激活函数原函数和导数的绘制及饱和度-- 021
微信公众号:python宝
关注可了解更多的python相关知识。若有问题或建议,请公众号留言;
内容目录
一、激活函数简介二、Sigmoid三、tanh四、ReLU 五、其它激活函数及饱和度
一、激活函数简介
深度学习的发展一般分为三个阶段,感知机-->三层神经网络-->深度学习(表示学习)。早先的感知机由于采用线性模型,无法解决异或问题,表示能力受到限制。为此三层神经网络放弃了感知机良好的解释性,而引入非线性激活函数来增加模型的表示能力,非线性变换函数又被称为激活函数。
1)非线性激活函数的引入,使得模型能解决非线性问题;
2)引入激活函数之后,不再会有0损失的情况,损失函数采用对数损失,这也使得三层神经网络更像是三层多元(神经单元)逻辑回归的复合。
神经网络中每一个神经元都可以看作是一个逻辑回归模型,三层神经网络就是三层逻辑回归模型的复合,只是不像逻辑回归中只有一个神经元,一般输入层和隐藏层都是具有多个神经元,而输出层对应一个logistic回归单元或者softmax单元,或者一个线性回归模型。
如果不用激励函数(其实相当于激励函数是f(x) = x),在这种情况下你每一层输出都是上层输入的线性函数,很容易验证,无论你神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,这种情况就是最原始的感知机(Perceptron)了。
如果使用激活函数,会给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中。
值得注意的是激活函数是一个数值操作,不涉及矩阵求导,线性函数中1/m是因为w是作用于m个样本,所以在确定负梯度方向时需要m个样本取均值。
二、Sigmoid
Sigmoid函数会造成梯度损失。
一个非常不好的地方在于Sigmoid在靠近1和0的两端时梯度几乎为0,而反向传播算法的梯度向下传播时,每过一层就会增加一个g′(z)项(Sigmoid关于每一层线性组合值的导数),且Sigmoid函数的导数满足f′(x)=f(x)(1−f(x)),又f(x)的值在(0, 1)之间,故f′(x)的值在(0, 0.25]之间,因此当神经网络层数非常深的时候,较深层的梯度值由于乘了很多值很小的数更变得很小,导致较深层的参数更新不动,这就是“梯度消失”现象。另外,如果使用Sigmoid函数,那么需要在权重初始化的时候非常小心,如果初始化的权重过大,经过线性激活函数也会导致大多数神经元变得饱和,没有办法更新参数。
Sigmoid输出并非zero-centered,不便于下层的计算
这就会导致经过Sigmoid激活函数之后的输出,作为后面一层的输入的时候是非0均值的,这个时候如果输入进入下一层神经元的时候全是正的,那么在更新参数时永远都是正梯度。怎么理解呢?比如下一层神经元的输入是x,参数是w和b,那么输出为f=wx+b,这个时候▽f(w)=x,所以如果x是0均值的数据,那么梯度就会有正有负,但是这个问题并不是很严重,因为一般神经网络在训练的时候都是按batch进行训练的,这个时候一定程度上可以缓解这个问题。
Sigmoid 输出不是以 O 为均值,这就会导致经过 Sigmoid 激活函数之后的输出,作为后面一层网络的输入的时候是非 0 均值的,如果数据进入神经元的时候是正的,那么 w 计算出的梯度也始终都是正的,那么在更新参数的时候永远都是正梯度。
Sigmoid有饱和区域,是软饱和,在大的正数和负数作为输入的时候,梯度就会变成零,使得神经元基本不能更新。
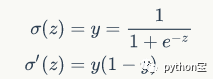
Sigmoid非线性函数的数学表达式是:
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.family']='SimHei'
plt.rcParams['font.sans-serif']=['SimHei']
import matplotlib
#更改字体,正确显示中文
matplotlib.rcParams['font.family']='SimHei'
