法。
3. 文本问答
文本问答(text-based QA),基于给定文本生成问题对应的答案,按照答案颗粒度的不同,文本问答任务又可以进一步分为答案句子选择和机器阅读理解两大类。
答案句子选择(answer sentence selection)任务从文本中寻找能够作为问题答案的句子。 由于文本所包含的句子集合能够通过断句的方式直接得到,该任务可以通过对句子集合进行打分和排序,并选择得分最高的句子作为最终的答案。 这里,打分的准则是每个句子能够作为当前问题答案的可能性。
机器阅读理解(machine reading comprehension)任务从文本中寻找能够作为问题答案的短语。 该任务的解决思路有两种:1)对文本中全部可能的答案短语候选进行抽取和排序,这样机器阅读理解可以看成对答案短语候选集合的一个排序任务;2)对文本中每个单词是否属于答案进行0/1标注,这样机器阅读理解可以看成一个序列标注任务。
下图给出一个文本问答的示例。对于问题“When were women allowed to vote in the usa?”,答案句子选择任务选择文本中的第一句话作为答案,阅读理解任务则从文本中抽取出短语"August 18,1920"作为答案。

由于博主,是做文本问答和机器阅读理解任务,后续还会深入学习和介绍文本问答的相关方法。
4. 社区问答
问答对(question-answer pair),是指问答社区网站(Quora、知乎等)上提供的《问题,答案》对数据集合。 该类数据通过如下方式生成:提问者通过网站发布问题,问答社区网站的其他用户如果对该问题感兴趣,可以直接进行回复,这样就生成一个问答对(如下图所示)。问答社区网站通常采用积分方式激励用户进行回答以及回复。同时,用户还可以通过“点赞”等方式对高质量答案进行标记,这些信息可以用来过滤低质量的回答。典型的问答社区网站为中文的百度知道/知乎和英文的Quora。由于问答对数据是人们对经验的高度总结,这类内容很难从文本中自动抽取获得,因此这类数据对于构建主观类型问答系统(比较类、意见类、指导类问题)而言非常重要。

社区问答(community QA),基于从问答社区网站抓取的问答对进行问答任务。具体来说,给定输人问题,社区问答从问答对中检索与输人问题语义最为匹配的已有问题,并采用该已有问题对应的答案作为当前问题的答案。由此可见,该类问答方法最关键的环节是计算当前问题和已有问题之间的语义相似度,以及计算问题和答案之间的语义相关度。 下图给出一个社区问答的例子。

四、QA任务相关的评测数据集
1. 知识图谱问答
在知识图谱问答任务中,最常用的英文问答数据集包括 WebQuestions 数据集和SimpleQuestions 数据集.WebQuestions[1]由斯坦福在2013年发布,包含5,810个来自Google搜索日志的自然语言问题,每个问题对应的答案由 Amazon Mechanical Turk上的标注人员基于 Freebase知识图谱进行标注。SimpleQuestions[2]由Facebook在2015年发布,包含108,442个《问题,答案》对。和WebQuestions 的标注方式不同,该数据集从Freebase 中选取知识图谱三元组
除了直接针对知识图谱问答任务标注的数据集外,针对语义分析任务的标注数据集也可以用于知识图谱问答的研究,例如 Free917资源1-6)[4]和Geoguery[5-8]这类数据集针对问题标注对应的语义表示,用于训练语义分析器。
2. 表格问答
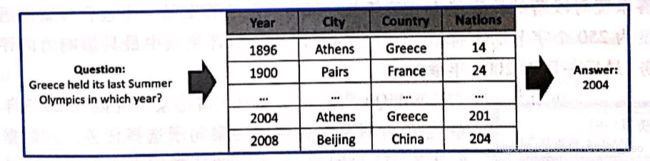
WikiTableQuestions[9]由斯坦福在2015年发布,主要针对表格问答任务。该数据集总共包含22033条人工标注的《问题,表格,答案》三元组,任务的目标是基于给定表格和问题,生成问题对应的答案。 该数据集中的表格来自英文维基百科,Amazon Mechanical Turk上的标注人员针对每个表格编写问题,并基于该表格标注问题对应的答案。下图给出该数据集中一个《问题,表格,答案》三元组示例。
WikiTableQuestions 数据集假设每个问题对应的表格已经存在,但真实场景中,如何为每个问题找到相关的表格,本身就是一个值得研究的问题。 针对该问题,微软亚洲研究院在2017年提出NLPCC-TBQA 数据集[10],用于表格检索任务。给定一个表格集合,该任务的目标是从表格集合中找到和输人问题在内容上最相关的表格子集。
3. 文本问答
TREC-8是由TREC在1999年提出的智能问答评测任务,它要求参加评测的问答系统为每个问题返回一个答案文档编号(Answer Doc ID),并保证该答案文档包含问题对应的答案短语或句子。该任务从信息检索角度开创了智能问答研究的一个崭新方向。下表给出TREC-8评测集中的一个问题对例子。

TREC-9在标注答案文档编号外,同时注明了问题对应的答案短语(Answer Phrase)。这类标注能够衡量智能问答系统从文档中抽取精准答案的能力,即机器阅读理解能力。下表给出TREC-9评测集中的一个问题-答案对例子。

