CVPR2019: Bag of Tricks for Image Classification with Convolutional Neural Networks
概况
自2012年AlexNet提出以后涌现了大量的深度神经网络结构,例如VGG、Inception 及ResNet等等,这些不同网络结构之间的性能差异不仅仅是由网络结构的差异造成的,其它很多小的trick,比如stride size、学习率等等都会对结果带来很大的影响。为了综合评估各种手段对于训练结果的影响程度,本文对多种训练技巧进行了评估,并提出了一系列可以提升深度神经网络训练效果的trick。
论文涉及到以下几个方面:
- 对batch大小的讨论
- 对参数精度(32或16位)的讨论
- 针对ResNet结构的微小调整
- 训练精度提升的手段:
- Learning rate Decay
- Label smoothing
- Knowledge distillation
Baseline
在baseline中采用的数据处理方式及优化手段等:
- ResNet 图像转换为32位浮点数格式,值域[0,255]
- 随机裁剪区域,比例随机选取范围[3/4, 4/3]. 区域大小随机采取范围[8%,100%]
- resize裁剪的区域至224×224→以0.5的概率随机水平翻转
- 色调、饱和度和明亮度随机调整比例范围[0.6,1.4]
- 增加符合正太分布N(0,0.1)的PCA噪声
- RGB通道减去[123.68,116.779,103.939], 除以[58.393,57.12,57.375].
- 初始化:采用Xavier algorithm. 偏置初始值全部设置为0.
- 优化方式:Nesterov Accelerated Gradient (NAG) desent
- 120 epoch, 8张Nvidia V100 GPU, batch size 256.
- Learning rate is initialized to 0.1 and divided by 10 at the 30th, 60th, and 90th epochs.
Batch size
在epoch一定的情况下,大的batch可能会降低模型的训练精度。这一问题的解决方案有:
- 线性改变学习率的初始值。大的batch会降低随机梯度下降的方差,因此有学者提出了通过线性增加学习率的方式改善大batch带来的不良影响。具体如下,如本文中baseline中的batch大小为256,如果将batch大小设置为一个更大的数字b,那么初始的学习率应该乘以b/256。【这种方式在文中实验中表现最差,后三者与小batch表现相当】
- 学习率预热策略(learning rate warmup)。由于在初始时刻所有的参数都是随机设定的,参数值与最终的结果相差甚远,如果一开始就采用很大的学习率会造成学习的不稳定。在学习率预热策略中,将学习率从一个很小的值随着训练的进行增大到预期初始学习率的大小。具体入戏,如果前5个epoch是用于预热的epoch,预期的初始学习率为0.1,那么在第i个预热epoch的学习率为i*0.1/5
- 0初始化γ.在ResNet中,一个block的输出包含上一层的输出和自己block的输出,如果将自己本block的输出权重设置为零,可以在开始的时候减少层数
- 无偏置衰减。偏置的L2 正则化是为了避免过拟合,除了在卷积层和全连接层使用以外,其它地方无需添加正则。
参数精度
当前主流的计算框架,参数的运算都是32位浮点数的,而一些新的计算设备,如Nvidia V100 提供了在16位浮点数情况下更高的计算效率。相比与32位浮点数,利用16位浮点数进行计算可以使训练速度增大2-3倍。但由此也会带来对训练效果的负面影响,Micikevicius 等人提出可以通过同时保留16位参数和32位参数,在计算梯度时采用16位数据,而在更新参数时采用32位参数的形式避免该问题。另外,对loss乘上一个系数也可以在一定程度上避免该问题。【实验发现从32位转到16位对训练结果并无显著影响】
模型调整(Model Tweaks)
对网络结构的细微调整,比如更改特定卷基层的的stride,可能会对模型的精度带了不可忽略的影响,在本文中以ResNet为例探究了微调网络结构对模型的影响。
%
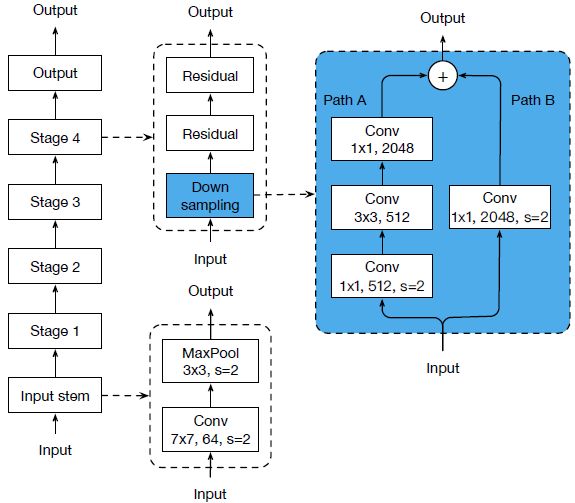
ResNet 50 网络结构示意图
ResNet 的几种变形:

ResNet-B: 最初来自与Torch中的ResNet. 在原始的ResNet的blocks中,Path A的第一次层卷积采用的是1×1,stride=2的卷积操作,因此会遗漏3/4的输入feature map, 在ResNet-B更改了Path A的前两层卷积参数。
ResNet-C: 最初来自于Inception-v2. 研究发现卷积的计算量与卷积核的长或者宽呈现二次关系。比如一个7×7的卷积核的计算量是3×3卷积核计算量的5.4倍。因此在该结构中,input stem的7×7卷积核被换成了3×3卷积核。
ResNet-D: 该结构由本文提出。受ResNet-B的启发,在ResNet blocks的path B上同样存在feature map 被遗漏的问题,因此文中提出了如上图C新ResNet结构。
上述几中不同模型的表现如下:

ResNet-D得到的精度最好,相比于ResNet, ResNet-D训练速度降低3%
Training refinements
学习率衰减
文中对比了两种学习率衰减策略:
- Step: decay: 每隔一定的epoch,比如30epoch,学习率降低至0.1
- Cosine decay: 假设总共的batch数量为T,那么第t个batch的学习率为:

两种衰减策略的表现:


Label Smoothing
在分类训练中,通过softmax获得标签的概率分布qi, 然后利用通过真实标签概率pi, 计算交叉损失熵:
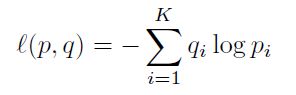
当i=真实标签时,pi = 1, 否则为0
如果直接采用softmax获取的概率分布容易造成过拟合,因此在Inception-v2中首次提出了label smoothing策略,对qi进行了如下调整:

Knowlege Distillation
利用一个pre-train的高精度网络充当teacher, 对待训练的student网络添加监督信息:
其中第一项为普通的分类交叉损失,第二项是待训练网络与teacher网络输出的交叉损失熵。
Mixup Training
一种数据增强的手段。每次随机选取两个样例(xi,yi)和(xj,yj),通过线性操作获得新的样例:
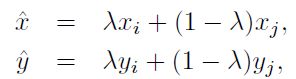
在mixup training中仅采用新生成的样例。
实验
实验发现cosine decay, label smoothing and mixup 对ResNet, Inception V3 and MobileNet 都有稳定的提升,而Distillation只对于ResNet有效,而对于Inception-V3和MobileNet无效,这可能与采用的teacher net的类型有关,文中采用的是ResNet-152.
随后作者将提升的训练结果用到了目标检测和语义分割两个任务中,证明了这些提升手段有很好的迁移能力。