matplotlib.rcParams['font.sans-serif']=['SimHei']
x=np.linspace(-10,10,100)
y=1/(1+np.exp(-x))
plt.xlabel("x")
plt.ylabel("y")
plt.title("sigmoid function and its derivative image")
plt.plot(x,y,color='r',label="sigmoid")
y=np.exp(-x)/pow((1+np.exp(-x)),2)
plt.plot(x,y,color='b',label="derivative")
plt.legend()#将plot标签里面的图注印上去
plt.show()
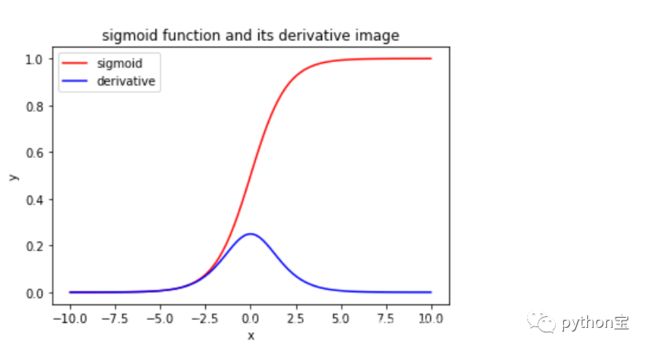
三、tanh
它将输入数据转化到-1到1之间,可以通过图像看出它将输出变成了0均值,在一定程度上解决了Sigmoid函数的第二个问题,但是它仍然存在梯度消失的问题。tanh激活函数是Sigmoid函数的变形,tanh激活函数在0附近可近似为恒等映射,即tanh(x)≈x。其数学表达式为如下所示:
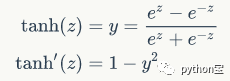
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.family']='SimHei'
plt.rcParams['font.sans-serif']=['SimHei']
import matplotlib
#更改字体,正确显示中文和显示负号
matplotlib.rcParams['axes.unicode_minus']=False
matplotlib.rcParams['font.family']='SimHei'
matplotlib.rcParams['font.sans-serif']=['SimHei']
x=np.linspace(-10,10,100)
y=(1-np.exp(-2*x))/(1+np.exp(-2*x))
plt.xlabel('x')
plt.ylabel('y')
plt.title("Tanh function and its derivative image")
plt.plot(x,y,color='r',label='Tanh')
y=1-pow((1-np.exp(-2*x))/(1+np.exp(-2*x)),2)
plt.plot(x,y,color='b',label='derivative')
plt.legend()plt.show()
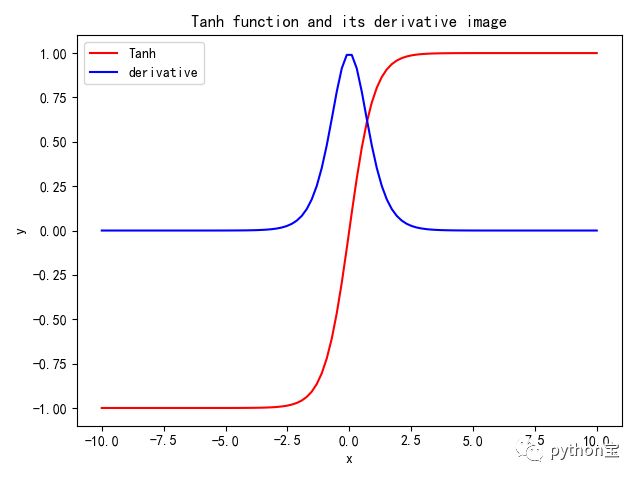
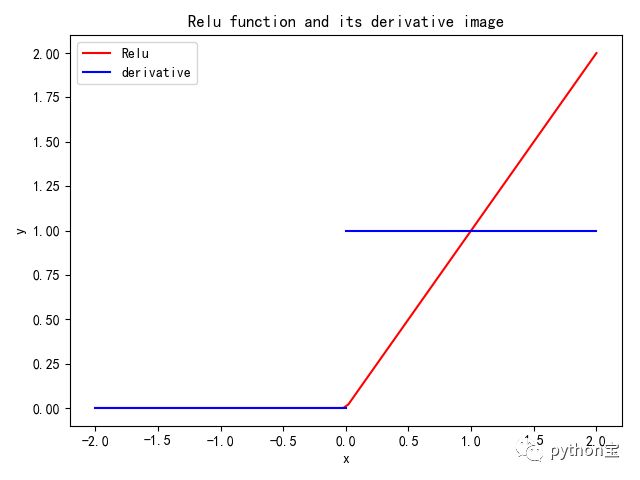
四、ReLU
ReLU激活函数近一些年来越来越流行,它的数学表达式为f(x)=max(0, x),换句话说,这个激活函数只是简单地将大于0的部分保留,将小于0的部分变成0,即Relu其实就是个取最大值的函数,这种操作被成为单侧抑制。(也就是说:在输入是负值的情况下,它会输出0,那么神经元就不会被激活。这意味着同一时间只有部分神经元会被激活,从而使得网络很稀疏,进而对计算来说是非常有效率的)。
对于线性函数而言,ReLU的表达能力更强,尤其体现在深度网络中;而对于非线性函数而言,ReLU由于非负区间的梯度为常数,因此不存在梯度消失问题(Vanishing Gradient Problem),使得模型的收敛速度维持在一个稳定状态。
ReLu虽然在大于0的区间是线性的,在小于等于0的部分也是线性的,但是它整体不是线性的,因为不是一条直线。
当激活函数是线性的时候,一个两层的神经网络就可以基本逼近所有的函数,但是,如果激活函数是恒等激活函数的时候,就不满足这个性质了,而且如果MLP使用的是恒等激活函数,那么其实整个网络跟单层神经网络是等价的;
f(x)≈x:当激活函数满足这个性质的时候,如果参数的初始化是random的很小的值,那么神经网络的训练将会很高效;如果不满足这个性质,那么就需要很用心的去设置初始值