随后两届 TREC问答评测任务TREC 2001和TREC 2002与TREC-9保持一致。2003年TREC 问答评测提出基于段落的问答任务(passages task),用于考察问答系统对段落的检索能力。 该任务中每个问题的答案是一个包含答案短语的长度为250个字节的字符串。 TREC问答评测是问答领域中最具影响力的评测任务,最后一届在2007年举办。
WikiQA[11]由微软雷德蒙研究院在2015年发布,主要针对英文领域的答案句子选择任务。该数据集包括3,047个问题,每个问题从微软必应搜索引擎的查询日志中采样获得,并保证该问题以疑问词开头、以问号结尾、并且点击过至少一个维基百科页面。给定每个问题,Amazon Mechanical Turk上的标注人员对该问题点击过的维基百科网页中包含的句子进行标注,将能够回答该问题的句子标注为1,将其他句子标注为0。
NLPCC-DBQA[3]由微软亚洲研究院在2016年发布,主要针对中文领域的答案句子选择任务。和WikiQA数据集不同,NLPCC-DBQA 将采样得到的维基百科文本直接提供给标注人员,由标注人员自主选择其中一个或若干个句子作为答案,并人工书写一个和该答案相关的问题。该数据集总共包含14,551个《问题,文本》标注对,并被用于由NLPCC举办的中文开放领域智能问答评测中,下图给出该数据集中的一个例子,其中,第一列是问题,第二列是问题对应的文本句子集合,第三列是标注答案,0表示当前句子不能作为问题对应的答案,1表示当前句子能够作为问题对应的答案。

SQuAD[12]由斯坦福在2016年发布,该数据集可以说是目前最热门的机器阅读理解数据集。 给定一个问题和一段文本,该任务的目的是从文本中抽取出问题对应的答案短语。 该数据集包含超过10万个《问题,文本,答案短语》标注对,目前对外开放了训练集和开发集,测试集暂时没有公开,参赛队伍可以验证其系统在测试集上的性能。 典型的机器阅读理解方法我们之后会详细介绍。
除 SQuAD 外,MS MARCO[13]和CNN/DailyMail[14]也是近年来出现的阅读理解数据集。 在中文方面,哈尔滨工业大学讯飞联合实验室在2017年举办了第一届“讯飞杯”中文机器阅读理解评测(CMRC2017)。百度也在2017年推出了中文机器阅读理解数据集 Du-Reader,并在2018年3月举办了“2018机器阅读理解技术竞赛”。
4. 社区问答
Community Question Answering[15]是近年来较受关注的社区问答评测任务。该任务是SemEval的一个子任务,从2015年开始每年举办一次。2015年第一届CQA的评测内容是基于给定问题,判断某条来自社区问答网站的答案是否能够回答该问题。 该任务的核心是计算问题和答案之间的相关性,这和答案句子选择任务非常类似。2016年第二届CQA在提供答案的同时,还提供每个答案对应的问题。 这样,该任务在计算问题和答案相关度的基础上,进一步引人问题和问题相似度的计算。2017年举办的第三届 CQA继续沿用第二届的评测任务。
Quora Question Pairs由Quora公司在2017年发布。该数据集对超过400000条Quora中的问题-问题对进行语义一致性的标注,非常适合用于训练社区问答系统中的问题-问题匹配模型和问题改写模型。
五、参考文献
[1] Jonathan Berant,Andrew Chou,Roy Frostig,etc.Semantic Parsing on Freebase from Question-Answer Pairs[C].EMNLP,2013.
[2] Antoine Bordes,Nicolas Usunier,Sumit Chopra,etc.Large-scale Simple Question Answering with Memory Networks[C].arXiv,2015.
[3] Nan Duan.Overview of the NLPCC-ICCPOL 2016 Shared Task:Open Domain Chinese Question Answering[C].NLPCC,2016.
[4]Qingqing Cai,Alexander Yates.Large-scale Semantic Parsing via Schema Matching and Lexicon Extension[C].ACL,2013.
[5]Raymond J.Mooney.Learning Semantic Parsers:An Important but Under-Studied Problem[C].AAAI,2004.
[6]Rohit J.Kate,Raymond J.Mooney.Semi-Supervised Learning for Semantic Parsing using Support Vector Machines[C].NAACL,2006
[7]Ruifang Ge,Raymond J.Mooney.Learning Semantic Parsers Using Statistical Syntactic Parsing Techniques[C].Technical Report UT-AI-TR-06-327,2006.
[8]Yuk Wah Wong,Raymond J.Mooney.Learning for Semantic Parsing with Statistical Machine Translation[C].NAACL,2006.
[9] Panupong Pasupat,Percy Liang.CompositionaL Semantic Parsing on Semi-Structured Tables[C].ACL,2015.
[10] Nan Duan.Overview of the NLPCC 2017 Shared Task:Open Domain Chinese Question Answering[C].NLPCC,2017.
[11] Yi Yang,Wen-tau Yih,Christopher Meek.WIKIQA:A Challenge Dataset for Open-Domain Question Answering[C].EMNLP,2015.
[12] Pranav Rajpurkar,Jian Zhang,Konstantin Lopyrev,etc.SQuAD:100,000+Questions for Machine Comprehension of Text[C].EMNLP,2016.
[13] Tri Nguyen,Mir Rosenberg,Xia Song,etc.MS MARCO:A Human Gerrerated MAchine Reading COmprehension Dataset[C].NIPS,2016.
[14] Karl Moritz Hermann,Tomas Kocisky,Edward Grefenstette,etc.Teaching Machines to Read and Comprehend[C].NIPS,2015.
[15] B.Li,Y.Liu,E.Agichtein,etc.Community Question Answering. SemEval,2016.