数据结构——基础(算法、复杂度、迭代与递归、动态规划)
目录
一、计算(数据结构与算法研究的对象和目标)
二、计算模型
一般情况下我们主要考虑时间复杂度
三、大O记号
常见时间复杂度的分级
四、算法分析
级数
级数在循环中的应用
算法分析示例
五、迭代与递归
减而治之
分而治之
六、动态规划
一、计算(数据结构与算法研究的对象和目标)
计算:即信息处理。是指借助某种工具,遵循一定规则,以明确而机械的形式进行的操作。
计算模型:即计算处理工具。
算法:在特定计算模型下,解决特定问题的指令序列(操作步骤)。
算法具有如下特征:
1、具有输入
2、能够输出
3、确定性 算法的每个基本操作步骤必须有确定的含义
4、可行性 算法中每个基本操作步骤都可以实现,并且在有限时间内完成
5、有穷性 对于任何输入,经过有限次基本操作之后都可以得到输出(举个栗子,Hailstone问题中Hailstone(n)无法确定是否存在n,使程序无法终止。)
综上可知,程序≠算法。程序可以无限循环,或者永远无法满足终止条件,但算法不可以。
好的算法,最重要的是效率,速度尽可能快,存储空间尽可能小。当然前提是正确,健壮、可读也是一方面。
程序=算法+数据结构 //N.Wirth于1976年提出
(算法+数据结构)×效率=计算 //由上式引申
二、计算模型
一个计算模型,效率取决于数据结构(Data Structure)和算法(Algorithm),我们称之为DSA。从效率而言,不同的DSA性能存在一定的差别。我们需要一种定量的方式表示它们之间的差别——算法效率的度量。
度量属于算法分析的范畴。算法分析主要包括两方面:正确性和复杂度。数据结构中我们关注的是复杂度,包括时间复杂度(运行时间)和空间复杂度(所需存储空间,通常我们只考虑除了输入所占空间之外,算法运行过程中所需要另外开辟的存储空间。即新定义的用于计算的变量所需的空间,如循环变量,临时变量,逻辑变量等)。
一般情况下我们主要考虑时间复杂度
使用特定算法求解同一类问题,其效率取决于众多的因素:1、算法(运算的规模)。2、问题的规模(比如求100以内还是1000以内的素数)。3、选用的语言。4、编译器编译的质量。5、计算机性能。因此,不可能使用绝对的时间单位来衡量算法的效率。假如我们使用相同的语言和编译器、在一台计算机上求解同一类问题的不同实例,那么可以认为一个特定算法的时间复杂度,往往只依赖于问题实例的规模。
对于特定问题的不同算法,很难用实验统计的方式确定真正的效率,因为不同的算法可能更适应于不同规模和类型的输入。为了给出客观评价,需要抽象出一个理想的平台或者模型,不依赖任何外部的各种因素。比如图灵机(Turing Machine)模型和随机存取机(Random Access Machine)模型。
图灵机(Turing Machine)

如上图所示,图灵机由以下部分组成:
- 一条无限长的纸带(tape):被均匀划分为单元格(cell),每个单元格中包含一个来自有限字母表中的符号(本例中为 #、0、1),字母表中有一个特殊的符号表示空(比如上图中的 #) 。纸带上的格子从左到右顺序编号,纸带右端无限延长。
- 一个读写头(head):任何时刻,读写头都对着某一个单元格,该读写头可以在纸带上左右移动,每次只能移动一个单元。它能读出当前所指的格子上的符号,并能改变当前格子上的符号。