输出值的范围:当激活函数输出值是有限的时候,基于梯度的优化方法会更加稳定,因为特征的表示,当激活函数的输出是无限的时候,模型训练会更加的高效,不过在这种情况很小,一般需要一个更小的学习率
ReLU函数的缺点:当输入为负时,梯度为0,会产生梯度消失问题。
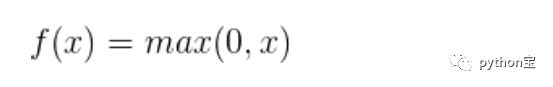
import matplotlib.pyplot as plt
import numpy as np
import matplotlib
#显示负号
matplotlib.rcParams['axes.unicode_minus']=False
plt.rcParams['font.family']='SimHei'
plt.rcParams['font.sans-serif']=['SimHei']
import matplotlib
#更改字体,正确显示中文
matplotlib.rcParams['font.family']='SimHei'
matplotlib.rcParams['font.sans-serif']=['SimHei']
x=np.linspace(-2,2,100)
y=x*(x>0)
plt.xlabel('x')
plt.ylabel('y')
plt.title("Relu function and its derivative image")
plt.plot(x,y,color='r',label="Relu")
x=np.linspace(-2,0)
y=np.linspace(0,0)
plt.plot(x,y,color='b')
x=np.linspace(0,2)
y=np.linspace(1,1)
plt.plot(x,y,color='b',label="derivative")
plt.legend()
plt.show()
ReLU的优点:
(1)相比于Sigmoid激活函数和Tanh激活函数,ReLU能够极大地加速随机梯度下降法的收敛速度,这因为它是线性的,且不存在梯度消失的问题。
(2)相比于Sigmoid激活函数和tanh激活函数的复杂计算,ReLU的计算方法更加简单,只需要一个阈值过滤就可以得到结果。
ReLU的缺点:
训练的时候很脆弱,如果权重初始化的时候不是很好,很多个大的w乘起来会得到一个很大的梯度——梯度爆炸现象,从而导致更新的w很小,进而得到的输出值进入了负半轴,神经元失活。如果发生这种情况之后,经过ReLU的梯度永远都会是0,也就意味着参数无法更新了,因为ReLU激活函数本质上是一个不可逆的过程。不过这个问题可以通过一些比较好的权重初始化方法解决,因此ReLU现在仍然是用的最多的激活函数。
五、其它激活函数及相关概念(饱和函数)1、饱和
当一个激活函数h(x)满足 limn→+∞ h′(x)=0 时,我们称之为右饱和。
当一个激活函数h(x)满足 limn→−∞h′(x)=0 时,我们称之为左饱和。
当一个激活函数,既满足左饱和又满足右饱和时,我们称之为饱和。
2、硬饱和与软饱和
对任意的x,如果存在常数c,当 x > c 时恒有 h′(x)=0,则称其为右硬饱和。
对任意的x,如果存在常数c,当 x < c 时恒有 h′(x)=0,则称其为左硬饱和。
若既满足左硬饱和,又满足右硬饱和,则称这种激活函数为硬饱和。
如果只有在极限状态下偏导数等于0的函数,称之为软饱和。
About Me:小婷儿
● 本文作者:小婷儿,专注于python、数据分析、数据挖掘、机器学习相关技术,也注重技术的运用
● 作者博客地址:https://blog.csdn.net/u010986753
● 本系列题目来源于作者的学习笔记,部分整理自网络,若有侵权或不当之处还请谅解
● 版权所有,欢迎分享本文,转载请保留出处
● 微信:tinghai87605025 联系我加微信群
● QQ:87605025
● QQ交流群py_data :483766429
● 公众号:python宝 或 DB宝
● 提供OCP、OCM和高可用最实用的技能培训
● 题目解答若有不当之处,还望各位朋友批评指正,共同进步

如果你觉得到文章对您有帮助,欢迎赞赏,有您的支持,小婷儿一定会越来越好!