南瓜书《动手机器学习公益训练营》-机器翻译、注意力机制Transformer模型
1 机器翻译和数据集
机器翻译(MT):将一段文本从一种语言自动翻译为另一种语言,用神经网络解决这个问题通常称为神经机器翻译(NMT)。
主要特征:输出是单词序列而不是单个单词。 输出序列的长度可能与源序列的长度不同。
数据预处理
将数据集清洗、转化为神经网络的输入minbatch
import os
os.listdir('/home/kesci/input/')
import sys
sys.path.append('/home/kesci/input/d2l9528/')
import collections
import d2l
import zipfile
from d2l.data.base import Vocab
import time
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils import data
from torch import optim
with open('/home/kesci/input/fraeng6506/fra.txt', 'r') as f:
raw_text = f.read()
print(raw_text[0:1000])
def preprocess_raw(text):
text = text.replace('\u202f', ' ').replace('\xa0', ' ')
out = ''
for i, char in enumerate(text.lower()):
if char in (',', '!', '.') and i > 0 and text[i-1] != ' ':
out += ' '
out += char
return out
text = preprocess_raw(raw_text)
print(text[0:1000])

字符在计算机里是以编码的形式存在,我们通常所用的空格是 \x20 ,是在标准ASCII可见字符 0x20~0x7e 范围内。
而 \xa0 属于 latin1 (ISO/IEC_8859-1)中的扩展字符集字符,代表不间断空白符nbsp(non-breaking space),超出gbk编码范围,是需要去除的特殊字符。再数据预处理的过程中,我们首先需要对数据进行清洗。
分词
字符串—单词组成的列表
num_examples = 50000
source, target = [], []
for i, line in enumerate(text.split('\n')):
if i > num_examples:
break
parts = line.split('\t')
if len(parts) >= 2:
source.append(parts[0].split(' '))
target.append(parts[1].split(' '))
source[0:3], target[0:3]
d2l.set_figsize()
d2l.plt.hist([[len(l) for l in source], [len(l) for l in target]],label=['source', 'target'])
d2l.plt.legend(loc='upper right');