- 一个状态寄存器(state):它用来保存图灵机当前所处的状态。图灵机的所有可能状态的数目是有限的,并且有一个特殊的状态,称为停机状态(这里定义为 h)。
- 一套控制规则(transition function):它根据当前机器所处的状态以及当前读写头所指的格子上的符号来确定读写头下一步的动作,并改变状态寄存器的值,令机器进入一个新的状态。这里定义传递函数为:(q,c;d,L/R,p),若当前状态为q且当前字符为c,则将当前字符更改为d,更改完毕后向左L或向右R移动一个单元格,同时将状态更改为p。
随机存取器(Random Access Machine)
随机存取器由以下部分组成:
- 无限的经过顺序编号的寄存器 :R[0],R[1],R[2]。。。
- 十种仅需常数时间的基本操作 :R[i] < - c (常数赋值)、R[i] < - R[j](互相赋值)、R[i] < - R[R[j]](间接取址后赋值)、R[R[j]] < - R[i](赋值给间接取址的寄存器)、R[i] < - R[j] + R[k](相加后赋值)、R[i] < - R[j] - R[k](相减后赋值)、IF R[i] = 0 GOTO n(条件判断及转向)、IF R[i] > 0 GOTO n(条件判断及转向)、GOTO n(转向)、STOP(终止语句)
在TM与RAM等模型中,我们将算法的运行时间转化为需要执行的基本操作的次数。
三、大O记号
渐进分析:大O记号(最坏情况下的时间复杂度)
对于特定问题的不同算法,我们关注的是,随着问题规模的增长,算法的计算成本如何增长(主要考虑问题规模足够大时,计算成本的增长速率)。因此可以采用渐进分析的方法,假设规模n趋于无限大,计算算法所需执行的基本操作次数 T(n) 以及需要占用的存储空间 S(n)(通常不考虑后者)。
一个算法由控制结构(顺序、分支、循环)和原操作(基于固有数据类型的基本操作语句)构成。
为了比较同一个问题的不同算法,通常我们从算法中选取一种对所研究问题来说是主要基本操作的原操作(原操作应该是重复执行次数与算法执行次数成正比的基本操作),以该操作重复执行的次数作为算法的时间量度。
假如问题的规模为 n ,算法中基本操作的执行次数是 n 的函数 f(n) , 算法的时间复杂度记做:T(n)=O[f(n)] 。大O记号是指,取T(n)随问题规模增长的最主要趋势然后记做 f(n),因此可以忽略T(n)最高次项常系数以及低次项。
如:++x; for(i=1;i<=n;++i) for(j=1;j<=n;++j)
{++x;} for(k=1;k<=n;++k)
{++x;}
以上三个程序的时间复杂度分别为:O(1)、O( )、O(
)、O(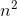 ) 。这里忽略了循环过程本身所花费的时间,只考虑循环体执行所花费的时间。
) 。这里忽略了循环过程本身所花费的时间,只考虑循环体执行所花费的时间。
一般情况下,对一个问题只需要选择一种基本操作来分析时间复杂度;有时候也需要同时考虑多种基本操作,甚至对不同操作赋予不同的权值来反映不同操作的相对执行时间。
有时候,对于同规模问题的不同实例,时间成本也可能天差地别。比如在平面上的n个点中,找到所成三角形面积最小的三个点。

最坏的情况下我们需要枚举所有 ![]() 种组合,但运气好的话可能第一次就找到了共线的三个点,显然不可能有比0更小的面积了。
种组合,但运气好的话可能第一次就找到了共线的三个点,显然不可能有比0更小的面积了。
因此稳妥起见,算法的时间复杂度,我们取值为最坏的情况下的时间复杂度。
当然有些特殊情况中我们也会考虑算法最好情况以及平均情况下的时间复杂度,它们分别用 ![]() 记号和
记号和 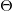 记号来表示。
记号来表示。
常见时间复杂度的分级
高效解
O(1) 常数复杂度
不含与问题规模n相关的显式或隐式循环的算法,即只由分支判断以及常数次循环组成的顺序执行的代码体。
注意,对于O(1) 类算法,随着问题规模的增长,其执行时间是不会变的。例如取非极端元素问题:在不少于三个元素的整数集合中找出一个非最大最小值的元素。无论集合中有多少元素,我们只需要取前三个元素并排除其中最大和最小的即可。
O(logn) 对数复杂度
不需要标明对数的底数以及n的幂指数。对于常底数来说,我们可以利用公式将对数的底数转化为任意常数,并将原底数与新底数的对数作为常系数忽略掉。对于n的常数次幂,也可以将幂指数调整为对数的常系数忽略掉。
这类算法也非常有效,时间复杂度无限接近于常数,低于任何次数为正的多项式。
有效解
O(![]() ) 多项式复杂度
) 多项式复杂度
其中,O(n )称作线性复杂度。多数情况下算法复杂度会介于O(n)到O(
)称作线性复杂度。多数情况下算法复杂度会介于O(n)到O(![]() )之间。当然,高于O(
)之间。当然,高于O(![]() )的复杂度,无论c取多大,都认为是可解的算法,只是效率会受到较大影响。
)的复杂度,无论c取多大,都认为是可解的算法,只是效率会受到较大影响。
难解
O(![]() ) 指数复杂度
) 指数复杂度
这类算法的计算成本增长极快,通常不可忍受。从O(![]() ) 到O(
) 到O(![]() ) ,是从有效算法到无效算法的分水岭。很多问题的O(
) ,是从有效算法到无效算法的分水岭。很多问题的O(![]() ) 算法往往显而易见,但是想要设计出O(
) 算法往往显而易见,但是想要设计出O(![]() ) 算法却很难,甚至无法设计出来。
) 算法却很难,甚至无法设计出来。
四、算法分析
主要任务包括,验证算法的正确性(不变性x单调性)以及复杂度的界定。
复杂度分析的主要方法有:
1、对于迭代类算法:级数求和
2、对于递归式算法:有两种方法,直观形象的递归跟踪和抽象思维的递推方程
3、猜测+验证
级数
迭代类算法的时间复杂度本质即级数求和。
算数级数:与末项平方同阶。
T(n)=1+2+ ![]() +n = n(n+1)/2 = O(
+n = n(n+1)/2 = O(![]() )
)
幂级数:比幂次高一阶。
![]()
![]()
![]()
![]()
![]()
几何级数(a>1):与末项同阶。
![]()
![]()
收敛级数:O(1)。
![]()
![]()
调和级数:
![]()
p级数(又称超调和级数):
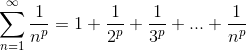
对数级数:
![]()
级数在循环中的应用
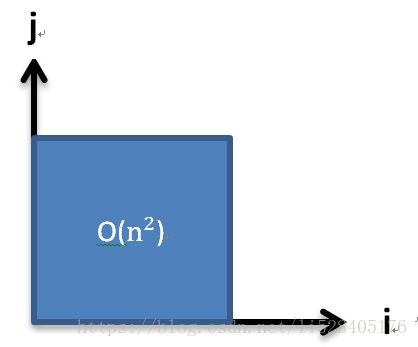
可以利用级数的结论,分析代码中涉及的循环操作的时间复杂度。双重循环以内也可以通过循环变量的取值范围,绘制二维图形并分析其面积来确定复杂度。例如:
1、i=0:n; i++;
j=0:n; j++;
执行次数为算数级数:
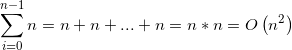
2、i=0:n; i++;
j=0:i; j++;
执行次数为算数级数:
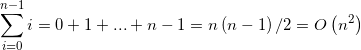
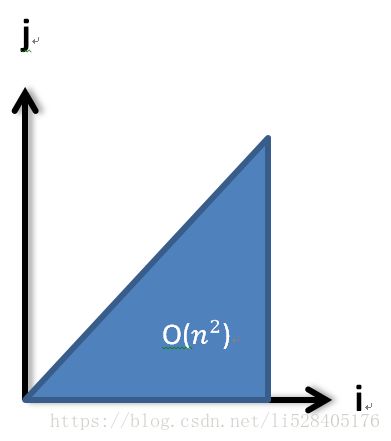
3、i=1:n; i<<1;
j=0:i; j++;
执行次数为几何级数:
由于 i 每次呈指数增长,因此第一层循环的次数为 ![]() ,再考虑第二层循环可得总循环次数为:
,再考虑第二层循环可得总循环次数为:
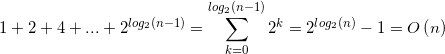
算法分析示例
冒泡/起泡排序法
问题:给定n个整数,将他们按(严格或非严格)升/降序排列。如:将 5、4、6、2、3、7、1 按升序排列
方法为:从第一个元素开始,依次与右边相邻的元素做比较。如果第一个元素比第二个元素大则二者交换位置,否则不做操作。然后再比较第二和第三个元素,规则相同。直到最后一个元素也参与了比较,则第一轮循环结束。第一轮一共经过了n-1次比较,最大的元素必然被交换到队列的末尾。然后开始第二轮比较,同样从第一个元素开始,依次向右比较,将第二大的元素交换到队列倒数第二的位置,第二轮的比较次数为n-2。然后继续开始循环,直到所有的元素顺序排列。每一轮循环能够完成一个元素的落位,易知完成所有元素的排列需要 n-1轮循环,第 i 轮需要比较 n-i 次。
int i,j,temp;
for (i=1; i a[j+1])
{
temp=a[j];
a[j]=a[j+1];
a[j+1]=temp;
}
}
} 这种写法是效率比较低的。因为即使有时候我们经过两轮交换就以及完成了排序,但还是要根据循环变量继续循环下去。后面我们会对算法进行优化。
下面证明冒泡法的正确性
首先算法具有的不变性:经过k轮循环后,最大的k个元素必然就位。
算法的单调性:经过k轮循环后,问题的规模缩减至n-k。
由以上两条,可以得出算法的正确性:至多经过n轮循环后,算法必然终止,并且给出正确结果。
接下来计算其复杂度
时间复杂度:1+2+ ... + n-1 =n(n-1)/2= O(![]() )
)
空间复杂度:只需要定义两个循环变量 i,j 以及一个临时变量 temp,所以复杂度为O(3)。
除了使用大O记号对算法进行定性分析,有时候还需要对算法进行粗略的定量分析,这时可以使用封底估算。下面列出一些我们常见的一些时间概念:
普通的pc机浮点计算速度大概为:10^9次/sec
1天=24h x 60min x 60sec ![]() 25 x 4000 = 10^5 sec
25 x 4000 = 10^5 sec
1生 ![]() 1世纪 =100年 x 365 = 3 x 10^4天 = 3 x 10^9 sec
1世纪 =100年 x 365 = 3 x 10^4天 = 3 x 10^9 sec
“三生三世” ![]() 300年 = 10^10 sec
300年 = 10^10 sec
宇宙大爆炸至今 ![]() 10^21 sec
10^21 sec
五、迭代与递归
迭代与递归是都是循环的一种。
迭代是显式的循环。从程序结构上来讲,迭代与普通循环无异。迭代与普通循环的区别是,迭代是在循环代码中不断使用变量的原值递推出变量的新值,当前变量的新值又作为下次循环的初始值。也就是说,迭代时,循环代码在不同循环轮次中始终是对同一组变量做修正。比如最简单的数组元素求和:sum=sum+a[i] 。而上面提到的冒泡排序法则不属于迭代。