建立词典
单词组成的列表—单词id组成的列表
def build_vocab(tokens):
tokens = [token for line in tokens for token in line]
return d2l.data.base.Vocab(tokens, min_freq=3, use_special_tokens=True)
src_vocab = build_vocab(source)
len(src_vocab)
载入数据集
def pad(line, max_len, padding_token):
if len(line) > max_len:
return line[:max_len]
return line + [padding_token] * (max_len - len(line))
pad(src_vocab[source[0]], 10, src_vocab.pad)
def build_array(lines, vocab, max_len, is_source):
lines = [vocab[line] for line in lines]
if not is_source:
lines = [[vocab.bos] + line + [vocab.eos] for line in lines]
array = torch.tensor([pad(line, max_len, vocab.pad) for line in lines])
valid_len = (array != vocab.pad).sum(1) #第一个维度
return array, valid_len
def load_data_nmt(batch_size, max_len): # This function is saved in d2l.
src_vocab, tgt_vocab = build_vocab(source), build_vocab(target)
src_array, src_valid_len = build_array(source, src_vocab, max_len, True)
tgt_array, tgt_valid_len = build_array(target, tgt_vocab, max_len, False)
train_data = data.TensorDataset(src_array, src_valid_len, tgt_array, tgt_valid_len)
train_iter = data.DataLoader(train_data, batch_size, shuffle=True)
return src_vocab, tgt_vocab, train_iter
src_vocab, tgt_vocab, train_iter = load_data_nmt(batch_size=2, max_len=8)
for X, X_valid_len, Y, Y_valid_len, in train_iter:
print('X =', X.type(torch.int32), '\nValid lengths for X =', X_valid_len,
'\nY =', Y.type(torch.int32), '\nValid lengths for Y =', Y_valid_len)
break
Encoder-Decoder
encoder:输入到隐藏状态
decoder:隐藏状态到输出
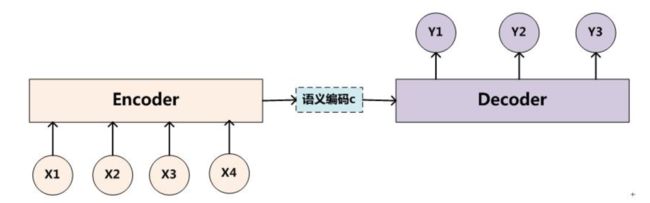
Sequence to Sequence模型
模型:
训练
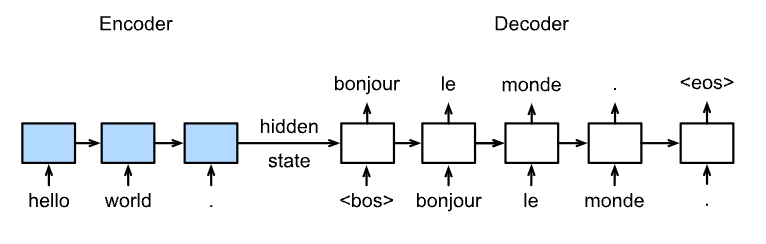
预测
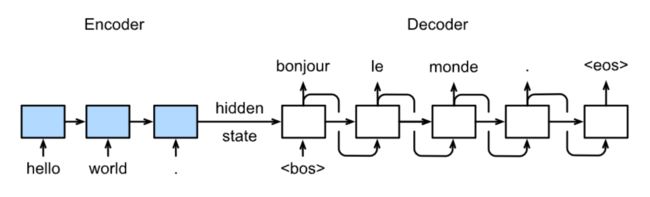
具体结构:
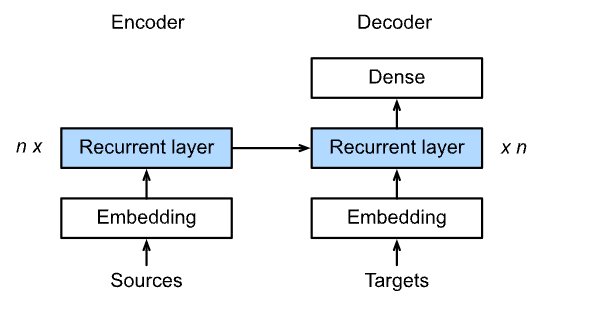
Encoder
class Seq2SeqEncoder(d2l.Encoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqEncoder, self).__init__(**kwargs)
self.num_hiddens=num_hiddens
self.num_layers=num_layers
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.LSTM(embed_size,num_hiddens, num_layers, dropout=dropout)
def begin_state(self, batch_size, device):
return [torch.zeros(size=(self.num_layers, batch_size, self.num_hiddens), device=device),
torch.zeros(size=(self.num_layers, batch_size, self.num_hiddens), device=device)]
def forward(self, X, *args):
X = self.embedding(X) # X shape: (batch_size, seq_len, embed_size)
X = X.transpose(0, 1) # RNN needs first axes to be time
# state = self.begin_state(X.shape[1], device=X.device)
out, state = self.rnn(X)
# The shape of out is (seq_len, batch_size, num_hiddens).
# state contains the hidden state and the memory cell
# of the last time step, the shape is (num_layers, batch_size, num_hiddens)
return out, state
Decoder
class Seq2SeqDecoder(d2l.Decoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqDecoder, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.LSTM(embed_size,num_hiddens, num_layers, dropout=dropout)
self.dense = nn.Linear(num_hiddens,vocab_size)
def init_state(self, enc_outputs, *args):
return enc_outputs[1]
def forward(self, X, state):
X = self.embedding(X).transpose(0, 1)
out, state = self.rnn(X, state)
# Make the batch to be the first dimension to simplify loss computation.
out = self.dense(out).transpose(0, 1)
return out, state
损失函数
def SequenceMask(X, X_len,value=0):
maxlen = X.size(1)
mask = torch.arange(maxlen)[None, :].to(X_len.device) < X_len[:, None]
X[~mask]=value
return X
class MaskedSoftmaxCELoss(nn.CrossEntropyLoss):
# pred shape: (batch_size, seq_len, vocab_size)
# label shape: (batch_size, seq_len)
# valid_length shape: (batch_size, )
def forward(self, pred, label, valid_length):
# the sample weights shape should be (batch_size, seq_len)
weights = torch.ones_like(label)
weights = SequenceMask(weights, valid_length).float()
self.reduction='none'
output=super(MaskedSoftmaxCELoss, self).forward(pred.transpose(1,2), label)
return (output*weights).mean(dim=1)
训练
def train_ch7(model, data_iter, lr, num_epochs, device): # Saved in d2l
model.to(device)
optimizer = optim.Adam(model.parameters(), lr=lr)
loss = MaskedSoftmaxCELoss()
tic = time.time()
for epoch in range(1, num_epochs+1):
l_sum, num_tokens_sum = 0.0, 0.0
for batch in data_iter:
optimizer.zero_grad()
X, X_vlen, Y, Y_vlen = [x.to(device) for x in batch]
Y_input, Y_label, Y_vlen = Y[:,:-1], Y[:,1:], Y_vlen-1
Y_hat, _ = model(X, Y_input, X_vlen, Y_vlen)
l = loss(Y_hat, Y_label, Y_vlen).sum()
l.backward()
with torch.no_grad():
d2l.grad_clipping_nn(model, 5, device)
num_tokens = Y_vlen.sum().item()
optimizer.step()
l_sum += l.sum().item()
num_tokens_sum += num_tokens
if epoch % 50 == 0:
print("epoch {0:4d},loss {1:.3f}, time {2:.1f} sec".format(
epoch, (l_sum/num_tokens_sum), time.time()-tic))
tic = time.time()
embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.0
batch_size, num_examples, max_len = 64, 1e3, 10
lr, num_epochs, ctx = 0.005, 300, d2l.try_gpu()
src_vocab, tgt_vocab, train_iter = d2l.load_data_nmt(
batch_size, max_len,num_examples)
encoder = Seq2SeqEncoder(
len(src_vocab), embed_size, num_hiddens, num_layers, dropout)
decoder = Seq2SeqDecoder(
len(tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
model = d2l.EncoderDecoder(encoder, decoder)
train_ch7(model, train_iter, lr, num_epochs, ctx)
Beam Search
简单greedy search:

维特比算法:选择整体分数最高的句子(搜索空间太大)
集束搜索:

课后练习题


贪心算法(又称贪婪算法)是指,在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,他所做出的是在某种意义上的局部最优解。
贪心算法不是对所有问题都能得到整体最优解,关键是贪心策略的选择,选择的贪心策略必须具备无后效性,即某个状态以前的过程不会影响以后的状态,只与当前状态有关。

3 Transformer
在之前的章节中,我们已经介绍了主流的神经网络架构如卷积神经网络(CNNs)和循环神经网络(RNNs)。让我们进行一些回顾:
- CNNs 易于并行化,却不适合捕捉变长序列内的依赖关系。
- RNNs 适合捕捉长距离变长序列的依赖,但是却难以实现并行化处理序列。
为了整合CNN和RNN的优势,[Vaswani et al., 2017] 创新性地使用注意力机制设计了Transformer模型。该模型利用attention机制实现了并行化捕捉序列依赖,并且同时处理序列的每个位置的tokens,上述优势使得Transformer模型在性能优异的同时大大减少了训练时间。
图10.3.1展示了Transformer模型的架构,与9.7节的seq2seq模型相似,Transformer同样基于编码器-解码器架构,其区别主要在于以下三点:
- Transformer blocks:将seq2seq模型重的循环网络替换为了Transformer Blocks,该模块包含一个多头注意力层(Multi-head Attention Layers)以及两个position-wise feed-forward networks(FFN)。对于解码器来说,另一个多头注意力层被用于接受编码器的隐藏状态。
- Add and norm:多头注意力层和前馈网络的输出被送到两个“add and norm”层进行处理,该层包含残差结构以及层归一化。
- Position encoding:由于自注意力层并没有区分元素的顺序,所以一个位置编码层被用于向序列元素里添加位置信息。