递归是隐式的循环。从程序结构上来讲,递归是指函数重复调用自身而实现的循环。这种隐式的循环结束的方式是,当程序满足终止条件时逐层返回。在循环次数较大的时候,递归的效率明显低于迭代。
递归有两种不同的思想。一种叫做减而治之,另一种为分而治之,它们共同的特点是把多阶段问题转化为一系列单阶段问题,利用各阶段之间的关系,逐个求解。即把原问题划分为一层层的子问题,然后逐层求解。
减而治之
即把一个大规模的问题划分为两个子问题,其中一个子问题相对与原问题形式相同且规模有所缩减,另一个子问题是平凡的(即可以直接求解的)。然后我们可以利用相同的方法递归的把未解决的子问题进一步的进行划分,直到被划分的两个子问题同时可解。最后我们把各层子问题的解合并即可得到原问题的解。例如:数组元素求和可以改写为以下线性递归的程序
sum (int A[],int n)
{
return (n<1) ? 0 : sum(A,n-1)+A[n-1];
}
那么如何确定递归调用的复杂度是多少呢?这里介绍一种叫做递归跟踪(recursion trace)的分析方法。
所谓递归跟踪,即把整个递归调用的过程用一张图表示出来。
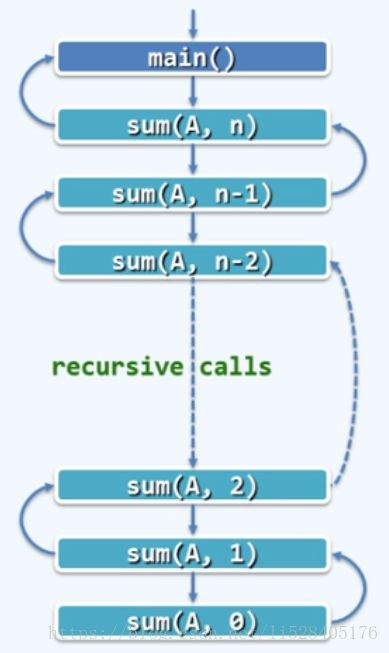
然后检查每个递归实例所需时间,其中递归调用语句要记入对应的子实例中,累计时间总和即算法的时间复杂度。
对于本例而言,T(n)=O(1) x (n+1)=O(n)。
但是,递归跟踪虽然直观形象,但仅适用于简明的递归模式。对于比较复杂的递归调用形式,很难使用图绘制出来。因此需要另外一种较为间接抽象,但更适用于复杂的递归模式的递归方程。
对于本例而言,递归方程:T(n)=T(n-1)+O(1)
递归基:T(0)=O(1)
求解:T(n) - n=T(n-1)+O(1) - n
= T(n-1) - (n -1)=T(n-2) + O(1) - (n -1)
= T(n-2) - (n -2) = ......
= T(1) -1
= T(0)
于是:T(n) =O(1)+n =O(n)
分而治之
即把一个大规模的问题划分为多个(通常两个)子问题,且规模相当。然后采用递归的策略分别求解子问题,最后通过子问题的解合并得到原问题的解。例如:二分递归数组元素求和
sum(int A[],int L,int H) // L 为第一个元素的下标,H为最后一个元素的下标
{
if(L==H) return A[L];
int M=(L+H)>>1; //M表示中间元素的下标
return sum(A,L,M)+ sum(A,M+1,H);
}
复杂度分析,递归跟踪法:
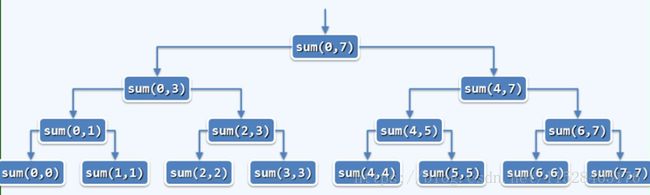
T(n)=O(1) x (![]() )
)
=O(![]() -1) =O(n)
-1) =O(n)
递归方程法:
递归方程:T(n)= 2 x T(n/2) + O(1)
递归基:T(1)=O(1)
求解:T(n) + O(1)=2 x T(n/2) + O(1) +O(1)
=2 ( T(n/2) + O(1) ) =2( 2T(n/4) + O(1) +O(1) )
= ( T(n/4) + O(1) ) = ......
( T(n/4) + O(1) ) = ......
=![]() ( T(1)+ O(1) )
( T(1)+ O(1) )
=O(n)
下面再给出一个例子来说明递归思想中分而治之的优点:
对于max2问题,即从数组区间A[L,H]中取出最大的两个数A[x1]和A[x2]。
迭代法1:两个数分别迭代寻找
void max2(int A[], int L, int H, int & x1, int & x2)
{
x1=x2=L;
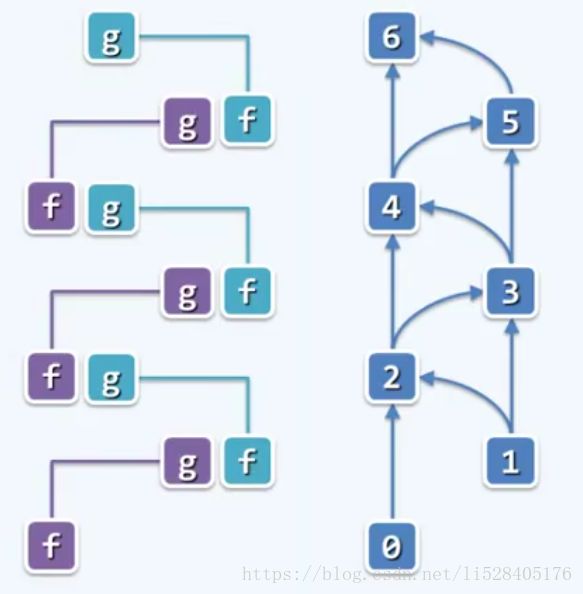
for (int i=L+1; i if (A[x1] for (int i=L+1; i if (A[x2] for (int i=x1+1; i if (A[x2] } 比较次数为:T(n)=2n-3 迭代法2:两个数同时迭代寻找 void max2(int A[], int L, int H, int & x1, int & x2) { if (A[x1=L] < A[x2=L+1]) swap(x1,x2); for (int i=L+2; i if (A[x2] < A[i]) if (A[x1] < A[x2 = i]) swap(x1,x2); } 比较次数为: 最好情况下:1+(n-2) = n-1 最坏情况下:1+(n-2) x 2 = 2n-3 二分递归法: 我们将数组二分,先找出左边的最大者和次大者,以及右边的最大者和次大者。然后将两边的最大者做比较,胜出者即全局最大者。可能左边大也可能右边大分别对应上图左半边和右半边。假如左边的最大者胜出,则再比较左边的次大者和右边的最大者,胜出者即为全局次大者。接着利用递归策略分别求得子数组的最大者和次大者。最后逐层返回可得全局最大者和次大者。代码如下图: 执行次数为: 最好情况下:懒得计算了 最坏情况下:T(n)=5n/3 - 2 与前两种方法相比,二分递归法显然更加有效率。即使在最坏情况下都比第一种方法要高效。(如果采用锦标赛树等数据结构,此问题的求解效率还可以进一步提高) 动态规划是DSA设计和优化的重要形式和手段。动态规划的思路和递归相同,也是将原问题分解,然后逐个求解。但通过递归所拆分出的子问题有许多是重复的,而重复计算会浪费大量的时间。动态规划说白了就是记忆化的递归,它把子问题的解临时存储在堆栈中,省去了重复计算的步骤,从而提高了算法效率。递归是自顶而下的,动态规划是自底而上的。所谓动态规划,可以简单理解为先用递归找出算法的本质并给出初步解然后等效的转化为迭代的形式(问题规模较大时,递归的效率比迭代低)。 例如,求解斐波那契数列的第 n 项,Fibonacci(n) = Fibonacci(n-1) + Fibonacci(n-2),即{0,1,1,2,3,5,8,13,...