F i g . 10.3.1 T r a n s f o r m e r 架 构 . Fig.10.3.1\ Transformer 架构. Fig.10.3.1 Transformer架构.
在接下来的部分,我们将会带领大家实现Transformer里全新的子结构,并且构建一个神经机器翻译模型用以训练和测试。
多头注意力层
在我们讨论多头注意力层之前,先来迅速理解以下自注意力(self-attention)的结构。自注意力模型是一个正规的注意力模型,序列的每一个元素对应的key,value,query是完全一致的。如图10.3.2 自注意力输出了一个与输入长度相同的表征序列,与循环神经网络相比,自注意力对每个元素输出的计算是并行的,所以我们可以高效的实现这个模块。

F i g . 10.3.2 自 注 意 力 结 构 Fig.10.3.2\ 自注意力结构 Fig.10.3.2 自注意力结构
多头注意力层包含 h h h个并行的自注意力层,每一个这种层被成为一个head。对每个头来说,在进行注意力计算之前,我们会将query、key和value用三个现行层进行映射,这 h h h个注意力头的输出将会被拼接之后输入最后一个线性层进行整合。

F i g . 10.3.3 多 头 注 意 力 Fig.10.3.3\ 多头注意力 Fig.10.3.3 多头注意力
假设query,key和value的维度分别是 d q d_q dq、 d k d_k dk和 d v d_v dv。那么对于每一个头 i = 1 , … , h i=1,\ldots,h i=1,…,h,我们可以训练相应的模型权重 W q ( i ) ∈ R p q × d q W_q^{(i)} \in \mathbb{R}^{p_q\times d_q} Wq(i)∈Rpq×dq、 W k ( i ) ∈ R p k × d k W_k^{(i)} \in \mathbb{R}^{p_k\times d_k} Wk(i)∈Rpk×dk和 W v ( i ) ∈ R p v × d v W_v^{(i)} \in \mathbb{R}^{p_v\times d_v} Wv(i)∈Rpv×dv,以得到每个头的输出:
o ( i ) = a t t e n t i o n ( W q ( i ) q , W k ( i ) k , W v ( i ) v ) o^{(i)} = attention(W_q^{(i)}q, W_k^{(i)}k, W_v^{(i)}v) o(i)=attention(Wq(i)q,Wk(i)k,Wv(i)v)
这里的attention可以是任意的attention function,比如前一节介绍的dot-product attention以及MLP attention。之后我们将所有head对应的输出拼接起来,送入最后一个线性层进行整合,这个层的权重可以表示为 W o ∈ R d 0 × h p v W_o\in \mathbb{R}^{d_0 \times hp_v} Wo∈Rd0×hpv
o = W o [ o ( 1 ) , … , o ( h ) ] o = W_o[o^{(1)}, \ldots, o^{(h)}] o=Wo[o(1),…,o(h)]
接下来我们就可以来实现多头注意力了,假设我们有h个头,隐藏层权重 h i d d e n _ s i z e = p q = p k = p v hidden\_size = p_q = p_k = p_v hidden_size=pq=pk=pv 与query,key,value的维度一致。除此之外,因为多头注意力层保持输入与输出张量的维度不变,所以输出feature的维度也设置为 d 0 = h i d d e n _ s i z e d_0 = hidden\_size d0=hidden_size。
基于位置的前馈网络
Transformer 模块另一个非常重要的部分就是基于位置的前馈网络(FFN),它接受一个形状为(batch_size,seq_length, feature_size)的三维张量。Position-wise FFN由两个全连接层组成,他们作用在最后一维上。因为序列的每个位置的状态都会被单独地更新,所以我们称他为position-wise,这等效于一个1x1的卷积。
下面我们来实现PositionWiseFFN:
Add and Norm
除了上面两个模块之外,Transformer还有一个重要的相加归一化层,它可以平滑地整合输入和其他层的输出,因此我们在每个多头注意力层和FFN层后面都添加一个含残差连接的Layer Norm层。这里 Layer Norm 与7.5小节的Batch Norm很相似,唯一的区别在于Batch Norm是对于batch size这个维度进行计算均值和方差的,而Layer Norm则是对最后一维进行计算。层归一化可以防止层内的数值变化过大,从而有利于加快训练速度并且提高泛化性能。 (ref)
位置编码
与循环神经网络不同,无论是多头注意力网络还是前馈神经网络都是独立地对每个位置的元素进行更新,这种特性帮助我们实现了高效的并行,却丢失了重要的序列顺序的信息。为了更好的捕捉序列信息,Transformer模型引入了位置编码去保持输入序列元素的位置。
假设输入序列的嵌入表示 X ∈ R l × d X\in \mathbb{R}^{l\times d} X∈Rl×d, 序列长度为 l l l嵌入向量维度为 d d d,则其位置编码为 P ∈ R l × d P \in \mathbb{R}^{l\times d} P∈Rl×d ,输出的向量就是二者相加 X + P X + P X+P。
位置编码是一个二维的矩阵,i对应着序列中的顺序,j对应其embedding vector内部的维度索引。我们可以通过以下等式计算位置编码:
P i , 2 j = s i n ( i / 1000 0 2 j / d ) P_{i,2j} = sin(i/10000^{2j/d}) Pi,2j=sin(i/100002j/d)
P i , 2 j + 1 = c o s ( i / 1000 0 2 j / d ) P_{i,2j+1} = cos(i/10000^{2j/d}) Pi,2j+1=cos(i/100002j/d)
f o r i = 0 , … , l − 1 a n d j = 0 , … , ⌊ ( d − 1 ) / 2 ⌋ for\ i=0,\ldots, l-1\ and\ j=0,\ldots,\lfloor (d-1)/2 \rfloor for i=0,…,l−1 and j=0,…,⌊(d−1)/2⌋