} 二分递归:int fib(int n) { return (2>n) ? n : fib(n-1) + fib(n-2); } 把原问题分解为前两项(即子问题)的求解 递归方程:T(n)=T(n-1)+T(n-2)+O(1) 其中n>1 递归基:T(0)=T(1)=O(1) 令 S(n)= [T(n)+O(1)] / 2 则 S(0)=1=fib(0),S(1)=1=fib(2) 归纳可得,S(n) = S(n-1) + S(n-2) = fib(n+1),根据斐波那契通项公式可知,S(n)=O( 所以,T(n) = 2*S(n) -1 = O( fib(n+1) ) = O( 封底估算:需要记住, 于是, 递归跟踪图: 由上图可知,二分递归过程中,存在大量的重复项的计算,因此导致运行效率低下。 (解决办法,记忆:memoization)要去掉重复的计算,当然我们最容易想到的就是将已计算过的数列项制表备查。初始化的时候可以都设置为负数表示还没有计算,一旦计算出某一项的结果就记录到表中。每次递归过程中都会先查询表格中的值从而避免重复计算。但是这样做需要消耗较多的存储空间,因为需要开辟一个数组来存储所有项的值。 线性递归:__int64 fib ( int n, __int64& prev ) { { __int64 prevPrev; prev = fib ( n - 1, prevPrev ); //递归计算前两项,prevPrev表示前前项 时间复杂度:O(n) 迭代:(动态规划)我们将计算方向颠倒过来,由自上而下的递归,改为自下而上的迭代。以上楼梯的方式,动态的更新代表相邻两项的两个变量的值。 __int64 fibI ( int n ) { 时间复杂度:只有一层循环,目测可知 T(n) = O(n) 空间复杂度:只有两个变量 f 和 g ,即O(2) 以上,通过递归,我们可以设计出可行并且正确的解。而通过动态规划,能够消除重复计算,提高算法效率。 教材可选算法导论或者普林斯顿的算法一和算法二 动态可视化网站Visualgo:https://visualgo.net/zh 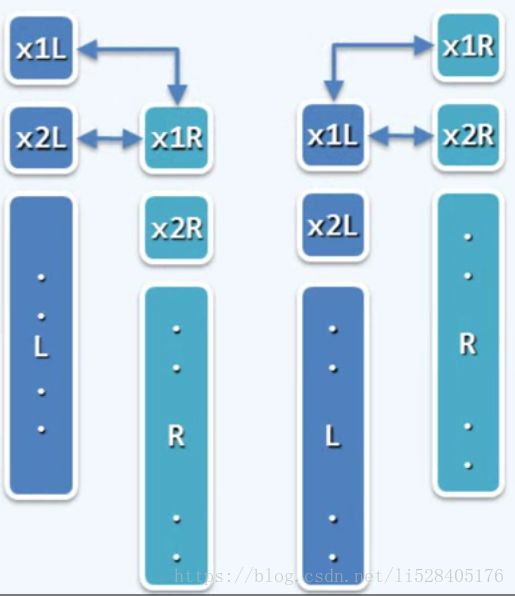

六、动态规划
![]() ),其中
),其中![]()
![]() ) = O(
) = O(![]() )
)![]() ,
,![]()
![]() ,这也就是我们从第43项开始感觉到明显的计算延迟的原因。
,这也就是我们从第43项开始感觉到明显的计算延迟的原因。![]() sec = 1 天
sec = 1 天![]() sec = 300 年
sec = 300 年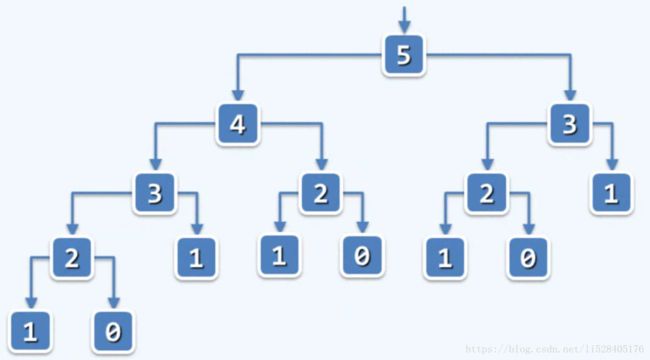
if ( 0 == n ) //若到达递归基,则
{ prev = 1; return 0; } //直接取值:fib(-1) = 1, fib(0) = 0
else
return prevPrev + prev; //其和即为正解
}
}
__int64 f = 1, g = 0; //初始化:fib(-1)、fib(0)
while ( 0 < n-- ) { g += f; f = g - f; } //依据原始定义,通过n次加法和减法计算fib(n)
return g; //返回
}