F i g . 10.3.4 位 置 编 码 Fig. 10.3.4\ 位置编码 Fig.10.3.4 位置编码
编码器
我们已经有了组成Transformer的各个模块,现在我们可以开始搭建了!编码器包含一个多头注意力层,一个position-wise FFN,和两个 Add and Norm层。对于attention模型以及FFN模型,我们的输出维度都是与embedding维度一致的,这也是由于残差连接天生的特性导致的,因为我们要将前一层的输出与原始输入相加并归一化。
现在我们来实现整个Transformer 编码器模型,整个编码器由n个刚刚定义的Encoder Block堆叠而成,因为残差连接的缘故,中间状态的维度始终与嵌入向量的维度d一致;同时注意到我们把嵌入向量乘以 d \sqrt{d} d 以防止其值过小。
解码器
Transformer 模型的解码器与编码器结构类似,然而,除了之前介绍的几个模块之外,编码器部分有另一个子模块。该模块也是多头注意力层,接受编码器的输出作为key和value,decoder的状态作为query。与编码器部分相类似,解码器同样是使用了add and norm机制,用残差和层归一化将各个子层的输出相连。
仔细来讲,在第t个时间步,当前输入 x t x_t xt是query,那么self attention接受了第t步以及前t-1步的所有输入 x 1 , … , x t − 1 x_1,\ldots, x_{t-1} x1,…,xt−1。在训练时,由于第t位置的输入可以观测到全部的序列,这与预测阶段的情形项矛盾,所以我们要通过将第t个时间步所对应的可观测长度设置为t,以消除不需要看到的未来的信息。

对于Transformer解码器来说,构造方式与编码器一样,除了最后一层添加一个dense layer以获得输出的置信度分数。下面让我们来实现一下Transformer Decoder,除了常规的超参数例如vocab_size embedding_size 之外,解码器还需要编码器的输出 enc_outputs 和句子有效长度 enc_valid_length。
课后练习题